混合精度训练 | fp16 用于神经网络训练和预测
混合精度训练
混合精度训练是在尽可能减少精度损失的情况下利用半精度浮点数加速训练。它使用FP16即半精度浮点数存储权重和梯度。在减少占用内存的同时起到了加速训练的效果。
IEEE标准中的FP16格式如下:
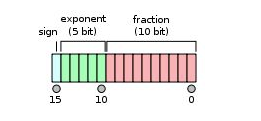
取值范围是5.96× 10−8 ~ 65504,而FP32则是1.4×10-45 ~ 3.4×1038。
从FP16的范围可以看出,用FP16代替原FP32神经网络计算的最大问题就是精度损失。
float : 1个符号位、8个指数位和23个尾数位
利用fp16 代替 fp32
优点:
1)TensorRT的FP16与FP32相比能有接近一倍的速度提升,前提是GPU支持FP16(如最新的2070,2080,2080ti等)
2)减少显存。
缺点:
1) 会造成溢出
因此,在日常使用过程中,常使用双混合精度训练。如图:
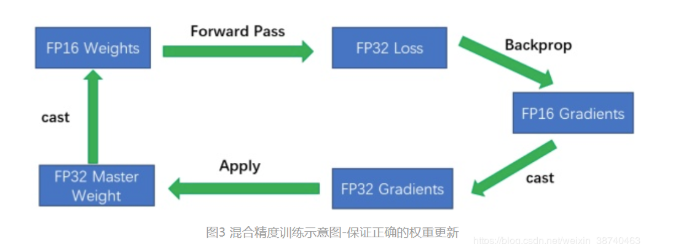
此过程中的技术:
1) Loss scaling :会存在很多梯度在FP16表达范围外,我们为了让其落入半精度范围内,会给其进行等比放大后缩小。
流程:

对百度&英伟达相关论文的解读
文中提出了三种避免损失的方法:
1.1. 为每个权重保留一份FP32的副本
在前向和反向时使用FP16,整个过程变成:权重从FP32转成FP16进行前向计算,得到loss之后,用FP16计算梯度,再转成FP32更新到FP32的权重上。这里注意得到的loss也是FP32,因为涉及到累加计算(参见下文)。
用FP32保存权重主要是为了避免溢出,FP16无法表示2e-24以下的值,一种是梯度的更新值太小,FP16直接变为了0;二是FP16表示权重的话,和梯度的计算结果也有可能变成0。实验表明,用FP16保存权重会造成80%的精度损失。

1.2. Loss-scaling
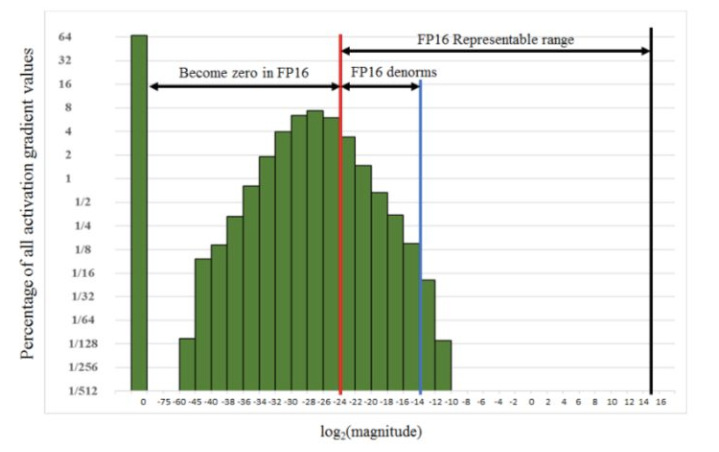
得到FP32的loss后,放大并保存为FP16格式,进行反向传播,更新时转为FP32缩放回来。下图可以看到,很多激活值比较小,无法用FP16表示。因此在前向传播后对loss进行扩大(固定值或动态值),这样在反响传播时所有的值也都扩大了相同的倍数。在更新FP32的权重之前unscale回去。
1.3. 改进算数方法:FP16 * FP16 + FP32。
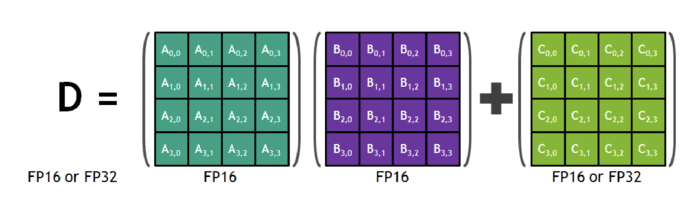
经过实验,作者发现将FP16的矩阵相乘后和FP32的矩阵进行加法运算,写入内存时再转回FP16可以获得较好的精度。英伟达V系列GPU卡中的Tensor Core(上图)也很支持这种操作。因此,在进行大型累加时(batch-norm、softmax),为防止溢出都需要用FP32进行计算,且加法主要被内存带宽限制,对运算速度不敏感,因此不会降低训练速度。另外,在进行Point-wise乘法时,受内存带宽限制。由于算术精度不会影响这些运算的速度,用FP16或者FP32都可以。
2. 实验结果
从下图的Accuracy结果可以看到,混合精度基本没有精度损失:

Loss scale的效果:

3. 如何应用MP
Pytorch可以使用英伟达的开源框架APEX,支持混合进度和分布式训练:
model, optimizer = amp.initialize(model, optimizer, opt_level="O1")
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward() Tensorflow就更简单了,已经有官方支持,只需要训练前加一句:
export TF_ENABLE_AUTO_MIXED_PRECISION=1
# 或者
import os
os.environ['TF_ENABLE_AUTO_MIXED_PRECISION'] = '1'
参考:
