用BERT做语义相似度匹配任务:计算相似度的方式
1. 自然地使用[CLS]
BERT可以很好的解决sentence-level的建模问题,它包含叫做Next Sentence Prediction的预训练任务,即成对句子的sentence-level问题。BERT也给出了此类问题的Fine-tuning方案:
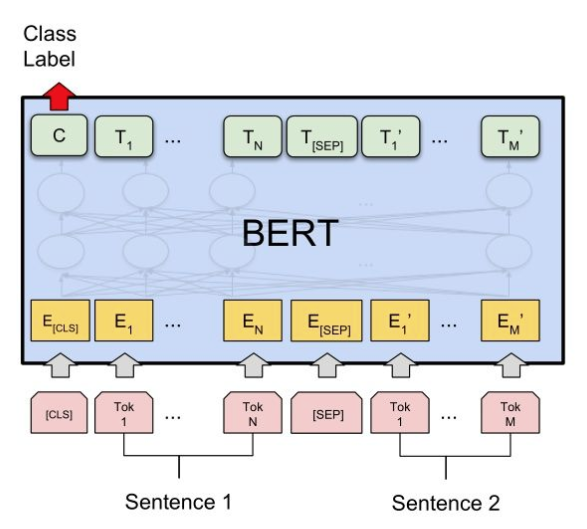
这一类问题属于Sentence Pair Classification Task.
计算相似度:
上图中,我们将输入送入BERT前,在首部加入[CLS],在两个句子之间加入[SEP]作为分隔。
然后,取到BERT的输出(句子对的embedding),取[CLS]即可完成多分类任务/相似度计算任务。
对应的:
假设我们取到的[CLS]对应的embedding为c,
多分类任务,需进行:P = softmax(cW')
相似度计算,需进行:P = sigmoid(cW')
然后,就可以去计算各自所需的loss了。
单纯的做相似度匹配,这种方式需要优化。
在不finetune的情况下,cosine similairty绝对值没有实际意义。
bert pretrain计算的cosine similairty都是很大的,如果直接以cosine similariy>0.5之类的阈值来判断相似不相似那肯定效果很差。如果用做排序,也就是cosine(a,b)>cosine(a,c)->b相较于c和a更相似,是可以用的。
模型评价的标准应该使用auc,而不是accuracy。
3. 长短文本的区别
短文本(新闻标题)语义相似度任务用先进的word embedding(英文fasttext/glove,中文tencent embedding)mean pooling后的效果就已经不错;
而对于长文本(文章)用simhash这种纯词频统计的完全没语言模型的简单方法也可以。
4. sentence/word embedding
bert pretrain模型直接拿来用作 sentence embedding效果甚至不如word embedding,cls的emebdding效果最差(也就是pooled output)。把所有普通token embedding做pooling勉强能用(这个也是开源项目bert-as-service的默认做法),但也不会比word embedding更好。
5. siamese network 方式
除了直接使用bert的句对匹配之外,还可以只用bert来对每个句子求embedding,再通过向Siamese Network这样的经典模式去求相似度。
用siamese的方式训练bert,上层通过cosine做判别,能够让bert学习到一种适用于cosine作为最终相似度判别的sentence embedding,效果优于word embedding,但因为缺少sentence pair之间的特征交互,比原始bert sentence pair fine tune还是要差些。
参考Siamese bert:

