预训练模型 | ELECTRA: Efficiently Learning an Encoder that Classifies Token Replacements Accurately
ELECTRA 与现有的生成式的语言表示学习方法相比,判别式的预训练任务具有更高的计算效率和参数效率。
- 计算效率:训练判别器分辨每一个 token 是否被替换,而不是 MLM 那样训练网络作为生成器预测被损坏的 15% token 的原始 token,从而使模型从所有的输入 token 中学习而不是 MLM 中那样仅从 masked 的部分 token 学习。此外,生成器与判别器共享token embedding以及判别器使用的二分类而非V分类任务也有效提升了训练效率。
- 参数效率:最终得到的判别式分类器不必对完整的数据分布进行建模。
ELECTRA和BERT最大的不同应该是在于两个方面:
- masked(replaced) tokens的选择
- training objective(生成式的Masked language model(MLM)预训练任务改成了判别式的Replaced token detection(RTD)任务)
不随机mask,去专门选那些对模型来说学习困难的token。
train一个简单的MLM,当做模型对训练难度的先验,简单的自动过滤(在这里就是sample出来的和原句子一样),复杂的后面再学。举“我想吃苹果”这个例子。比如我这里还是mask为“我想吃苹[MASK]”,MLM这个生成器可以以很高的概率sample到“果”,但是对“我[MASK]吃苹果”,MLM就很难说大概率采样到“想”了,也可能是“不”、“真”等等……总的来说,MLM的作用就是为自动选择masked tokens提供了一种非常有效的方法!
ELECTRA另辟蹊径,用一个二分类去判断每个token是否已经被换过了。这就把一个DAE(或者LM)任务转换为了一个分类任务(或者序列标注)。这有两个好处:(1)每个token都能contribute to some extent;(2)缓解distribution的问题。第一点是和MLM联系起来的(这也是ELECTRA精妙的地方了)。如果MLM牛逼,那么discriminate的难度就很大,从而就可以看作是hard example。第二点是,如果我们像BERT那样去预测真正的token,也即通过一个classifier ![[公式]]() 的话,那么它相比二分类器
的话,那么它相比二分类器 ![[公式]]() 而言就需要更多的计算量,而且还要suffer 由于
而言就需要更多的计算量,而且还要suffer 由于 ![[公式]]() 较大导致的分布问题。
较大导致的分布问题。
以上两点总结起来就是:
性能
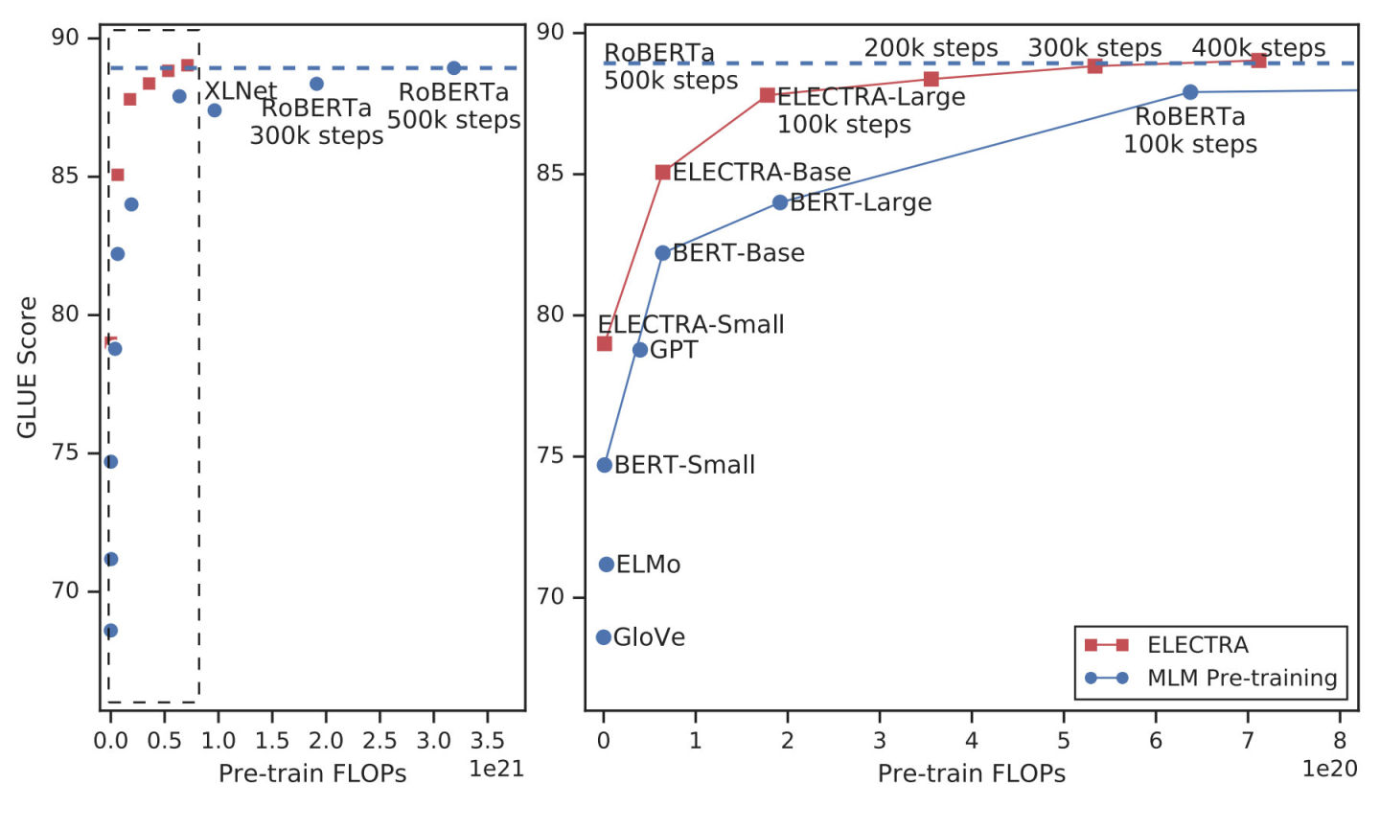
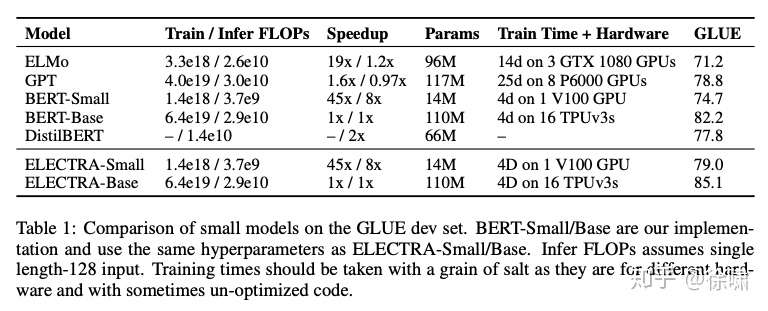
首先是对小模型的表现。观察第二列中的Train / Infer FLOPs 以及最后一列的 GLUE 均分,同等计算成本下,效果超过 BERT-Small,甚至略高于计算成本更高的GPT,而且参数量极小。而且ELECTRA-Base 模型也优于 BERT-Base ,甚至优于 BERT-Large (GLUE得分84.0)。这正是ELECTRA所追求的以较少的计算量获得出色的结果,从而扩大在 NLP 中开发和应用预训练模型的可行性。
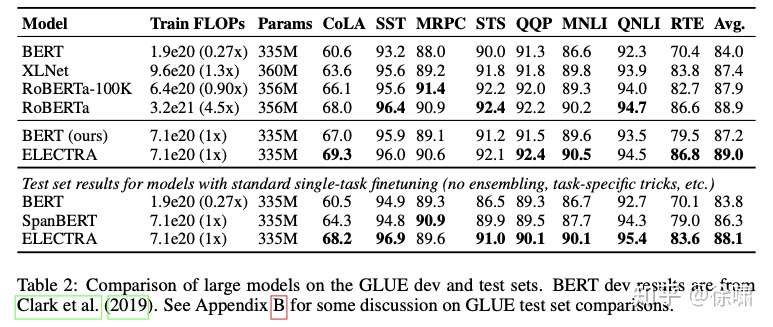
再看大模型的表现(此时用的 XLNet 使用的数据集)。同样观察第二列与最后一列,ELECTRA与当前 RoBERTa 的性能相匹配,但是计算时间仅为其 1 / 4。
综上,与 MLM 相比,ELECTRA 的预训练目标具有更高的计算效率,并且可以在下游任务上实现更好的性能。尤其是在小模型上,其表现相当亮眼。
最后分享一个原文作者对模型的理解:论文第四节中提到,本文的工作可以看做是带有负采样的 CBOW 的大规模版本,将 CBOW 的 BOW encoder 换成 Transformer,将基于 unigram 的负采样换成了基于小型 MLM 生成器的负采样,并且将任务重新定义为关于输入令牌是否来自数据的二分类任务。
这个解释很有意思,MLM 完成负采样,transformer 作为判别器,对所有 token 做二分类任务,这样不仅能从所有 token 中学习,而且二分类任务相比直接生成 token 的 分类任务要简单,计算量也小,实在是精妙。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号