论文阅读 | Real-Time Adversarial Attacks
摘要
以前的对抗攻击关注于静态输入,这些方法对流输入的目标模型并不适用。攻击者只能通过观察过去样本点在剩余样本点中添加扰动。
这篇文章提出了针对于具有流输入的机器学习模型的实时对抗攻击。
1 介绍
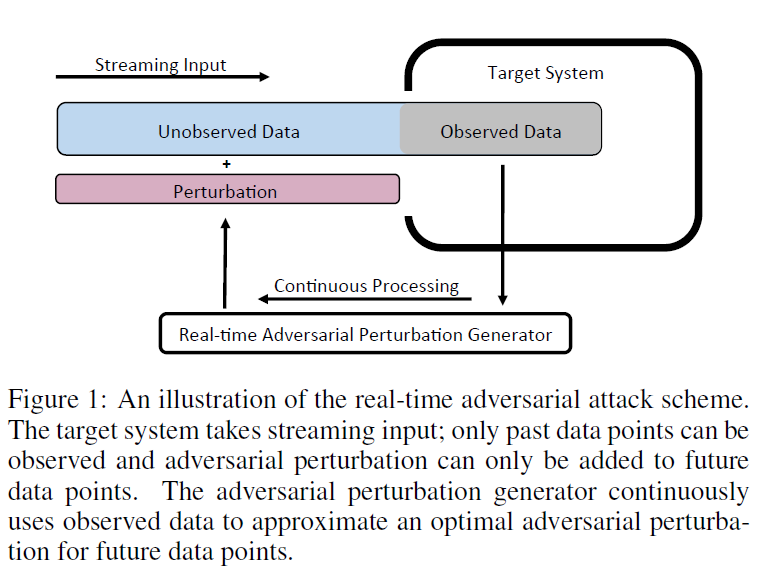
在实时处理场景中,攻击者只能观察数据样本的过去部分,并且只能向数据样本的未来部分添加扰动,而目标模型的决策将基于整个数据样本。
当攻击实时系统时,攻击者面临着观察空间和操作空间之间的权衡。也就是说,假设目标系统接受顺序输入x,攻击者可以选择在开始时设计对抗性扰动。然而,在这种情况下,攻击者对x没有任何观察,但是可以将扰动添加到x的任意时间点上,即,攻击者有最小的观察空间和最大的动作空间。相反,如果攻击者选择在末尾添加对抗性扰动,则攻击者可以完全观察到x,但不能向数据添加扰动(即,攻击者的观察量最大,但动作空间最小)。
提出了一种新的攻击方案,使用深度强化学习体系结构(如图1所示),连续使用观测数据来近似未来时间点的最优对抗性扰动。
2 实时对抗攻击
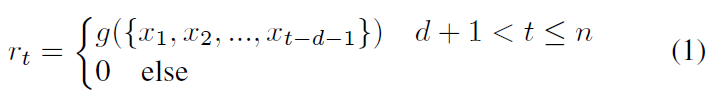
rt 是在t时刻添加的扰动,需要d的时间生成数据 添加扰动等。g根据t时刻之前的样本(减去延迟d),预测t时刻的最优扰动。
![]()
m()测量对抗性扰动的可感知性。
问题被描述为:(O, S, A, T, R)

对抗生成器只会在最后得到奖励。RL的目标是学习一个最优策略πg: at =g(ot),使奖励期望最大化。在这个问题中,环境是目标模型f,输入数据分布为Px。
用学习来代替优化。在几何术语中,攻击模型试图用最短的距离预测将原始示例x推出正确决策区域的方向。

攻击模型的一个挑战是对尚未观测到的数据“预测”未来的扰动。
此外,使用RL实现实时对抗性攻击的另一个挑战是稀疏奖励问题,即, agent只在最后收到奖励,很难根据观察到的数据和过去的行为来估计每个时间点的奖励。
模仿学习策略
通过模仿专家的行为来学习最优策略。具体来说,模仿学习需要一组决策轨迹,{T1, T2,..由专家生成,其中每一个判定轨迹由一系列“观测-动作”对组成。e, Ti = oi, ai....。这样的轨迹可以作为示范,教智能体如何在观察中表现。我们可以提取所有的专家意见,
![]()
o是输入特征,a是输出标签。
可以使用先进的非实时攻击模型生成样例扰动对![]()
x是不同的原始样本,r是添加了扰动之后的。
将x和r转换为o和a,建立一个训练集D,用它来进行监督,学习策略πg。
使用一个先进的非实时对抗样本生成技术作为专家。这些方法有两个大类别。第一类是基于梯度的,例如 FGSM, DeepFool。一般都有确定的优化策略。第二类gradient-free, 一般基于随机优化算法。
一个好的方法,除了攻击的成功率,还包括:
1. 添加约束的灵活性。
一般来说,随机优化算法比确定性优化算法在附加复杂约束条件方面更灵活。
2. 攻击者的知识。
攻击者应该根据攻击场景选择专家策略。
3.专家的决定论。
计算开销和速度
随机优化算法通常需要调用目标模型(或替代模型)数百或数千次才能找到解决方案。但是,由于我们使用深度神经网络g代替优化,无论我们选择模仿哪个专家,产生一个时间点对抗性扰动的计算开销固定为g的推理时间(用tg表示,即计算延迟)。在实时场景中,如果输入的采样频率高于1/tg,则产生器的速度不足以赶上流输入。然后攻击者需要通过修改g来降低更新频率来进行批处理,即,在一个推理中为nbatch将来的点生成一批nbatch操作。这可以降低nbatch时间的延迟要求。
方法架构
具体来说,神经网络可以分为两部分:编码器和解码器。
该编码器是一个递归神经网络,它将一个可变长度的输入映射到一个固定的二维编码。我们期望所学习的编码能从o中获得有用的特征;然后解码器对动作进行描述。
例如,在图2中的例子中,我们期望编码能够表示出数据样本渴望哪个集群,解码器可以根据这个信息找到最优扰动。然后,我们可以计算出预测动作和真实动作之间的误差,并使用标准的反向传播来更新g。
我们有nt轨道,每个轨道由n对 观测-动作 对组成。该数据集有n x nt样本,这可能非常大,会使训练速度变慢。事实上。来自同一轨迹的观测高度相关,即, ot+l与ot的唯一区别是ot+1多了一个观测点t+1;因此,递归神经网络将会有大量的重复计算(例如编码器)。为了加快训练速度,我们应该从同一个轨道中训练一批观测-动作对,在将输入Ot输入到g中得到at后,我们没有将新的输入Ot +1输入到g中,而是将xt+1输入到g中,得到g在at+1时的输出。图3演示了这个训练过程。
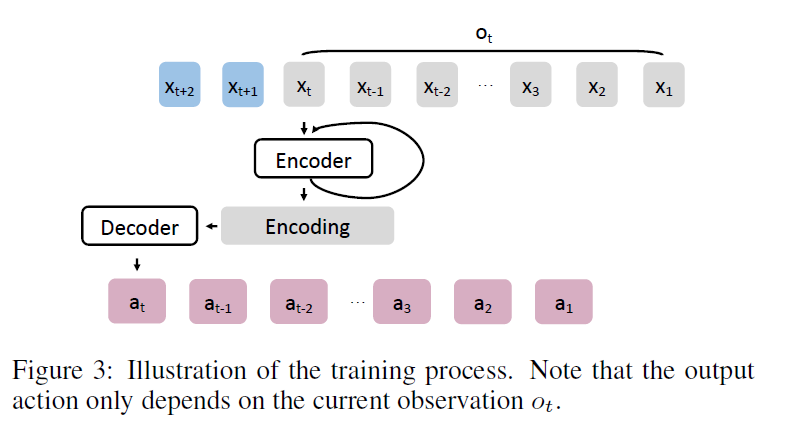
具体来说,这种方法避免了任何重复的编码器计算,可以看作是序列到序列的训练。注意,预测的动作只依赖于当前的观察结果(即这与其他应用程序(如机器翻译))中使用的序列训练不同,在机器翻译中,中间编码包含整个输入样本的信息。该算法的伪代码如算法1所示。

值得一提的是,尽管在本文中,为了简单起见,我们主要关注使用基本的行为克隆算法,有许多更高级的算法(e.g., Dataset Aggregation[Ross et al., 2011])在模仿学习和控制一定的学习,可以进一步提高攻击结构,例如,可以设计一个补救机制实时对抗扰动个发生器,如果它意识到它曾犯了一个错误的决定 ,允许其调整其未来战略。因此,将实时攻击形式化为增强学习问题不仅是自然的,而且允许我们应用现有的工具和算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号