Feature map transfer in TinyBert/MobileBert
MobileBert: 自下而上的知识转移: 将 Bottleneck BERT-LARGE teacher 的知识传递给student。
先训练teacher,然后逐步从下网上训练student,要求它一层一层地模仿teacher。
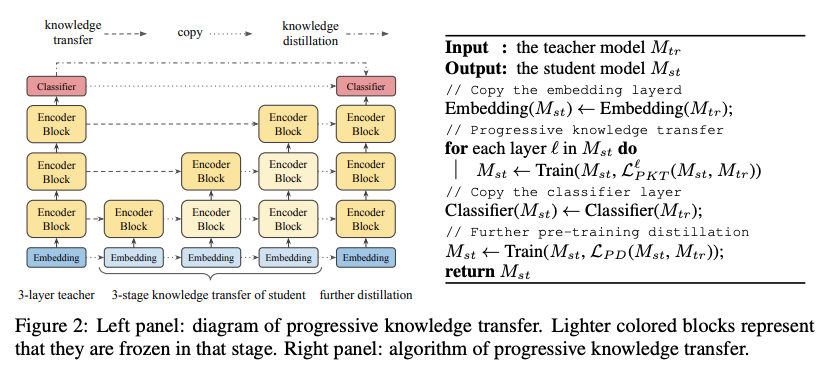
知识转移的渐进过程分为L个阶段,其中L为层数。图2展示了渐进式知识转移的原理图和算法。渐进迁移的思想是在训练学生的(l+1)层时,(l)层已经是最优的了。
由于BERT的中间状态没有软目标分布,我们提出了两个知识转移目标: feature map transfer和attention transfer来训练学生网络。特别地,我们假设老师和学生有相同的1)feature map的大小,2)层的数量,3)attention heads的数量。
FEATURE MAP TRANSFER (FMT)
由于BERT中的每一层仅仅是将前一层的输出作为输入,所以在逐步训练学生网络时,最重要的是每一层的feature maps应该尽可能接近于教师的feature maps,即优化的。其中,以学生与教师归一化特征图的均方误差为目标:
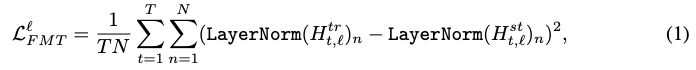
其中l为层索引,T为序列长度,N为特征映射大小。增加层间归一化以稳定层间训练损失。
我们还最小化了特征图转换中均值和方差的两个统计差异:
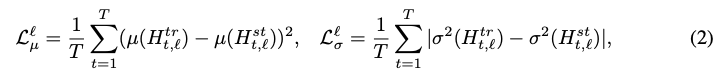
µ和σ2代表均值和方差。实验表明,在BERT中去除层标准化以减少推理延迟时,最小化统计差异是有帮助的(参见4.3节中的更多讨论)。
ATTENTION TRANSFER (AT)
BERT中的注意分布可以检测出词语之间合理的语义和句法关系。
这激发了我们使用来自优化过的教师的“自我注意maps”来帮助训练学生在增强到“feature map transfer”的过程中。特别是,我们最小化了教师和学生的pre-head的(head平均的)注意力分布的kl-散度:
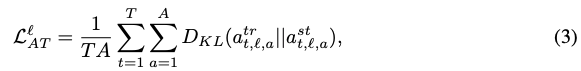
A是attention heads的数目。
TinyBert
作者提出了两个点:针对Transformer结构的知识蒸馏和针对pre-training和fine-tuning两阶段的知识蒸馏。
作者在这里构造了四类损失函数来对模型中各层的参数进行约束来训练模型,具体模型结构如下:
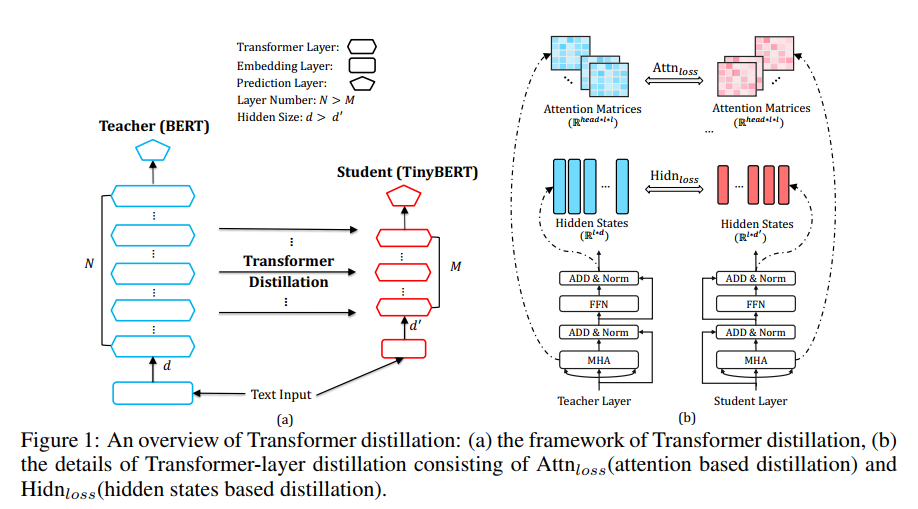
作者构造了四类损失,分别针对embedding layer,attention 权重矩阵,隐层输出,predict layer。可以将这个统一到一个损失函数中:
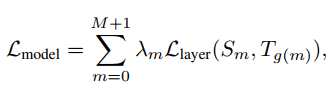
上面式子中𝜆𝑚λm表示每一层对应的系数,𝑆𝑚Sm表示studnet网络的第m层,𝑇𝑔(𝑚)Tg(m)表示teacher网络的第n层,其中𝑛=𝑔(𝑚)n=g(m)。并且有𝑔(0)=0g(0)=0,𝑔(𝑀+1)=𝑁+1g(M+1)=N+1,0表示embedding layer,M+1和N+1表示perdict layer。
针对上面四层具体的损失函数表达式如下:
attention 权重矩阵
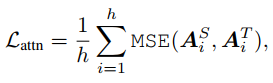
h为multi attention中头数
隐层输出
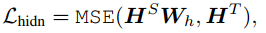
因为student网络的隐层大小通常会设置的比teacher的小,因此为了在计算时维度一致,这里用一个矩阵𝑊ℎWh将student的隐层向量线性映射到和teacher同样的空间下。
embedding layer

𝑊𝑠Ws同理上。
以上三种损失函数都采用了MSE,主要是为了将模型的各项参数对齐。
predict layer
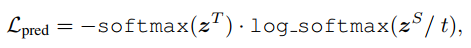
predict layer也就是softmax层,在这里的损失函数是交叉熵,t是温度参数,在这里设置为1。
以上四种损失函数是作者针对transformer提出的知识蒸馏方法。除此之外作者认为除了对pre-training蒸馏之外,在fine-tuning时也利用teacher的知识来训练模型可以取得在下游任务更好的效果。因此作者提出了两阶段知识蒸馏,如下图所示:
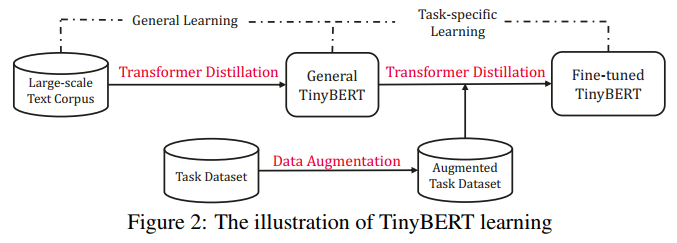
本质上就是在pre-training蒸馏一个general TinyBERT,然后再在general TinyBERT的基础上利用task-bert上再蒸馏出fine-tuned TinyBERT。
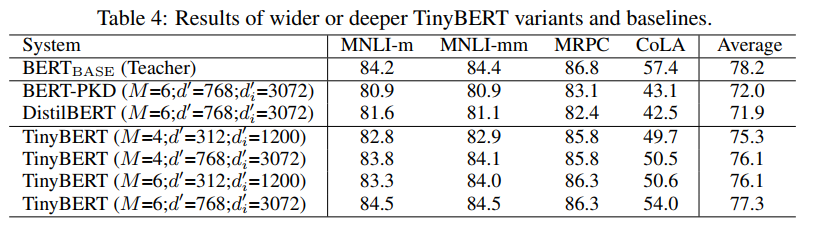
作者给出了TinyBERT的效果:
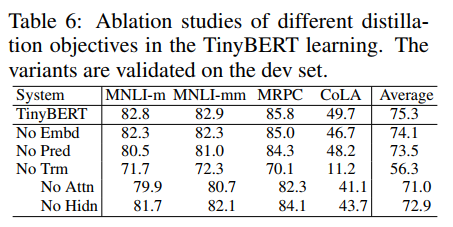
另外作者也给出了四种损失对最终结果的贡献:
还有就是关于𝑛=𝑔(𝑚)n=g(m)这个式子中𝑔(𝑚)g(m)怎么选择,假设student的层数为4层,这里的𝑛=𝑔(𝑚)=3𝑚n=g(m)=3m,作者将这种称为Uniform-strategy。另外作者还和其他的𝑔(𝑚)g(m)做了对比:

Top-strategy指用teacher最后4层,Bottom-strategy指用前面4层,其实这里的映射函数,我感觉可能还有更优的方案,例如取平均,或者用attention来做,可能效果会更好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号