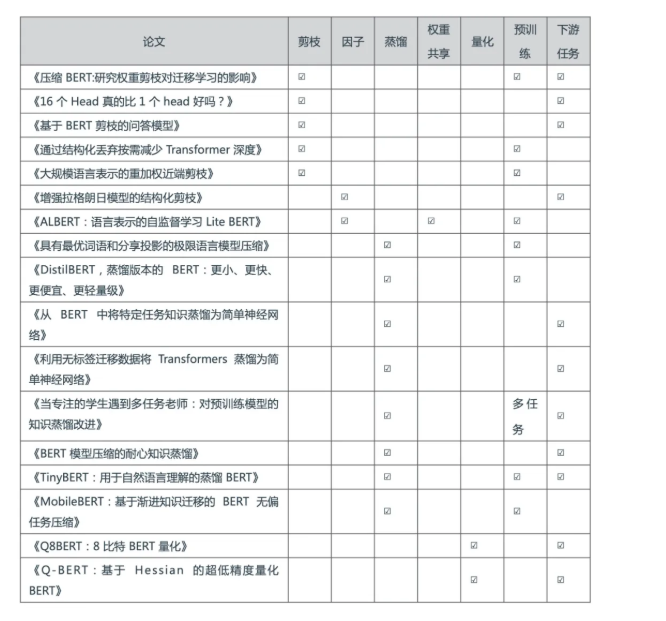
BERT 模型压缩方法
模型压缩可减少受训神经网络的冗余,由于几乎没有 BERT 或者 BERT-Large 模型可直接在 GPU 及智能手机上应用,因此模型压缩方法对于 BERT 的未来的应用前景而言,非常有价值。
一、压缩方法
1、剪枝——即训练后从网络中去掉不必要的部分。
这包括权重大小剪枝、注意力头剪枝、网络层以及其他部分的剪枝等。还有一些方法也通过在训练期间采用正则化的方式来提升剪枝能力(layer dropout)。
2、权重因子分解——通过将参数矩阵分解成两个较小矩阵的乘积来逼近原始参数矩阵。
这给矩阵施加了低秩约束。权重因子分解既可以应用于输入嵌入层(这节省了大量磁盘内存),也可以应用于前馈/自注意力层的参数(为了提高速度)。
===> 分解成两个小矩阵的话参数会变少,例如 5*5 ==> 3*3 3*3
3、知识蒸馏——又名「Student Teacher」。
在预训练/下游数据上从头开始训练一个小得多的 Transformer,正常情况下,这可能会失败,但是由于未知的原因,利用完整大小的模型中的软标签可以改进优化。一些方法还将BERT 蒸馏成如LSTMS 等其他各种推理速度更快的架构。另外还有一些其他方法不仅在输出上,还在权重矩阵和隐藏的激活层上对 Teacher 知识进行更深入的挖掘。
4、权重共享——模型中的一些权重与模型中的其他参数共享相同的值。
例如,ALBERT 对 BERT 中的每个自注意力层使用相同的权重矩阵。
5、量化——截断浮点数,使其仅使用几个比特(这会导致舍入误差)。
模型可以在训练期间,也可以在训练之后学习量化值。
6、预训练和下游任务——一些方法仅仅在涉及到特定的下游任务时才压缩 BERT,也有一些方法以任务无关的方式来压缩 BERT。
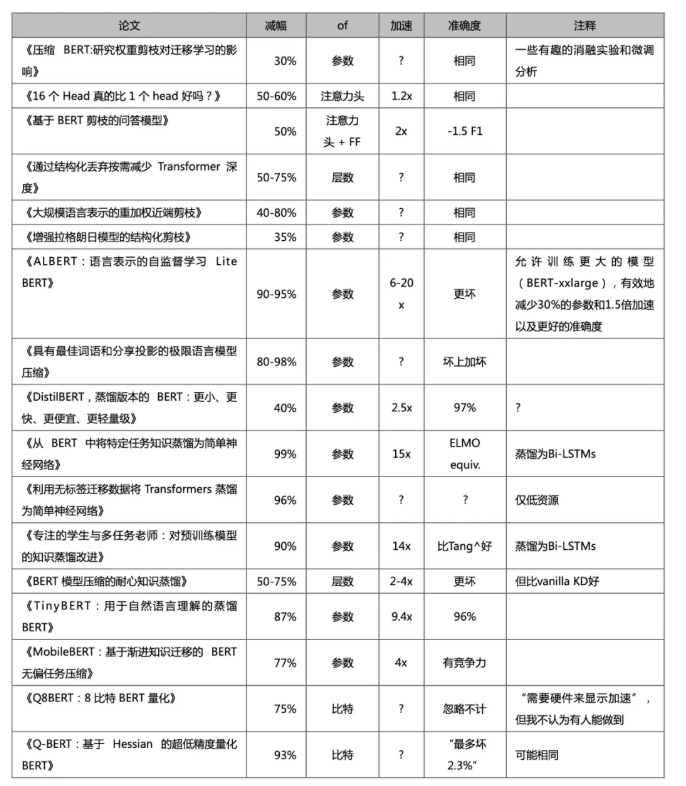
结果比较,同时主要关注以下指标:参数缩减,推理加速和准确性。
若需要选一个赢家,我认为是 ALBERT,DistilBERT,MobileBERT,Q-BERT,LayerDrop和RPP。你也可以将其中一些方法叠加使用 4,但是有些剪枝相关的论文,它们的科学性要高于实用性,所以我们不妨也来验证一番:
相关论文和博文推荐
- 《稀疏 Transformer:通过显式选择集中注意力》(Sparse Transformer: Concentrated Attention Through Explicit Selection),论文链接:https://openreview.net/forum?id=Hye87grYDH)
- 《使用四元数网络进行轻量级和高效的神经自然语言处理》(Lightweight and Efficient Neural Natural Language Processing with Quaternion Networks,论文链接:http://arxiv.org/abs/1906.04393)
- 《自适应稀疏 Transformer》(Adaptively Sparse Transformers,论文链接:https://www.semanticscholar.org/paper/f6390beca54411b06f3bde424fb983a451789733)
- 《压缩 BERT 以获得更快的预测结果》(Compressing BERT for Faster Prediction,博文链接:https://blog.rasa.com/compressing-bert-for-faster-prediction-2/amp/)
最后的话:
1、请注意,并非所有压缩方法都能使模型更快。众所周知,非结构化剪枝很难通过 GPU 并行来加速。其中一篇论文认为,在 Transformers 中,计算时间主要由 Softmax 计算决定,而不是矩阵乘法。
2、期待有更好的模型压缩评价标准。就像 F1之类的。
3、其中一些百分比是根据 BERT-Large 而不是 BERT-Base 衡量的,仅供参考。
4、不同的压缩方法如何交互,是一个开放的研究问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号