论文阅读 | Lite Transformer with Long-Short Range Attention
论文:Lite Transformer with Long-Short Range Attention by Wu, Liu et al.
LSRA特点:两组head,其中一组头部专注于局部上下文建模(通过卷积),而另一组头部专注于长距离关系建模(通过注意)。
传统的self-attention被认为是有冗余的,经验表明,句子中的本地关系被过于关注了。这可以通过标准卷积更加有效的进行建模。同样的结论在On the Relationship between Self-Attention and Convolutional Layers也有,同时,这个精简可以在某些情况下帮助提升模型的能力,但它不适用于较轻量级的应用。
Long-Short Range Attention (LSRA)通过将输入沿通道维度分成两部分,并将这两个部分分别提供给两个模块,从而提高了计算效率:全局提取器使用标准的自注意力,局部提取器使用轻量级的深度卷积。作者给出了一个2.5×简化的模型的总体计算量,使它适合移动端的配置。在机器翻译、抽象摘要和语言建模任务上有提高。
配合剪枝和量化,模型大小压缩到达了18.2x。
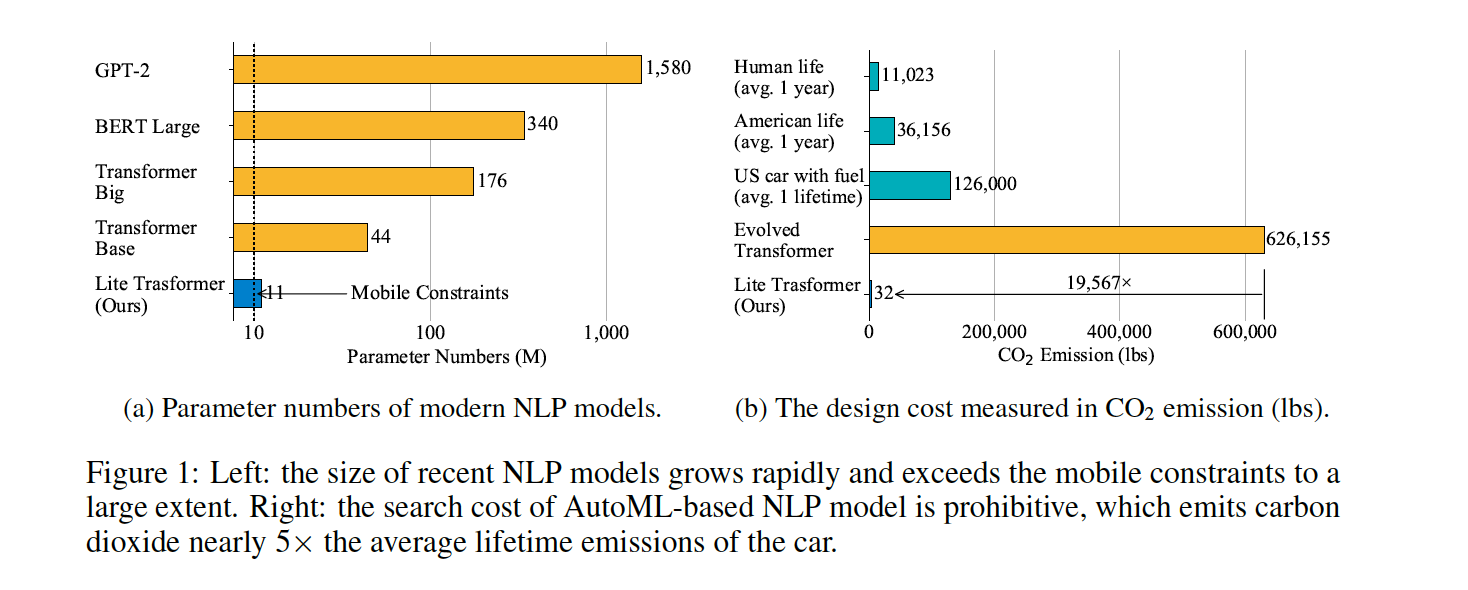
从图上看对比还是非常明显的。
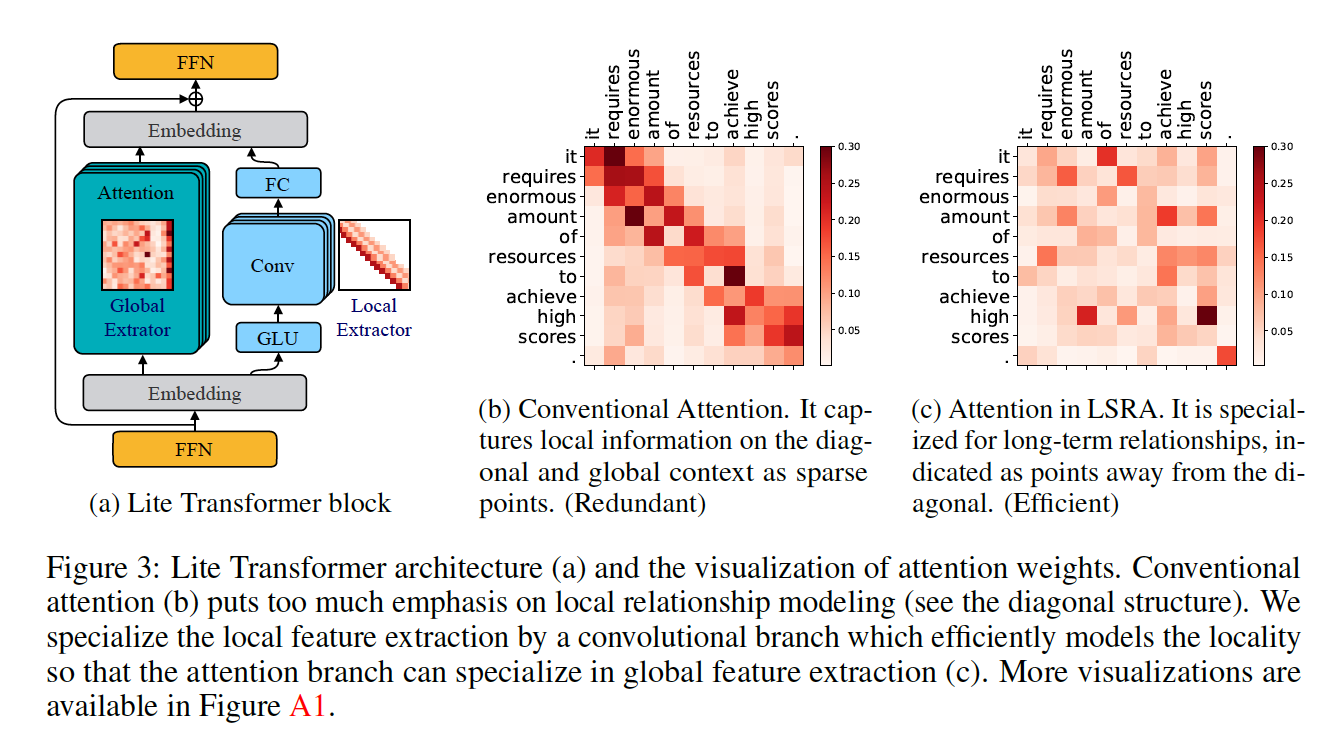
得到输入的embedding后,分为两个分支,一个是attention(在原始的transformer 上,通道维度减少了一半。另一个分支是卷积,通过滑动窗口,对角线组可以很容易地被模块覆盖。最后把两个分支的结果stack后交给FFN。
实验结果
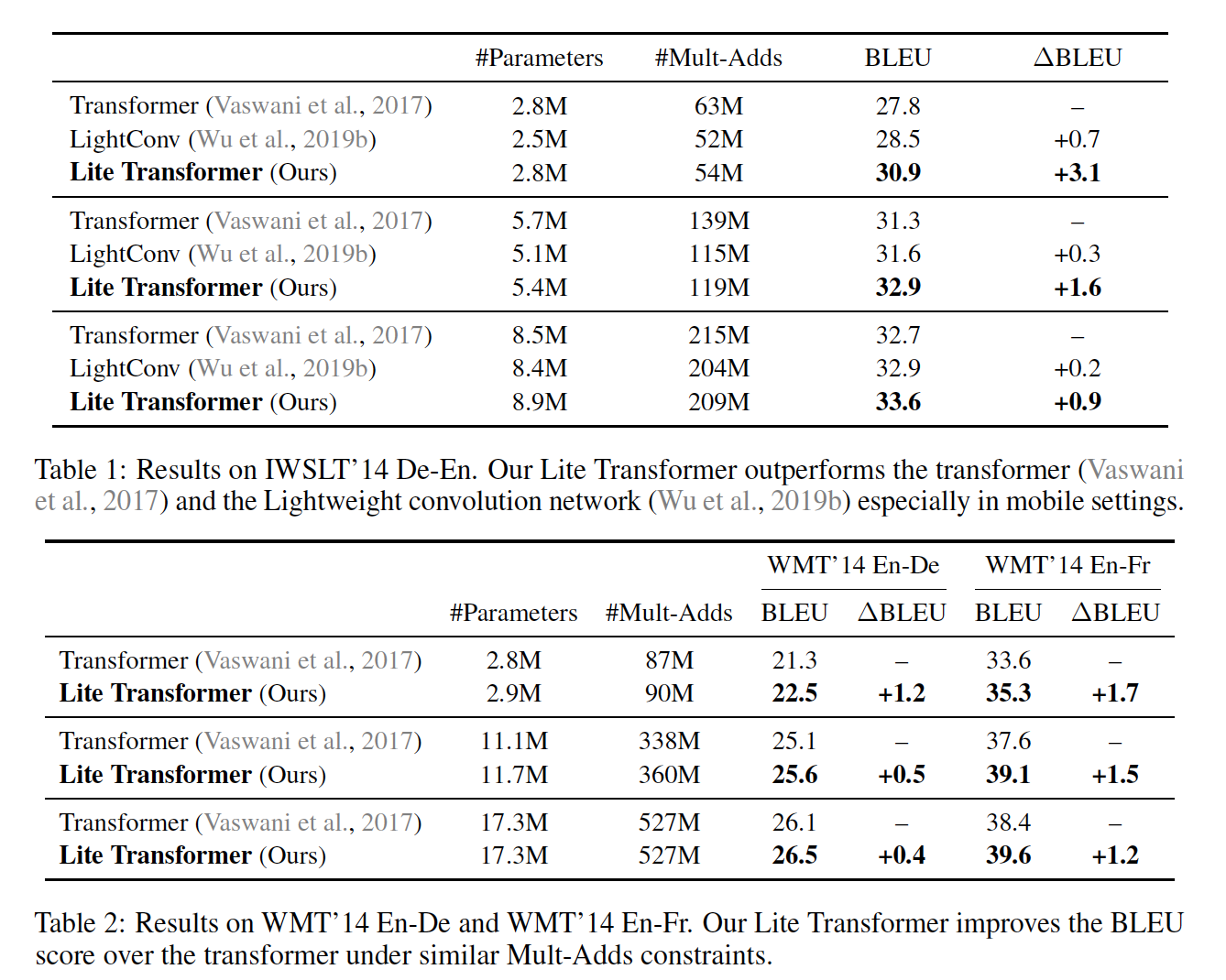
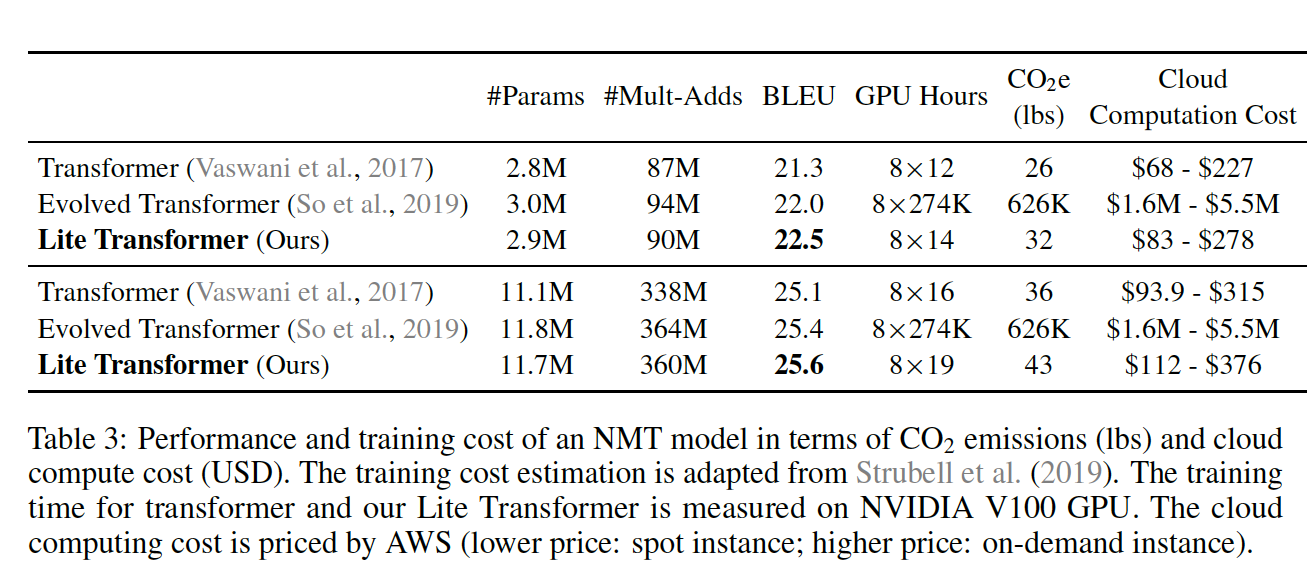
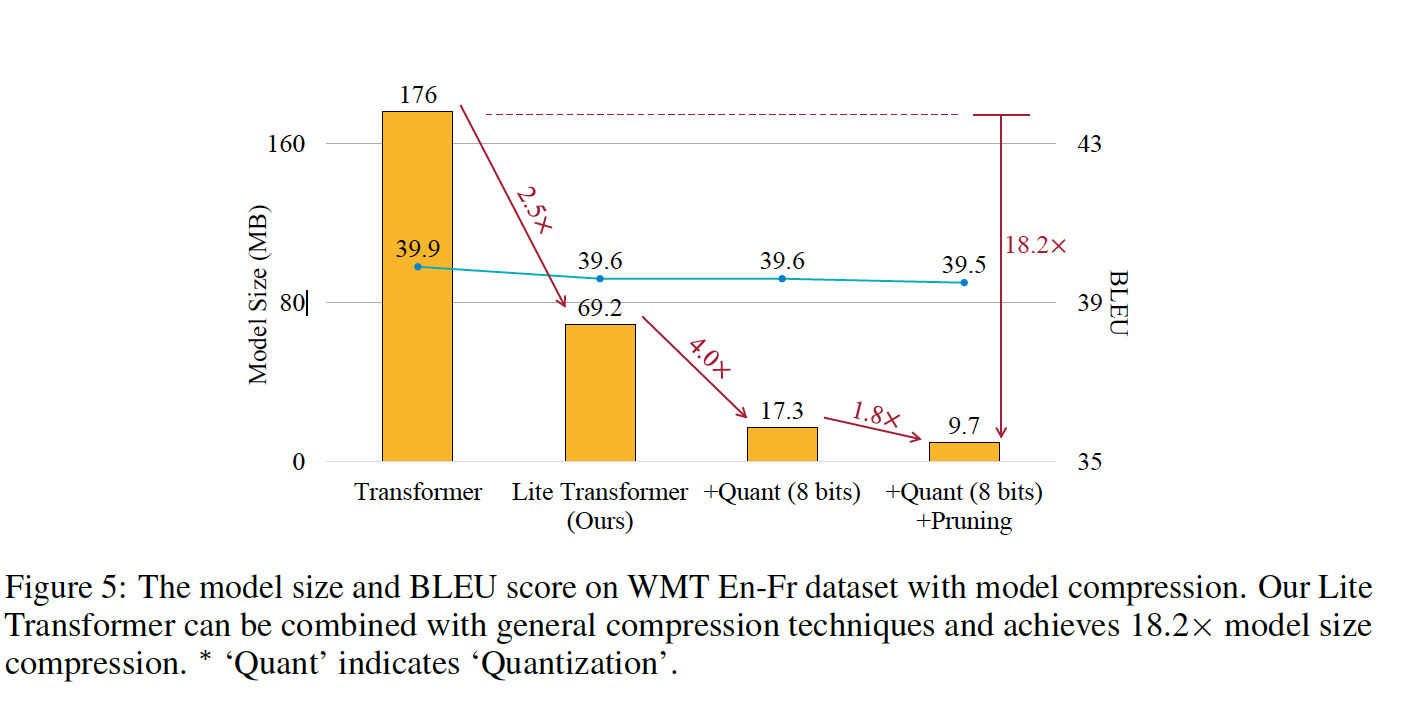
论文用到的量化和剪枝方法分别参考:
1. 量化:
K-means (Han et al., 2016),
Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding.
2. 剪枝:
sensitivity of each layer (Han et al., 2015a),Learning both weights and connections for efficient neural network.
这两个方法的一作也是本文的作者之一。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号