【 记忆网络 1 】 Memory Network
2015年,Facebook首次提出Memory Network。
应用领域:NLP中的对话系统。
1. 研究背景
大多数机器学习模型缺乏一种简单的方法来读写长期记忆。
例如,考虑这样一个任务:被告知一组事实或一个故事,然后必须回答关于这个主题的问题。
循环神经网络(RNN) 经过训练来预测下一个(一组)单词的输出。----> 记忆通常太小,并且不能准确地记住过去的事实(知识被压缩到密集的向量中)。
RNNs在记忆方面有困难。
然而,例如,在视觉和听觉领域,观看一部电影并回答有关它的问题需要长时间的记忆。
2. 基本思想
推理 + 长期记忆。
将机器学习策略中的推理与记忆组件相结合,学习如何有效地使用以及组件。
3. 具体方法
记忆网络的组成
记忆 m + 四个组件 I、G、O、R
m:由mi索引的objects数组,例如,向量数组或字符串数组。
I: input feature map (输入特征映射) 将输入转换为内部特征表示。
G: generalization (泛化) 根据新的输入更新记忆。在这个阶段,网络有机会压缩和泛化它的记忆以备将来使用。
O: output feature map (输出特征图) 在给定新的输入和当前记忆状态的情况下,在特征表示空间中生成一个新的输出。
R: response (响应) 将输出转换为所需的响应格式。例如,文本响应或操作。
流程
给定一个输入x(例如,输入字符、单词或句子),流程如下:
1. 将x转换为内部特征表示I(x);
2. 更新内存mi给定新的输入: mi = G(mi, I(x), m), ∀i ;
3. 给定新的输入和记忆,计算输出特征o: o = O(I(x), m) ; // 找到对应记忆
4. 最后,解码输出特征o给出最终响应:r = R(o)。 // 根据第三步找到的记忆生成答案
最简单的G:
![]()
H(.) : 选择记忆中的一个“插槽”。该简单G函数将在记忆中的H(x)的位置进行更新,其他地方不变。
思考:可以对记忆进行分组,根据输入的特征选择更新记忆中对应的组;记忆满了,可以加入“遗忘策略”。
4. 实施与评价
MemNN : memory neural networks // for text
基本模型:
I模块:输入文本
首先假设这是一个句子:也可以是一个事实的陈述,或者需要系统回答的问题(基于单词的输入序列)。这个文本以原始的形式存储在下一个可用的记忆槽中。
S(x)返回下一个空的内存槽N:mN=x, N=N+1。
G模块只用来存储这个新的记忆,旧的记忆不被更新。
O和R模块:推理的核心模块
O
对于给定x,模块O通过查找k个支持记忆来产生输出特征。将k设为2。
k=1,通过如下方式检索出得分最高的支持记忆:
sO对x和mi的匹配程度进行打分。
k=2,利用迭代的方式发现第二个支持记忆:
![]()
候选支持记忆mi需要基于初始输入和第一个支持记忆打分,方括号代表列表。
对列表的解释:作为bag-of-words模型,将使用x和mo1在袋子里被表示(但使用两种不同字典),这相当于使用sO(x, mi) + (mo1,mi),然而更复杂的建模的输入(例如,非线性)可能并不是一个加和。
最终的输出o为[x,mo1,mo2],作为模块R的输入。
R
最后,R需要产生一个文本回复r。
最简单的回复就是返回mok,也就是输出刚刚检索到的句子。
为了进行真实语句的生成,可以利用RNN来代替。
本文通过排序的方式将文本回复限定为一个单词:
![]()
W是字典中所有单词的集合,sR是对匹配进行打分的函数。
总结:O模块和R模块各有一种打分机制(sO, sR),分别用来找到最匹配记忆(一个字典)和该字典中最匹配的单词。
例子
未来回答问题x=“Where is the milk now?”
mo1=“Joe left the milk”
在给定[x,mo1]的情况下,再一次搜索第二个相关事实,也就是mo2=“Joe travelled to the office”(在Joe放下牛奶之前去过的最后一个地方)。
最后,模块R对给定的[x,mo1,mo2]对单词进行打分,输出r=“office”。

在文中实验中,打分函数sO和sR具有相同的形式,一个嵌入表示模型:
U是一个n×D矩阵,D是特征的数量,n是嵌入表示的维度。
Φx和Φy是用于将原始文本映射到D维的特征空间里。
特征空间最简单的选择是词袋表示,对于sO选择D=3|W|,也就是词典中的每个单词有三个不同的表示:
一个用于Φy(.),另外两个用于Φx(.),依赖于输入的单词来自于实际输入x或支持记忆,以使得它们可以不同建模。
sR也使用D=3|W|。这两个打分函数使用不同的矩阵UO和UR。
训练
在完全有监督的设置下训练,在训练数据中给定应有的输入和回答,以及被标记的支持这个回答的句子(测试集中只有输入)。
即,在训练时知道匹配记忆和单词最佳选择。训练使用一个边际排序损失和随机梯度下降(SGD)来进行。对于给定真实回复rr的问题x,以及支持的语句mo1,mo2(当k=2时),在参数UO和UR之上优化模型:
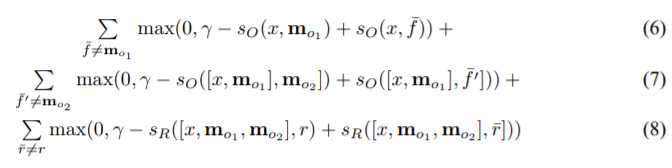
f¯,f′¯以及r¯都是错误的标签选择,γ是边际。
在SGD的每一步,采样选取f¯,f′¯,r¯(并非总和)。
使用RNN来实现记忆神经网络的R模块时(不是像上面那样用单词回复),将最后一项替换为语言建模任务中使用的标准对数似然函数,其中RNN的输入是序列[x,o1,o2,r]。
在测试的时候,在给定[x,o1,o2]的情况下输出r。
对比最简单的模型,即,使用k=1并且输出mo1的记忆作为回复r,将只使用第一项用来训练。
接下来的部分,是一些基于基础模型的扩展。
词序列作为输入
如果输入是词而非句子级别,即词是流的形式(就像RNN经常处理的那样),并且陈述和问题都没有进行词分割,此时,需要修改下之前描述的方法。
加入“分割”函数(通过学习得到),输入单词的最后没有分割的序列以寻找分割点。当分割器触发时(指示当前序列时分割段),将序列写入记忆,然后就可以像以前一样处理。
这个分割器的建模方式和其他模块类似,以嵌入表示模型的形式:
其中Wseg是一个向量(实际上是嵌入空间里的线性分类器的参数),c是用词袋表示的词序列。如果seg(c)>γ(γ是边际),那么这个序列被视为一个分割。通过这种方式,记忆神经网络在写操作时拥有一个学习模块。
利用散列表的高效记忆
如果存储的记忆集合十分庞大,那么对所有记忆进行打分的代价将十分巨大。
使用散列的技巧来加速查找:将输入I(x)散列到一个或多个桶中,然后只对相同桶里的记忆mi进行打分。
考察两种散列的方式:(i)散列词语;(ii)对词嵌入表示进行聚类。
方法(i)构造和词典中词语数量相同的桶,然后对于给定的语句将其散列到所包含词语的对应的桶中。(i)的问题在于记忆mi只有当和I(x)至少一个相同的词语时才被考虑。
方法(ii)试图通过聚类解决这个问题。在训练嵌入式矩阵UO之后,使用K-近邻进行聚类词向量(UO)i,所以给出了K个桶。然后将语句散列到所有包含词语落入的桶中。
因为词向量会和其同义词相接近从而彼此聚类到一起,所以将会对这些相似的记忆进行打分。输入和记忆之间匹配的词语都会按照定义被打分。选择K控制速度准确权衡。
建模写入时间
我们可以将何时一个内存被写入加入到我们的模型中。这对于回答固定事实的问题(“What is the capital of France?”)并不重要,但当回答一个如图1的故事相关的问题时却是重要的。对于给定的mj,实现这个的一种明显方式就是向表示Φx和Φy中加入编码jj的额外特征,假设jj遵循写时间(也就是,没有内存槽被重写)。然而,需要处理的事绝对时间而非相对时间。
代替打分输入,候选对利用上述的s学习一个定义在三元组上的函数sOΦt(x,y,y′)使用三个新的特征,取值0或1:是否x比y更加久,x比y'更加久,y比y′更加久。(也就是,我们将所有的Φ维度扩展3位,如果不适用的时候都设置位0)现在,如果Φt(x,y,y′)>0,模型更偏于选择y,如果Φt(x,y,y′)<0,模型更偏于选择y′y′。eq.2和eq.3中的argmax替换为在i=1,⋯,Ni=1,⋯,N的循环,在每步中持续赢取内存记忆(yy或者y′),即总是比较当前赢得的内存和下一个内存mimi。如果把时间特征移走,这个过程等价于之前的argmax。更多的细节将在附录C中讨论。
建模生词
即使对于阅读量很大的人类来说,生词也是经常遇到。比如指环王中的单词“Boromir”。一个机器学习模型如何处理这个问题?一个可能的方式是使用语言模型:通过生词周围的词语,来预测可能的单词,并假设这个生词和预测的单词语义相似。我们提出的方法正是采用这个想法,但是我们将其融入到我们的网络sO和sR而不是作为一个单独的步骤。
具体地,对于我们看到的单词,我们将其周围词保存在词袋中,一个词袋保存左侧的词语,另一个保存右侧的词语。任何未知的词语都可以这样表示。所以我们将特征表示D从3|W|扩展到5|W|来对这些上下文进行建模(每个词袋有|W|个特征)。我们的模型在训练阶段使用一种“dropout”技术来处理新的单词:d%的时间我们装作从未读取过任何词语,不使用n维嵌入表示这个词语,而是用它的上下文来代替。
精准匹配和生词
由于低维度nn嵌入式模型无法进行精准的词汇匹配。一个解决方案是对词对x,yx,y进行如下打分来替代之前的:
也就是,向学习到的嵌入式分数加入“词袋”的匹配(使用一个混合参数\lambda)。另一个,相关的方法还是在这个n−维的嵌入式空间里,但是为特征表示D扩展更多的匹配特征,比如,一个词汇。一个匹配的特征意味着这个词在x和y中都有出现。也就是,我们使用Φx(x)⊤UΦy(y,x)进行打分,其中Φy实际建立在x基础上:如果y中的词语与x中的一次匹配,我们就将这些匹配特征设置为1。未登录词可以使用相似的方法建模,在上下文词汇中使用匹配特征。最后,D=8|W|。
5. 不足
不能进行端到端的训练。
6. 未来工作
下一篇会写关于端到端的记忆网络。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步