论文阅读 | Compressing Large-Scale Transformer-Based Models: A Case Study on BERT
Transefomer-based 的预处理模型往往很消耗资源,对运算性能要求极高,还有严格的延迟需求。
潜在补救方法:模型压缩。
这篇文章主要讲如何压缩Transformers,重点关注BERT。使用不同的方法对attention层 全连接层等不同部分的压缩会有不同的效果,来看看作者后面怎么说。
对BERT的分解与分析
BERT主要有两个训练目标: (1) Masked Language Model (MLM), 学习预测句子内容 (2) Next Sentence Prediction(NSP), 学习预测两个句子之间的关系
ALBERT提出了Sentence-order prediction (SOP)来取代NSP。具体来说,其正例与NSP相同,但负例是通过选择一篇文档中的两个连续的句子并将它们的顺序交换构造的。这样两个句子就会有相同的话题,模型学习到的就更多是句子间的连贯性。
BERT的输入给到WordPiece tokens [Wu et al., 2016] 来得到更小的词表,并且,在出现词汇表外(OOV)单词时变得更加健壮。
[CLS]放在句子开始前,[SEP]是句对任务中两个句子的分隔符。每个WordPiece token输入被表示为三个向量,token/ segment/ position embedding,相加进入model主体。
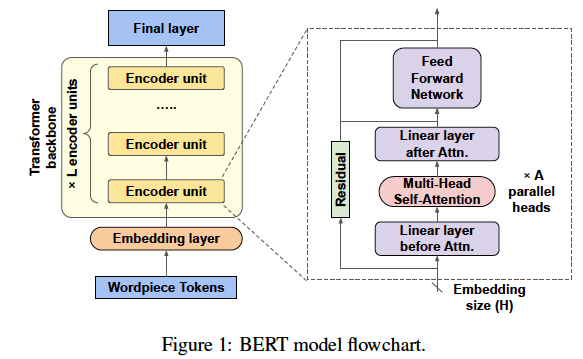
每个transformer层堆叠很多编码器单元,每个编码器包含两个主要子单元:self-attention和前向反馈网络FFN,通过残差连接。每个self-attention包含全连接层、多头multi-head self-attention层、全连接层(前后都有),FFN只包含全连接层。
BERT模型可以使用指定大小的三个hyper-parameters: 编码器单元(L)的数量、每个嵌入向量的大小(H)和每个self-attention层(a)的attention heads的数量。L和H确定模型的深度和宽度,而A是Transformer的内部hyper-parameter,影响每个编码器可以关注的上下文关系的数量。BERT的两个pre-trained模型:BERTBASE (L = 12; H = 768; A= 12)和BERTLARGE (L = 24; H = 1024; A = 16) 。
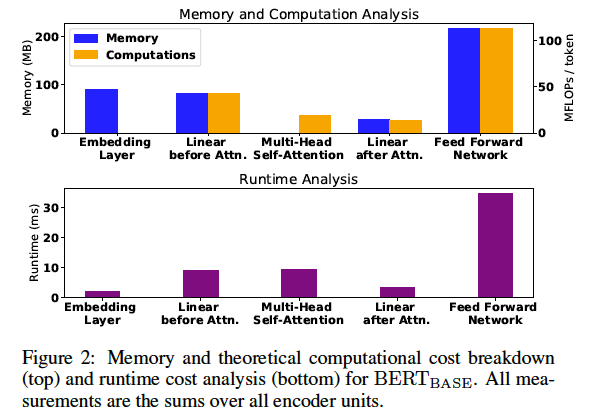
图2分析了BERTBASE模型的不同部分的内存和理论计算要求 (measured in millions of FLOPs, FLOP: 每秒浮点运算次数) 。显然,消耗最大内存和执行最多的浮点运算的部分是FFN。embedding层也需要大量的内存,因为需要较大的vector size(H)表示每个embedding向量。注意,嵌入层为的FLOPS为0,它仅仅是一个查找表,不包括任何算术计算推理时间。
对于self-attention单元,将它分为multi-head self-attention层和线性层(全连接层)。self-attention层消耗零内存,因为他们没有任何可学的参数;但因为有softmax操作,计算成本不是零。每个注意力层周围的线性层会产生额外的内存和计算开销,比FFN相对较小。attention层划分不同的输入给多个头,因此每个头运行在一个低维空间(H/A)。每个attention层之前的线性层的大小大约是attention层之后的三倍,因为每个attention层有三个输入(key value query),只有一个输出。
理论计算开销成本可能不同于实际运行中的推理,这依赖于硬件的运行模式。基于作者对实际运行中的分析,多头self-attention层比理论上更costly。这是因为在这些层的softmax是相当复杂的,而且它的实现为几个矩阵转换矩阵乘法。与此同时,嵌入层的执行时间不是零(因为内存访问成本),但仍相对较小。FFN是整个模型的瓶颈,这与理论分析的结果是一致的。
模型压缩方法
表1对现有方法进行了分类:根据是否需要访问原始BERT训练集(用√标记)或直接在特定于任务的数据集上压缩(用△标记)。
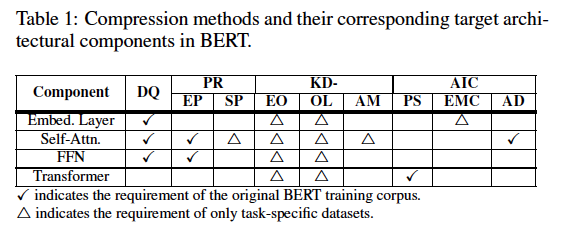
1 数据量化(DQ)
DQ指代表每个模型weight使用更少的bits,从而降低模型的内存占用,降低数值计算的精度。当底层计算设备具备处理低精度数字更快的优化时,DQ可能提高推理速度,如,新一代Nvidia gpu的tensor cores。可编程硬件(如fpga)可以针对任何位宽表示进行专门优化。
DQ通常是适用于所有BERT全连接层的权重(即,嵌入层、线性层、FFN),已被证明是quantization-friendly 量化友好的。谷歌提供的原始BERT模型用32位浮点数表示每个权值。一个简单方法是简单地截断每个32位权重,进行重构,这往往产生较大精度下降。Quantization Aware Training (QAT)方法是更有效地保持模型的准确性。QAT包括额外的培训步骤调整量化权重。QAT在BERT上的应用有,使用fake nodes, 8位整数,和基于hessian混合精度的方法。有趣的是,嵌入层比其他层对量化更敏感,需要更多的比特来保持其准确性。
2 剪枝(PR)
删除不重要的权重 and/or 组件,有时候能使得模型有更鲁棒更好的性能。BERT的剪枝大概分为两类:
(1) Elementwise Pruning (EP)
也成为稀疏剪枝。侧重于PR单个权重,侧重于确定模型中最不重要的权重集合。权重的重要性可以通过它们的绝对值、梯度或设计者定义的其他度量来判断。PR对BERT来说可能是有效的,因为BERT有大量的全连接层。
然而,现有的EP方法仅对Transformer主干进行了实验(即 self-attention和FFN),嵌入层还没有。
(2) Structured Pruning (SP)
结构化剪枝。与EP不同,SP侧重于通过减少和简化BERT模型中的数值组件模块来修剪架构组件:
Attention head pruning:
如第2节所示,在推理时,自我注意层会带来相当大的计算开销,其重要性也常常受到质疑。最近的研究还表明,大多数注意力集中在琐碎的位置关系上,可以用固定的注意力模式代替。因此,减少self-attention层的头的数量可以显著减少模型的执行时间。事实上,原来的模型有16个注意头,但只有1-2注意头每编码器单位达到高精度是可能的。
Encoder unit pruning:
可以通过修剪不太重要的层来减少编码器单元(L)的数量,而不是从头开始训练一个更小的学生模型。Layer dropout 提出了在训练过程中随机丢弃编码单元的层丢失法。这使得在推断过程中提取任意期望深度的更小模型成为可能,因为原始模型已经被训练为对这种修剪具有鲁棒性。
3 知识蒸馏(KD)
KD指使用一个或多个大pre-trained模型(称为老师)的输出(通常是中间层的输出)训练一个较小的模型(称为学生)。在BERT模型中,有多个中间结果学生可以学习,如编码器的输出单位,最后一层logits和attention map。根据学生学习的老师,现有的分类方法如下。
(1) 对编码器输出(EO)进行蒸馏
每个编码单元负责在输入语句中提供单词之间的语义和上下文关系,并逐步改进预训练的表示。因此,我们可以通过减少编码器单元(H)的大小、编码器单元的数量(L)或两者都减少来创建更小的BERT模型。
减少H导致学生中更紧凑的表示。由于大小不同,学生不能直接从老师的输出中学习。为了克服这个问题,学生也学会转换,从而可以实现为down-projecting老师的输出到一个较低的维数,或up-projecting学生的输出为原始维度,性能是相似的。
减少L。即编码器单元的数量,迫使学生中的每个编码器单元从教师中的多个编码器单元序列的行为中学习。蒸馏知识来自于等距的编码器的输出单位老师中捕捉的相对更均匀的信息,与只从编码器蒸馏知识单元末尾学习想必,会产生性能更好的学生模型。
(2) 蒸馏输出的logits (OL)
类似于知识蒸馏cnn,学生可以直接从最后softmax层的logits(即软标签)学习。softmax计算中一个常见hyper-parameter 是temperature,通过在softmax之前扩展logits,控制输出的平滑。因此,这个hyper-parameter决定学生在多大程度上依赖于老师提供的软标签。根据temperature设置,现有解决方案可以进一步分为两类: (i) 尝试不同的温度值 (ii) 固定温度值为1。
注意,这里的学生不一定是小BERT 小Transformer,也能是其它完全不同的网络结构。这种替代可以帮助保持模型的性质,同时大幅压缩。两个常用的替代结构如下:
(i) 用BiLSTM代替Transformer。
BiLSTMs不是同时添加句子中的每个单词,也可以创建双向表示,被认为是较轻的替代品。大部分的工作压缩成BiLSTM的BERT模型一般直接针对一个特定的NLP下游任务。但由于特定任务的数据集较小,从而有使用基于规则的数据增强技术来创建额外的合成训练数据或从多个任务收集数据来训练一个模型等方法。
(ii) 用CNN代替Transformer。
CNN的并行性会提高运行时推理性能。cnn也可以同时向所有方向process。由于其内kernel size越小,一个CNN卷积层只能专注于local context,而Transformer中单个编码器单元关注完整的全局上下文。因此,可以用深CNN网络来替代,可以通过在学生网络使用一个可微的神经结构搜索算法(NAS)获得更轻、更快的模型。
(3) 蒸馏attention maps (AM)
AM指的是通过自我关注层的softmax分布输出,表明各种输入标记之间的上下文依赖关系。BERT中的AM表示可区分的语言关系,例如句子、动词和相应对象之间的相同单词,或者所有格代词和相应的名词之间的相同单词。为了获取这些信息,可以指导学生学习这些语言关系。
4 结构不变压缩 (AIC)
AIC压缩输入模型而不改变其结构。上述DQ就是这样一种方法。在这里,研究了其他类型的AIC。
(1) 参数共享(PS)
ALBERT采用与BERT相同的架构,但是在所有编码器单元中共享权重,从而显著减少了内存占用。此外,ALBERT已经被证明能够实现更大更深的模型训练。例如,BERT的性能在BERTLARGE处达到峰值(BERTXLARGE的性能显著下降),而Albert的性能不断提高,直到更大的ALBERTXXLARGE (L = 12; H = 4096; A = 64)模型。
(2) 嵌入矩阵embedding matrix压缩(EMC)
嵌入矩阵是嵌入层的查找表 lookup table,它的大小大约是整个BERT模型的21%。为了减小嵌入矩阵的大小,一种可能是减小词汇量V,在原始BERT中大约是30k。回忆一下上文,BERT的词汇是使用一个WordPiece tokenizer从训练数据中学习的。当|V|设置成5k,约94%的token在BERT学习到的新词表也存在于原来BERT的词表中。这表明,原始BERT词汇表中的大多数标记可能都是多余的。另一个方法是应用矩阵分解, 通过两个小矩阵的乘积 (V*E和E*H)取代原来V*H 嵌入矩阵。如果E原小于H,就可以减少相当大的内存使用。
(3) 注意层分解(AD)
较低层的多头self-attention层学习local context,而上层的学习全局上下文。对于关注local context的层,计算self-attention整个完整的输入没必要。因此,对于输入为句对的任务,在低层的self-attention可以分解为分别去计算每个句子的self-attention。因为self-attention层不包含权重,该方法只降低计算成本,模型的大小保持不变。此外,由于local上下文输出句子都是彼此独立的计算,该方法还允许更高程度的并行处理和缓存中推断。
压缩效果
主要比较最终模型大小,运行时加速多少,以及它们在各种NLP任务上的准确性/F1分数。
1 数据集和指标
从通用语言理解评估(GLUE)基准和斯坦福问题回答数据集(SQuAD)来看,依赖于以下最常见的任务:MNLI和QQP用于句子对分类,SST-2用于句子分类,SQuAD v1.1用于基于理解的问题回答。在GLUE排行榜中,给出了MNLI和SST-2的精度比较,以及QQP的精度和F1。对于SQuAD v1.1,比较F1(SQuAD leaderboard的官方评价标准)。使用模型大小的下降与MNLI压缩前后精度下降之间的比率来评估常见规模上的方法,因为这是一个重要的权衡。
2 比较和分析
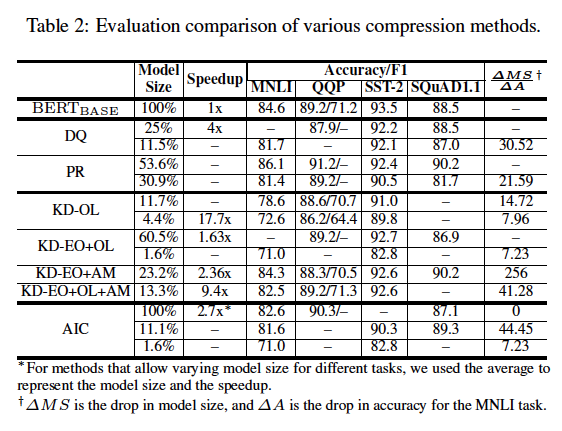
表2比较了BERT压缩方法的有效性。注意一些方法只专注于压缩模型的一部分。有的将BERTBASE作为teacher,有的将BERTLARGE模型作为teacher。对于一致性,所有模型大小和加速效果报告压缩后的最终完整的模型与BERTBASE比较,即使最初是应用于BERTLARGE方法。使用BERTLARGE为teacher进行训练比其他方法有优势。我们也基于他们在不同的任务的绝对精度下降或相对于BERTBASE F1分数比较各种方法。下面是表中几个有趣的趋势。
(1) 精度 vs 模型大小
模型降低与精度降低的比率 △MS/△A 在使用KD-EO时很高,但KD-OL会低很多,因为在精度上有明显的下降,才能达到所需的压缩。相比之下,DQ和PR实现可观的比例因为他们把主要精力集中于减少冗余模型中。然而,KD-AM有很高的比率(KD-EO +AM是最高的),说明KD-AM降低模型的大小几乎不损失精度。
(2) 剪枝和量化
数据量化(DQ)和element-wise修剪(EP)非常适合BERT,性能与其他方法相当。如表2所示,修剪有效,减少了原始伯特模型以其53.6%的大小,而量化成八位减少BERT的原始大小25%,这两个在所有任务只有精度和F1 1 - 2%的下降。然而当被迫提供更高的压缩比,如修剪模型几乎30%的大小或量化2 - 3位(原始尺寸的11%),这些方法会引起精度下降和F1的大幅下降(在某些任务高达4 - 7%)。
(3) 特定的蒸馏
在压缩BERT时有多种方法来提取信息。大变化的最终压缩比(原始模型大小的1.6%到60%)方法在编码器单元输出使用KD(KD-EO)和输出logits(KD-OL)在对范围广泛的解决方案上展示了他们的互补性。我们可以通过减少隐层大小(H)和编码器的数量单位(L)创建一个非常小的BERT student模型(原始尺寸的1.6%)。然后用原始BERT模型的蒸馏来训练它,使它具有良好的性能。我们还发现,KD在attention maps(KD-AM)比KD-EO或KD-OL产生更小但更好的模型,这表明了在学生网络中复制注意力分布的重要性。
(4) 精度损失最小的压缩
一个重要的研究方向是想办法最大化模型压缩不伤害精度/ F1。这些压缩方法依赖于找到原始模型中的冗余。我们观察到的方法如DQ、PR和多种形式的KD可以保留大部分的模型的准确性/ F1(少于1 - 2%下降为所有任务),并以最小的精度损失模型压缩的好。然而,与其他方法相比,这些方法减少模型大小也是有限的(在大多数情况下,是50 - 60%的原始模型大小)。具体来讲,所有BERT压缩方法,EP提供最好的精度/ F1(几乎没有损失),且压缩后模型比例为原规模的53.6%。
(5) 极端的压缩方法
有时模型必须被压缩为部署在内存或延迟绑定边缘设备,同时保留最好的精度。大多数工作在这个方向依靠更换Transformer为一个较轻的替代,然后使用KD-OL训练模型。这些方法能够实现最高的压缩比现有方法中(4 - 11%的原始模型大小)。像预期的那样,这些方法的精度/ F1下降是相当大的(在某些任务如MNLI高达6 - 12%),因为重点是获得极小模型。所有不同的BET的压缩方法收益率,[Zhao et al., 2019]通过减少隐藏的大小(H)和编码器的数量单位(L)生成了最小的模型大小(1.6%的原始模型),但在所有任务精度/ F1遭受巨大的损失(约11 - 13%)。
5 未解决的问题和研究方向
传统的模型压缩方法如DQ和剪枝对BERT很有帮助,但最有效的方法是特定于BERT的,包括变异KD和减少编码器单元的大小和编码器的数量单位的方法。这些方法还提供了对BERT工作方式的深入了解,以及其复杂架构的不同部分的重要性。
重大问题
1. BERT压缩方法是一个非常突出的特征是编码器单元的耦合特性以及编码器本身的内部结构。然而一般在深度学习,一些层模型中可能被压缩更多,从而压缩的方法对待不同的层有同样的处理不是最优的。
2. Transformer主干的本质是强制模型具有大量的参数,这使得BERT的模型压缩更具挑战性。用BiLSTMs和CNNs替换变压器主干的现有工作已经产生了非常高的压缩比,但是精度下降了相当大。
3. 通过增加叠加编码器单元的数量,如MegatronLM、T-NLG等,可以提高Transformer模型的精度。但是,增加这些单元的数量会影响执行时间。
研究方向
1. 对于BERT [Guo et al., 2019]来说,即使在稀疏剪枝的权重矩阵中也存在有趣的结构化模式。如何使用这些模式来取得更好的压缩是一种很有前途的研究方向。
2. 现有的思想压缩自注意层较低的编码器单位,只给了进一步探索解耦编码器单位的motivation。根据每个编码器单元的重要性对其进行压缩,例如,处理不同数量的注意头或编码器单元之间不同的隐层大小,这可能是一个重要的步骤。
3. 解耦,然后单独研究自注意和FFN子单元,对于理解它们提供的渐进改进也很重要。它们的重要性随深度的不同而不同。这意味着某些FFN可能更容易被压缩,即使相应的self-attention不是。
4. 用更轻的体系结构替代Transformer主干的方法的高压缩比表明,这些模型和混合Bi-LSTM/CNN/Transformer模型(比Transformet的参数范围更小)的更复杂变体的进一步探索,以限制精度下降。
5. 其他改进CNN模型性能的想法也可以应用于BERT。例如,在之前网络中采用的并行卷积启发了并行编码器单元的使用,而不是将它们堆叠在一起以获得更好的精度。同样,其他像cross-layer shortcut connections, hourglass architecture, use of NAS,还可以应用于骨干BERT的体系结构。
6. 许多现有的BERT压缩方法都是针对模型的特定部分的。我们可以结合这些互补的方法来实现更好的整体模型压缩,例如,可以将注意力修剪与量化相结合。

