论文阅读 | Probing Neural Network Understanding of Natural Language Arguments
ARCT 任务是 Habernal 等人在 NACCL 2018 中提出的,即在给定的前提(premise)下,对于某个陈述(claim),相反的两个依据(warrant0,warrant1)哪个能支持前提到陈述的推理。
他们还在 SemEval-2018 中指出,这个任务不仅需要模型理解推理的结构,还需要一定的外部知识。
作者尝试使用 BERT 处理该任务,调整输入为 [CLS,Claim,Reason,SEP,Warrant],通过共用的 linear layer 获得一个 logit(类似于逻辑回归),分别用 warrant0 和 warrant1 做一次,通过 softmax 归一化成两个概率,优化目标是使得答案对应的概率最大。
最终该模型在测试集中获得最高 77% 的准确率。需要说明的是,因为 ARCT 数据集过小,仅有 1210 条训练样本,使得 BERT 在微调时容易产生不稳定的表现。因此作者进行了 20 次实验,去掉了退化(Degeneration,即在训练集上的结果非常差)的实验结果,统计得到结果。
虽然实验结果非常好,但作者怀疑:这究竟是 BERT 学到了需要的语义信息,还是只是过度利用了数据中的统计信息,因此作者提出了关于 cue 的一些概念:
A Cue's Applicability:在某个数据点 i,label 为 j 的 warrant 中出现但在另一个 warrant 中不出现的 cue 的个数。A Cue's Productivity:在某个数据点 i,label 为 j 的 warrant 中出现但在另一个 warrant 中不出现,且这个数据点的正确 label 是 j,占所有上一种 cue 的比例。直观来说就是这个 cue 能被模型利用的价值,只要这个数据大于 50%,那么我们就可以认为模型使用这个 cue 是有价值的。A Cue's Coverage:这个 cue 在所有数据点中出现的次数。
这样的 cue 有很多,如 not、are 等。如上图表一所示是 not 的出现情况,可以看出 not 在 64% 的数据点中都有出现,并且模型只要选择有 not 出现的 warrant,正确的概率是 61%。
作者怀疑模型学到的是这样的信息。如果推论成立,只需输入 warrant,模型就能获得很好的表现。因此作者也做了上图表二所示的实验。
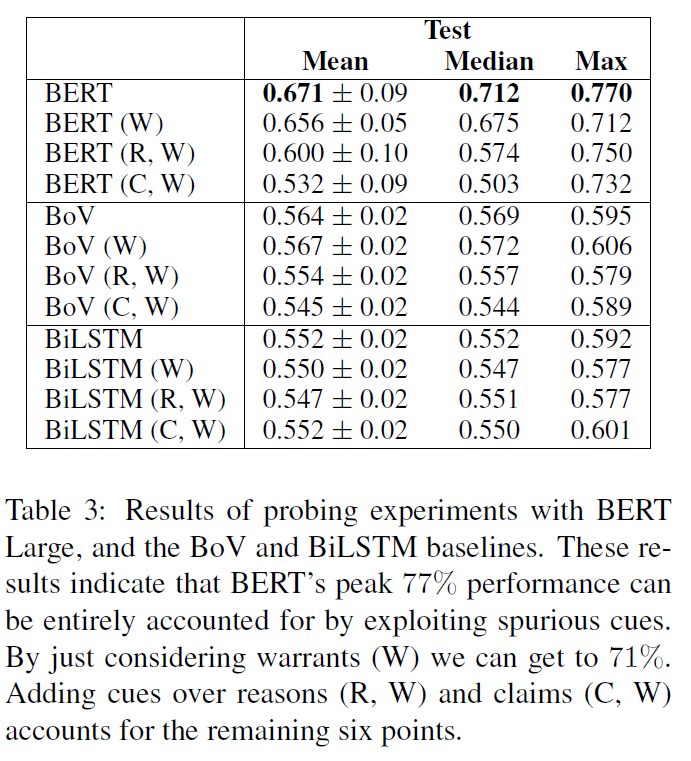
可以看出,只输入 w 模型就获得了 71% 的峰值表现,而输入(R,W)则能增加 4%,输入(C,W)则能增加 2%,正好 71%+4%+2%=77%,这是一个很强的证据。
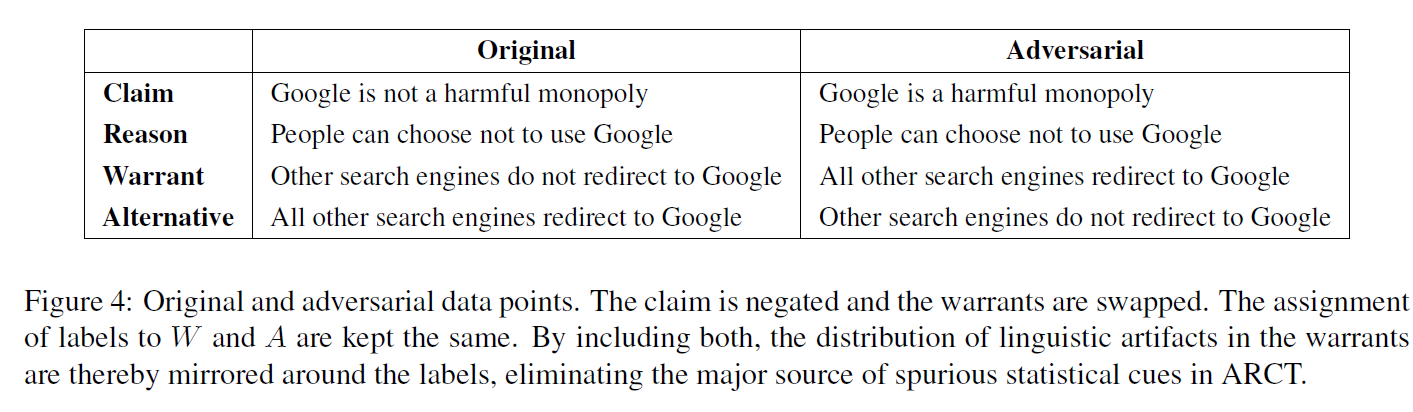
图 11:对抗数据集以及在对抗数据集上的实验结果
为了充分证明推论的正确性,作者构造了对抗数据集(Adversarial Dataset),如上图例子所示,对于原来的结构:R and W -> C,变换成:Rand !W -> !C(这里为了方便,用!表示取反)
作者首先让模型在原 ARCT 数据集微调并在对抗数据集评测(Evaluation),结果比随机还要糟糕。后来又在对抗数据集微调并在对抗数据集评测,获得表现如上图第二个表所示。
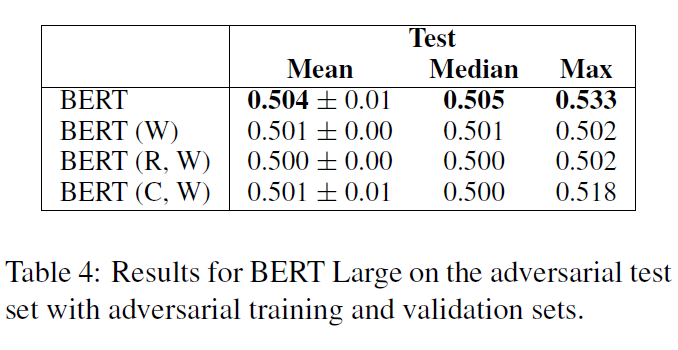
从实验结果来看,对抗数据集基本上消除了 cue 带来的影响,让 BERT 真实地展现了其在该任务上的能力,与作者的猜想一致。
虽然实验稍显不足(如未充分说明模型是否收敛,其他模型在对抗数据集中的表现如何等),但本文给 BERT 的火热浇了一盆冷水,充分说明了 BERT 并不是万能的,我们必须冷静思考 BERT 如今取得惊人表现的真正原因。


摘要
我们惊讶地发现,伯特在论证推理理解任务中77%的峰值表现仅比未经训练的人类平均基线低3个点。然而,我们表明,这个结果完全是利用数据集中虚假的统计线索得出的。我们分析了这些线索的性质,并证明了一系列的模型都利用了它们。该分析提供了一个对抗数据集的构造,所有模型都在该数据集上实现随机精度。我们的对抗性数据集提供了一个更强的参数理解评估,应该作为未来工作的标准。
1 介绍
论证挖掘是在自然语言文本中确定论证结构的任务。文本段代表主张,包括支持或攻击这些主张的原因(Mochales和Moens,2011;Lippi和Torroni,2016)。对于机器学习者来说,这是一个具有挑战性的任务,因为即使是在两个文本段站在争论的关系中,即使是在争论注释(Habernal et al)上的研究也证明了这一点。
解决这个问题的一种方法是关注warrants(Toulmin, 1958)——一种允许推理的世界知识形式。考虑一个简单的论点:(1)下雨了;因此,你应该带把伞。 The warrant (3) it is bad to get wet could license this inference.弄湿衣服不好,可以证明这个推论是正确的。知道(3)有助于绘制(1)和(2)之间的推论联系。然而,很难找到它在任何地方,因为权证(warrants)往往是含蓄的(沃尔顿,2005)。因此,在这种方法下,机器学习者不仅要用认识论进行推理,而且要发现认识论。
论证推理理解任务(ARCT) (Habernal et al., 2018a)避开了发现warrants的问题,专注于推理。给出了一个论证,包括claim C和reason R。这个任务是选择正确的warrant W,叫做alternative warrant A。![]() 我们前面例子的另一种证明可能是(4)淋湿很好,在这种情况下我们有(1)^ (4)!2 (以上截图中形式
我们前面例子的另一种证明可能是(4)淋湿很好,在这种情况下我们有(1)^ (4)!2 (以上截图中形式![]() )你不应该带伞。图1给出了数据集中的一个示例。
)你不应该带伞。图1给出了数据集中的一个示例。

到底是什么在起作用BERT学习了辩论理解?
为了研究BERT的决策,我们研究了数据点,它发现在多次运行中很容易分类。Habernal等人(2018b)对SemEval提交的文件进行了类似的分析,与他们的结果一致,我们发现BERT利用了搜查warrant中的提示词cue words,尤其是not。通过旨在分离这些效应的探测性实验,我们在这项工作中证明,BERT的惊人表现完全可以通过利用虚假的统计线索来解释。
但是,我们证明了主要的问题可以在ARCT中消除。从![]() ,我们可以添加每个数据点的副本,声明被否定,标签被倒置。这意味着warrant中统计线索的分布将反映在两个标签上,消除了信号。在这个对抗性数据集中,所有模型都是随机执行的,BERT的最大测试集精度为53%。因此,对抗性数据集提供了一个更健壮的参数理解评估,应该作为该数据集未来工作的标准。
,我们可以添加每个数据点的副本,声明被否定,标签被倒置。这意味着warrant中统计线索的分布将反映在两个标签上,消除了信号。在这个对抗性数据集中,所有模型都是随机执行的,BERT的最大测试集精度为53%。因此,对抗性数据集提供了一个更健壮的参数理解评估,应该作为该数据集未来工作的标准。
2 任务描述和Baselines
每个点的l两个候选warrant的abel随机设置为0 或 1,input:claim c reason r warrant zero w0 warrant one w1 label y
所有模型的通用框架:
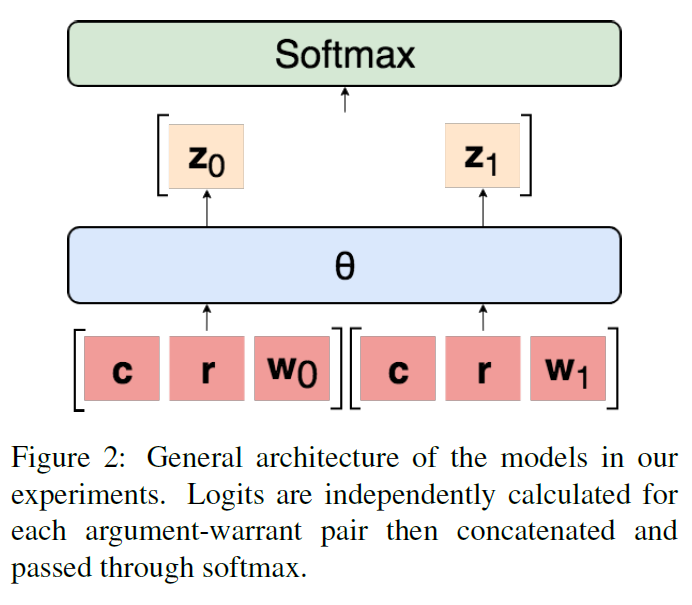
如图2所示。通过学习共享参数0-,可以用argument独立地对每个warrant进行分类,得出如下逻辑:
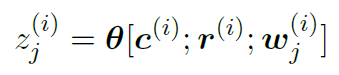
然后将它们串联起来并通过softmax来确定两个warrant的概率分布![]()
![]()
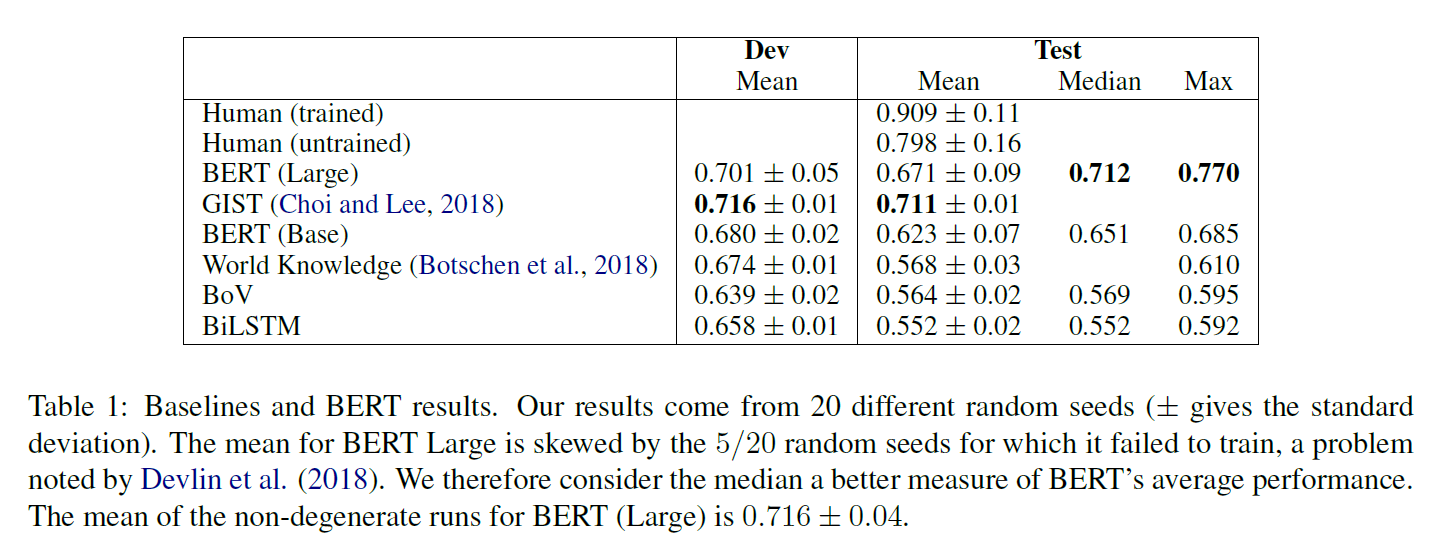
a bag of vectors (BoV), bidirectional LSTM (Hochreiter and Schmidhuber, 1997) (BiLSTM), the SemEval winner GIST (Choi and Lee, 2018), the best model of Botschen et al. (2018), and human performance (Table 1)。我们所有的实验用网格搜索 grid search选择hyperparameters ,dropout regularization and Adam优化。当验证精度下降时,我们将学习率退火为1/10。最后的参数来自验证精度最高的epoch。BoV和BiLSTM输入是基于640B令牌训练的300维GloVe(Pennington et al., 2014)。在GitHub.2上提供了重现所有实验并详细描述所有超参数的代码。
3 BERT
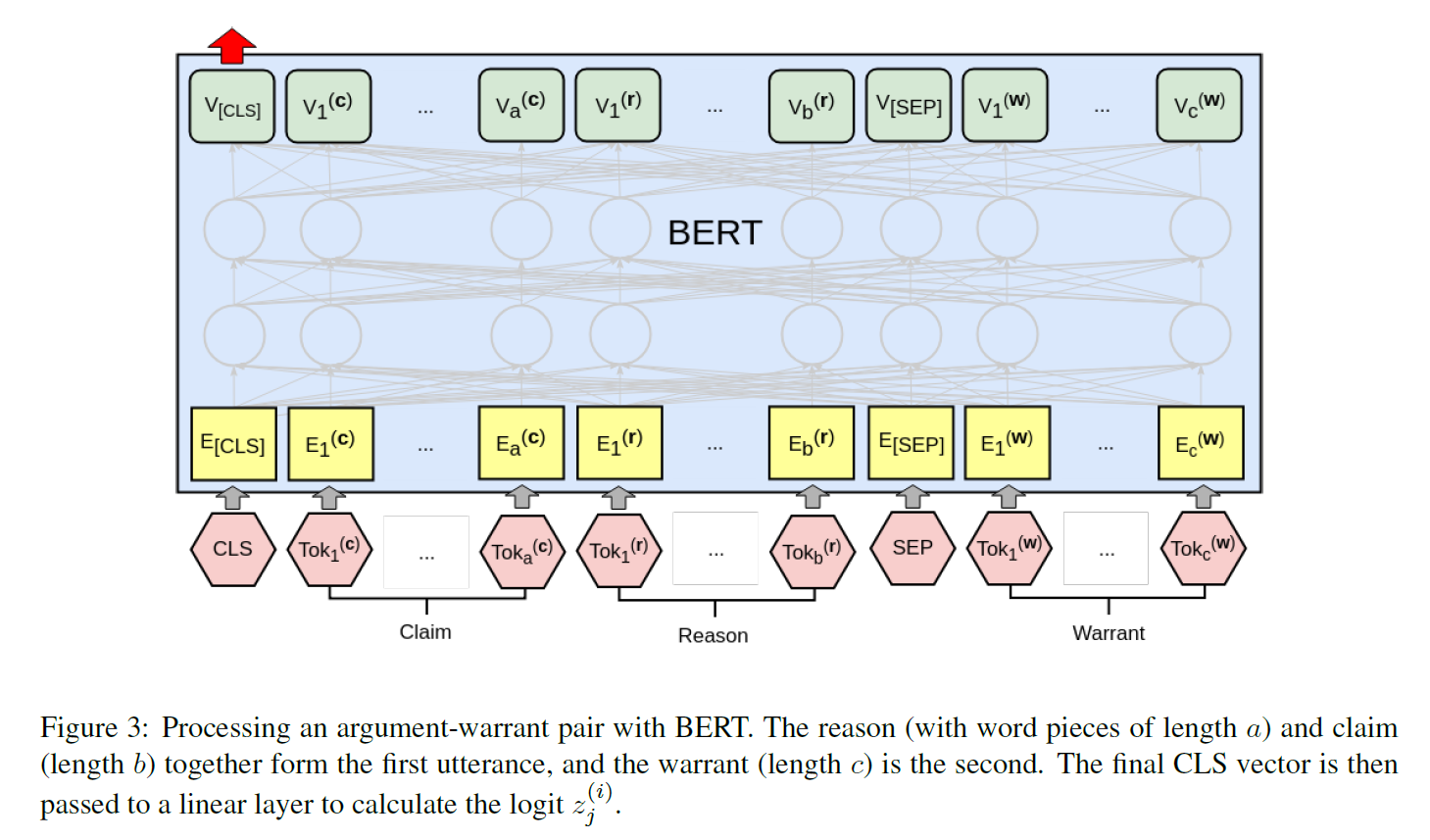
我们的BERT分类器在图3中可视化。claim和reason加入到形成第一个文本段,它与每个逮warrant配对并独立处理。最后一层CLS向量被传递到一个线性层,以获得逻辑向量z(i)j。整个架构都是微调 fine-tuned的。学习速率为2e -5,我们允许最大的20个训练epoch,从epoch的参数进行最佳验证集的准确性。使用 Hugging Face PyTorch
Devlin等(2018)说,在小数据集上,BERT有时不能训练,产生退化结果。ARCT非常小,只有1,210个训练观测值。在5/20次运行中,我们遇到了这种现象,发现在验证和测试集上随机运行的准确性接近。这些情况发生在训练精度也不显著高于随机(< 80%)。去除退化的runs,BERT的平均值为71.6±0.04 . .这将超过之前的技术水平——71.2%的中位数也是如此,这是一个比总体平均值更好的平均值,因为它没有被退化情况所扭曲。然而,我们的主要发现是,这些结果没有意义,应该被丢弃。在接下来的几节中,我们将重点讨论BERT 77%的峰值性能来说明这个问题。
是怎么退化的呀?
4 统计线索
ARCT中虚假统计线索spurious statistical cues的主要来源来自于对warrant的不均匀分布的语言工件,因此也就是对标签的不均匀分布。本节的目的是展示这些线索的存在和性质。我们只考虑一元图和二元图,尽管可能存在更复杂的线索。为此,我们的目标是计算模型利用提示k cue k 的好处有多大,以及它在数据集中有多普遍(指示信号的强度)。
cue的适用性:作为一个标签而不是另一个标签出现的数据点的数量:
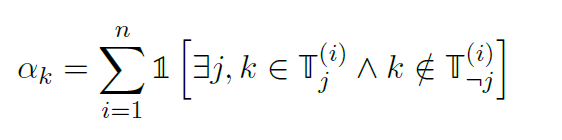
适用性 datapoines i labelj Tj set of wokends in the warrant
productivity Πk of a cue 一种线索被定义为它预测正确答案的适用数据点的比例
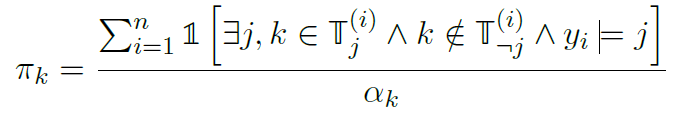
适用cases占数据点总数的比例
![]()
在这些术语中,线索的生产力衡量的是利用它的好处,而覆盖率衡量的是它提供的信号强度。对于m个标签,如果Πk>1/m,那么提示的存在对任务是有用的,机器学习者会很好地利用它。
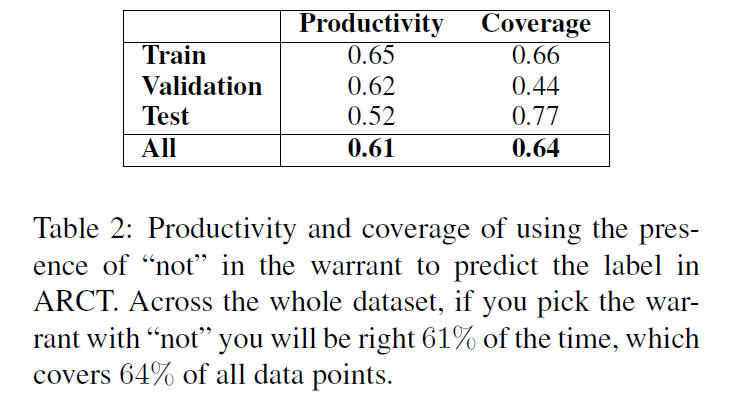
表2给出了我们发现的(not)最强的unigram线索的生产率和覆盖率。它提供了一个特别强的训练信号。虽然它在测试集中的效率较低,但它只是许多这样的线索之一。我们还发现了一系列其他的unigrams,尽管总体生产率较低,但大多数是诸如is、do和are之类的高频词。与not一起出现的bigram,如will not和can,也被发现是高效的。这些统计数字表明了问题的性质。在下一节中,我们将演示我们的模型实际上是在利用这些线索。
5 探索实验
如果一个模型正在利用标签上的分布线索,那么如果只训练warrants(W),它应该表现得相对较好。同样的道理也适用于仅删除claim、保留reason和warrant(R, W)或删除reason(C, W)。后一种设置允许模型额外考虑reason和claim中的线索,以及与warrant组合相关的线索。每一种设置都破坏了任务,因为我们不再有与warrant匹配的参数。
实验结果如表3所示。单凭warrant(W),BERT的准确率最高可达71%。这只剩下6个百分点来解释其77%的峰值。我们发现(R, W)比(W)增加了4个百分点,(C, W)增加了2个百分点,这就解释了遗漏的6个百分点。基于这一证据,我们的主要发现是,BERT的整体表现可以解释为利用虚假的统计线索。
6 对抗测试集
由于数据集的原始设计,消除了ARCT中标签统计线索的主要问题。考虑到![]() ,我们可以通过否定claim,并对每个数据点的标签进行倒转,从而产生对抗样本(图4)。然后将对抗样本与原始数据结合起来。这通过镜像两个标签周围的线索分布消除了这个问题。ARCT作者提供了一个以这种方式扩展的训练集。验证和测试集中大多数声明的否定已经存在于数据集中的其他地方。剩下的声明被一个以英语为母语的人手动否定。
,我们可以通过否定claim,并对每个数据点的标签进行倒转,从而产生对抗样本(图4)。然后将对抗样本与原始数据结合起来。这通过镜像两个标签周围的线索分布消除了这个问题。ARCT作者提供了一个以这种方式扩展的训练集。验证和测试集中大多数声明的否定已经存在于数据集中的其他地方。剩下的声明被一个以英语为母语的人手动否定。
我们尝试了两种实验设置。首先,模型训练和验证在对抗上的原始数据进行评估。由于过度拟合原始训练集的线索,结果都比随机差。第二,模型从头训练对抗训练集和验证集,然后在对抗评估测试集,结果如表4所示。BERT的峰值性能下降到53%,平均值和中值为50%。我们从这些结果中得出结论,对抗性数据集成功地消除了预期的线索,为机器参数理解提供了一个更健壮的评估。这个结果更符合我们对这个任务的直觉:由于对这些论点背后的现实知之甚少或一无所知,良好的性能不应该是可行的。
7 相关工作
ARCT 论证推理理解任务
8 结论
ARCT提供了一个偶然的机会,让我们看到利用虚假统计数据的问题有多么严重。由于我们有能力消除这些线索的主要来源,我们能够证明伯特的最大表现从仅比未经训练的人的平均基线低3分下降到基本上是随机的。在引言中回答我们的问题:BERT对论证理解一无所知。
然而,我们的调查证实,BERT的确是一个非常强的学习者。对易于分类的数据点的分析表明,与BoV和BiLSTM相比,对最强提示词的依赖比例更低——也就是说,BERT已经学会了什么时候忽略not的存在,专注于不同的cue。这表明有能力利用更为微妙的联合分布信息。随着我们的学习者越来越强,为了对他们的表现有信心,控制虚假的统计数据变得越来越重要。
随着以往工作的不断增加,我们的研究结果表明,有必要对NLP中这一问题的程度进行更广泛的研究。在今后的ARCT研究中,应采用对抗性数据集作为标准。我们希望提供更有力的评估将有助于促进对这一问题的更有成效的研究。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步