Pearson、Spearman秩相关系数、kendall等级相关系数 (附python实现)
目录:
相关系数
相关系数:考察两个事物(在数据里我们称之为变量)之间的相关程度。
如果有两个变量:X、Y,最终计算出的相关系数的含义可以有如下理解:
(1)、当相关系数为0时,X和Y两变量无关系。
(2)、当X的值增大(减小),Y值增大(减小),两个变量为正相关,相关系数在0.00与1.00之间。
(3)、当X的值增大(减小),Y值减小(增大),两个变量为负相关,相关系数在-1.00与0.00之间。
相关系数的绝对值越大,相关性越强,相关系数越接近于1或-1,相关度越强,相关系数越接近于0,相关度越弱。
通常情况下通过以下取值范围判断变量的相关强度:
相关系数 0.8-1.0 极强相关
0.6-0.8 强相关
0.4-0.6 中等程度相关
0.2-0.4 弱相关
0.0-0.2 极弱相关或无相关
Pearson(皮尔逊)相关系数
皮尔逊相关也称为积差相关(或积矩相关)是英国统计学家皮尔逊于20世纪提出的一种计算直线相关的方法。
假设有两个变量X、Y,那么两变量间的皮尔逊相关系数可通过以下公式计算:

以上列出的四个公式等价,其中E是数学期望,cov表示协方差,N表示变量取值的个数。
适用范围
当两个变量的标准差都不为零时,相关系数才有定义,皮尔逊相关系数适用于:
(1)、两个变量之间是线性关系,都是连续数据。
(2)、两个变量的总体是正态分布,或接近正态的单峰分布。
(3)、两个变量的观测值是成对的,每对观测值之间相互独立。
pearson 描述的是线性相关关系,取值[-1, 1]。负数表示负相关,正数表示正相关。在显著性的前提下,绝对值越大,相关性越强。绝对值为0, 无线性关系;绝对值为1表示完全线性相关。
Python 实现
DataFrame.corr(method='pearson', min_periods=1)
参数说明:
method:可选值为{‘pearson’, ‘kendall’, ‘spearman’}
min_periods:样本最少的数据量
返回值:各类型之间的相关系数DataFrame表格。
a) Dataframe.corr(method='pearson'), 返回相关关系矩阵
b) from scipy.stats import normaltest, probplot normaltest(a)返回统计数和检验P值, 样本要求>20。 probplot(np.array(x,y), dist="norm", plot=pylab) 化PP图,若在对角线,则相关性强。
example:
import pandas as pd df = pd.read_csv('demo.csv') ## 计算相关度系数 ## df.corr() #计算pearson相关系数 #df.corr('kendall') #计算kendall相关系数 #df.corr('spearman') #计算spearman相关系数
funded_amnt funded_amnt_inv funded_amnt 1.00000 0.92876 funded_amnt_inv 0.92876 1.00000
Spearman Rank(斯皮尔曼等级)相关系数
在统计学中,斯皮尔曼等级相关系数以Charles Spearman命名,并经常用希腊字母ρ(rho)表示其值。斯皮尔曼等级相关系数用来估计两个变量X、Y之间的相关性,其中变量间的相关性可以使用单调函数来描述。如果两个变量取值的两个集合中均不存在相同的两个元素,那么,当其中一个变量可以表示为另一个变量的很好的单调函数时(即两个变量的变化趋势相同),两个变量之间的ρ可以达到+1或-1。
假设两个随机变量分别为X、Y(也可以看做两个集合),它们的元素个数均为N,两个随即变量取的第i(1<=i<=N)个值分别用Xi、Yi表示。对X、Y进行排序(同时为升序或降序),得到两个元素排行集合x、y,其中元素xi、yi分别为Xi在X中的排行以及Yi在Y中的排行。将集合x、y中的元素对应相减得到一个排行差分集合d,其中di=xi-yi,1<=i<=N。随机变量X、Y之间的斯皮尔曼等级相关系数可以由x、y或者d计算得到,其计算方式如下所示:

以下是一个计算集合中元素排行的例子(仅适用于斯皮尔曼等级相关系数的计算)
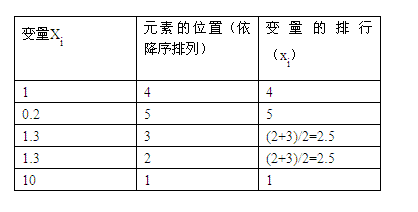
这里需要注意:当变量的两个值相同时,它们的排行是通过对它们位置进行平均而得到的。
适用范围
斯皮尔曼等级相关系数对数据条件的要求没有皮尔逊相关系数严格,只要两个变量的观测值是成对的等级评定资料,或者是由连续变量观测资料转化得到的等级资料,不论两个变量的总体分布形态、样本容量的大小如何,都可以用斯皮尔曼等级相关系数来进行研究。
a) Dataframe.corr(method='spearman'), 返回相关关系矩阵 b) from scipy.stats import spearmanr spearmanr(array)返回 Pearson 系数和检验P值, 样本要求>20。
Kendall Rank(肯德尔等级)相关系数
在统计学中,肯德尔相关系数是以Maurice Kendall命名的,并经常用希腊字母τ(tau)表示其值。肯德尔相关系数是一个用来测量两个随机变量相关性的统计值。一个肯德尔检验是一个无参数假设检验,它使用计算而得的相关系数去检验两个随机变量的统计依赖性。肯德尔相关系数的取值范围在-1到1之间,当τ为1时,表示两个随机变量拥有一致的等级相关性;当τ为-1时,表示两个随机变量拥有完全相反的等级相关性;当τ为0时,表示两个随机变量是相互独立的。
假设两个随机变量分别为X、Y(也可以看做两个集合),它们的元素个数均为N,两个随即变量取的第i(1<=i<=N)个值分别用Xi、Yi表示。X与Y中的对应元素组成一个元素对集合XY,其包含的元素为(Xi, Yi)(1<=i<=N)。当集合XY中任意两个元素(Xi, Yi)与(Xj, Yj)的排行相同时(也就是说当出现情况1或2时;情况1:Xi>Xj且Yi>Yj,情况2:Xi<Xj且Yi<Yj),这两个元素就被认为是一致的。当出现情况3或4时(情况3:Xi>Xj且Yi<Yj,情况4:Xi<Xj且Yi>Yj),这两个元素被认为是不一致的。当出现情况5或6时(情况5:Xi=Xj,情况6:Yi=Yj),这两个元素既不是一致的也不是不一致的。
这里有三个公式计算肯德尔相关系数的值:
公式一:
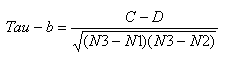
其中C表示XY中拥有一致性的元素对数(两个元素为一对);D表示XY中拥有不一致性的元素对数。
注意:这一公式仅适用于集合X与Y中均不存在相同元素的情况(集合中各个元素唯一)。
公式二:
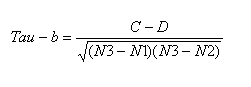
注意:这一公式适用于集合X或Y中存在相同元素的情况(当然,如果X或Y中均不存在相同的元素时,公式二便等同于公式一)。
其中C、D与公式一中相同;
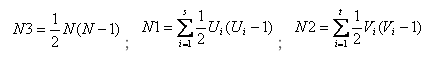
N1、N2分别是针对集合X、Y计算的,现在以计算N1为例(N2的计算可以类推,在集合Y的基础上计算而得):
X集合中所有重复元素个数:将X中的相同元素分别组合成小集合,s表示集合X中拥有的小集合数(例如X包含元素:1 2 3 4 3 3 2,那么这里得到的s则为2,因为只有2、3有相同元素),Ui表示第i个小集合所包含的元素数。
公式三:
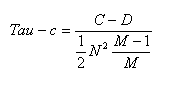
注意:这一公式中没有再考虑集合X、或Y中存在相同元素给最后的统计值带来的影响。公式三的这一计算形式仅适用于用表格表示的随机变量X、Y之间相关系数的计算(下面将会介绍)。
参数M稍后会做介绍。
通常人们会将两个随机变量的取值制作成一个表格,例如有10个样本,对每个样本进行两项指标测试X、Y(指标X、Y的取值均为1到3)。根据样本的X、Y指标取值,得到以下二维表格(表1):
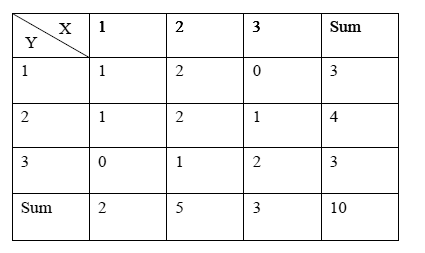
由表1可以得到X及Y的可以以集合的形式表示为:
X={1, 1, 2, 2, 2, 2, 2, 3, 3, 3};
Y={1, 2, 1, 1, 2, 2, 3, 2, 3, 3};
得到X、Y的集合形式后就可以使用以上的公式一或公式二计算X、Y的肯德尔相关系数了(注意公式一、二的适用条件)。
这里需要注意的是:公式二也可以用来计算表格形式表示的二维变量的肯德尔相关系数,不过它一般用来计算由正方形表格表示的二维变量的肯德尔相关系数,公式三则只是用来计算由长方形表格表示的二维变量的Kendall相关系数。这里给出公式三中字母M的含义,M表示长方形表格中行数与列数中较小的一个。表1的行数及列数均为三。
适用范围
肯德尔相关系数与斯皮尔曼相关系数对数据条件的要求相同。
a) Dataframe.corr(method='kendall'), 返回相关关系矩阵 b) from scipy.stats import kendalltau kendalltau(x, y) 返回系数和P值
example
from pandas import DataFrame import pandas as pd x=[a for a in range(100)] #构造一元二次方程,非线性关系 def y_x(x): return 2*x**2+4 y=[y_x(i) for i in x] data=DataFrame({'x':x,'y':y}) #查看data的数据结构 data.head() Out[34]: x y 0 0 4 1 1 6 2 2 12 3 3 22 4 4 36 data.corr() Out[35]: x y x 1.000000 0.967736 y 0.967736 1.000000 data.corr(method='spearman') Out[36]: x y x 1.0 1.0 y 1.0 1.0 data.corr(method='kendall') Out[37]: x y x 1.0 1.0 y 1.0 1.0
因为y经由函数构造出来,x和y的相关系数为1,但从实验结构可知pearson系数,针对非线性数据有一定的误差。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号