NLP | 文本风格迁移 总结
简介
对于文本风格迁移,先举个例子:
Input:谢谢
Output(金庸): 多谢之至
Input: 再见
Output(金庸): 别过!
Input:请问您贵性?
Output(金庸): 请教阁下尊姓大名?
再泼个冷水:
目前自然语言生成(NLG)领域的研究还不太实用,所以希望像人一样先理解句子,再改写句子是不太现实的。
那么能否用机器翻译的方法,不理解句子也能实现句子的转换?这也是挺有局限的。机器翻译需要使用使用大量的对齐语料进行监督学习,应该是不会有人专门标注这样的语料的。
不过在某些特定领域,可以通过一些巧妙的数据挖掘方式来获取语料。例如根据新闻报道自动生成评论或摘要等,这样的题目现在很多人在做。假如把新闻语料和新闻评论的关系也当做“风格转换”的话,那么答案还是存在的。相关工作
论文 LIST1. Unpaired Sentiment-to-Sentiment Translation: A Cycled Reinforcement Learning Approach
2. Delete, Retrieve, Generate: A Simple Approach to Sentiment and Style Transfer
3. Generating Sentences by Editing Prototypes
4. Style Transfer from Non-Parallel Text by Cross-Alignment
5. Style Transfer Through Back-Translation
6. A Dual Reinforcement Learning Framework for Unsupervised Text Style Transfer
7. A Hierarchical Reinforced Sequence Operation Method for Unsupervised Text Style Transfer
1. Unpaired Sentiment-to-Sentiment Translation: A Cycled Reinforcement Learning Approach
第一篇工作 [1] 从题目来看就很吸引人,unpaired 对应 cycle,很自然联想到 reconstruction。而 reinforcement learning 主要是为了解决训练过程中离散文本不可求导的问题。
虽然过去也有一些 text style transfer 的问题,但是因为缺少对于非 stylish 或者说“普通文本”的语义信息的显式保留,导致很容易出现下面这种情况:当把“The food is delicious”这句话从正向情感迁移到负向情感时,会得到“What a bad movie”——虽然情感被正确转化了,但是内容的主体也跟着变了。这显然是不好的。
为了解决这个问题,这篇工作 [1] 使用了两个 module,一个 neutralization module 用于提取 non-emotional content,另一个 emotionalization module 用于生成或者说融入 sentiment words。
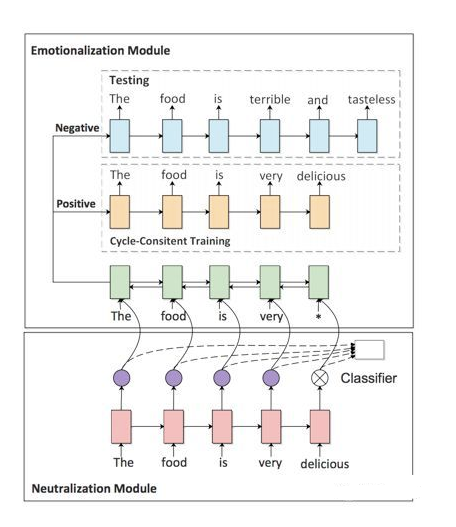
如上图所示,下面的 neutralization module 其实是通过直接删除emotional words 来实现 non-emotional content 的保留。这一步中,作者 [1] 通过使用 self-attention 得到的注意力权重作为分类器特征,从而自动找出 emotional words。从实验结果来看,这个方法的分类准确率也可以达到 90% 左右(不过 sentiment classification 本身也不是很难,稍微复杂一点的模型都可以达到95%甚至更高)。
接下来就是 emotionalization module,可以看到,一个 encoder 和两个 decoder。两个 decoder 对应 sentiment classification 的两个类别(positive or negative),并且分别用于训练时的 reconstruction 和测试时的 generation(emotionalization)。
由于文本的离散性,作者采用了 RL 的方法来训练这两个 module。RL 成功与否严重依赖于奖励函数的设计。在这篇论文中 [1],作者提出了两个 reward:sentiment confidence 和 BLEU。尤其是 BLEU,主要是针对作者想解决的问题——non-emotional content perserving。最终的奖励函数如下:
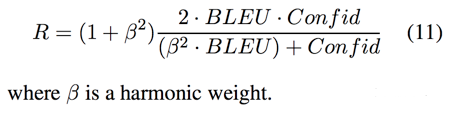
插播:BLEU(Bilingual Evaluation Understudy)
其中,
这里的BLEU值是针对一条翻译(一个样本)来说的。
例子:
候选译文(Predicted):
It is a guide to action which ensures that the military always obeys the commands of the party参考译文(Gold Standard)
1:It is a guide to action that ensures that the military will forever heed Party commands
2:It is the guiding principle which guarantees the military forces always being under the command of the Party
3:It is the practical guide for the army always to heed the directions of the partyModified n-gram Precision计算也即Pn):
这里n取值为4,也就是从1-gram计算到4-gram。
首先统计候选译文里每个词出现的次数,然后统计每个词在参考译文中出现的次数,Max表示3个参考译文中的最大值,Min表示候选译文和参考译文中的最大值的最小值。 例如,词"the":
然后将每个词的Min值相加,将候选译文每个词出现的次数相加,然后两值相除即得
类似得到2-gram 3-gram 4-gram的Pn,例如"ensures that":
然后我们取$w_{1}=w_{2}=w_{3}=w_{4}=0.25$,也就是Uniform Weights。
得到:
下面计算BP(Brevity Penalty),翻译过来就是“过短惩罚”。由BP的公式可知取值范围是(0,1],候选句子越短,越接近0。
候选翻译句子长度为18,参考翻译分别为:16,18,16。
所以$c=18$(候选翻译句子长度),$r=18$(参考翻译中选取长度最接近候选翻译的作为r)所以$BP=e^0=1$
整合:
$BLEU=1⋅exp(−0.684055269517)=0.504566684006$
BLEU的取值范围是[0,1],0最差,1最好。通过计算过程,我们可以看到,BLEU值其实也就是“改进版的n-gram”加上“过短惩罚因子”。
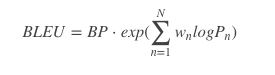
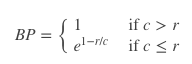

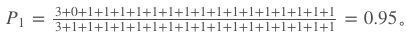


从实验结果来看,过去的工作主要都只考虑了 style transfer 的成功与否(sentiment accuracy),而没有显性地考虑 content perserving,所以确实在 BLEU 指标下表现很差。

但是也可以看到,这篇工作提出的方法 [1] 在大幅提高 BLEU 的情况下,ACC 也有一定损失。可以从这个结果看到,想要非常自然地融入 sentiment words 并且不破坏语义和语法,是很困难的事情。看一些直观的转换结果:

2. Delete, Retrieve, Generate: A Simple Approach to Sentiment and Style Transfer
第二篇论文 [2] 几乎也是一样的思路。但是在具体实现上要更直接一点。第二篇论文 [2] 在进行 style transfer 的时候,基于的是这样的假设:文本的一些属性(attribute),比如文本传达出来的情感信息等,可以体现在文本中的某些特定词汇上。通过改变这些词汇,就可能直接改变整句文本的性质属性(value)。
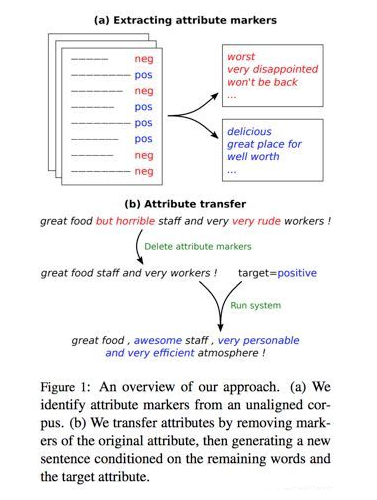
由上面的示意图可以看出,作者将那些具有指示功能的特定词称为 attribute marker,通过(主要)改变这些 marker,进行 attribute transfer。文章进一步提出了4种具体的方法来改变 marker。

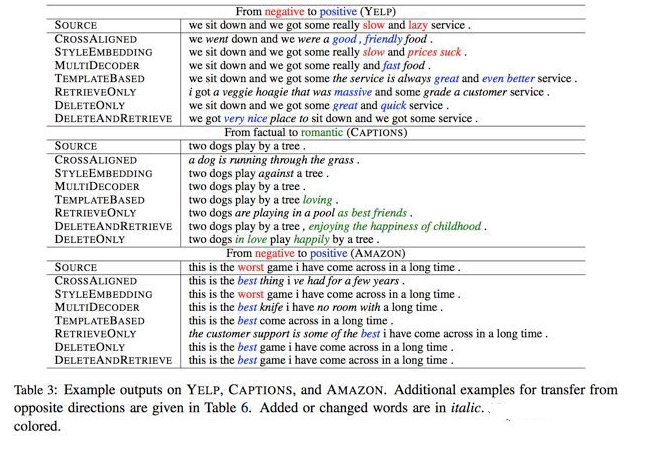
这4种具体的方式也由上图很清晰地展示了出来。值得一提的是 DeleteOnly 和 DeleteAndRetrieve。在删除了具体的 marker 后,作者提出再去根据这个没有情感特定性的句子去从数据中检索出一句最相似但是 attribute 的数值相反(target attribute)的话。检索出的这句话主要用于提取新的 target attribute marker,作为“重写” RNN 的输入之一。
很明显,这样的工作可能有一定局限性,但在一些简化场景中,却是更可控的。其实验结果也印证了这点 [2]。
3. Generating Sentences by Editing Prototypes
上面两篇工作都是进行风格转换,而在进行文本改写的时候,还有一类常见的场景就是进行非情感类改写,比如扩写句子,改写语法错误等。在进行这样的工作时,其实也可以采用类似的思路。先找到一个“中立”的、“简单”的“模板”,再在这个基础上加入希望增加的信息,如情感、一些复杂修饰词等等。今天要分享的最后一篇工作 [3] 就是这样一个思路。
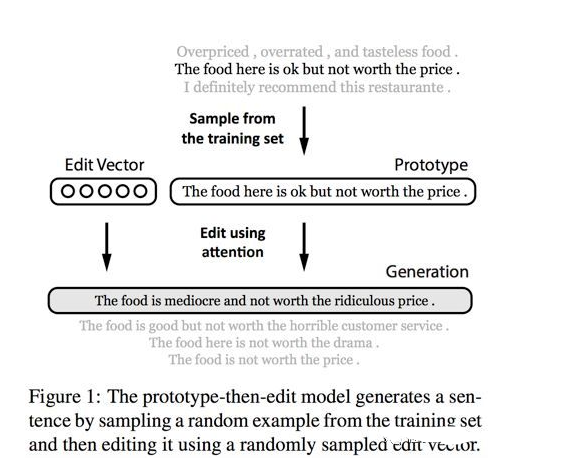
从上面的示意图中可以看到,修改后的句子增加了“modiocre”和“ridiculous”这两个形容词,变得更复杂了。而重中之重就是在学习 edit vector 上。可以看到,此时的 edit vector 不再是 sentiment words,而是一种 semantic operation。如果让 edit vector 作为一种隐变量,也遵循某种分布,那么同样的 edit vector 应该符合同一种 edit operation,并且对于句子的改写是一种微小的可控的操作。
基于这样的假设和期望,作者用 VAE 来建模 z,目标函数如下:

关键就是如何保证学到好的 p 和 q。这篇论文使用的方式和过去很多 VAE 的文本应用都不太一样,有兴趣的同学请一定去查阅原文。值得一提的是,这篇工作中的 edit vector z 是直接拼接在给 decoder 的每一个时刻的输入上的,并没有额外的 gate 或者 transform。这也是和上面两篇工作的区别之一。
最后从结果来看,作者提出的方法确实能更自然地改写句子。这点从 case studies 还有句子的平滑度方面可以看出:

目前的方法大概就是深度学习在外加使用policy gradient的方法,对于文本的生成的损失函数只论词的生成概率,可添加语言规则的损失项,类似词性,情感等之类,可以提升,而后在beam search阶段也可添加语言规则,而不是以只关注概率。另则,现在的文本风格迁移在人类的角度来看过于easy,离我们想象中的文本风格迁移还有很大一段距离。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号