NLP 语义相似度计算 整理总结
更新中
更新时间:
2019-12-03 18:29:52
写在前面:
本人是喜欢这个方向的学生一枚,写文的目的意在记录自己所学,梳理自己的思路,同时share给在这个方向上一起努力的同学。写得不够专业的地方望批评指正,欢迎感兴趣的同学一起交流进步。
(参考文献在第四部分,侵删)
一、背景
在很多NLP任务中,都涉及到语义相似度的计算,例如:
在搜索场景下(对话系统、问答系统、推理等),query和Doc的语义相似度;
feeds场景下Doc和Doc的语义相似度;
在各种分类任务,翻译场景下,都会涉及到语义相似度语义相似度的计算。
所以在学习的过程中,希望能够更系统的梳理一下这方面的方法。
二、基本概念
1. TF
Term frequency即关键词词频,是指一篇文章中关键词出现的频率,比如在一篇M个词的文章中有N个该关键词,则
![]()
为该关键词在这篇文章中的词频。
2. IDF
Inverse document frequency指逆向文本频率,是用于衡量关键词权重的指数,由公式
![]()
计算而得,其中D为文章总数,Dw为关键词出现过的文章数。
3. 向量空间模型
向量空间模型简称 VSM,是 VectorSpace Model 的缩写。在此模型中,文本被看作是由一系列相互独立的词语组成的,若文档 D 中包含词语 t1,t2,…,tN,则文档表示为D(t1,t2,…,tN)。由于文档中词语对文档的重要程度不同,并且词语的重要程度对文本相似度的计算有很大的影响,因而可对文档中的每个词语赋以一个权值 w,以表示该词的权重,其表示如下:D(t1,w1;t2,w2;…,tN,wN),可简记为 D(w1,w2,…,wN),此时的 wk 即为词语 tk的权重,1≤k≤N。关于权重的设置,我们可以考虑的方面:词语在文本中的出现频率(tf),词语的文档频率(df,即含有该词的文档数量,log N/n。很多相似性计算方法都是基于向量空间模型的。
三、语义相似度计算方法
1. 余弦相似度(Cosine)
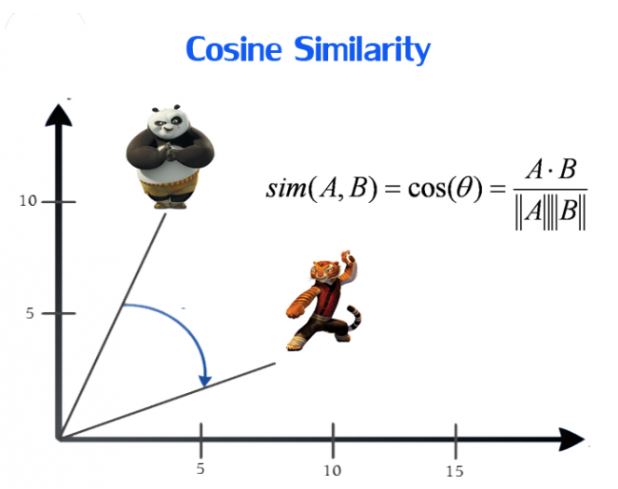
余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。
两个向量间的余弦值可以通过使用欧几里得点积公式求出:
![]()
余弦相似性θ由点积和向量长度给出,如下所示(例如,向量A和向量B):

这里的![]() 分别代表向量A和B的各分量。
分别代表向量A和B的各分量。
问题:表示方向上的差异,但对距离不敏感。
关心距离上的差异时,会对计算出的每个(相似度)值都减去一个它们的均值,称为调整余弦相似度。
代码:

2. 欧式距离
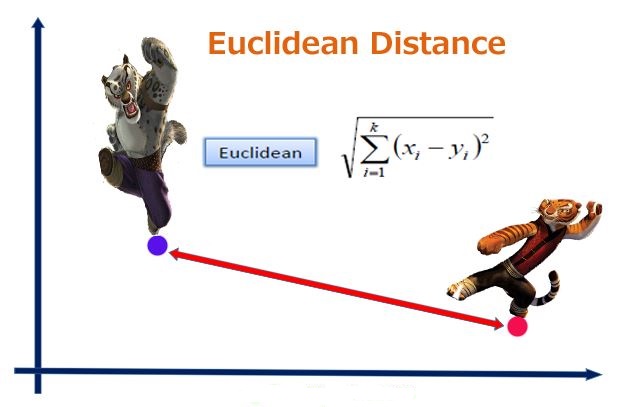

考虑的是点的空间距离,各对应元素做差取平方求和后开方。能体现数值的绝对差异。
代码:

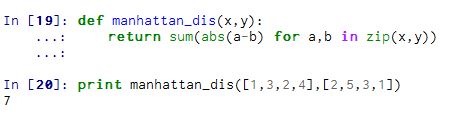
3. 曼哈顿距离(Manhattan Distance)
d(i,j)=|X1-X2|+|Y1-Y2|.
向量各坐标的绝对值做查后求和。
代码:
4. 明可夫斯基距离(Minkowski distance)
明氏距离是欧氏距离的推广,是对多个距离度量公式的概括性的表述。
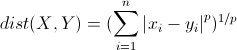
- 当p==1,“明可夫斯基距离”变成“曼哈顿距离”
- 当p==2,“明可夫斯基距离”变成“欧几里得距离”
- 当p==∞,“明可夫斯基距离”变成“切比雪夫距离”
代码:

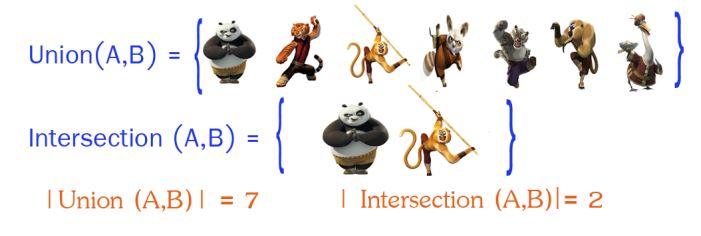
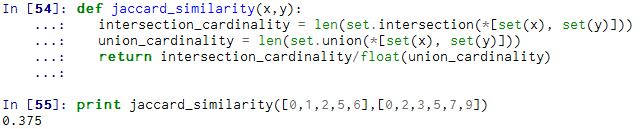
5. Jaccard 相似系数(Jaccard Coefficient)

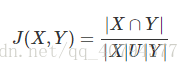
Jaccard系数主要用于计算符号度量或布尔值度量的向量的相似性。即,无需比较差异大小,只关注是否相同。Jaccard系数只关心特征是否一致(共有特征的比例)。
然后利用公式进行计算:

代码:
6. 皮尔森相关系数(Pearson Correlation Coefficient)
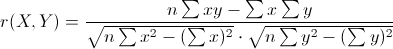
又称为相关相似性。
或表示为:
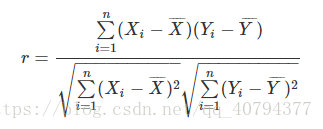
这就是1中所提到的调整余弦相似度,向量内各对应元素减去均值求积后求和,记为结果1;各对应元素减去均值平方求和再求积,记为结果2;结果1比结果2。
针对线性相关情况,可用于比较因变量和自变量间相关性如何。
7. SimHash + 汉明距离(Hamming Distance)
Simhash:谷歌发明,根据文本转为64位的字节,计算汉明距离判断相似性。
汉明距离:在信息论中,两个等长字符串的汉明距离是两者间对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。例如:
“10110110”和“10011111”的汉明距离为3; “abcde”和“adcaf”的汉明距离为3.
8. 斯皮尔曼(等级)相关系数(SRC :Spearman Rank Correlation)
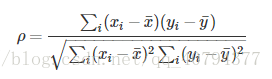
和6上述类似,不同的是将对于样本中的原始数据Xi,Yi转换成等级数据xi,yi,即xi等级和yi等级。并非考虑原始数据值,而是按照一定方式(通常按照大小)对数据进行排名,取数据的不同排名结果代入公式。
实际上,可通过简单的方式进行计算,n表示样本容量,di表示两向量X和Y内对应元素的等级的差值,等级di = xi - yi,则:
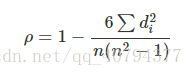
例如( 维基百科):
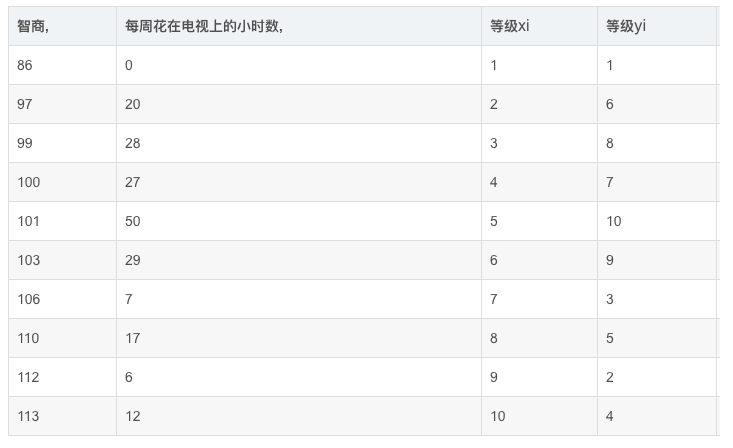
n = 10,di2的和为194,则可代入公式计算出结果为:-0.17575757...,Xi和Yi几乎不相关。
9. BM25算法
原理
BM25算法,通常用来作搜索相关性平分:对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
BM25算法的一般性公式如下:

定义Wi:
判断一个词与一个文档的相关性的权重,方法有多种,较常用的是IDF。这里以IDF为例,公式如下:

其中,N为索引中的全部文档数,n(qi)为包含了qi的文档数。
根据IDF的定义可以看出,对于给定的文档集合,包含了qi的文档数越多,qi的权重则越低。也就是说,当很多文档都包含了qi时,qi的区分度就不高,因此使用qi来判断相关性时的重要度就较低。
我们再来看语素qi与文档d的相关性得分R(qi,d)。
BM25中相关性得分的一般形式:


其中,k1,k2,b为调节因子,通常根据经验设置,一般k1=2,b=0.75;fi为qi在d中的出现频率,qfi为qi在Query中的出现频率。dl为文档d的长度,avgdl为所有文档的平均长度。由于绝大部分情况下,qi在Query中只会出现一次,即qfi=1,因此公式可以简化为:

从K的定义中可以看到,参数b的作用是调整文档长度对相关性影响的大小。b越大,文档长度的对相关性得分的影响越大,反之越小。而文档的相对长度越长,K值将越大,则相关性得分会越小。这可以理解为,当文档较长时,包含qi的机会越大,因此,同等fi的情况下,长文档与qi的相关性应该比短文档与qi的相关性弱。
综上,BM25算法的相关性得分公式可总结为:

从BM25的公式可以看到,通过使用不同的语素分析方法、语素权重判定方法,以及语素与文档的相关性判定方法,我们可以衍生出不同的搜索相关性得分计算方法,这就为我们设计算法提供了较大的灵活性。
代码实现:
1 import math 2 import jieba 3 from utils import utils 4 5 # 测试文本 6 text = ''' 7 自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。 8 它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。 9 自然语言处理是一门融语言学、计算机科学、数学于一体的科学。 10 因此,这一领域的研究将涉及自然语言,即人们日常使用的语言, 11 所以它与语言学的研究有着密切的联系,但又有重要的区别。 12 自然语言处理并不是一般地研究自然语言, 13 而在于研制能有效地实现自然语言通信的计算机系统, 14 特别是其中的软件系统。因而它是计算机科学的一部分。 15 ''' 16 17 class BM25(object): 18 19 def __init__(self, docs): 20 self.D = len(docs) 21 self.avgdl = sum([len(doc)+0.0 for doc in docs]) / self.D 22 self.docs = docs 23 self.f = [] # 列表的每一个元素是一个dict,dict存储着一个文档中每个词的出现次数 24 self.df = {} # 存储每个词及出现了该词的文档数量 25 self.idf = {} # 存储每个词的idf值 26 self.k1 = 1.5 27 self.b = 0.75 28 self.init() 29 30 def init(self): 31 for doc in self.docs: 32 tmp = {} 33 for word in doc: 34 tmp[word] = tmp.get(word, 0) + 1 # 存储每个文档中每个词的出现次数 35 self.f.append(tmp) 36 for k in tmp.keys(): 37 self.df[k] = self.df.get(k, 0) + 1 38 for k, v in self.df.items(): 39 self.idf[k] = math.log(self.D-v+0.5)-math.log(v+0.5) 40 41 def sim(self, doc, index): 42 score = 0 43 for word in doc: 44 if word not in self.f[index]: 45 continue 46 d = len(self.docs[index]) 47 score += (self.idf[word]*self.f[index][word]*(self.k1+1) 48 / (self.f[index][word]+self.k1*(1-self.b+self.b*d 49 / self.avgdl))) 50 return score 51 52 def simall(self, doc): 53 scores = [] 54 for index in range(self.D): 55 score = self.sim(doc, index) 56 scores.append(score) 57 return scores 58 59 if __name__ == '__main__': 60 sents = utils.get_sentences(text) 61 doc = [] 62 for sent in sents: 63 words = list(jieba.cut(sent)) 64 words = utils.filter_stop(words) 65 doc.append(words) 66 print(doc) 67 s = BM25(doc) 68 print(s.f) 69 print(s.idf) 70 print(s.simall(['自然语言', '计算机科学', '领域', '人工智能', '领域']))
分段再分词结果:
[['自然语言', '计算机科学', '领域', '人工智能', '领域', '中', '一个', '方向'], ['研究', '人', '计算机', '之间', '自然语言', '通信', '理论', '方法'], ['自然语言', '一门', '融', '语言学', '计算机科学', '数学', '一体', '科学'], [], ['这一', '领域', '研究', '涉及', '自然语言'], ['日常', '语言'], ['语言学', '研究'], ['区别'], ['自然语言', '研究', '自然语言'], ['在于', '研制', '自然语言', '通信', '计算机系统'], ['特别', '软件系统'], ['计算机科学', '一部分']]
s.f
列表的每一个元素是一个dict,dict存储着一个文档中每个词的出现次数
[{'中': 1, '计算机科学': 1, '领域': 2, '一个': 1, '人工智能': 1, '方向': 1, '自然语言': 1},
{'之间': 1, '方法': 1, '理论': 1, '通信': 1, '计算机': 1, '人': 1, '研究': 1, '自然语言': 1},
{'融': 1, '一门': 1, '一体': 1, '数学': 1, '科学': 1, '计算机科学': 1, '语言学': 1, '自然语言': 1},
{},
{'领域': 1, '这一': 1, '涉及': 1, '研究': 1, '自然语言': 1},
{'日常': 1, '语言': 1},
{'语言学': 1, '研究': 1},
{'区别': 1},
{'研究': 1, '自然语言': 2},
{'通信': 1, '计算机系统': 1, '研制': 1, '在于': 1, '自然语言': 1},
{'软件系统': 1, '特别': 1},
{'一部分': 1, '计算机科学': 1}]
s.df
存储每个词及出现了该词的文档数量
{'在于': 1, '人工智能': 1, '语言': 1, '领域': 2, '融': 1, '日常': 1, '人': 1, '这一': 1, '软件系统': 1, '特别': 1, '数学': 1, '通信': 2, '区别': 1, '之间': 1, '计算机科学': 3, '科学': 1, '一体': 1, '方向': 1, '中': 1, '理论': 1, '计算机': 1, '涉及': 1, '研制': 1, '一门': 1, '研究': 4, '语言学': 2, '计算机系统': 1, '自然语言': 6, '一部分': 1, '一个': 1, '方法': 1s.idf
存储每个词的idf值
{'在于': 2.0368819272610397, '一部分': 2.0368819272610397, '一个': 2.0368819272610397, '语言': 2.0368819272610397, '领域': 1.4350845252893225, '融': 2.0368819272610397, '日常': 2.0368819272610397, '人': 2.0368819272610397, '这一': 2.0368819272610397, '软件系统': 2.0368819272610397, '特别': 2.0368819272610397, '数学': 2.0368819272610397, '通信': 1.4350845252893225, '区别': 2.0368819272610397, '之间': 2.0368819272610397, '一门': 2.0368819272610397, '科学': 2.0368819272610397, '一体': 2.0368819272610397, '方向': 2.0368819272610397, '中': 2.0368819272610397, '理论': 2.0368819272610397, '计算机': 2.0368819272610397, '涉及': 2.0368819272610397, '研制': 2.0368819272610397, '计算机科学': 0.9985288301111273, '研究': 0.6359887667199966, '语言学': 1.4350845252893225, '计算机系统': 2.0368819272610397, '自然语言': 0.0, '人工智能': 2.0368819272610397, '方法': 2.0368819272610397s.simall(['自然语言', '计算机科学', '领域', '人工智能', '领域'])
['自然语言', '计算机科学', '领域', '人工智能', '领域']与每一句的相似度
[5.0769919814311475, 0.0, 0.6705449078118518, 0, 2.5244316697250033, 0, 0, 0, 0.0, 0.0, 0, 1.2723636062357853]
TODO:
Dice 系数法(DiceCoefficient)
最新的:百度报告会中的分享:RBF MM GMM GMM核函数的应用场景?
在目录中添加每个方法
BM25算法的优缺点
四、参考文献

