CNN - 卷积神经网络
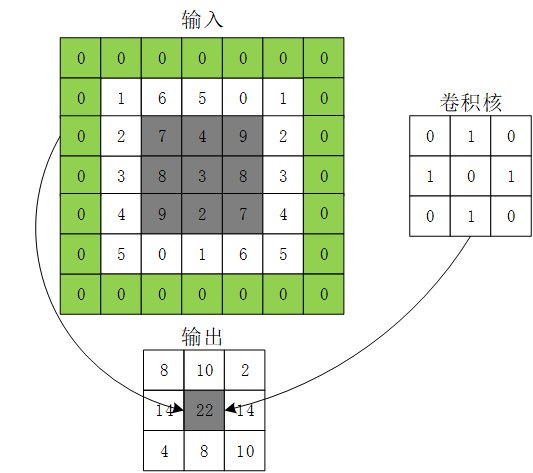
例:

卷积公式:
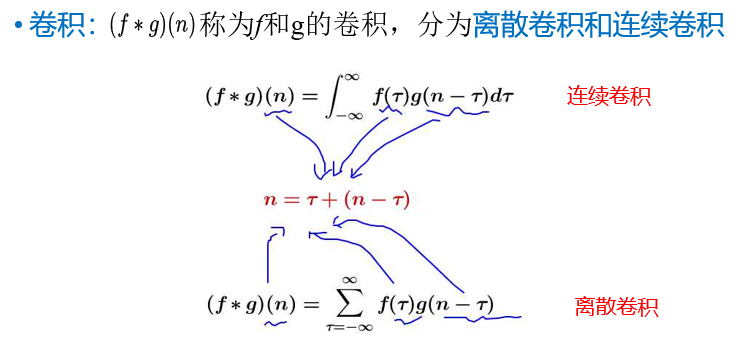
卷积和卷积没有什么特别的关系,只是计算步骤比较像,成为卷积神经网络名字的由来。
感受野:单个感觉神经元的感受野是感觉空间的特定区域(如体表或视野),在这个区域内,刺激会改变神经元的放电。
卷积神经网络的感受野
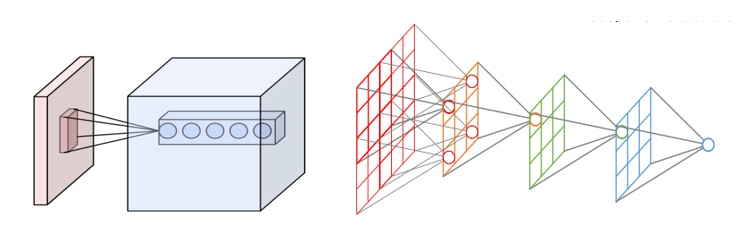
卷积神经网络的基本结构
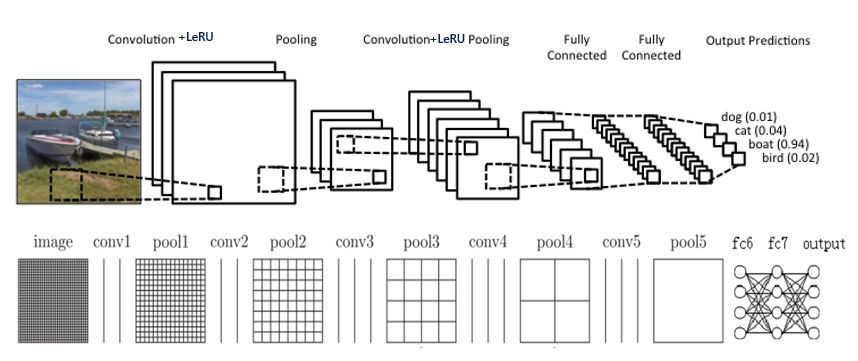
卷积神经网络的组成部分
卷积层+ReLU(Convolution)
池化层(Pooling)
全连接层(Full-connected)
卷积层
不同过滤器可检测不同特征。
卷积运算(二维):
![]()
卷积步长(stride):
滑动滤波器时每次移动的像素点个数
边缘扩充(addpad) :
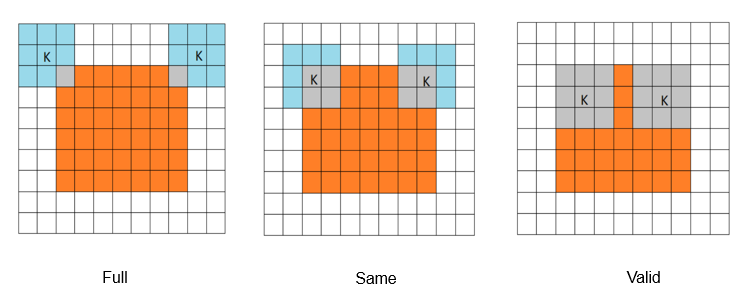
Full: 刚开始相交进行卷积
Same:输入和输出保持不变的卷积
Valid: 在图像内进行卷积
如果我们有一个𝑛×𝑛的图像,使用𝑓×𝑓的卷积核进行卷积操作,在进行卷积操作之前我们在图像周围填充𝑝层数据,步幅为s。输出的维度为:
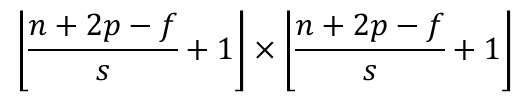
深度(卷积核个数):一个卷积层通常包含多个尺寸一致的卷积核
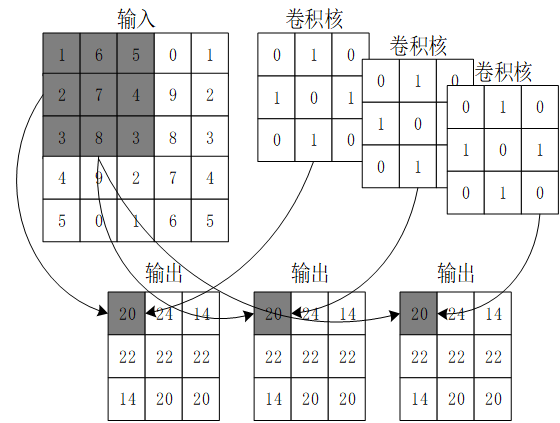

卷积核参数:可以通过训练得出
浅层卷积层:提取的是图像基本特征,如边缘、方向和纹理等特征
深层卷积层:提取的是图像高阶特征,出现了高层语义模式, 如“车轮”、“人脸”等特征
激活函数
Sigmoid激活函数
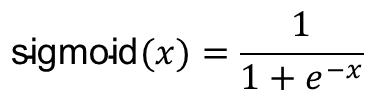
求导:

ReLu激活函数
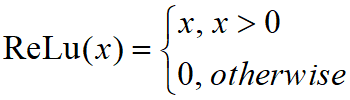
池化层
池化操作使用某位置相邻输出的总体统计特征作为该位置的输出,常用最大池化(max-pooling)和均值池化(average-pooling)。
池化层不包含需要训练学习的参数,仅需指定池化操作的核大小、操作步幅以及池化类型。
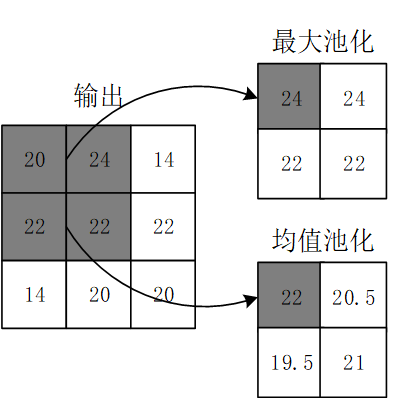
池化的作用
减少网络中的参数计算量,从而遏制过拟合
增强网络对输入图像中的小变形、扭曲、平移的鲁棒性(输入里的微小扭曲不会改变池化输出——因为我们在局部邻域已经取了最大值/平均值)。
帮助我们获得不因尺寸而改变的等效图片表征。这非常有用,因为这样我们就可以探测到图片里的物体,不管它在哪个位置。
全连接层
卷积层和池化层构成特征提取器;
全连接层的目的是对卷积层和池化层输出的特征图进行降维,可将特征信息转化为各个类别的概率,可作为分类器。
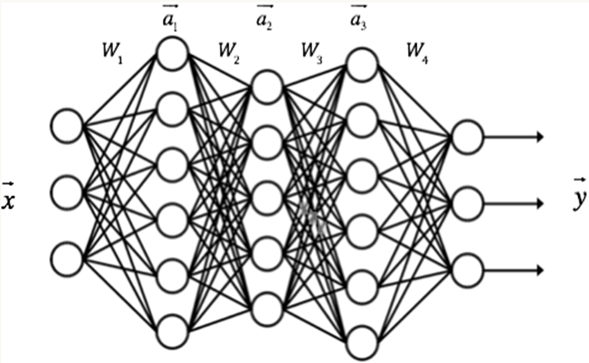
对于全连接层的每一个神经元,它用来连接前一层神经元的权重和偏置都只有一个。
输出层
分类问题:Softmax函数
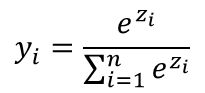
递归问题:线性函数
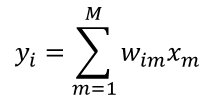
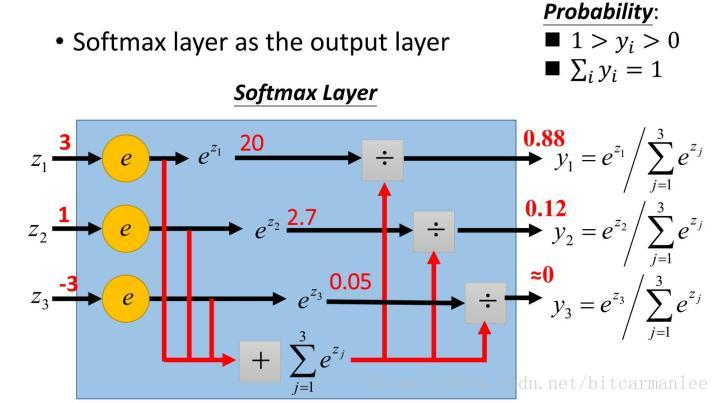
训练时使用反向传播算法计算误差相对于所有权重的梯度,并更新梯度。
为何选择“深"而非"广”的网络结构?
即使只有一层隐层,只要有足够的神经元,神经网络理论上可以拟合任意连续函数。为什么还要使用深层网络结构?
深度网络可从局部到整体理解图像
学习复杂特征时(例如人脸识别), 浅层的卷积层感受野小,学习到局部特征,深层的卷积层感受野大,学习到整体特征。
深度网络可减少权值数量
以宽度换深度,用多个小卷积替代一个大卷积, 在获得更多样特征的同时所需权值数量也更少。
经典卷积神经网络
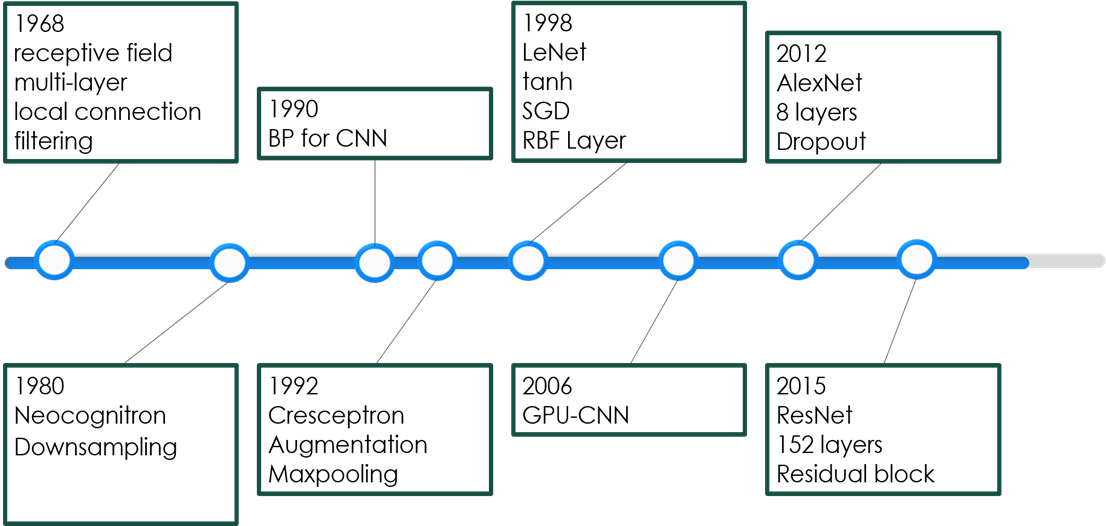
- LeNet-5
- AlexNet
- VGGNet
- Inception Net
- ResNet
- R-CNN系列
- YOLO系列

LeNet-5
LeNet-5由LeCun等人提出于1998年提出。
主要进行手写数字识别和英文字母识别。
经典的卷积神经网络,LetNet虽小,各模块齐全,是学习CNN的基础。
http://yann.lecun.com/exdb/lenet/
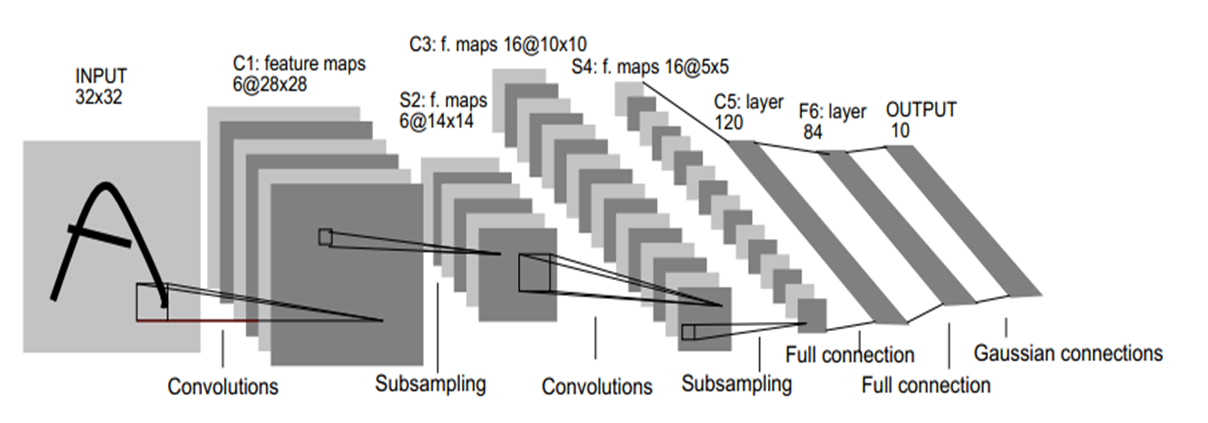
LeNet-5包含8层,分别是:输入层、卷积层、下采样层、卷积层、下采样层、全连接层、全连接层、全连接层(输出层)。
输入层:32*32的图片,即1024个神经元。
C1层:卷积层,选择6个特征卷积核,卷积核大小选择5*5,得到6个特征图,每个特征图的大小为32-5+1=28,即神经元的个数由1024减小到了28*28=784。(通过卷积运算,可以使原信号特征增强,并且降低噪音)
S2层:下采样层,使用最大池化进行下采样,池化的size选择(2,2),即对C1层28*28的图片进行分块,每个块的大小为2*2,这样我们可以得到14*14个块,将每个块中最大的值作为下采样的新像素,得到S1结果为:14*14大小的图片,且共有6个这样的图片。(利用图像局部相关性的原理,对图像进行子抽样,可以1.减少数据处理量同时保留有用信息,2.降低网络训练参数及模型的过拟合程度)
C3层:卷积层,卷积核大小为5*5,得到新的图片大小为10*10(14-5+1=10),这一层得到的结果是:16张10*10的图片。即需要16*6个卷积核,16*6*5*5个卷积参数。
S4层:下采样层,对C3的16张10*10的图片进行最大池化,池化块的大小为2*2。因此最后S4层为16张大小为5*5的图片。神经元个数已经减少为:16*5*5=400。
F5层:全连接层,输入矩阵大小为5*5*16。如果将此矩阵中的节点拉成一个向量,那么这就和全连接层的输入一样了。本层的输出节点个数为120,总共有5*5*16*120+120=48120个参数。
F6层:全连接层。本层的输入节点个数为120个,输出节点个数为84个,总共参数为120*84+84=10164个。
输出层:全连接层。本层的输入节点为84个,输出节点个数为10个,总共有参数84*10+10=850个。
输出层由欧式径向基函数(Euclidean Radial Basis Function)单元组成,每类一个单元,每个有84个输入。 换句话说,每个输出RBF单元计算输入向量和参数向量之间的欧式距离。输入离参数向量越远,RBF输出的越大。用概率术语来说,RBF输出可以被理解为F6层配置空间的高斯分布的负log-likelihood。给定一个输式,损失函数应能使得F6的配置与RBF参数向量(即模式的期望分类)足够接近。
| 层(layer) | 激活后的维度(Activation Shape) | 激活后的大小(Activation Size) | 参数w、b(parameters) |
| Input | (32,32,1) | 1024 | 0 |
| CONV1(f=5,s=1) | (28,28,6) | 4704 | (5*5+1)*6=156 |
| POOL1 | (14,14,6) | 1176 | 0 |
| CONV2(f=5,s=1) | (10,10,16) | 1600 | (5*5*6+1)*16=2416 |
| POOL2 | (5,5,16) | 400 | 0 |
| FC3 | (120,1) | 120 | 120*(400+1)=48120 |
| FC4 | (84,1) | 84 | 84*(120+1)=10164 |
| Softmax | (10,1) | 10 | 10*(84+1)=850 |
总结:卷积核大小、卷积核个数(特征图需要多少个)、池化核大小(采样率多少)这些参数都是变化的,这就是所谓的CNN调参,需要学会根据需要进行不同的选择。
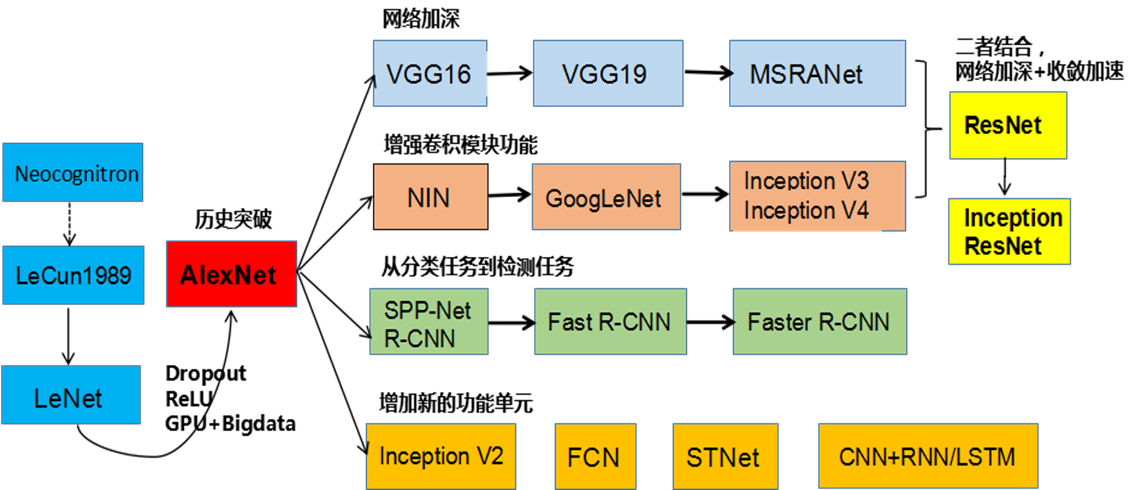
AlexNet
AlexNet由Hinton的学生Alex Krizhevsky于2012年提出。
获得ImageNet LSVRC-2012(物体识别挑战赛)的冠军,1000个类别120万幅高清图像,Error: 26.2%(2011)→15.3%(2012).
通过AlexNet确定了CNN在计算机视觉领域的王者地位。
What's New
首次成功应用ReLU作为CNN的激活函数
使用Dropout丢弃部分神元,避免了过拟合。
使用重叠MaxPooling(池化层的步长小于池化核的大小),一定程度上提升了特征的丰富性。
使用CUDA加速训练过程。
进行数据增强,原始图像大小为256×256的原始图像中重复截取224×224大小的区域,大幅增加了
数据量,大大减轻了过拟合,提升了模型的泛化能力。
LRN局部归一化:提升较大影响,抑制较小影响。
Local Respose Normalization (LRN)
局部响应归一化
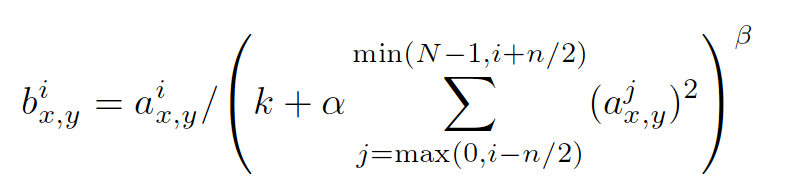
i:代表下标,你要计算像素值的下标,从0计算起
j:平方累加索引,代表从j~i的像素值平方求和
x,y:像素的位置,公式中用不到
a:代表feature map里面的 i 对应像素的具体值
N:每个feature map里面最内层向量的列数
k:超参数,由原型中的blas指定
α:超参数,由原型中的alpha指定
n/2:超参数,由原型中的deepth_radius指定
β:超参数,由原型中的belta指定
对图像的每个"位置",提升高响应特征,抑制低响应特征;”减少高激活神经元数量,提高训练速度,抑制过拟合;
被后来研究者发现无明显效果,故现在很少使用。
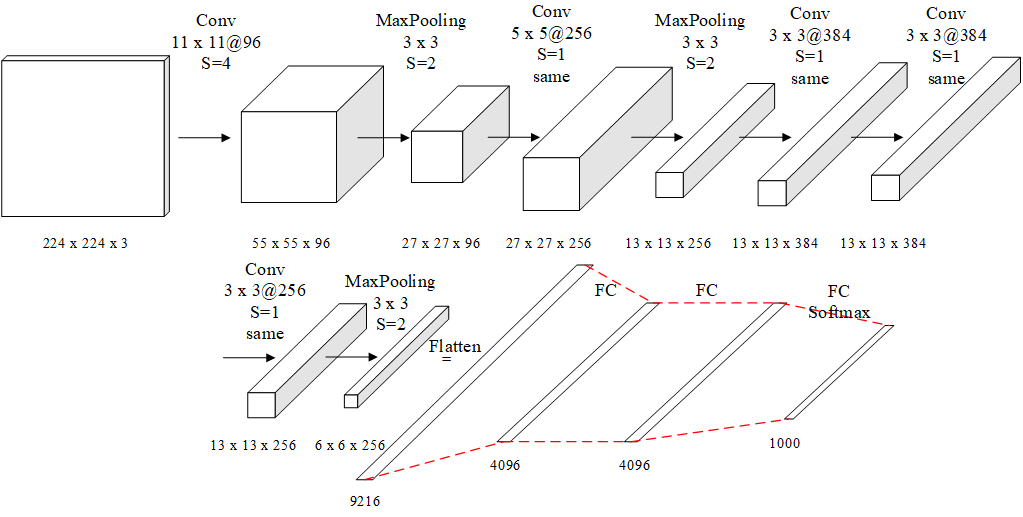
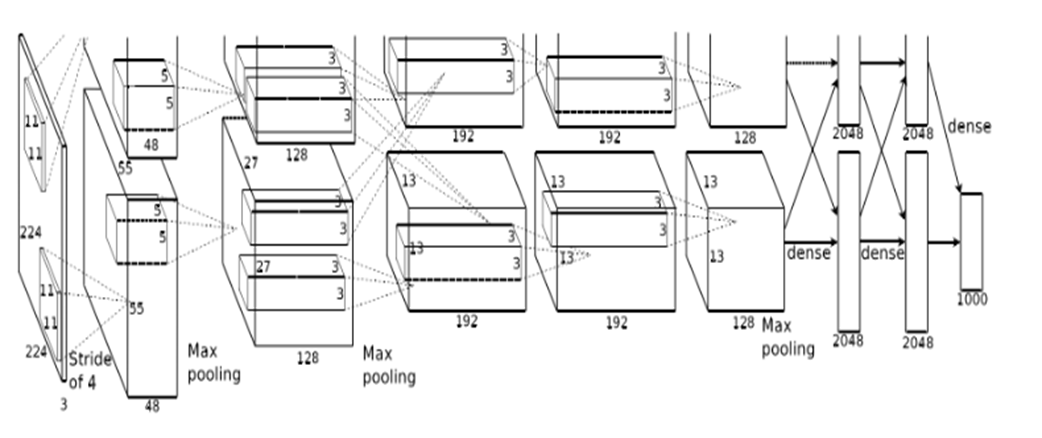
AlexNet可分为8个模块,包括5个卷积模块以及3个全连接模块。
输入层:使用大小为224×224×3图像作为输入。
1、AlexNet——模块一和模块二
结构类型为:卷积-激活函数(ReLU)-降采样(池化)-标准化
模块一:包含96个大小为11×11的卷积核,卷积步长为4,输出大小为55×55×96;然后构建一个核大小为3×3、步长为2的最大池化层进行数据降采样,进而输出大小为27×27×96。
模块二:包含256个大小为5×5卷积核,卷积步长为1,同时利用padding保证输出尺寸不变,因此该层输出大小为27×27×256;通过核大小为3×3、步长为2的最大池化层进行数据降采样,进而输出大小为13×13×256。
2、AlexNet——模块三和模块四
模块三和四也是两个same卷积过程,差别是少了降采样(池化层),原因就跟输入的尺寸有关,特征的数据量已经比较小了,所以没有降采样。
卷积核大小为3×3、步长为1的same卷积,共包含384个卷积核,因此两层的输出大小13×13×384。
3、AlexNet——模块五
模块五也是一个卷积和池化过程,和模块一、二一样的。模块五输出的其实已经是6\6的小块儿了。
(一般设计可以到1\1的小块,由于ImageNet的图像大,所以6\6也正常的。)
原来输入的227\227像素的图像会变成6\*6这么小,主要原因是归功于降采样(池化层),
当然卷积层也会让图像变小,一层层的下去,图像越来越小。
卷积核大小为3×3、步长为1的same卷积,但包含256个卷积核,进而输出大小为13×13×256;在数据进入全连接层之前再次通过一个核大小为3×3、步长为2的最大池化层进行数据降采样,数据大小降为6×6×256,并将数据扁平化处理展开为9216个单元。
4、模块六、七、八
模块六和七是全连接层,使用一个dropout层,去除一部分没有足够激活的层。
模块八是输出的结果,结合上softmax做出分类。有几类,输出几个结点,每个结点保存的是属于该类别的概率值。
全连接加上Softmax分类器输出1000类的分类结果。
AlexNet 成功的原因
使用多个卷积层,有效提取图像特征;
RELU、LRN、 Dropout 帮助提高训练速度,抑制过拟合;
数据增强扩大训练集,防止过拟合。
使用更多卷积层是否能进一步提升效果?
VGGNet
VGGNet由剑桥大学和DeepMind公司提出。
获得ImageNet LSVRC-2014亚军。
比较常用的是VGG-16,结构规整,具有很强的拓展性。
VGGNet16
相较于AlexNet,VGG-16网络模型中的卷积层均使用3*3的卷积核,且均为步长为1的same卷积,池化层均使用2*2的池化核,步长为2。
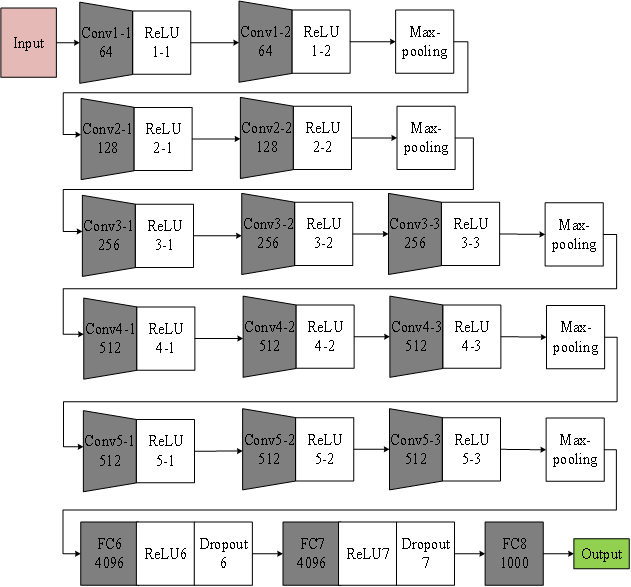

关于卷积核的选取:
两个卷积核大小为3*3的卷积层串联后的感受野尺寸为5*5,相当于单个卷积核大小为5*5的卷积层。
两者参数数量比值为(2*3*3)/(5*5)=72% ,前者参数量更少。
此外,两个的卷积层串联可使用两次ReLU激活函数,而一个卷积层只使用一次。
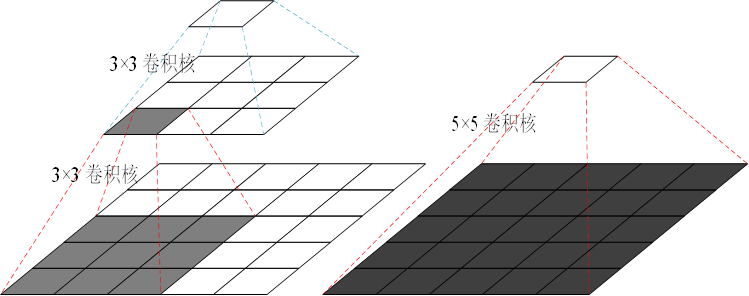
VGG成功的原因
更深的卷积网络,更多卷积层;
使用规则的小卷积替代大卷积,以及对权值进行与初始化,有效提高训练
收敛速度;
数据增强扩大训练集,防止过拟合。
卷积核还能不能更小?网络还能不能更深?
Inception Net
Google公司2014年提出。
获得ImageNet LSVRC-2014冠军。
文章提出获得高质量模型最保险的做法就是增加模型的深度(层数)或者是其宽度(层核或者神经元数),采用了22层网络。
Inception四个版本所对应的论文及ILSVRC中的Top-5错误率:
[v1] Going Deeper with Convolutions: 6.67% test error
[v2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift: 4.8% test error
[v3] Rethinking the Inception Architecture for Computer Vision: 3.5% test error
[v4] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning: 3.08% test error
Inception - v2
深度:层数更深,采用了22层,在不同深度处增加了两个loss来避免梯度消失问题。
宽度:Inception Module包含4个分支,在卷积核3x3、5x5之前、max pooling之后分别加上了1x1的卷积核,起到了降低特征图厚度的作用。
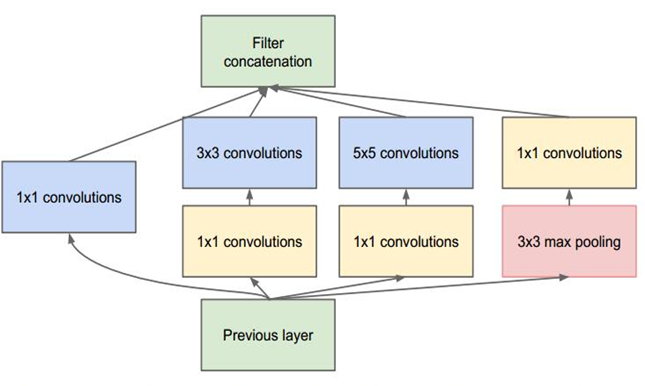
ResNet
ResNet(Residual Neural Network),又叫做残差神经网络,是由微软研究院的何凯明等人2015年提出。
获得ImageNet ILSVRC 2015比赛冠军。
获得CVPR2016最佳论文奖。
随着卷积网络层数的增加,误差的逆传播过程中存在的梯度消失和梯度爆炸问题同样也会导致模型的训练难以进行。
甚至会出现随着网络深度的加深,模型在训练集上的训练误差会出现先降低再升高的现象。
残差网络的引入则有助于解决梯度消失和梯度爆炸问题。
梯度消失和梯度爆炸问题原因
深度神经网络训练问题
激活函数问题
https://blog.csdn.net/qq_25737169/article/details/78847691
ResNet的核心是叫做残差块(Residual block)的小单元,残差块可以视作在标准神经网络基础上加入了跳跃连接(Skip connection)。

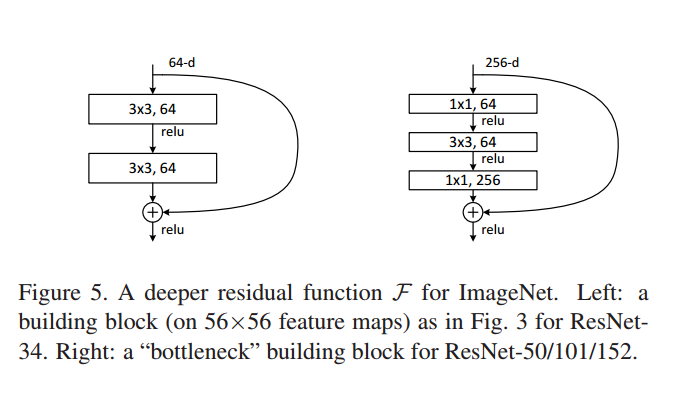
残差网络在训练时更容易收敛。
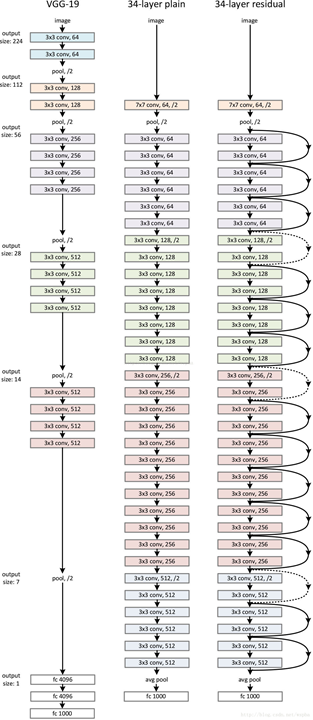
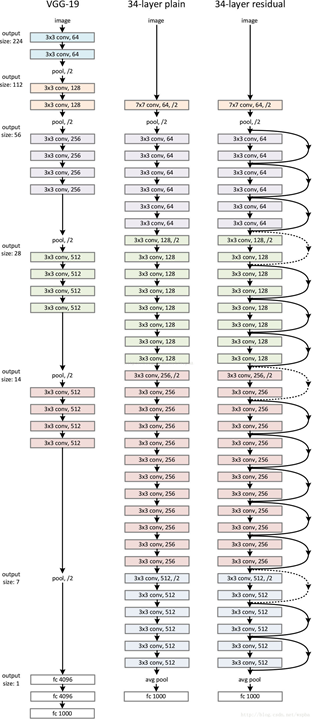
将残差块应用到普通网络
改造VGG得到plain-network
plain-network: 无跳转连接的普通网络;
基本全部由卷积层构成: fiter=3*3, stride=1, pad=SAME;
特征图尺寸的减小由 stride=2的卷积层完成;
若特征图的尺寸不变,则特征的数量也不变;若特征图的尺寸减半,则特征图的数量翻倍;
增加跳转连接得到resnet
实线:特征图尺寸和特征数量不变,直接相连;
虚线:特征图尺寸减半,特征图数量翻倍;
两种方法:
a. stride=2, 直接取值,不够的特征补0(不引入额外参数)
b. stride=2, 特征数量翻倍的1X1卷积做映射,卷积的权值经过学习得到,会引入额外参数
R-CNN系列
R-CNN
Region-CNN的缩写,主要用于目标检测。
来自2014年CVPR论文“Rich feature hierarchies for accurate object detection and semantic segmentation”
在 Pascal VOC 2012 的数据集上,能够将目标检测的验证指标 mAP 提升到 53.3%,这相对于之前最好的结果提升了整整 30%。
采用在 ImageNet 上已经训练好的模型,然后在 PASCAL VOC 数据集上进行 fine-tune
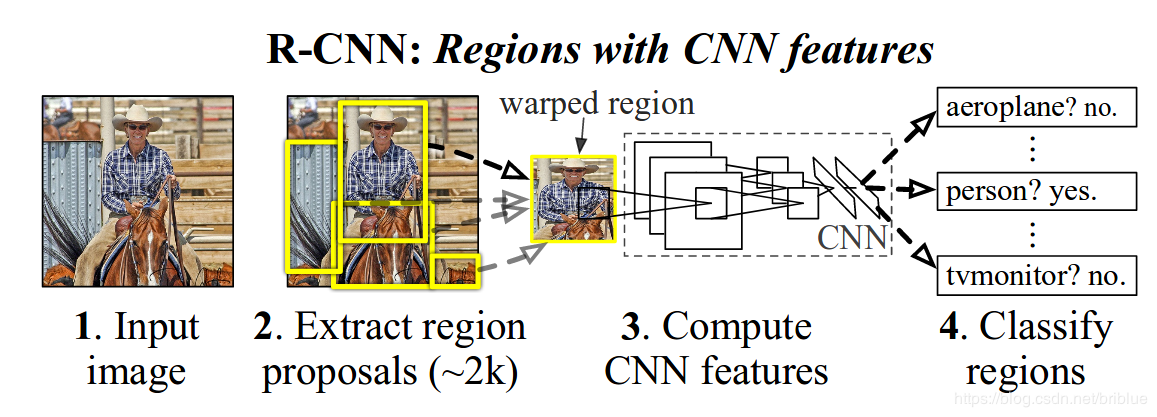
实现过程
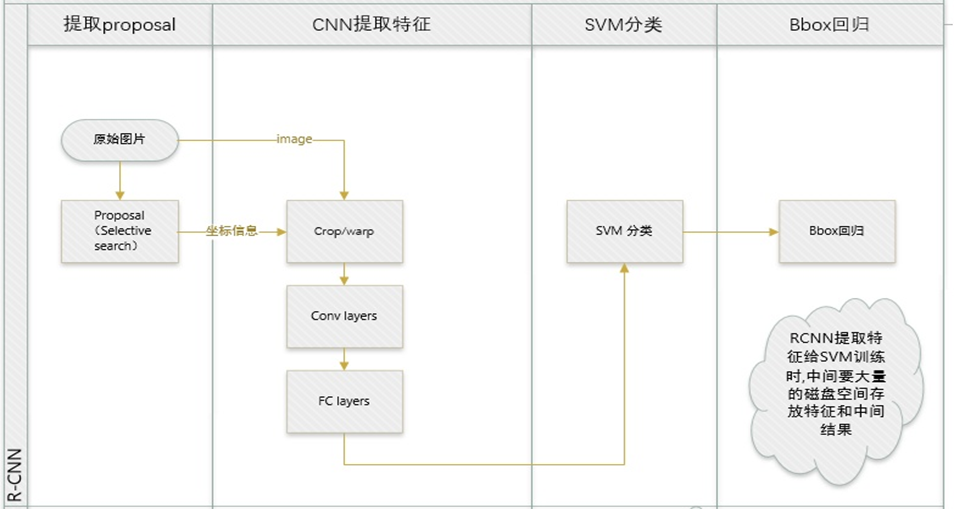
区域划分:给定一张输入图片,从图片中提取 2000 个类别独立的候选区域,R-CNN 采用的是 Selective Search 算法。
特征提取:对于每个区域利用 CNN 抽取一个固定长度的特征向量,R-CNN 使用的是 Alexnet。
目标分类:再对每个区域利用 SVM 进行目标分类。
边框回归:Bounding box Regression(Bbox回归)进行边框坐标偏移优化和调整。
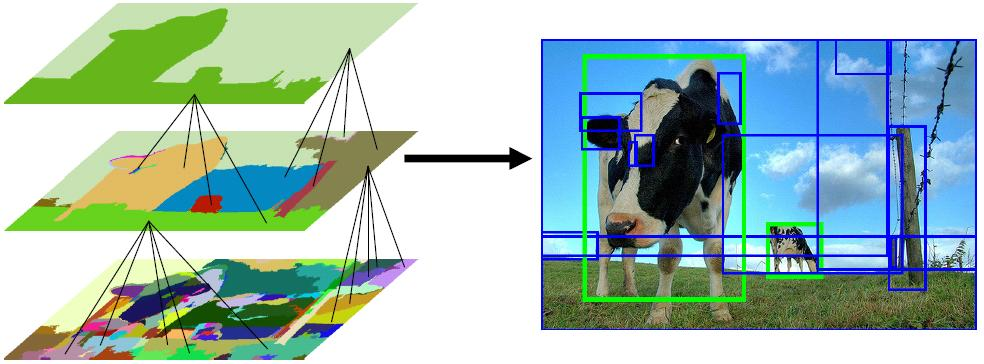
Selective Search 算法
核心思想:图像中物体可能存在的区域应该有某些相似性或者连续性的,选择搜索基于上面这一想法采用子区域合并的方法提取bounding boxes候选边界框。
首先,通过图像分割算法将输入图像分割成许多小的子区域;
其次,根据这些子区域之间的相似性(主要考虑颜色、纹理、尺寸和空间交叠4个相似) 进行区域迭代合并。每次迭代过程中对这些合并的子区域做bounding boxes(外切矩形),这些子区域的外切矩形就是通常所说的候选框。
Step 0:生成区域集R,参见论文《Efficient Graph-Based Image Segmentation》
Step 1:计算区域集R里每个相邻区域的相似度S={s1,s2,…}
Step 2:找出相似度最高的两个区域,将其合并为新集,添加进R
Step 3:从S中移除所有与step2中有关的子集
Step 4:计算新集与所有子集的相似度
Step 5:跳至step2,直至S为空

Bbox回归
核心思想:通过平移和缩放方法对物体边框进行调整和修正。


Fast R-CNN
联合学习(joint training): 把SVM、Bbox回归和CNN阶段一起训练,最后一层的Softmax换成两个:一个是对区域的分类Softmax,另一个是对Bounding box的微调。训练时所有的特征不再存到硬盘上,提升了速度。
ROI Pooling层:实现了单尺度的区域特征图的Pooling。
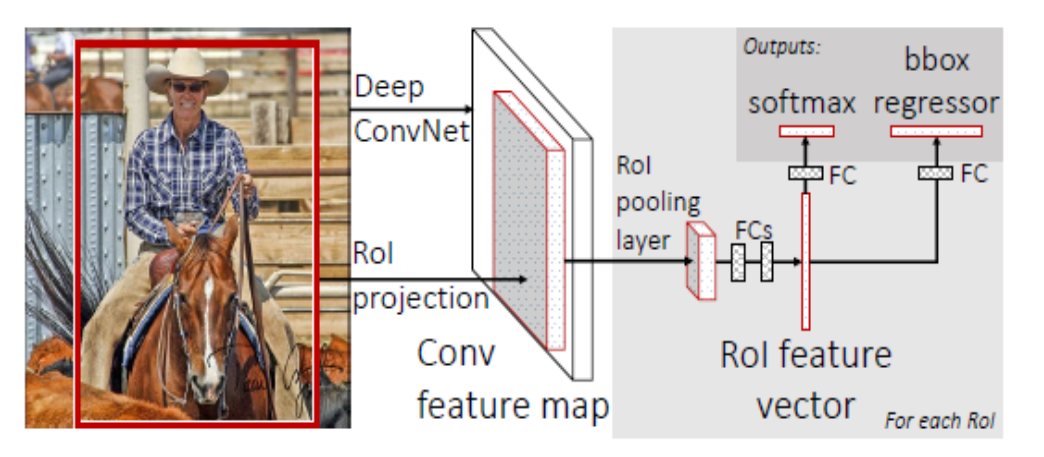
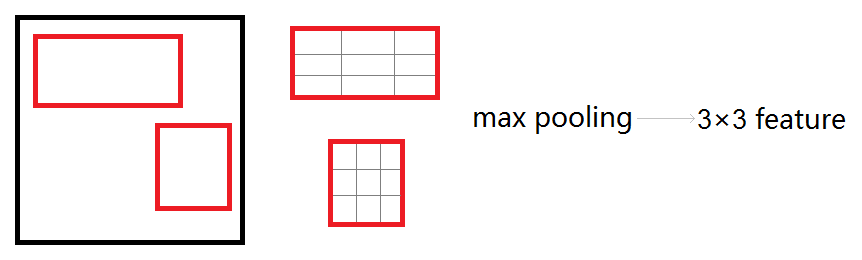
ROI Pooling层:将每个候选区域均匀分成M×N块,对每块进行max pooling。将特征图上大小不一的候选区域转变为大小统一的数据,送入下一层。
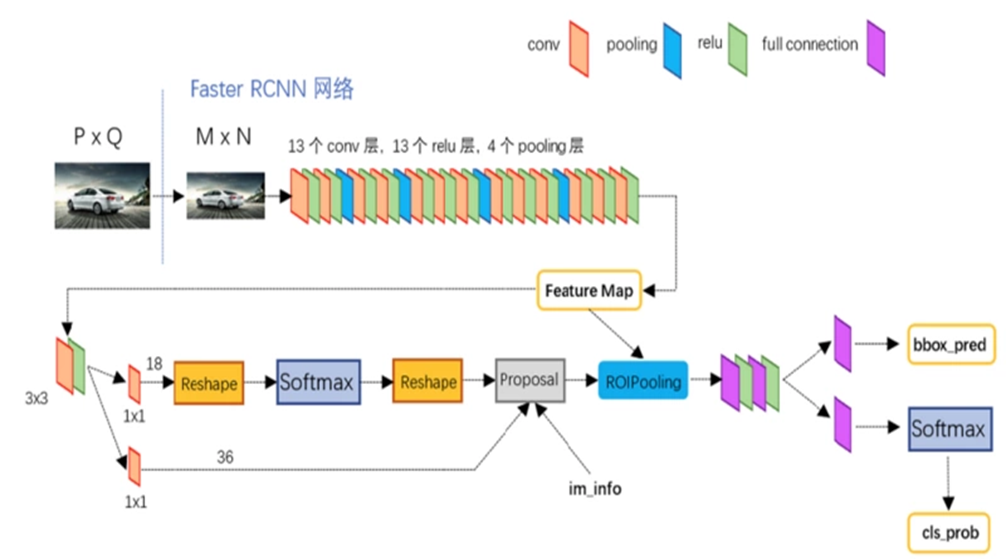
Faster R-CNN
RPN(Region Proposal Network):使用全卷积神经网络来生成区域建议(Region proposal),替代之前的Selective search。
YOLO系列
YOLO
与R-CNN系列最大的区别是用一个卷积神经网络结构就可以从输入图像直接预测bounding box和类别概率,实现了End2End训练。
速度非常快,实时性好。
可以学到物体的全局信息,背景误检率比R-CNN降低一半,泛化能力强。
准确率还不如R-CNN高,小物体检测效果较差。
YOLO2和YOLO9000