论文阅读 | A Robust Adversarial Training Approach to Machine Reading Comprehension
背景

方法
作者们提出了一种模型驱动的方法,使用自动对抗的方法自动生成未观察过的对抗样本,并运用生成的样本最终提升阅读理解模型的效果鲁棒性,全程无需人工参与。
该方法可以简单地划分为三个步骤:
(1)对每个训练样本利用对抗的方法生成一个干扰向量输入,使得它能够误导当前的阅读理解模型;
(2)采用贪心策略从干扰向量的词汇权重中采样得到对应的离散化的干扰文本;
(3)使用干扰文本构建用于训练的对抗样本,并重新训练阅读理解模型并重复上述步骤直至收敛。

在步骤(1)中,针对已有阅读理解模型训练干扰向量的方法如图4中高亮所示。对于任意一组训练样本,该方法在embedding输入中随机插入一段由词表embedding加权得到的干扰向量序列,组成含有干扰的embedding输入序列。
在训练干扰向量时,选择一个性能优的模型,固定参数,以最小化当前模型正确预测概率为目标,使用梯度下降的方法调整归一化的词表权重,从而生成能够达到迷惑目的的干扰向量序列。
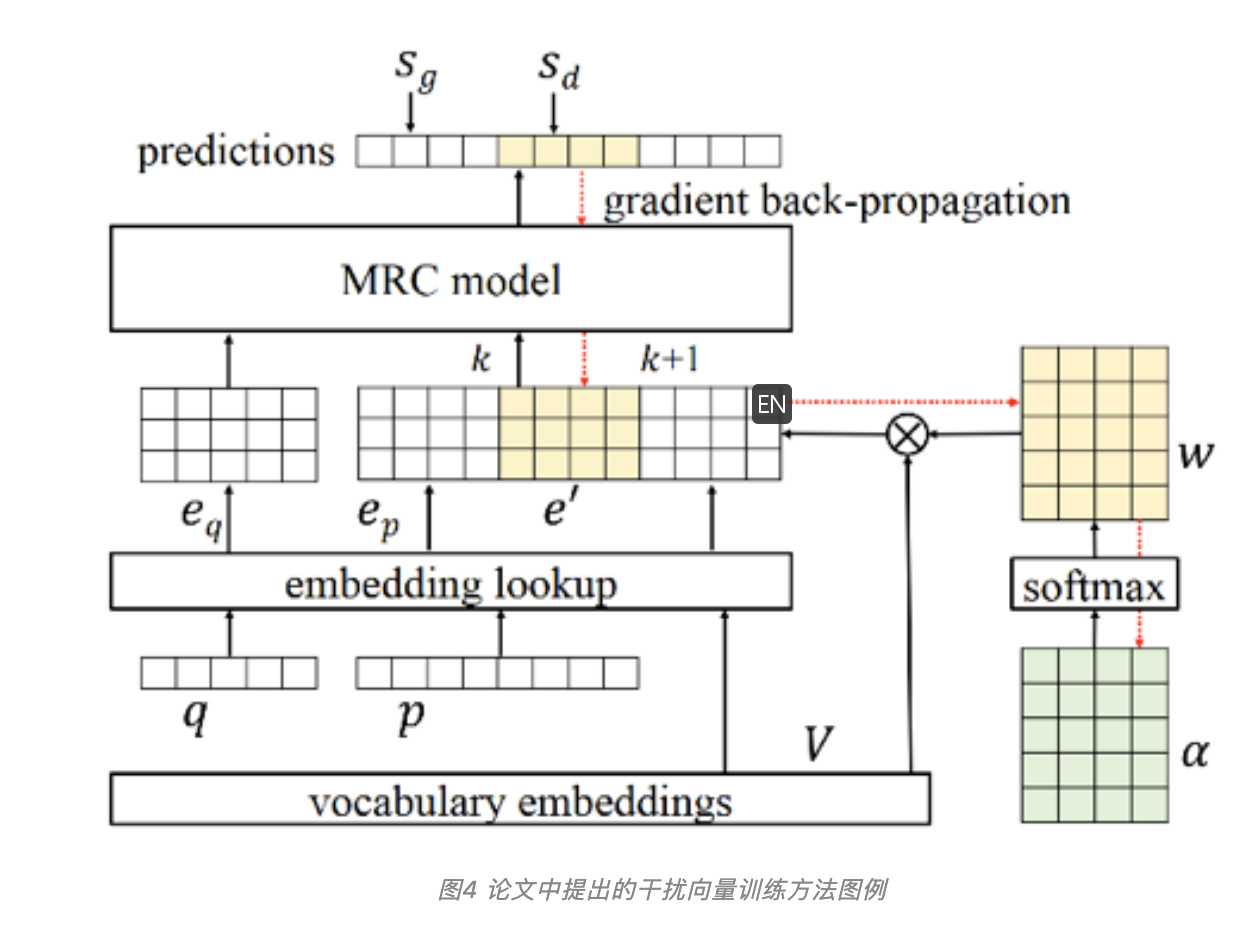
在步骤(2)中,针对干扰向量序列上的各个干扰向量,作者使用贪心的方法采样词表中词汇embedding与干扰向量欧式距离最近的词汇作为该位置的代表词,从而生成一段干扰文本。由于该算法的特性,可以近似地直接选取词表中权重最大的词作为代表词。
在步骤(3)中,作者将生成的干扰文本重新加入到对应训练数据中,构建成为具有对抗意义的对抗样本(adversarial examples),并在训练数据中追加上这些样本进行重新训练,得到鲁棒性加强后的阅读理解模型。并运用该模型继续从步骤(1)开始下一轮迭代,寻找新的能够对抗当前模型的样本,直至收敛。
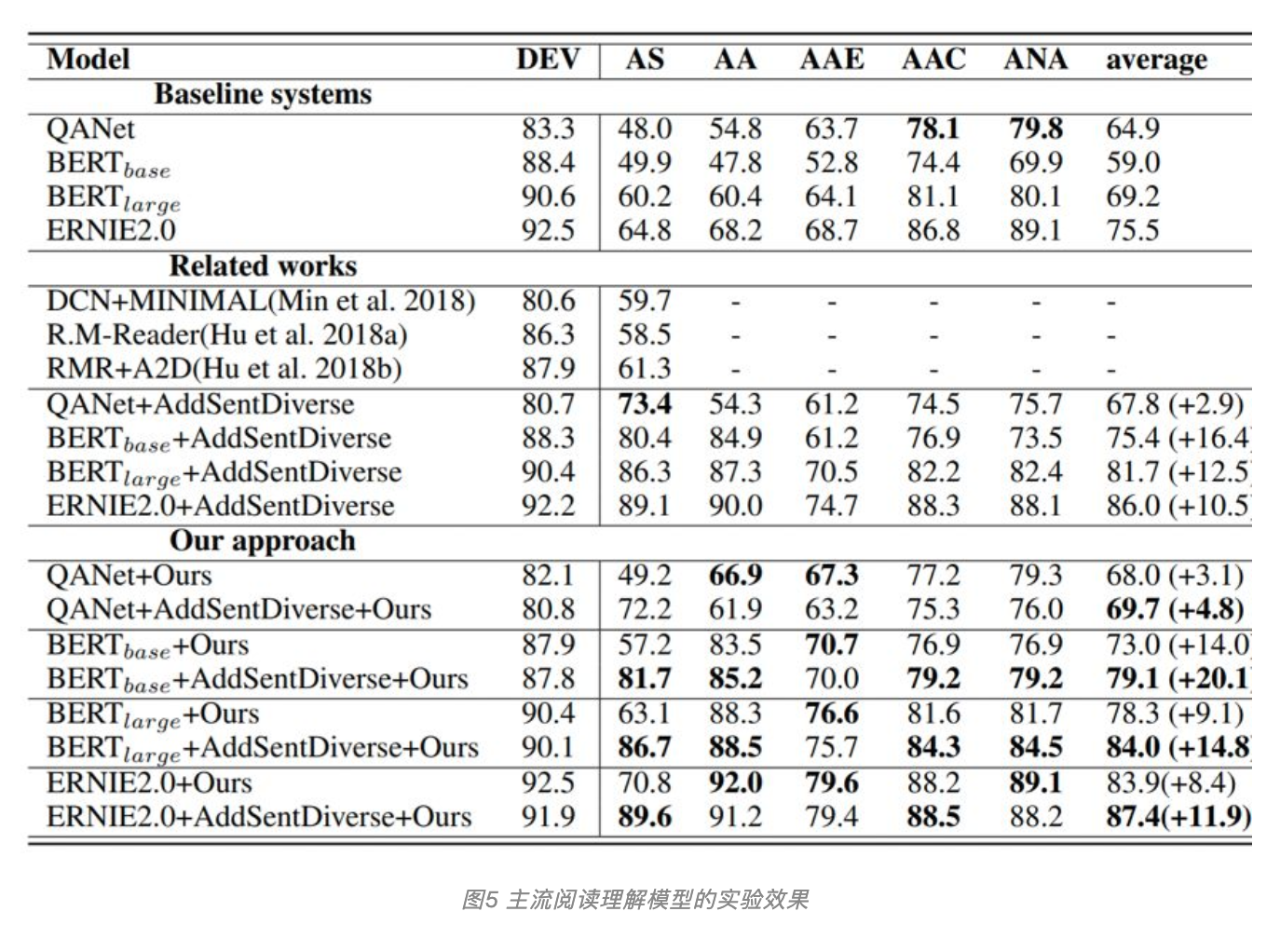
经实验验证,作者发现当前包含BERT和ERNIE等预训练模型在内的最好的阅读理解模型,在面对对抗样本的时候仍然非常脆弱。在5类不同的对抗测试集上,效果均有较大幅度下降,其中BERT-large和ERNIE2.0效果降幅绝对值超过17%。
而当同样的模型运用上论文中的对抗训练方法后,在不同的对抗数据集上均有非常显著的效果提升(如图5所示),相比基线效果错误率降低50%。
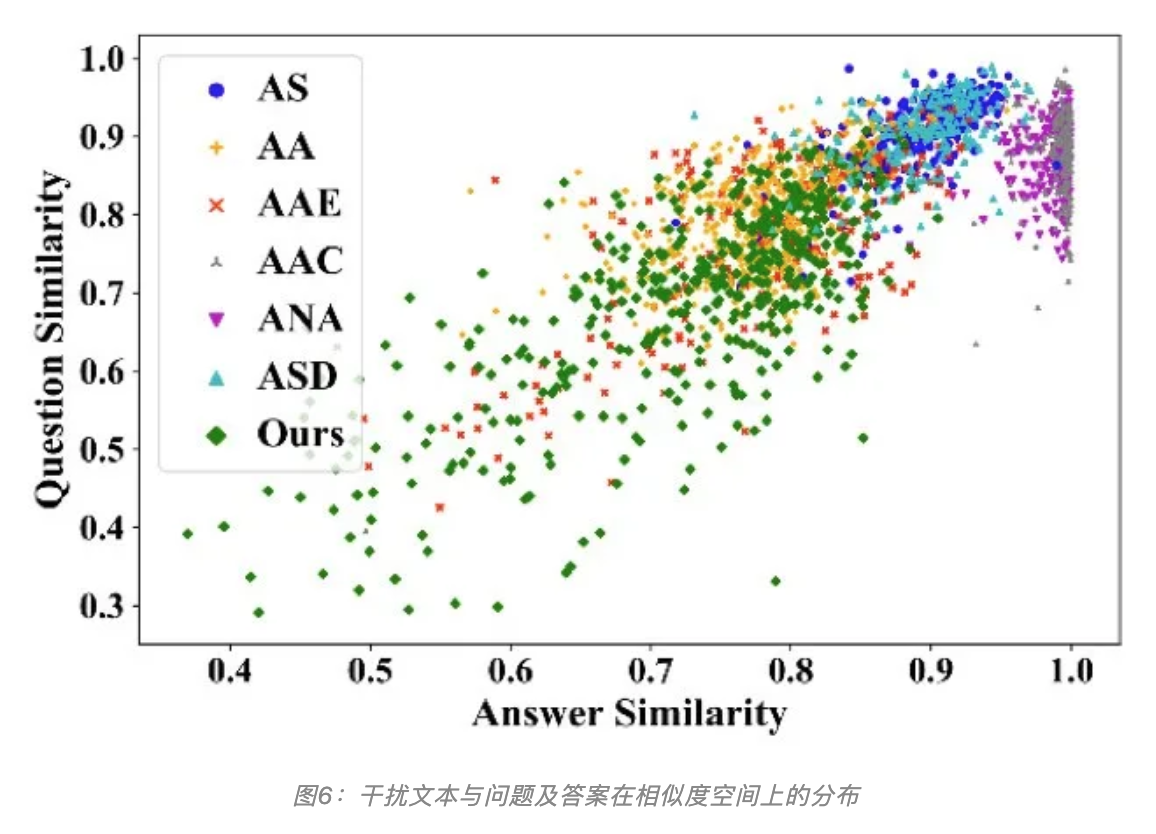
作者通过相关实验,发现论文提出的模型驱动的方法确实能够生成多样性更加丰富的干扰文本(图6中绿点),从而有效补充人工规则的不足。同时也发现使用该方法生成的对抗样本case仍然较为杂乱,并不具备很好的流利度甚至完全不是自然语言,因此当前对抗生成的方法仍然有较大提升空间。
个人想法
个人认为这种策略对模型的提升十分有限,既然不是符合语义的那么和真实场景还是存在很大差距的。
十分有趣的是,百度用自己的ernie2.0 加上自己提出的方法没有得到任何提升?甚至『ERNIE2.0 + AddSentDiverse + Ours』还不如baseline的水平。
文章写得一般,感觉没有重点。
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号