不同预训练模型的总结对比
持续更新 2020-06-28
目录
structBERT(Alice)
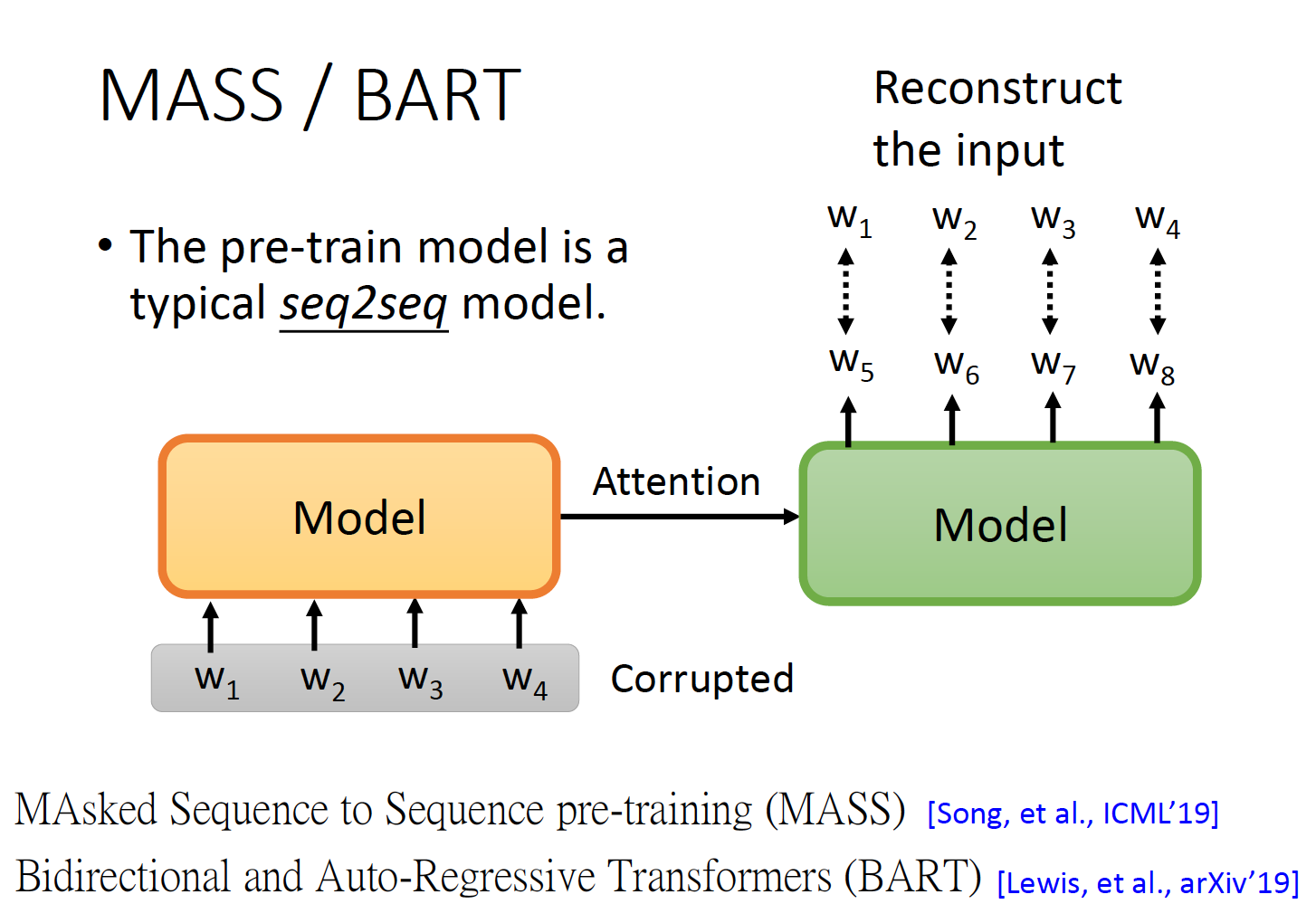
BART
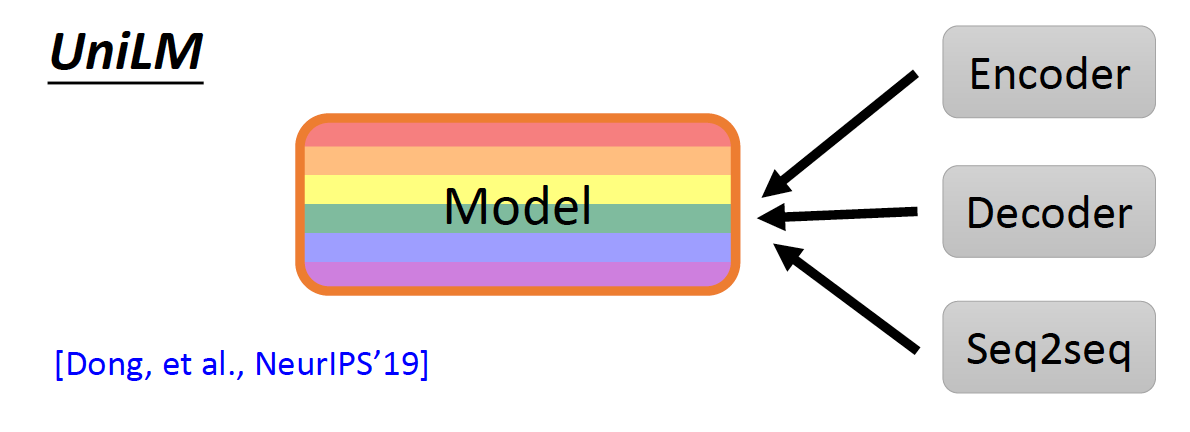
UniLM
T5
C4
Smaller Model:
Distill BERT
Q8BERT
BERT家族
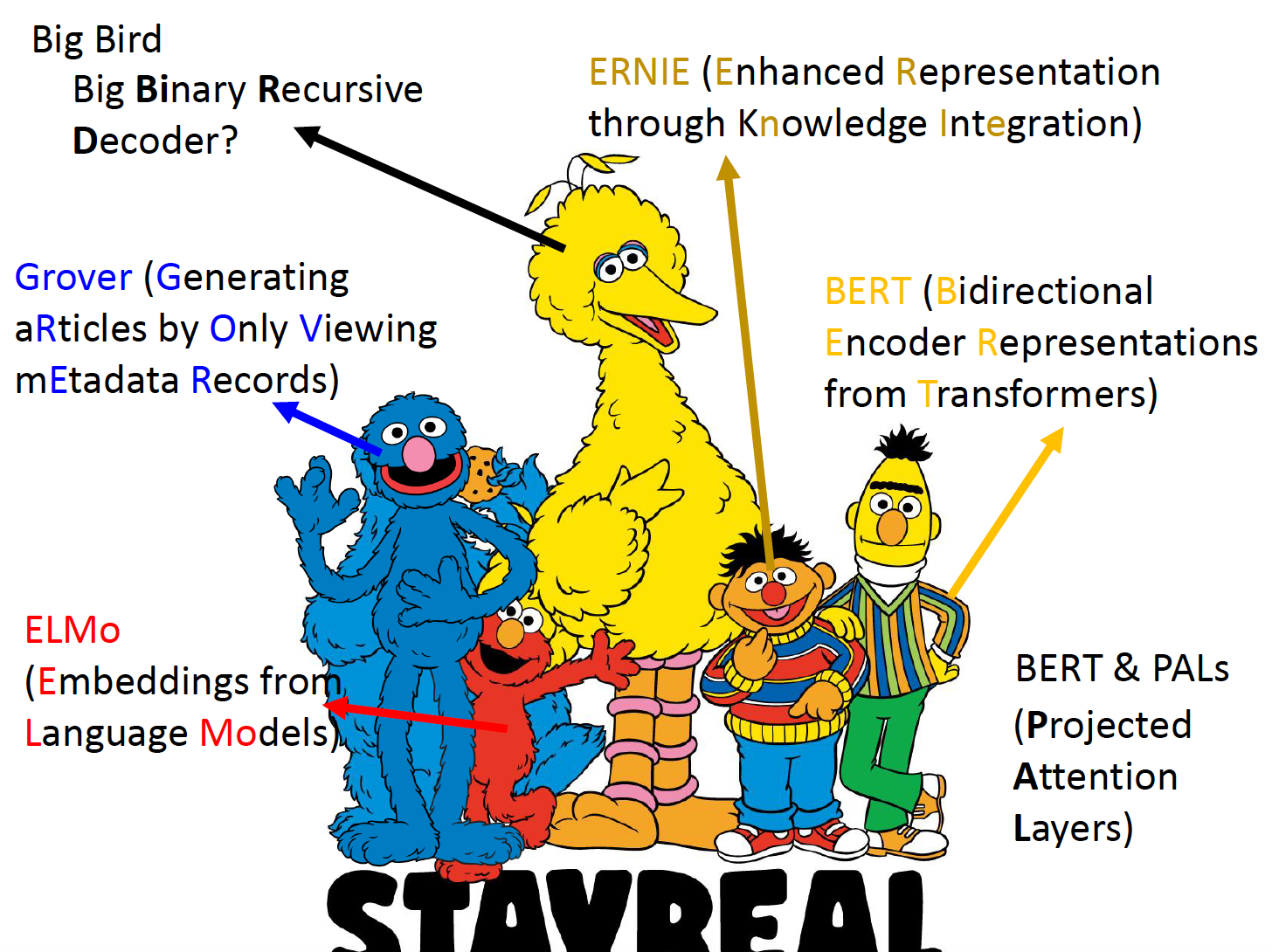
图片来源:李宏毅老师的课程
ELMO
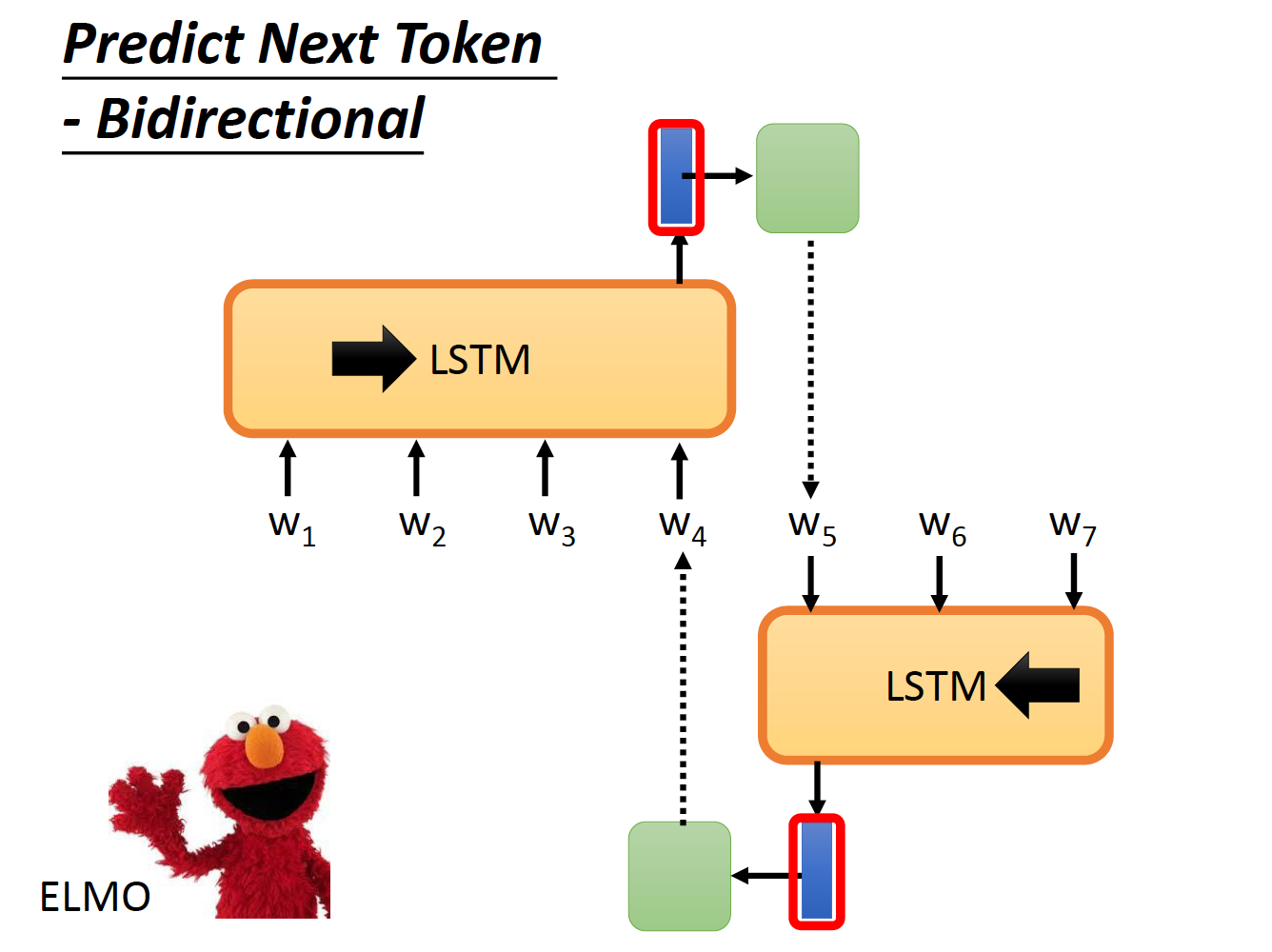
Encoder是双向的LSTM。
BERT
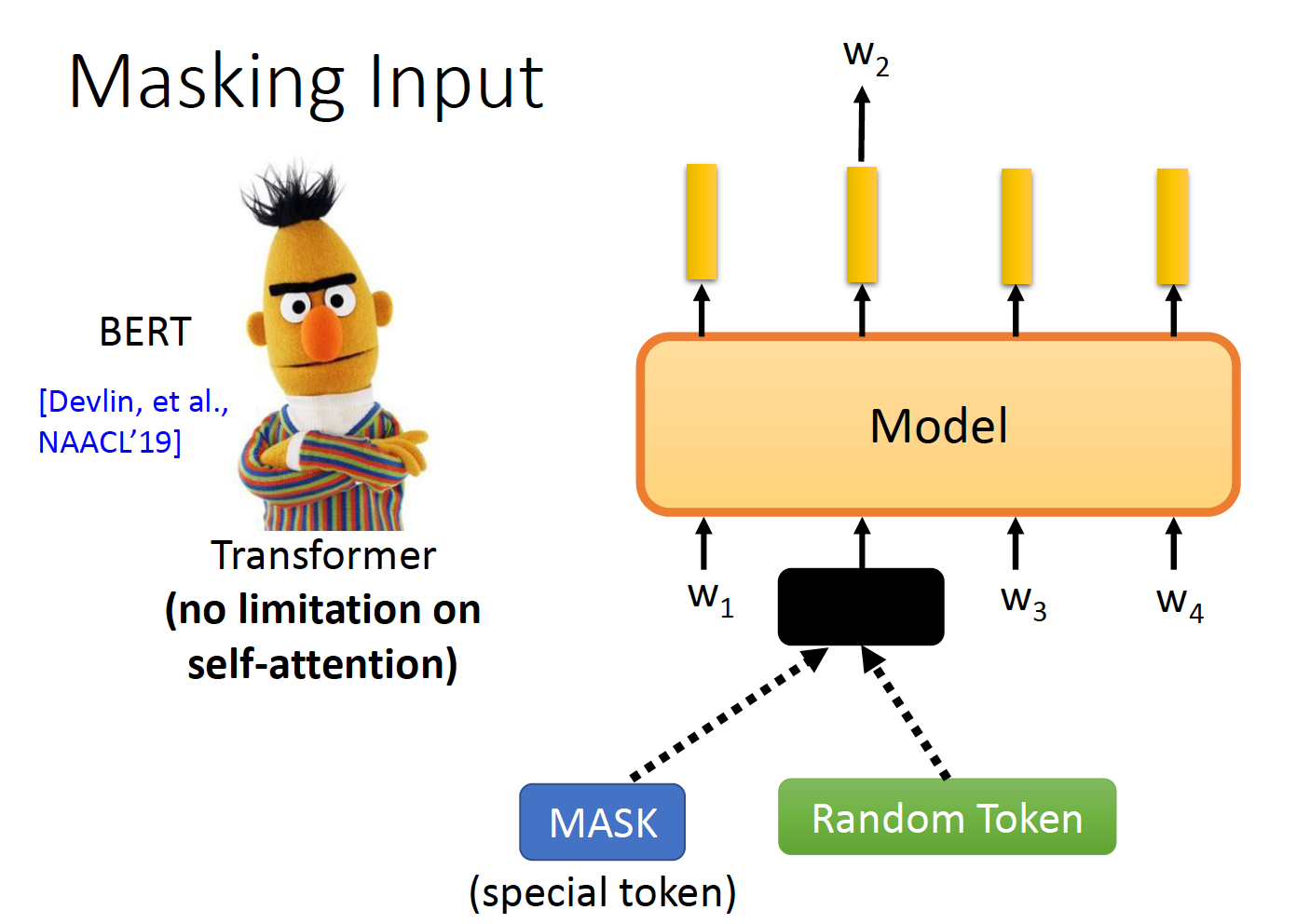
encoder由ELMO的LSTM换成了Transformer。
mask机制
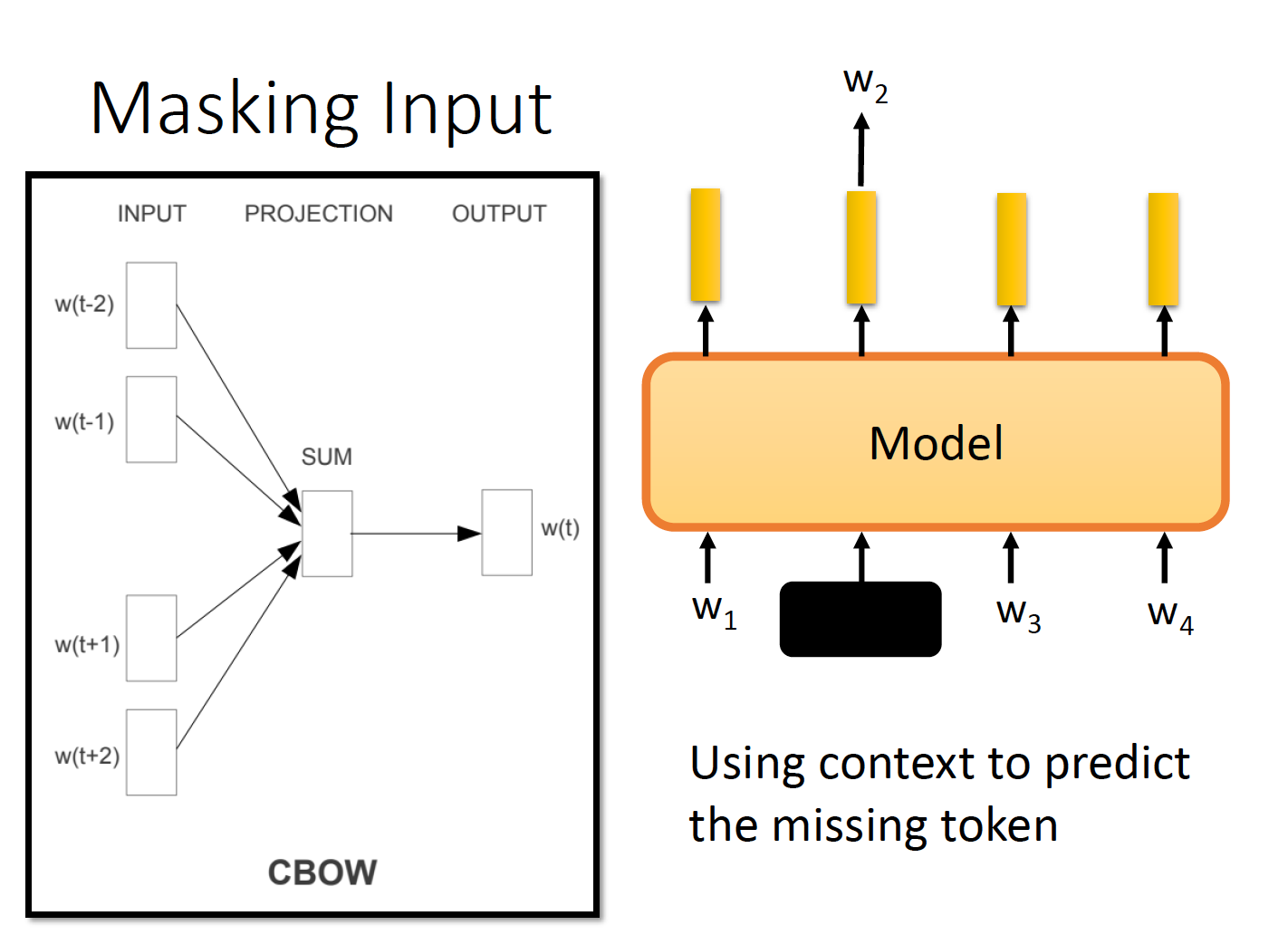
让模型去预测被mask or 被替换的token。
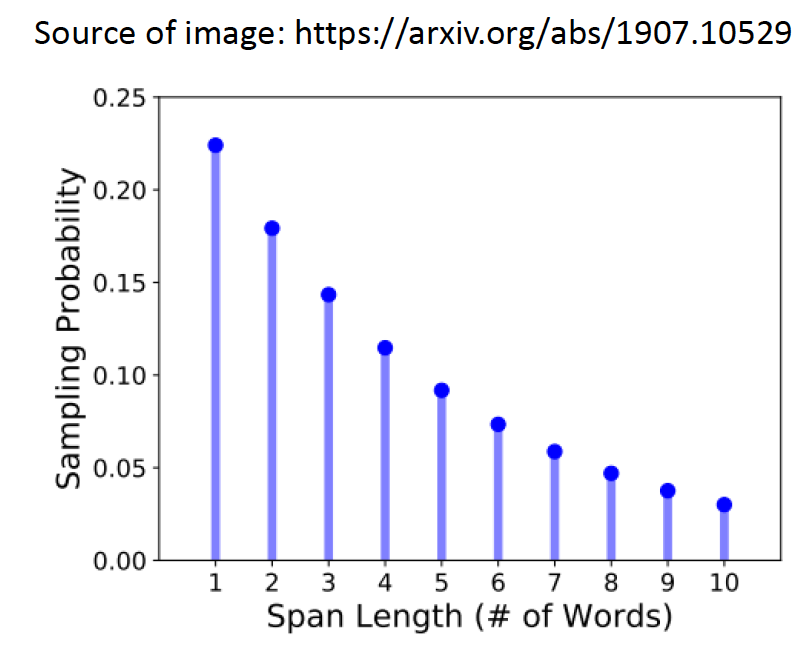
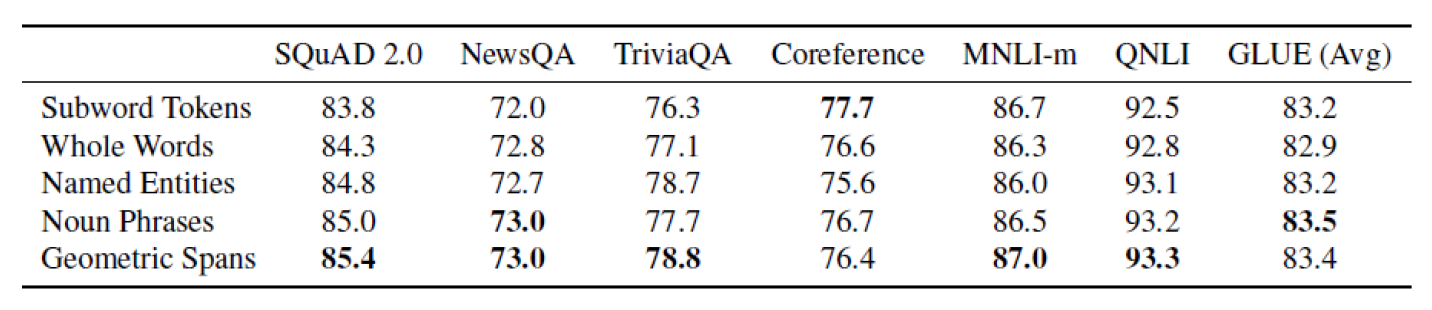
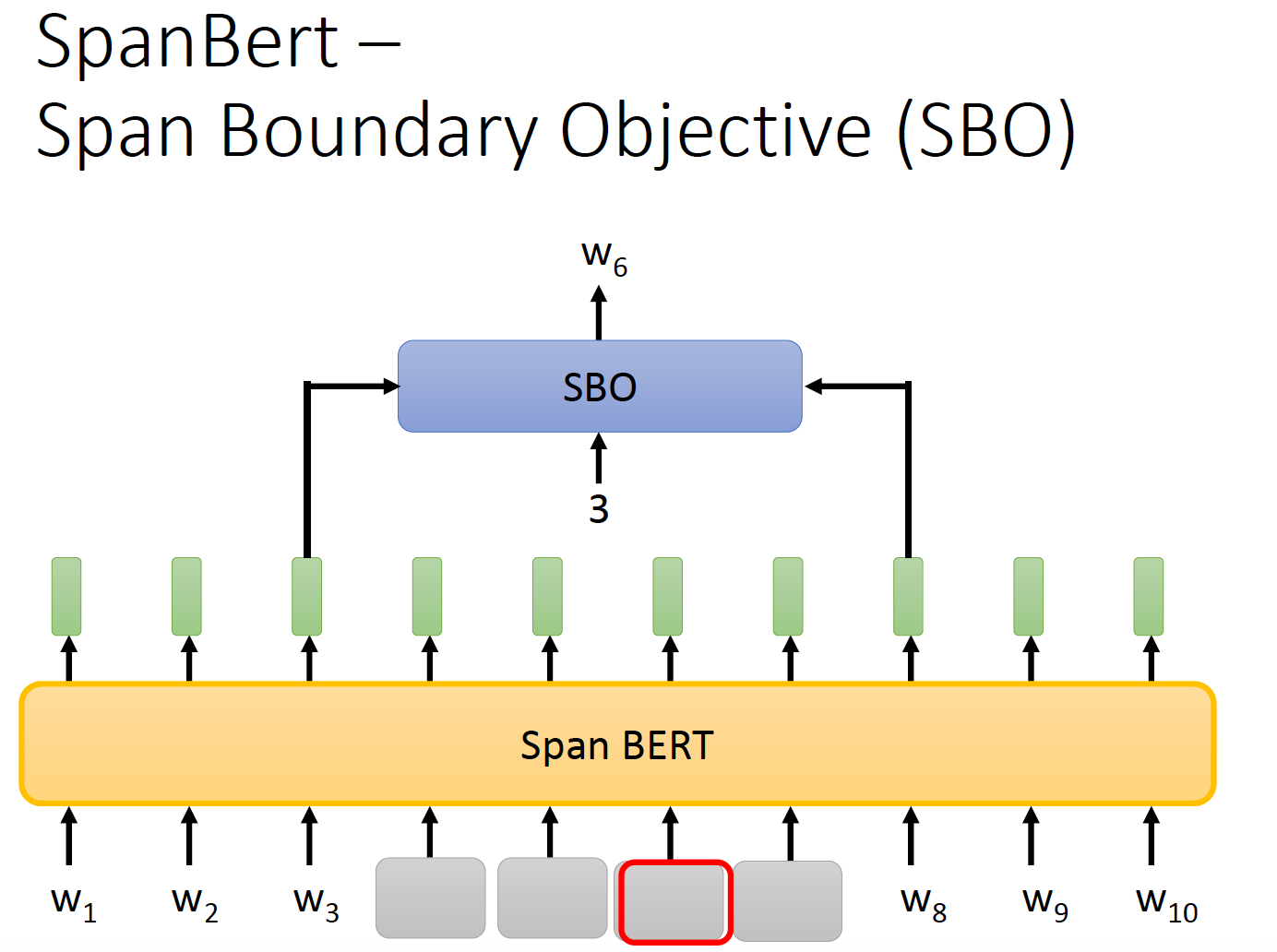
SpanBert
不同长度的『mask』。这里不用[mask],而是用空格。
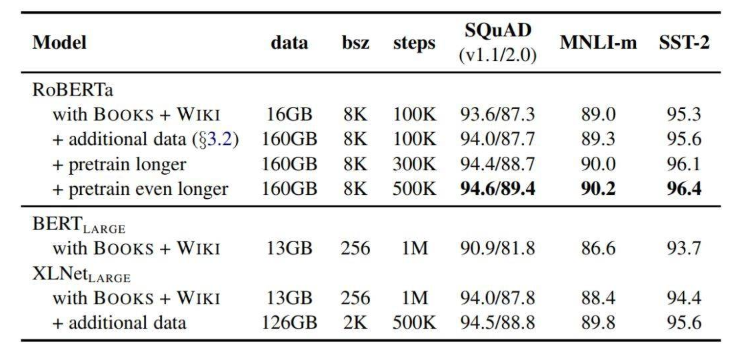
RoBERTa
RoBERTa 在模型规模、算力和数据上,主要比 BERT 提升了以下几点:
-
更大的模型参数量(从 RoBERTa 论文提供的训练时间来看,模型使用 1024 块 V 100 GPU 训练了 1 天的时间)
-
更多的训练数据(包括:CC-NEWS 等在内的 160GB 纯文本)
此外如下所示,RoBERTa 还有很多训练方法上的改进。

1. 动态掩码:mask更随机
BERT 依赖随机掩码和预测 token。原版的 BERT 实现在数据预处理期间执行一次掩码,得到一个静态掩码。而 RoBERTa 使用了动态掩码:每次向模型输入一个序列时都会生成新的掩码模式。这样,在大量数据不断输入的过程中,模型会逐渐适应不同的掩码策略,学习不同的语言表征。
static masking: 原本的BERT采用的是static mask的方式,就是在create pretraining data中,先对数据进行提前的mask,为了充分利用数据,定义了dupe_factor,这样可以将训练数据复制dupe_factor份,然后同一条数据可以有不同的mask。注意这些数据不是全部都喂给同一个epoch,是不同的epoch,例如dupe_factor=10, epoch=40, 则每种mask的方式在训练中会被使用4次。
dynamic masking: 每一次将训练example喂给模型的时候,才进行随机mask。
2. 更大批次
RoBERTa 在训练过程中使用了更大的批数量。研究人员尝试过从 256 到 8000 不等的批数量。
3. 文本编码
Byte-Pair Encoding(BPE)是字符级和词级别表征的混合,支持处理自然语言语料库中的众多常见词汇。
原版的 BERT 实现使用字符级别的 BPE 词汇,大小为 30K,是在利用启发式分词规则对输入进行预处理之后学得的。Facebook 研究者没有采用这种方式,而是考虑用更大的 byte 级别 BPE 词汇表来训练 BERT,这一词汇表包含 50K 的 subword 单元,且没有对输入作任何额外的预处理或分词。
基于bytes的编码可以有效防止unknown问题。
中文RoBERTa
中文预训练RoBERTa-zh模型,使用了大量文本进行数据训练,包含新闻、社区问答、百科数据等。
作者按照 RoBERTa 论文主要精神训练了这一模型,并进行了多项改进和调整:
-
数据生成方式和任务改进:取消下一个句子预测,并且数据从一个文档中连续获得 (见:Model Input Format and Next Sentence Prediction,DOC-SENTENCES);
-
更大更多样性的数据:使用 30G 中文训练,包含 3 亿个句子,100 亿个字 (即 token)。由于新闻、社区讨论、多个百科,保罗万象,覆盖数十万个主题;
-
训练更久:总共训练了近 20 万,总共见过近 16 亿个训练数据 (instance); 在 Cloud TPU v3-256 上训练了 24 小时,相当于在 TPU v3-8(128G 显存) 上需要训练一个月;
-
更大批次:使用了超大(8k)的批次 batch size;
-
调整优化器参数;
-
使用全词 mask(whole word mask)。

图注:全词 Mask 和其他文本处理方法对比。
ERNIE2
持续学习的机制(continual learning)
持续学习包括持续构建预训练任务和增量多任务学习两个部分,具体如下图:
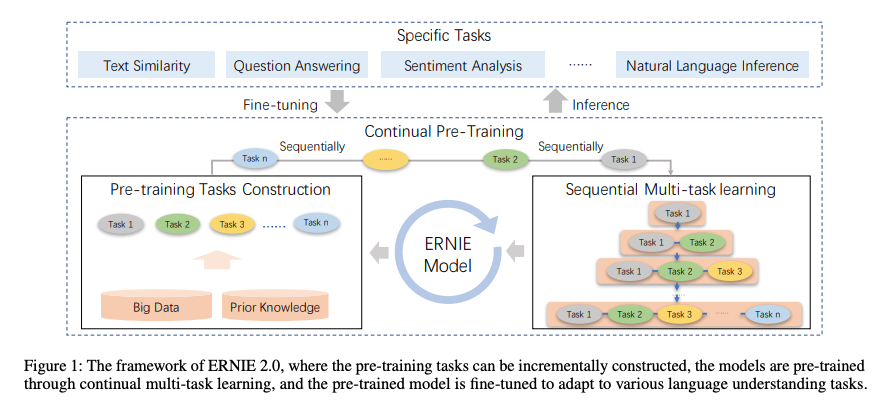
连续预训练包含一系列共享的文本编码层来编码上下文信息,编码器的参数能通过所有预训练任务更新。
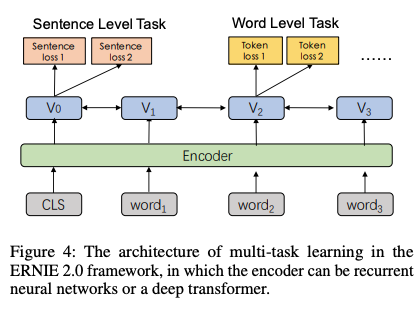
Multi-Level & More Task
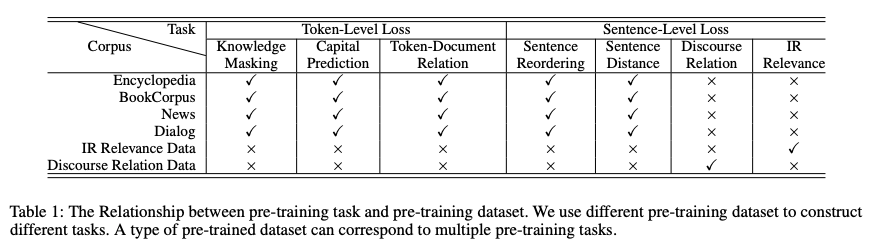
不同于ERNIE1仅有词级别的Pretraining Task,ERNIE2考虑了词级别、结构级别和语义级别3类Pretraining Task,词级别包括Knowledge Masking(短语Masking)、Capitalization Prediction(大写预测)和Token-Document Relation Prediction(词是否会出现在文档其他地方)三个任务,结构级别包括Sentence Reordering(句子排序分类)和Sentence Distance(句子距离分类)两个任务,语义级别包括Discourse Relation(句子语义关系)和IR Relevance(句子检索相关性)两个任务。三者关系如图:
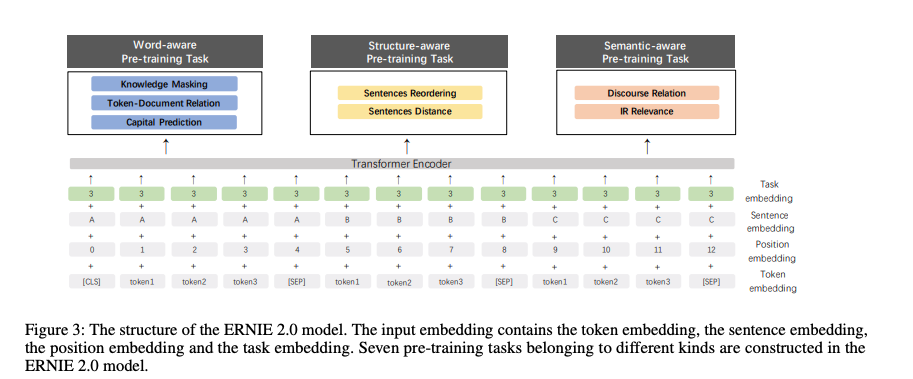
XLNet
XLNet是一种大型双向transformer,它使用的是改进过的训练方法,这种训练方法拥有更大的数据集和更强的计算能力,在20个语言任务中XLNet比BERT的预测指标要更好。
为了改进训练方法,XLNet引入了置换语言建模,其中所有标记都是按随机顺序预测的。 这与BERT的掩蔽语言模型形成对比,后者只预测了掩蔽(15%)标记。 这也颠覆了传统的语言模型,在传统语言模型中,所有的标记都是按顺序而不是按随机顺序预测的。 这有助于模型学习双向关系,从而更好地处理单词之间的关系和衔接。此外使用Transformer XL做基础架构,即使在不统一排序训练的情况下也能表现出良好的性能。
Transformer XL
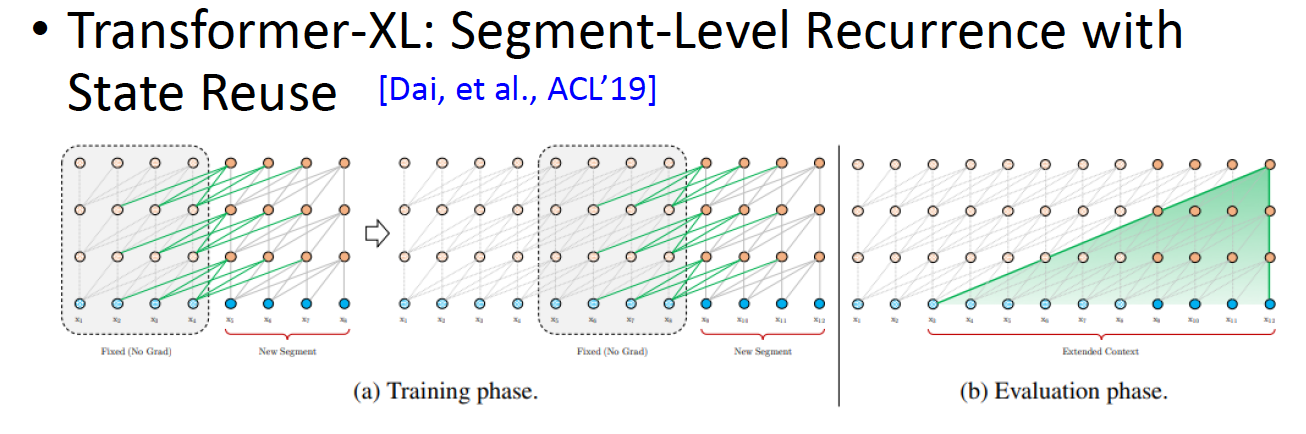
XLNet使用了超过130 GB的文本数据和512 TPU芯片进行训练,运行时间为2.5天,XLNet用于训练的资料库要比BERT大得多。
推荐阅读 XLNet:运行机制及和Bert的异同比较,讲得十分细致。
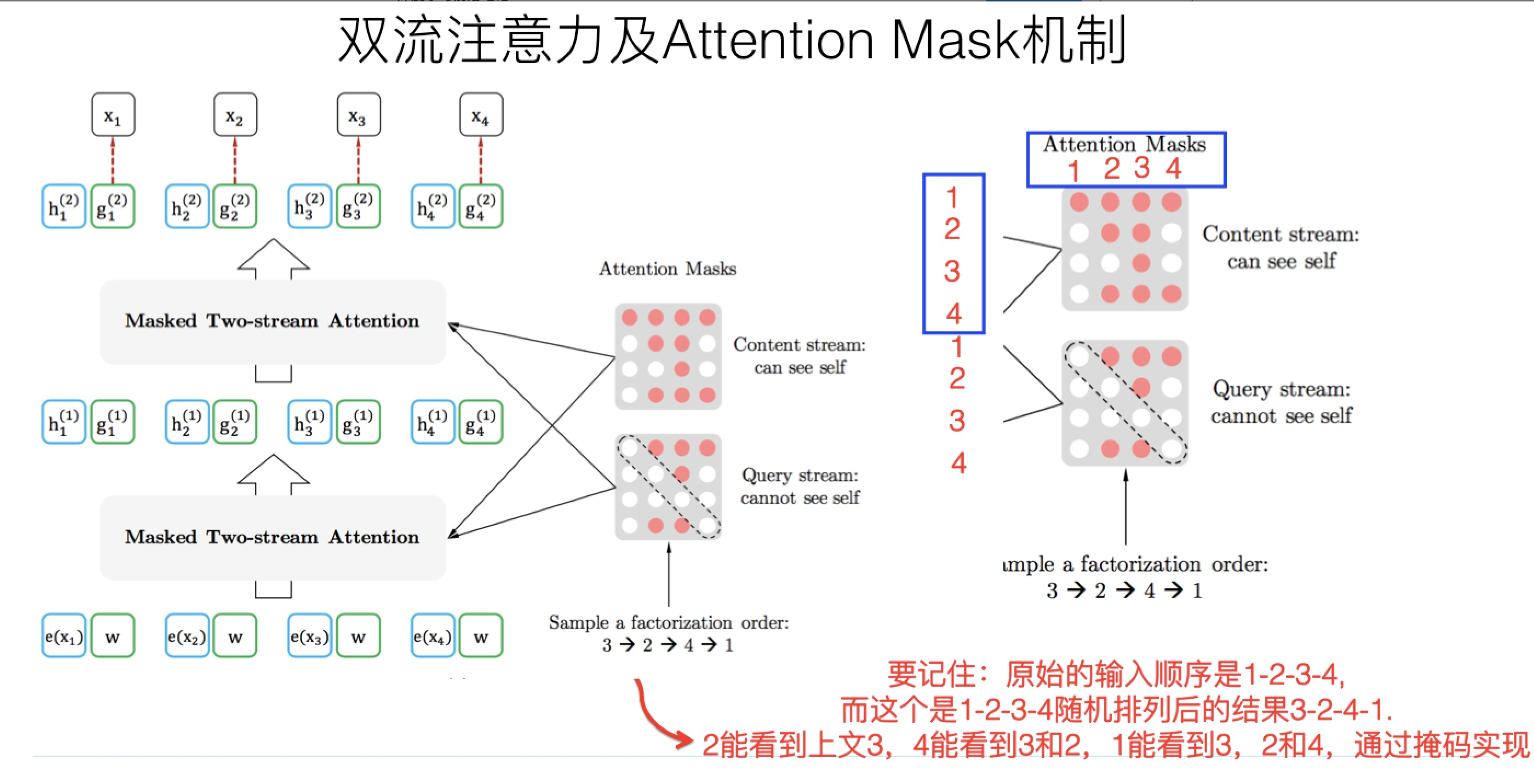
“双流自注意力机制”
一个是内容流自注意力,其实就是标准的Transformer的计算过程;主要是引入了Query流自注意力,就是用来代替Bert的那个[Mask]标记的,因为XLNet希望抛掉[Mask]标记符号,但是比如知道上文单词x1,x2,要预测单词x3,此时在x3对应位置的Transformer最高层去预测这个单词,但是输入侧不能看到要预测的单词x3,Bert其实是直接引入[Mask]标记来覆盖掉单词x3的内容的,等于说[Mask]是个通用的占位符号。而XLNet因为要抛掉[Mask]标记,但是又不能看到x3的输入,于是Query流,就直接忽略掉x3输入了,只保留这个位置信息,用参数w来代表位置的embedding编码。其实XLNet只是扔了表面的[Mask]占位符号,内部还是引入Query流来忽略掉被Mask的这个单词。和Bert比,只是实现方式不同而已。
Attention Mask
引入的Permutation Language Model这种新的预训练目标,本质上和bert的mask标记是类似的。区别主要在于:Bert是直接在输入端显示地通过引入Mask标记,在输入侧隐藏掉一部分单词,让这些单词在预测的时候不发挥作用,要求利用上下文中其它单词去预测某个被Mask掉的单词;而XLNet则抛弃掉输入侧的Mask标记,通过Attention Mask机制,在Transformer内部随机Mask掉一部分单词(这个被Mask掉的单词比例跟当前单词在句子中的位置有关系,位置越靠前,被Mask掉的比例越高,位置越靠后,被Mask掉的比例越低),让这些被Mask掉的单词在预测某个单词的时候不发生作用。
XLNet相对Bert性能提升因素:
1. 与Bert采取De-noising Autoencoder方式不同的新的预训练目标:Permutation Language Model(简称PLM);这个可以理解为在自回归LM模式下,如何采取具体手段,来融入双向语言模型。这个是XLNet在模型角度比较大的贡献,确实也打开了NLP中两阶段模式潮流的一个新思路。
2. 引入了Transformer-XL的主要思路:相对位置编码以及分段RNN机制。实践已经证明这两点对于长文档任务是很有帮助的;
3. 加大增加了预训练阶段使用的数据规模;Bert使用的预训练数据是BooksCorpus和英文Wiki数据,大小13G。XLNet除了使用这些数据外,另外引入了Giga5,ClueWeb以及Common Crawl数据,并排掉了其中的一些低质量数据,大小分别是16G,19G和78G。可以看出,在预训练阶段极大扩充了数据规模,并对质量进行了筛选过滤。这个明显走的是GPT2.0的路线。
UniLM
Smaller Model
模型压缩方法:
- 模型剪枝
- 知识蒸馏
- 参数量化
- 框架设计
Excellent reference: all-the-ways-to-compress-BERT
Albert
A Lite Bert For Self-Supervised Learning Language Representations
https://github.com/brightmart/albert_zh
ALBERT模型是BERT的改进版,与最近其他State of the art的模型不同的是,这次是预训练小模型,效果更好、参数更少。
它对BERT进行了三个改造 Three main changes of ALBert from Bert:
1)词嵌入向量参数的因式分解 Factorized embedding parameterization
O(V * H) to O(V * E + E * H)
如以ALBert_xxlarge为例,V=30000, H=4096, E=128
那么原先参数为V * H= 30000 * 4096 = 1.23亿个参数,现在则为V * E + E * H = 30000*128+128*4096 = 384万 + 52万 = 436万,
词嵌入相关的参数变化前是变换后的28倍。
2)跨层参数共享 Cross-Layer Parameter Sharing
参数共享能显著减少参数。共享可以分为全连接层、注意力层的参数共享;注意力层的参数对效果的减弱影响小一点。
3)段落连续性任务 Inter-sentence coherence loss.
使用段落连续性任务。正例,使用从一个文档中连续的两个文本段落;负例,使用从一个文档中连续的两个文本段落,但位置调换了。
避免使用原有的NSP任务,原有的任务包含隐含了预测主题这类过于简单的任务。
We maintain that inter-sentence modeling is an important aspect of language understanding, but we propose a loss
based primarily on coherence. That is, for ALBERT, we use a sentence-order prediction (SOP) loss, which avoids topic
prediction and instead focuses on modeling inter-sentence coherence. The SOP loss uses as positive examples the
same technique as BERT (two consecutive segments from the same document), and as negative examples the same two
consecutive segments but with their order swapped. This forces the model to learn finer-grained distinctions about
discourse-level coherence properties.
其他变化:
1)去掉了dropout Remove dropout to enlarge capacity of model.
最大的模型,训练了1百万步后,还是没有过拟合训练数据。说明模型的容量还可以更大,就移除了dropout
(dropout可以认为是随机的去掉网络中的一部分,同时使网络变小一些)
We also note that, even after training for 1M steps, our largest models still do not overfit to their training data.
As a result, we decide to remove dropout to further increase our model capacity.
其他型号的模型,在我们的实现中我们还是会保留原始的dropout的比例,防止模型对训练数据的过拟合。
2)为加快训练速度,使用LAMB做为优化器 Use LAMB as optimizer, to train with big batch size
使用了大的batch_size来训练(4096)。 LAMB优化器使得我们可以训练,特别大的批次batch_size,如高达6万。
3)使用n-gram(uni-gram,bi-gram, tri-gram)来做遮蔽语言模型 Use n-gram as make language model
即以不同的概率使用n-gram,uni-gram的概率最大,bi-gram其次,tri-gram概率最小。
本项目中目前使用的是在中文上做whole word mask,稍后会更新一下与n-gram mask的效果对比。n-gram从spanBERT中来。
训练语料/训练配置 Training Data & Configuration
30g中文语料,超过100亿汉字,包括多个百科、新闻、互动社区。
预训练序列长度sequence_length设置为512,批次batch_size为4096,训练产生了3.5亿个训练数据(instance);每一个模型默认会训练125k步,albert_xxlarge将训练更久。
作为比较,roberta_zh预训练产生了2.5亿个训练数据、序列长度为256。由于albert_zh预训练生成的训练数据更多、使用的序列长度更长,
我们预计albert_zh会有比roberta_zh更好的性能表现,并且能更好处理较长的文本。
训练使用TPU v3 Pod,我们使用的是v3-256,它包含32个v3-8。每个v3-8机器,含有128G的显存。
使用相关
宝藏库:
https://github.com/huggingface/transformers
几乎包含所有主流的预训练语言模型,并且使用起来非常便捷。它从 Tokenize、转化为字符的 ID 到最终计算出隐藏向量表征,提供了整套 API,我们可以快速地将其嵌入到各种 NLP 系统中。
但是在使用过程中,我们会发现中文的预训练模型非常少,只有 BERT-Base 提供的那种 hhhh
pytorch-transformers 同时支持导入 TensorFlow 预训练的模型与 PyTorch 预训练的模型,它们俩都可以导入到库中。
参考:
RoBERTa中文预训练模型,你离中文任务的「SOTA」只差个它
RoBERTa、ERNIE2、BERT-wwm-ext和SpanBERT

