
计算机组成原理 —— CPU
其实,发现自己处于 厦门马拉松的 30 公里状态,你知道还有更多的事情要干,但是就是动力很少。
鉴于知道厦门马拉松之后的体验很差,那么就坚持吧!
Knowledge will be the only prescription of anxiety for uncertainty.
2024年1月22日 晴天
完成所有大题,我认为,42.095 公里跑完了。
2024年1月19日 雨
身体是革命的本钱。无论每天做多少工作,必须每天保持运动!
【2010】下列寄存器,汇编语言程序员可见的是()
A 存储器地址寄存器(MAR)
B 程序计数器(PC)
C 存储器数据寄存器(MDR)
D 指令寄存器(IR)
答案:B
解析:这里注意,CPU 内部的 MAR,MDR,IR 都是不可见的
【2016】某计算机的主存空间为 4GB ,字长为 32 位,按字节编址,采用 32 位字长指令格式。若指令按字边界对齐存放,则程序计数器(PC)和指令寄存器(IR)的位数至少分别为()
A 30,30
B 30,32
C 32,30
D 32,32
答案:B
解析:
1. 假设,主存充满指令,一共能存放多少条指令?因此,存放的指令条数 = 4GB / 32bit = 1G = 2^30 bit 因此,PC 至少要 30 位,才能遍历整个主存;
2.指令寄存器 IR ,其长度至少能放置指令,长度为最短的指令长度,#IR = 32 位。
【2018】减法指令“sub R1, R2, R3” 的功能为 “(R1) - (R2) -> R3” ,该指令执行后将生成进位/错位标志 CF 和溢出标志 OF 。若 (R1) = FFFF FFFH, (R2) = FFFF FFF0H,则该减法指令执行后,CF 和 OF 分别为()
A CF=0, OF=0
B CF=1, OF=0
C CF=0, OF=1
D CF=1, OF=1
答案:A
解析:
1. R1 > R2,相减之后没有进位错位;
2. 也没有溢出问题,通常溢出出现在加法。
综上,CF=0, OF=0
【2009】冯 诺依曼计算机中指令和数据均以二进制形式存放在存储器中,CPU 区分它们的依据是()
A 指令操作码的译码结果
B 指令和数据的寻址方式
C 指令周期的不同阶段
D 指令和数据所在的存储单元
答案:C
解析:背出来
【2011】假定不采用 Cache 和指令预取技术,且机器机器处于“开中断” 状态,则在下列有关指令执行的过程中,错误的是()
A 每个指令周期中 CPU 都至少访问内存一次
B 每个指令周期一定大于等于一个 CPU 时钟周期
C 空操作指令的指令周期中任何寄存器的内容都不会被改变
D 当前程序在每条 指令执行结束时都可能被外部中断打断
答案:C
解析:空操作指令的 PC会自动自增
【2018】若某计算机最复杂指令的执行需要完成 5 个子功能,,分别由功能部件 A ~ E 实现,各功能部件所需时间分别为 80ps, 50ps, 50ps, 70ps, 50ps,采用流水线方式执行指令,流水段寄存器延时为 20ps,则 CPU 时钟周期至少为 ()
A 60ps
B 70ps
C 80ps
D 100ps
答案:D
解析:
1.指令每个子功能,假设都是对齐的,这样的话,子功能一律拨出 80ps
2.每个功能还要 20 ps delay, 时钟周期至少 20 + 80 = 100 ps
【2009】相对于微程序控制器,硬布线控制器的特点是()
A 指令执行速度慢,指令功能的扩展和修改容易
B 指令执行速度慢,指令功能的扩展和修改难
C 指令执行速度快,指令功能的扩展和修改容易
D 指令执行速度快,指令功能的扩展和修改难
答案:D
解析:
1. 硬布线属于硬件编程,速度快于微程序;
2. 硬布线烧制在 CPU 内部,不易扩展。
【2012】某计算机的控制器采用微程序控制方式,微指令中的操作控制字段采用字段直接编码法,共有 33 个微命令,构成 5 个互斥类,分别包含 7,3,12,5 和 6 个微命令,则操作控制字段至少有()
A 5位
B 6位
C 15位
D 33位
答案:C
解析:
1. 要覆盖 7, 3, 12, 5, 6 种命令,必须要有 3, 2, 4, 3, 3 个bit
2. 综上, 3+2+4+3+3 = 15 bit
因此,操作字段至少 15 位。
【2014】某计算机采用微程序控制器,共有 32 条指令,公共的取指令微程序包含 2 条微指令,各指令对应的微程序平均由 4 条微指令组成,采用断定法(下地址字段法)确定下条微指令地址,则微指令中下地址字段的位数至少是()
A 5 B 6 C 8 D 9
答案:C
解析:
1. 公共微指令 2 条;
2. 32条指令,每条指令有 4 条微指令。 32 * 4 = 128 条;
3. 128 + 2 = 130 条
覆盖上述指令,需要 8 比特。
【2017】下列关于主存储器(MM)和控制存储器(CS)的叙述中,错误的是()
A MM 在 CPU 外,CS 在 CPU 内;
B MM 按地址访问, CS 按内容访问;
C MM 存储指令和数据,CS 存储微指令;
D MM 用 RAM 和 ROM 实现,CS 用 ROM 实现
答案:B
解析:
1.CS 按照微指令的地址访问;
2. CS 是存放微程序的组件,集成在 CPU 内部,用 ROM 制成
综合题 - 1
若某机主频为 200 MHz ,每个指令周期平均为 2.5 个 CPU 周期,每个 CPU 周期平均包括 2 个主频周期,问题:
(1)该机器平均指令执行速度我多少 MIPS?
(2)若主频不变,但每条指令平均包括 5 个 CPU 周期,每个周期又包含 4 个主频周期,平均指令执行速度又为多少 MIPS?
(3)由此可得出什么结论?
解析:
(1) MIPS = million insctructions per second
每个指令周期 = 5 个主频周期 = 5 / 200M
平均执行速度 = 1/(5/200M) = 200M / 5 = 40 M I/S = 40 MIPS
(2)每个指令周期 = 5 * 4 个主频周期 = 20 / 200M
平均执行速度 = 1/(20/200M) = 200M / 20 =10 MIPS
(3)指令复杂程度会影响速度
综合题 - 2
(1)若存储器容量为 64K * 32位,指出主机中各寄存器的位数。
(2)写出硬布线控制器完成 STA X(X 为主存地址)指令发出的全部微操作命令及节拍安排。
(3)若采用微程序控制,还需增加哪些微操作?
解析:
(1)MDR = 32 bit, MAR = 16 bit
以下是没掌握的
PC 跟着 MDR:PC = 16比特
ALU 跟着 MDR:ALU=32比特,ACC=32比特,MQ = 32比特
还剩一些未知原因的:X = 32比特, IR = 32比特
(2)微操作节拍安排 STA X (Store the value of accumulator into memory address X)
将 ACC 的值存储在地址X 的主存中
T0 PC->MAR, 1->R // 读主存
T1 M(MAR) -> MDR, (PC)+1 -> PC
T2 MDR -> IR, OP(IR) -> ID // 间址
T0 Ad(IR) -> MAR, 1->W
T1 ACC -> MDR
T2 MDR -> M(MAR) // 寄存器数据存到主存
(3)若采用微程序控制,还需增加下列微操作:
取址周期
Ad(CMDR) -> CMAR // CS 内部取址
OP(IR) -> CMAR
执行周期
Ad(CMDR) -> CMAR
综合题 - 3
假设某机器有 80 条指令,平均每条指令由 4 条微指令组成,其中有一条取指微指令是所有指令公用的。已知微指令长度为 32 位,请估算控制存储器 CM 容量。
解析:
1.每条指令,1条微指令是公用的,3条指令私用。80 * 3 + 1 = 241 条 微指令;
2.32位 * 241 = 964 字节 -- 正确答案是,32位 * 256 = 1024 字节= 1KB
综合题 - 4
某微程序控制器中,采用水平型直接控制(编码)方式的微指令格式,后续微指令地址由微指令的下地址字段给出。已知机器共有 28 个微命令,6 个互斥的可判定的外部条件,控制存储器的容量为 512B * 40位。试设计其微指令的格式,说明理由。
解析:
1. 水平型,操作控制字段 + 判别测试字段 + 下地址字段
2. 微指令采用直接控制(编码)方式,操作控制字段 28 位;
下地址 9 位,因为 512 = 2^9
6个互斥类,需要 3 个比特覆盖
3.微指令格式: OP 28 位 + 判断测试 3 位 + 下地址 9 位
综合题 - 5
某机器共有 52 个微操作控制信号,构成 5 个相斥类的微命令组,各组分别包含 5,8,2,15,22 个微命令。已知可判定的外部条件有两个,微指令字长 28 位。
(1)按水平型微指令格式设计微指令,要求微指令的下地址字段直接给出后继微指令地址。
自己答案:长度 28 比特,控制信号 52个,6 比特;互斥类别 3 比特;下地址最长 22 位,留出 5 比特。 —— 这是错的
正确答案:
组长度 5,8,2,15,22 ,需要 3,4,2,4,5 比特;
判断条件2个,留出 2 比特;
下地址(后继地址),28 - 3 - 4 - 2 - 4 - 5 - 2 = 8 比特

微指令格式,记一记。
(2)指出控制存储器的容量。
CS/CM 的容量。
第一,后继地址 8 位,覆盖 2^8 SLOTs
第二,一个指令长度 28 位
综上,容量 = 2^8 * 28 位
综合题 - 6
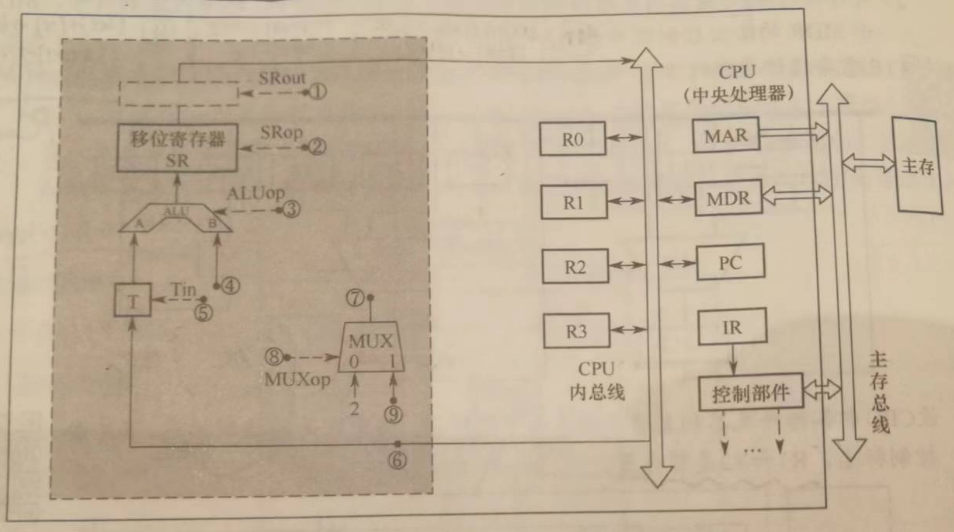
设 CPU 中各部件及其相互连接关系如下图所示,其中 W 是写控制标志;R 是读控制标准;R1, R2 是暂存器。
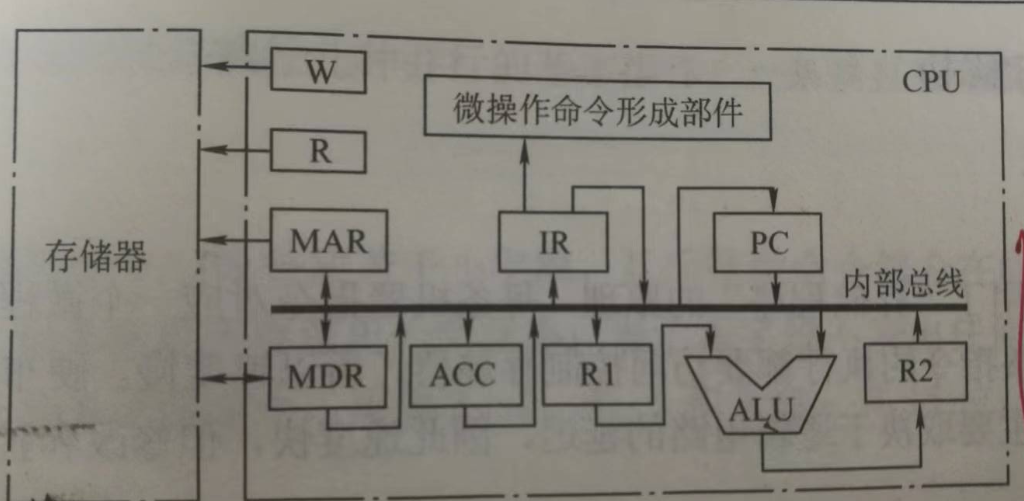
(1)写出指令 ADD #a (#为立即寻址特征,隐含的操作数在 ACC 寄存器中),在执行阶段所完成的微操作命令及节拍安排;
(2)假设要求在取指周期实现 PC + 1 -> PC ,且由 ALU 完成此操作(ALU 可以对它的一个源操作数完成加 1 的运算),以最少的节拍写出取指周期全部微操作命令及节拍安排/
解析:
(1)立即数加法
T0 Ad(IR) -> R1 // 立即数写到 R1
T1 (R1) + (ACC) -> R2
T2 (R2) -> ACC
(2)关键,要考虑总线冲突的问题
注意这里“由ALU完成该动作”,关键是 PC 内容要放到通用寄存器 R2,使用完毕之后,R2 的内容取出。
T0 PC -> MAR, 1->R
T1 M(MAR) -> MDR, (PC)+1 -> R2
T2 MDR -> IR, OP(IR) -> 微操作命令形成部件
T3 (R2) -> PC
综合题 - 7
【2017】在按字节编址的额计算机 M 上,f1 的部分源程序(阴影部分)如下,将 f1 中的 int 都改成 float,可得到计算 f(n) 的另一个函数 f2。
int f1(unsigned n) {
int sum=1, power=1;
for (unsigned i=0; i<=n-1; i++) {
power *= 2;
sum += power;
}
return sum;
}
对应机器级代码(包含指令的虚拟地址):
1 0040 1020 55 push ebp
...
for (unsigned i=0; i<=n-1; i++)
...
20 0040 105E 39 4D F4 emp dword ptr [ ebp - 0Ch ], ecx
...
{ power *= 2;
...
23 0040 1066 D1 E2 shl edx, 1
...
return sum;
...
35 0040 107F C3 ret
其中,机器级代码行包括行号、虚拟地址、机器指令和汇编指令。
(1)计算机 M 是 RISC 和 CISC?为什么?
(2)f1 的机器指令代码共占多少字节?要求写出计算过程。
(3)第 20 条指令 cmp 通过 i 减 n-1 实现对 i 和 n-1 的比较。执行 f1(0) 的过程中,当 i=0 时,cmp 指令执行后,进/错位标志 CF 内容是什么?写出计算过程。
(4)第 23 条指令 shl 通过左移操作实现了 power * 2 运算,在 f2 中能否用 shl 指令实现 power * 2?为什么?
解析:
(1)指令长短不一,是 CISC。
(2)f1 函数占据字节 = ( 0040 107F(H) - 0040 1020(H))字节 + 1字节 = 0000 005F(H) 字节 + 1字节 = 5*16 + 15 + 1 = 96字节
(3)CF=1。
i = 0000 0000(H) n-1 = FFFF FFFF(H)
当 i=0, 第 20 行 i 和 n-1 比较大小的时候,发生 0-(n-1),进位错位 CF =1 。 —— 记忆,小的数减去大的数,CF = 1
(4)f1 是 unsigned, f2 是 float。
因此 f2 不能用移位实现 乘法。
【2009】某计算机的指令流水线由 4 个功能段组成,指令流经各功能段的时间(忽略各功能段之间的缓存时间)分别为 90ns,80ns,70ns 和 60ns,则该计算机的 CPU 周期至少是()
A 90ns
B 80ns
C 70ns
D 60ns
答案:A
解析:
时钟周期以各功能段最长执行时间为准,因此 CLOCK CYCLE = 90ns
【2010】下列不会引起指令流水线阻塞的是()
A 数据旁路 B 数据相关 C 条件转移 D 资源冲突
答案:A
解析:
数据旁路,ALU处理完之后,结果直接存在寄存器中,作为下一个运算的输入数。
【2017】下列关于超标量流水线特性的叙述中,正确的是()
I. 能缩短流水线功能段的处理时间
II. 能在一个时钟周期内同时发射多条指令
III. 能结合动态调度技术提高指令执行并行性
A 仅 II B 仅 I,III C 仅 II, III D I, II 和 III
答案:C
解析:
1. 超标量的含义,同一个 CLOCK CYCLE,用多套硬件执行同一个动作,因此,一个 CLOCK CYCLE,同一个动作可以并行。
2.(I) 属于【超流水线技术】 (III)不涉及调度
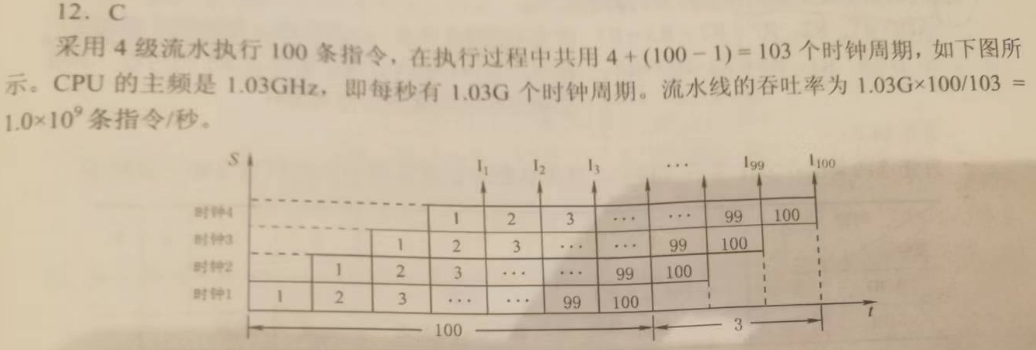
【2013】某 CPU 主频为 1.03 GHz ,采用 4 级指令流水线,每个流水段的执行需要 1个时钟周期,假定 CPU 执行了 100 条指令,在其执行过程中,没有发生任何流水线阻塞,此时流水线吞吐率()
A 0.25 * 10^9 条指令/秒
B 0.97 * 10^9 条指令/秒
C 1.0 * 10^9 条指令/秒
D 1.03 * 10^9 条指令/秒
答案:C
解析:
1. 主频 = 1.03 * 10^9 CLOCK CYCLE / second
2. 完成 100 条指令流水水,需要 4 + 100 -1 = 103 CLOCK CYCLE
3. 每秒钟,可以完成 1.03 * 10^9 / 103 = 1 * 10^7 个指令流水
4. 吞吐率 = 任务数量 / T(k) = 100 * 1 * 10^7 / 1 second = 1 * 10^9 条/秒
【2016】在无转发机制的五段基本流水线(取指、译码/读寄存器、运算、访写回寄存器)中,下列指令序列存在数据冒险的指令对是()
I1: add R1, R2, R3; (R2)+(R3) -> R1
I2: add R5, R2, R4; (R2) + (R4) -> R5
I3: add R4, R5, R3; (R5) + (R3) -> R4
I4: add R5, R2, R6; (R2) + (R6) -> R5
A I1 和 I2
B I2 和 I3
C I2 和 I4
D I3 和 I4
答案:B
解析:
发现 I2 到 I3,有写后读矛盾。
综合题 - 1
现有四级流水线,分别完成取指令、指令译码并取数、运算、回写四步操作:假设完成各部操作的时间依次为 100ns,100ns,80ns 和 50ns。
(1)流水线的操作周期应设计为多少?
(2)试给出相邻两条指令发生数据相关的例子(假设在硬件上不采取措施),试分析第二条指令要推迟多少时间进行才不会出错。
(3)若在硬件设计 加以改进,至少需要推迟 多少时间?
解析:
(1)CLOCK CYCLE = 100ns 取功能部件时间最长的。
(2)步骤:取址、译码、运算、回写。其中,运算和回写会产生数据相关。例如:
Add R1, R2, R3 R2 + R3 -> R1
Sub R4, R1, R5 R1 - R5 -> R4
该案例中,R1 存在数据 相关冲突。
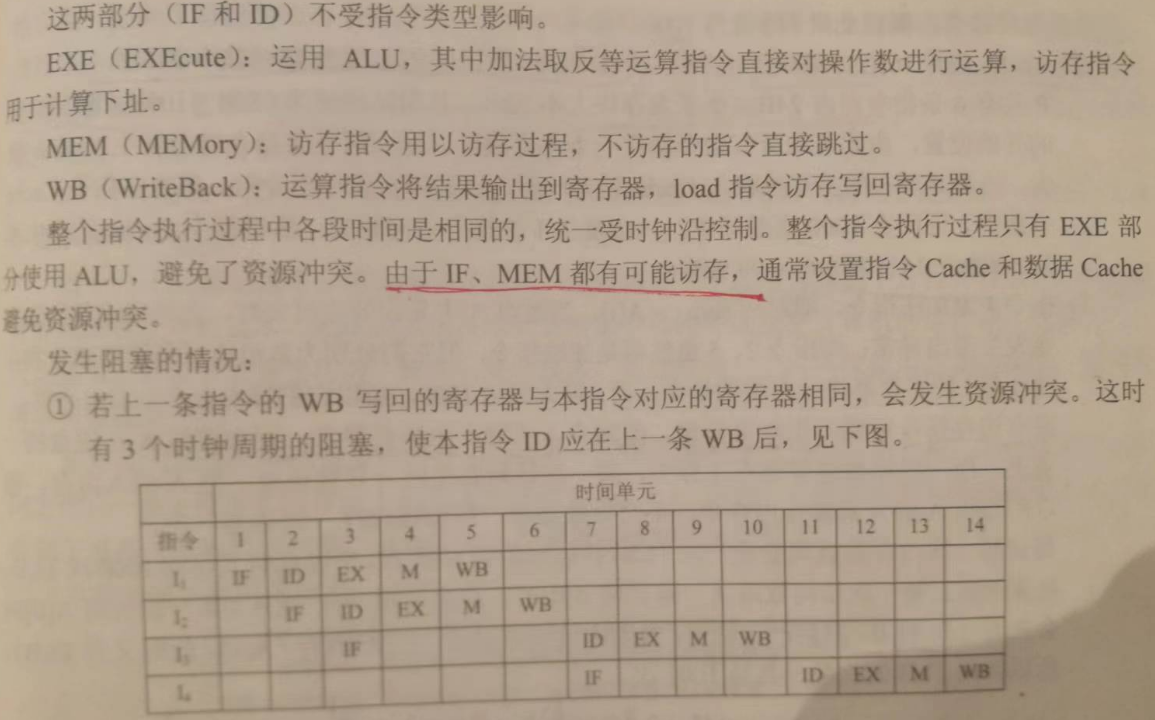
修正:第二条指令,译码取数阶段在上一条写回之后,因此至少停 2 CLOCK CYCLE
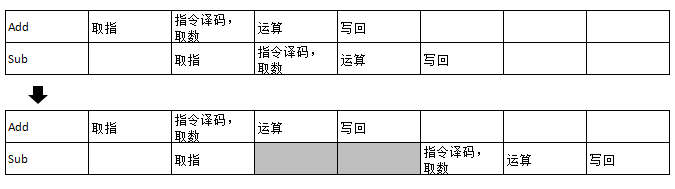
(3)该硬件。
第一,延后一个 CLOCK CYCLE;
第二,用数据旁路技术。

综合题 - 2
假设指令流水线分为 取指(IF)、译码(ID)、执行(EX)、回写(WB)4 个过程,共有 10 条指令连续输入此流水线。
(1)画出指令周期流程图;
(2)画出非流水线时空图;
(3)假设时钟周期为 100ns,求流水线的实际吞吐量(单位时间执行完毕的指令数)。
解析:
(1)IF - ID - EX - WB
(2)每间隔 4 CLOCK CYCLE 输出一个结果

(3)指令流水,通常都是重叠 k-1 段

(4)完成 10 条指令,需要 13 CLOCK CYCLE
吞吐量 = 10 / (100ns * 13) = 7.7 M条/second
2024年1月21日 阴天
综合题 - 3
流水线中有 3 类数据相关冲突:写后读(RAW)相关;读后写(WAR)相关;写后写(WRW)相关。判断以下 3 组指令各存在哪种类型的数据相关。
第一组
I1 ADD R1,R2,R3 (R2+R3)-> R3
I2 SUB R4,R1,R5 (R1-R5) -> R 4
第二组
I3 STA M(x), R 3 (R3) -> M(x), M(x) 是存储器单元
I4 ADD R3, R4, R5 (R4+R5) -> R3
第三组
I5 MUL R3, R1, R2 (R1)x(R2) -> R3
I6 ADD R3, R4, R5 (R4 + R5) -> R3
解析:
第一组 正常顺序是先写后读。矛盾是 RAW
第二组 正常顺序,先读后写,矛盾是 WAR
第三组 正常顺序是先写后写,矛盾是 WAW
综合题 - 4
某台单流水线多操作部件处理机,包含取指、译码、执行 3 个功能段,在该机上执行以下程序。取指和译码功能段各需要 1 个时钟周期,MOV 操作需要 2 个时钟周期, ADD 操作需要 3 个时钟周期,MUL 操作需要 4 个时钟周期,每个操作都在第一个时钟周期接收数据,在最后一个时钟周期把结果写入通用寄存器。
K: MOV R1, R0 (R0) -> R1
K+1: MUL R0, R1, R2 ( R1 ) x ( R2 ) -> R0
K+2: ADD R0, R2, R3 ( R2 ) x ( R3 ) -> R0
(1)画出流水线功能段及构图
(2)画出指令执行过程流水线和时空图
解析:
如何理解,以及设计对应指令运行?
第一,先确定三个指令放在同一个时间轴上操作。取址 - 译码 - MOV - MUL - ADD
第二,注意到,第二步的时候,是存在 R0。第三步也是存在 R0,参与计算的数值所在的寄存器,内容不变。因此,第二步,可以拿出数据,暂存着,再进行操作。
采取的措施,第三步 ADD,将 R2 和 R3 相乘,然后在第二步完成之后,在存在 R0。
(1)
流水线功能: 取址 - 译码 - MOV - MUL - ADD
(2)
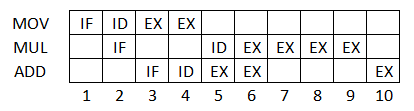
综合题 - 5
【2012】某 16 位计算机中,有符号整数用补码表示,数据 Cache 和指令 Cache 分离。下表给出了指令系统中的部分指令格式,其中 Rs 和 Rd 表示寄存器, mem 表示存储单元地址,(x) 表示寄存器 x 或存储单元 x 的内容。

该计算机采用 5 段流水方式执行指令,各流水段分别是取址(IF)、译码/读寄存器(ID)、执行/计算有效地址(EX)、访问存储器(M)和结果写回寄存器(WB),流水线采用“按序发射、按序完成” 方式,未采用转发技术处理数据相关,且同一寄存器的读和写操作不能在同一个时钟周期内进行。回答:
(1)若 int 型变量 x 的值 -513,存放在寄存器 R1 中,则执行“SHR R1” 后,R1 中的内容是多少?
(2)若在某个时间段中,有连续的 4 条指令进入流水线,在其执行过程中未发生任何阻塞,则执行这 4 条指令所需的时钟周期数是多少?
(3)若高级语言程序中某赋值语句为 x = a+b, x, a 和 b 均为 int 型变量、它们的存储单元地址分别表示为 [x], [a] 和 [b],该语句对应的指令序列,及其在指令流中执行过程如下:
I1 LOAD R1, [a]
I2 LOAD R2, [b]
I3 ADD R1, R2
I4 STORE R2, [x]
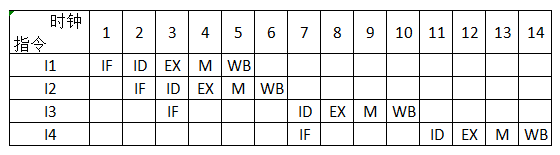
则这 4 条指令执行过程中 I3 的 ID 段和 I4 和 IF 段被阻塞的原因各是什么?
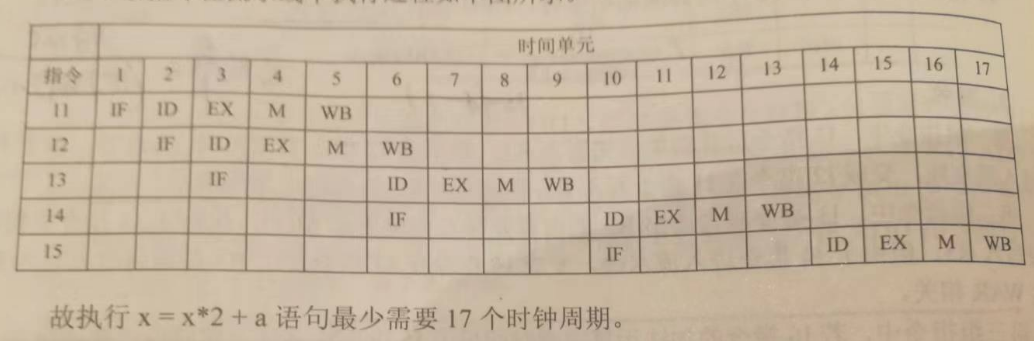
(4)若高级语言程序中某赋值语句 x=x*2+a, x 和 a 均为 unsigned int 类型的变量,它们的存储单元地址分别表示为 [x], [a], 则执行这条地址语句至少需要多少个时钟周期?要求模仿上图画出这条语句对应的指令序列及其在流水线中的执行过程示意图。
解析:
(1)右移 R1 中的数据;R1 = 1111 1101 1111 1111(B) 注意,INT 补码,取反加一。这个基础都忘了!
右移,左边补1。 SHR R1, R1 = 1111 1110 1111 1111(B) = FEFF(H)
(2)4条指令未阻塞,含义就是,每条指令的每个步骤都是挨着的,没有 DELAY。
4 条 五段式: 4 + 5 -1 = 8 CLK
(3)I3,是 将两个寄存器内容相加。前两条指令中,WB 是写入寄存器,因此,要在数据被写入寄存器之后,才开始间址;
第四个指令也是一样,必须扽到相加结果存到寄存器之后,再将 R2 的结果存到地址为 x 的主存位置。
(4)第四小题,是仿照第三小题,完成 x = x*2 + a 的 CLK 画图。
注意到,SHL R1 和上一步的 R2 没有关系,可以在 WB 阶段直接间址(ID)。
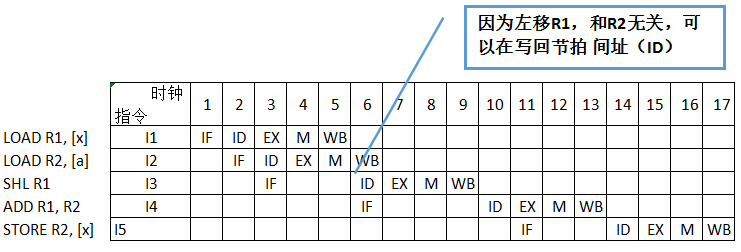
综合题 - 6
【2014】某程序中有循环代码段 P:"for (int i=0; i<N; i++) sum += A[i]" 。假设编译时变量 sum 和 i 分别分配在寄存器 R1 和 R2 中。常量 N 在寄存器 R6 中,数组 A 的首地址在寄存器 R3 中。程序段 P 的起始地址为 0804 8100 H ,对应的汇编代码和机器代码如下表:

执行上述代码的计算机 M 采用 32 位定长指令字,其中分支指令 bne 采用如下格式:

OP 为操作码; Rs 和 Rd 为寄存器编号,OFFSET 为偏移量,用补码表示,回答问题。
(1)M 的存储器编址单位是什么?
(2)已知 sll 指令实现左移功能,数组 A 中每个元素占多少位?
(3)表中 bne 指令的 OFFSET 字段的值是多少?已知 bne 指令采用相对寻址方式,当前 PC 内容为 bne 指令地址,通过分析表中指令地址和 bne 指令内容,推断 bne 指令的转移目标地址计算公式。
(4)若 M 采用如下“按序发射、按序完成” 的 5 级指令流水线:IF(取值)、ID(译码及取数)、EXE(执行)、MEM(访存)。WB (写回寄存器),且硬件不采取任何转发措施,分支指令的执行均引起 3 个时钟周期的阻塞,则 P 中哪些指令的执行会由于数据相关而发生流水线阻塞?哪条指令的执行会发生控制冒险?为什么指令 1 的执行不会因为与指令 5 的数据相关阻塞?
解析:
(1)计算机一个字 = 32 bit,指令地址间隔单位 = 4。于是,推断出是【按字节编址】,编址单位 1 字节,8 比特。
(2)数组A 中的元素是 int ,占据 4 字节。
(3)
【如何知道 bne OFFSET?】
针对指令机器码,后2字节数据,表示 OFFSET;
bne 机器码 1446 FFFA(H) ,后面 2 字节 FFFA (H) = 1111 1111 1111 1010 H = (取反加一) - 110 B = -6D
【如何计算跳转距离?】
找到【跳转目标地址】,找到【当前指令地址】,两个地址作差。
目标地址 08048100H,当前地址 08048114H + 4H (最后一条指令起始地址+指令长度),OFFSET = 08048100H - 08048118H = -1*16 - 8 = -24D
跳转次数 = -24 / -6 = 4
于是,转移指令的目标地址 = (PC) + 4 + 4*OFFSET
(4)阻塞指令,在第 2、3、4、6 条指令;
第六条指令到第一条指令,均用到第二号寄存器。因为,指令 6 有三个节拍的阻塞,因此不会受到影响。

综合题 - 7
【2014】假设对于上题中的计算机 M 和程序 P 的机器代码,M 采用页式虚拟存储管理; P 开始执行时,(R1) = (R2) = 0,(R6) = 1000,其机器代码已调入主存但不在 Cache 中;数组 A 未调入主存,且所有数组元素在同一页,并存储在磁盘的同一个扇区。回答问题。
(1)P 执行结束时,R2 内容是多少?
(2)M 的指令 Cache 和数据 Cache 分离。若指令 Cache 共有 16 行,Cache 和主存交换的块大小为 32 B,则其数据区的容量是多少?若仅考虑程序段 P 的执行,则指令 Cache 的命中率为多少?
(3)P 在执行过程中,哪条指令的执行可能发生溢出异常?哪条指令的执行可能产生缺页异常?对于数组 A 的访问,需要读磁盘和 TLB 至少各是多少次?
(本题和综合题-6,是一起的)
解析:
(1)
R2 的内容是 i ,P程序中,i >= N 时候,结束循环,N = (R6)= 1000
因此,程序结束时候,(R2) = 1000
(2)
主存块 = 32B,16行,则数据区 = 32B * 16 = 2^9 B = 512B —— 这是对的!
程序首次读到的时候,装入 Cache;
(R6) = 1000,于是,整个数组 4B* 1000 = 4 KB
遍历上述数组所有元素,需要装入 X 次,X = 4KB / 512B = 8次
总共访问 4000 次 Cache,故失效率 = 8 / 4000 = 0.2%, Cache 命中率 = 99.8%
这是错的!!
这道题这么理解,数据区 512B。
P程序,我指的是程序大小,24B。由于主存块 32B,因此,只要导入一次,就能跑程序了。
跑几次呢?
跑 6000 次,因为P程序 6条指令,一条指令执行 1000 次,P程序 跑 6000次。
失效几次呢?失效 1 次,程序装入 Cache ,此后,无需再装入。
失效率 = 1/ 6000, Cache 命中率 = 1 - 失效率 = 5999 / 6000 = 99.98%
(3)
溢出和缺页
 这是我自己做的答案,是错的!
这是我自己做的答案,是错的!
正确答案
1.首先,+1 或者 *2 都是小范围运算,所以不会溢出(注意,不是是否有溢出的可能性,毕竟只循环 1000 次)
2.其次,指令4 可能溢出;
3.指令3,类似间址,因此可能缺页。
TLB和磁盘读取次数
因为数组在同一页,只需要读磁盘一次,装入内存之后,只要不换出,可以一直访问;
TLB访问 1000 + 1 = 1001次,磁盘访问 1 次。
2024年1月22日,终于,这几天带着感冒和莫名不爽的身体,完成这部分笔记。
【2009, 2011】


【2018】


【2009】


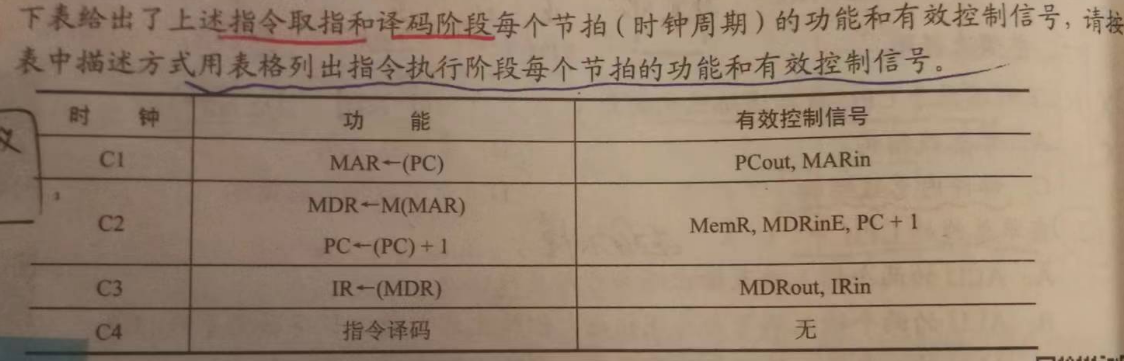
答案:


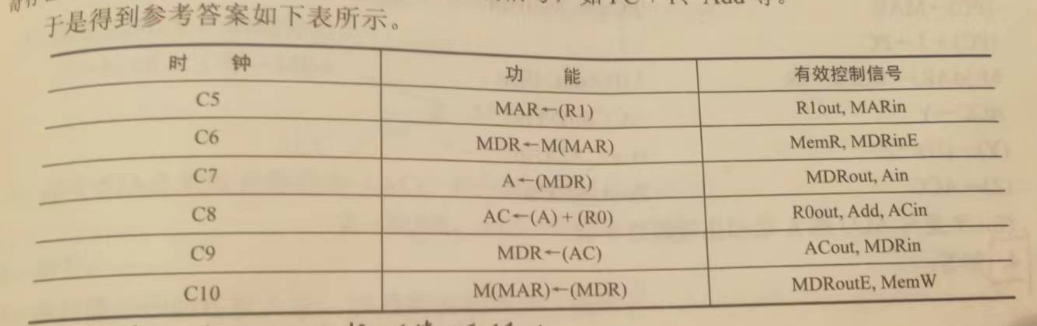
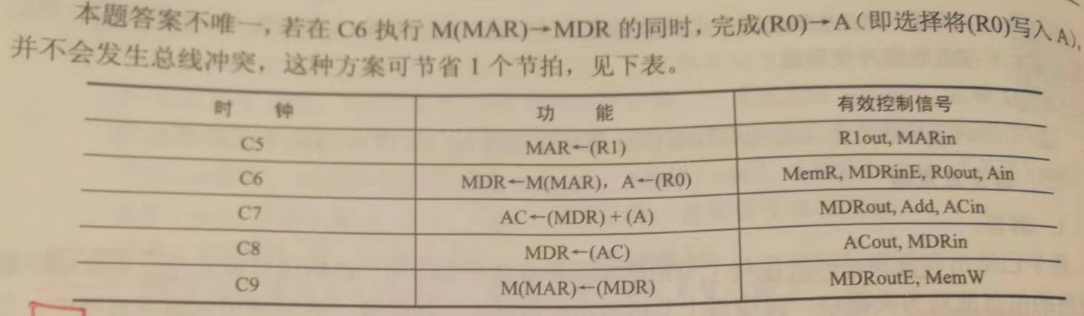
【2015】

答案:

这道题的讲解放在 ShoelessCai.com 小网站上了!!!
【2012, 2014】


【2017】


【2017】



答案:

【2013, 2016】

答案:
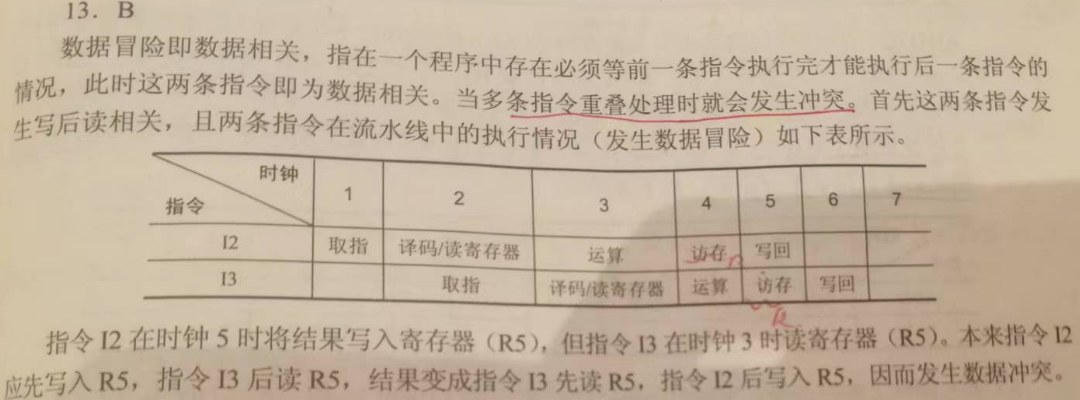
13 答案:B
数据冒险即数据相关,指在一个程序中存在必须等前一条指令执行完才能执行后一条指令的情况,此时这两条指令即为数据相关。当多条指令重叠处理时就会发生冲突。首先这两条指令发生写后读相关,且两条指令在流水线中的执行情况(发生数据冒险) 如下表所示。

指令I2 在时钟 5 时将结果写入寄存器(R5),但指令I3 在时钟 3 时读存器(R5)。本来指令I2 应先写入R5,指令 I3 后读 R5,结果变成指令 I3 先读 R5,指令 I2 后写入 R5,因而发生数据冲突。
14 答案:A
五阶段流水线可分为取指 IF、译码/取数ID、执行EXC、存储器读 MEM、写回 Write Back。数字系统中,各个子系统通过数据总线连接形成的数据传送路径称为数据通路,包括程序计数器、算术逻辑运算部件、通用寄存器组、取指部件等,不包括控制部件,选 A。
【2009,2010】

答案:

【2017】

答案:
5.答案: 选择 C。
超标量是指在CPU中有一条以上的流水线,并且每个时钟周期内可以完成一条以上的指令。其实质是以空间换时间。错误,它不影响流水线功能段的处理时间;II、II 正确。选C。
【2013, 2016】

答案:
【2012】

答案:

【2014】
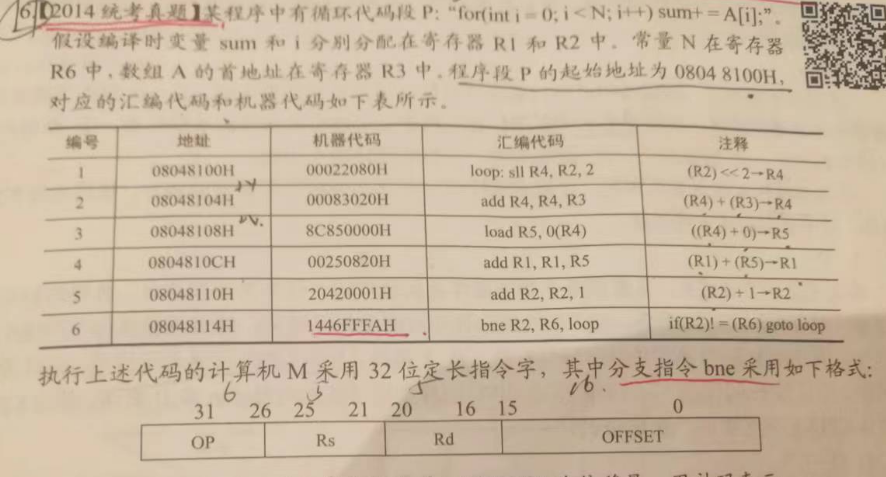
OP 为操作码 Rs 和 Rd 为寄存器编号。OFFSET 为偏移量,用补码表示。
请回答下列问题,并说明理由。
1) M的存储器编址单位是什么?
2)已知 sll 指令实现左移功能,数组A中每个元素占多少位??
3)表中 bne 指令的 OFFSET 字段的值是多?已知 bne 指今采用相对寻址方式,当前 PC 内容为 bne 指令地址,通过分析表中指令地址和 bne 指令内容推断 bne 指令的转移目标地址计算公式。
4)若 M 采用如下 “按序发射、按序完成” 的 5 级指令流水线:(取值)、ID(译码及取数)、EXE (执行)、MEM (访存)、WB (写回寄存器 ),且硬件不采取任何转发措施分支指令的执行均引起 3 个时钟周期的阻塞,则 P 中哪些指令的执行会由于数据
相关而发生流水线阻塞? 哪条指令的执行会发生控制冒险? 为什么指令 1 的执行不会因为与指令5的数据相关而发生阻塞?
答案:
【2014】

答案:


【2014】

答案:


关于总线
1.【2011】在系统总线的数据线上,不可能传输的是()
A 指令 B 操作数 C 握手(应答)信号 D 中断类型号
答案:C
2.【2009】假设某系统总线在一个总线周期中并行传输 4 字节信息,一个总线周期占用 2 个时钟周期,总线时钟频率为 10MHz,则总线带宽是i()
A 10 MB/s B 20MB/s C 40MB/s D 80MB/s
答案:B
3.【2012】某同步总线的时钟频率 100 MHz,宽度为 32 位,地址/数据线复用,每传输一个地址或数据占用一个时钟周期,若该总线支持突发(猝发)传输方式,则一次“主存写”总线事务传输 128 位数据所需要的时间至少是()
A 20ns B 40ns C 50ns D 80ns
答案:C
4.【2014】某同步总线采用数据线和地址线复用方式,其中地址/数据线有 32 根,总线时钟频率为 66 MHz ,每个时钟周期传送两次数据(上升沿和下降沿各传送一次数据),该总线的最大数据传输率(总线带宽)是()。
A.132 MB/s
B.264 MB/s
C.528 MB/s
D.1056 MB/s
答案:C
5.014】一次总线事务中,主设备只需给出一个首地址,从设备就能从首地址开始的若干连续单元读出或写入多个数据。这种总线事务方式称为()。
A 并行传输
B 串行传输
C 突发传输
D 同步传输
答案:C
22.【2015】下列有关总线定时的叙述,错误的()
A 异步通信方式中,全互锁协议最慢
B ii异步通信方式中,非互锁协议的可靠性最差
C 同步通信方式中,同步时钟信号可由各设备提供
D 半同步通信方式中,握手信号的采样由同步时钟控制
答案:C
23.【2016】下列关于总线设计的叙述中,错误()
A 并行总线传输比串行总线传输速度快
B 采用信号线复用技术可减少信号线数量
C 采用突发传输方式可提高总线数据传输率
D 采用分离事务通信方式可提高总线利用率
答案:A
24.【2017ii】下列关于多总线结构的叙述中,错误的是()
A 靠近 CPU 的总线速度较快
B 存储器总线可支持突发传送方式
C 总线之间须通过桥接器相连
D PCI - Express * 16 采用并行传输方式
答案:D
25.【2018】下列选项中,可提高同步总线数据传输率的是()
(I) 增加总线宽度
(II) 提高总线工作频率
(III) 支持突发传输
(IV) 采用地址/数据线复用
A 仅 I, II
B 仅 I,II,III
C 仅 III,IV
D I,II,III 和 IV
答案:B
总答案


ShoelessCai.com 值得您的关注!
