论文阅读 | Bridging the Gap Between Relevance Matching and Semantic Matching for Short Text Similarity Modeling
作者提出了HCAN (Hybrid Co-Attention Network),包含:
(1)混合编码模块:CNN与LSTM混合的encoder;
(2)多粒度的相关性匹配模块;
(3)co-attention的语义匹配模块
背景
两类匹配模型未必能混用,语义匹配强调意思的对应和成份的结构,而相关性匹配关注关键词的匹配;
三个特征识别相关性匹配:精确匹配信号,匹配查询词的重要性,和多样化的需求;
相关性匹配模型(DRMM,Co-PACRR)采用基于交互的设计,在query和doc乘积相似性矩阵上构建模型;
语义匹配模型关注上下文感知的表示学习
研究两个问题:
(1)现有的两类模型是否可用于对方的问题?
(2)两类模型捕获的信息是否互补?
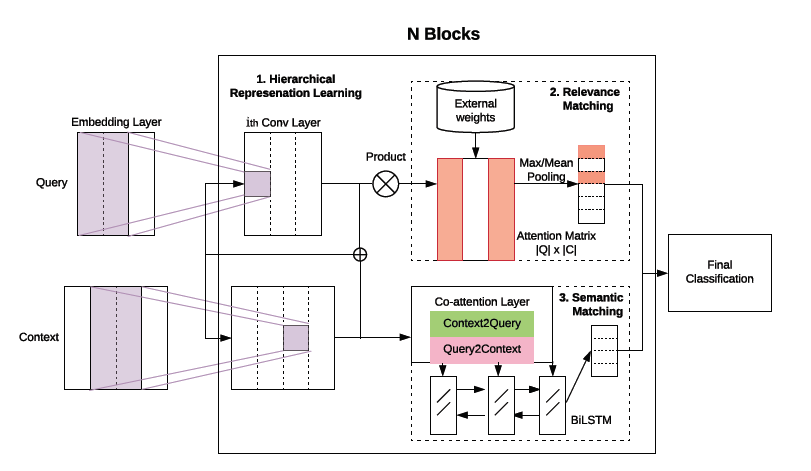
混合encoder
模型的输入为查询(query)和与之比较的文本(context),目标就是让模型判断两者间的匹配程度。为了捕获短语级的表示,这里使用了三种类型的encoder,作者将其称为deep、wide和contextual。
针对句子的embedding 矩阵,encoder分为:
(1)堆叠的多层CNN;
(2)并行多个CNN;
(3)双向LSTM。

三种类型的encoder在理想情况下应该起到一种互补的效果,前两种可以显式控制卷积核大小且速度更快,最后一个更容易捕获长程特征。
相关性匹配 Relevance Matching
word-level -> phrase-level -> sentence-level

inverse document frequency (IDF)
语义匹配 Semantic Matching
在每个编码层应用共同注意机制 Co-Attention,实现多语义层的上下文感知表示学习。
使用了Co-Attention来计算查询向量和文本向量之间的注意力分数,将其作为语义匹配得分。
得到Uq和Uc,首先使用 bilinear attention:
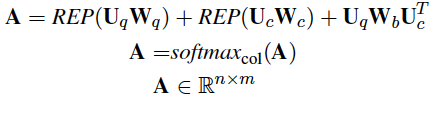
REP算子通过重复缺失维度中的元素将输入向量转换为Rn*m矩阵。
从两个方向进行co-attention:query-to-context和context-to-query,如下所示:

max col == > max pooling
concatenated contextual embeddings H:
![]()
然后接Bi-LSTM:
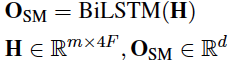
分类
两种匹配方式得到的d+2维输出,接上两层全连接+ReLU、softmax,损失函数采用NLL negative log likelihoold loss
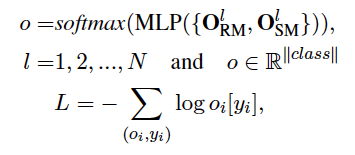
N是编码器的个数,相关性和语义匹配模块在每一个编码器层中都被应用,最终被集成用于分类。
实验
任务:
Answer Selection: TrecQA
评价标准:mean average precision (MAP) and mean reciprocal rank (MRR).
Paraphrase Identification: TwitterURL
评价标准:正例:F1值,负例:macro-F1
Semantic Textual Similarity (STS):Quora
评价标准:class prediction accuracy
Tweet Search: TREC Microblog 2013-2014,此任务是根据短查询的相关性对候选tweet进行排序。
评价标准:MAP and precision at rank 30 (P@30)
一些实现细节:
300d word2vec (Mikolov et al., 2013) embeddings
SGD optimizer
initialize word embeddings: uniform distribution from[0, 0.1]
CNN层N=4,filter size = 2,hidden_size = 150,卷积核数量 [128, 256, 512]
学习率:[0.05, 0.02, 0.01]
batch_size: [64, 128, 256]
drop_out: 0.1~0.5
三种HCAN model变体:
(1) only relevance matching signals (RM),
(2) only semantic matching signals (SM),
(3) the complete model (HCAN).
整体上来看,相关性匹配模型效果优于语义匹配模型,虽然SM一直比不上RM,但却对融合模型效果有提升。可能是SM模型获得到的语义信息有限。just few words
如图,比BERT还是不如,之后测试了它的推理速度,和ERNIE比还是慢很多。
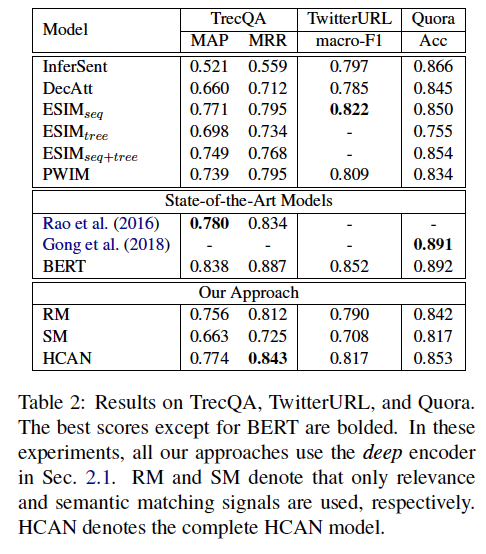
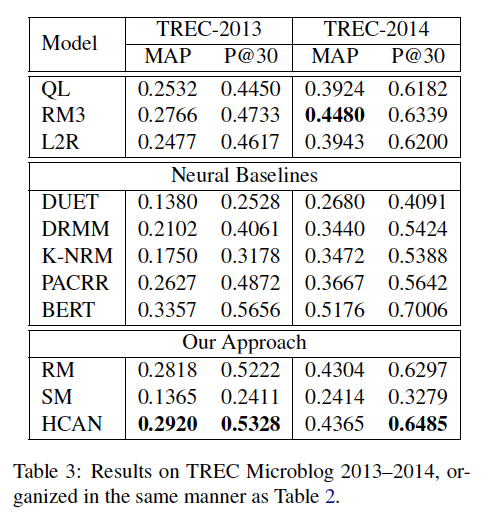
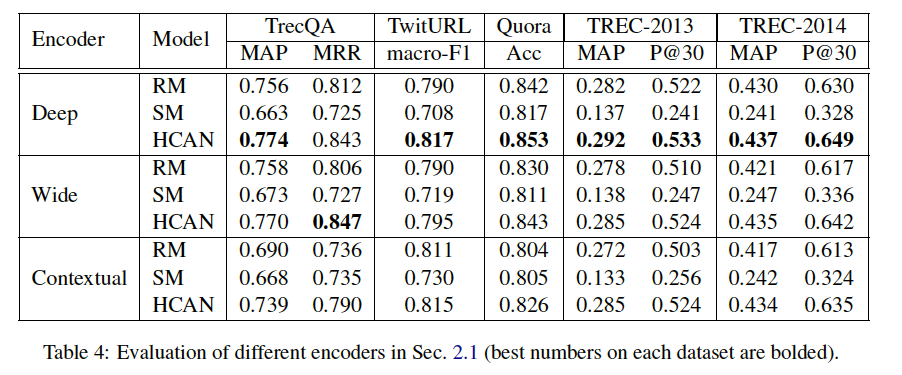
不同的编码器比较
deep 和 wide 编码器的表现差不多。contextual编码器在TrecQA数据集不如前两个,其它差不多。
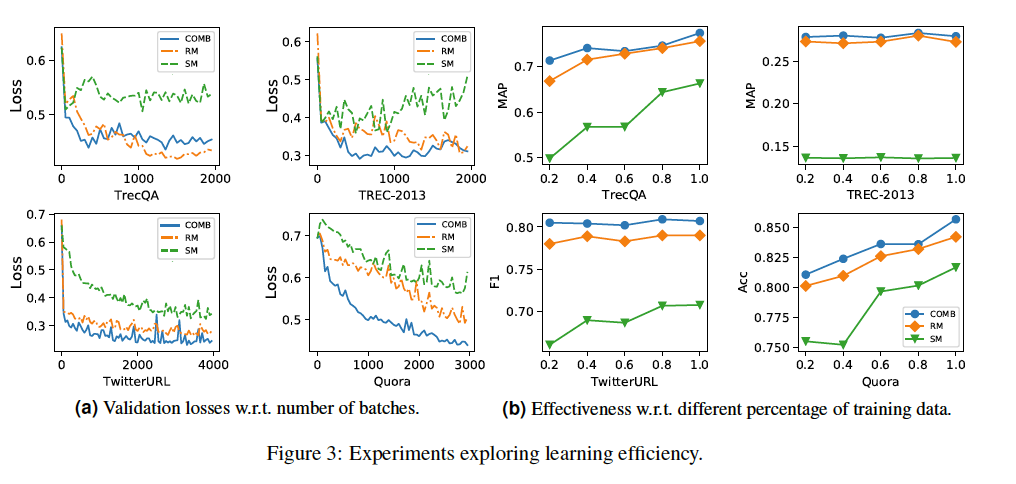
SM需要更多的数据支持。(Quora上,RM和SM表现相近,因为Quora数据集较其它数据集庞大很多)
编码器数量的影响:
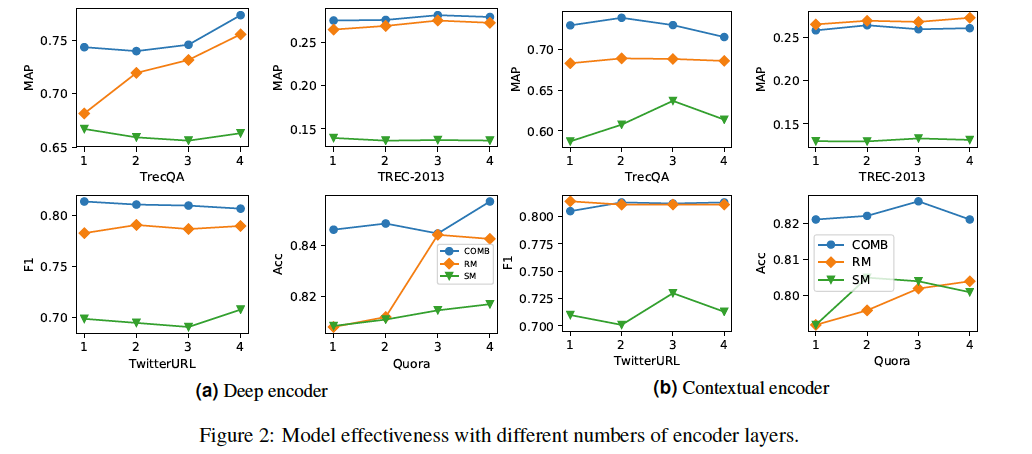
样本质量分析
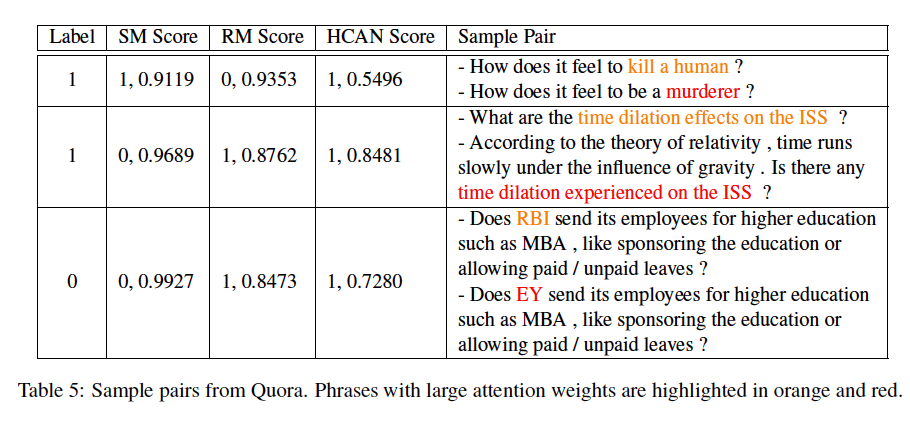
总体而言,RM在捕获重叠信号方面表现得更好,而结合语义匹配信号改善了表示学习。
others:
SM 是依赖于大量数据集的。
RM 需要关注各个level的相似性信号。
对两个text的语义理解和推理是SM的核心。
现有的最新SM技术通常包括三个主要部分:
(1)序列句子编码器,它结合了单词上下文和句子顺序以获得更好的句子表示
(2)交互和注意机制
(3) 结构建模
推理速度对比:
Batch_size = 64 , P40 单卡
Ernie - 2层: 15~16 steps/s
Ernie - 4层: 13~14 steps/s
Hcan: 1.1~ 2.6 steps/s 平均 2.1 steps/s

