HBase学习的第六天--Hbase之过滤器
Hbase之过滤器
HBase 的基本 API,包括增、删、改、查等。
增、删都是相对简单的操作,与传统的 RDBMS 相比,这里的查询操作略显苍白,只能根据特性的行键进行查询(Get)或者根据行键的范围来查询(Scan)。
HBase 不仅提供了这些简单的查询,而且提供了更加高级的过滤器(Filter)来查询。过滤器可以根据列族、列、版本等更多的条件来对数据进行过滤,
基于 HBase 本身提供的三维有序(行键,列,版本有序),这些过滤器可以高效地完成查询过滤的任务,带有过滤器条件的 RPC 查询请求会把过滤器分发到各个 RegionServer(这是一个服务端过滤器),这样也可以降低网络传输的压力。
使用过滤器至少需要两类参数:
一类是抽象的操作符,另一类是比较器
作用
- 过滤器的作用是在服务端判断数据是否满足条件,然后只将满足条件的数据返回给客户端
- 过滤器的类型很多,但是可以分为三大类:
- 比较过滤器:可应用于rowkey、列簇、列、列值过滤器
- 专用过滤器:只能适用于特定的过滤器
- 包装过滤器:包装过滤器就是通过包装其他过滤器以实现某些拓展的功能。
比较过滤器
所有比较过滤器均继承自
CompareFilter。创建一个比较过滤器需要两个参数,分别是比较运算符和比较器实例。
public CompareFilter(final CompareOp compareOp,final ByteArrayComparable comparator) {
this.compareOp = compareOp;
this.comparator = comparator;
}
比较运算符
-
LESS <
-
LESS_OR_EQUAL <=
-
EQUAL =
-
NOT_EQUAL <>
-
GREATER_OR_EQUAL >=
-
GREATER >
-
NO_OP 排除所有
常见的六大比较器
BinaryComparator
按字节索引顺序比较指定字节数组,采用Bytes.compareTo(byte[])
BinaryPrefixComparator
通BinaryComparator,只是比较左端前缀的数据是否相同
NullComparator
判断给定的是否为空
BitComparator
按位比较
RegexStringComparator
提供一个正则的比较器,仅支持 EQUAL 和非EQUAL
SubstringComparator
判断提供的子串是否出现在中
代码演示(行键,列簇,列名,列值)
rowKey过滤器:RowFilter 行键过滤器
通过RowFilter与BinaryComparator过滤比rowKey 1500100010小的所有值出来
/**
* 需求1:通过RowFilter与BinaryComparator过滤比rowKey 1500100010小的所有值出来
*/
@Test
public void rowFilterAndBinaryFun(){
try {
//将表名封装成TableName的对象
TableName students = TableName.valueOf("students");
//获取表的实例
Table table = conn.getTable(students);
//创建Scan对象
Scan scan = new Scan();
//创建BinaryComparator比较器
BinaryComparator binaryComparator = new BinaryComparator(Bytes.toBytes("1500100010"));
//创建行键过滤
//老版本:RowFilter(final CompareOp rowCompareOp,final ByteArrayComparable rowComparator)
// RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.LESS, binaryComparator);
//新版本:public RowFilter(final CompareOperator op,final ByteArrayComparable rowComparator)
RowFilter rowFilter = new RowFilter(CompareOperator.LESS, binaryComparator);
//设置过滤器
scan.setFilter(rowFilter);
ResultScanner resultScanner = table.getScanner(scan);
//输出结果
printResultScanner(resultScanner);
}catch (Exception e){
e.printStackTrace();
}
}
列簇过滤器:FamilyFilter
通过FamilyFilter与SubstringComparator查询列簇名包含in的所有列簇下面的数据
/**
* 通过FamilyFilter与SubstringComparator查询列簇名包含in的所有列簇下面的数据
*/
@Test
public void FamilyFilterAndSubstringFun(){
try {
TableName students = TableName.valueOf("students2");
Table table = conn.getTable(students);
Scan scan = new Scan();
//创建包含比较器
SubstringComparator substringComparator = new SubstringComparator("jia");
//创建列簇过滤器
//public FamilyFilter(final CompareOperator op, final ByteArrayComparable familyComparator)
FamilyFilter familyFilter = new FamilyFilter(CompareOperator.EQUAL, substringComparator);
scan.setFilter(familyFilter);
ResultScanner resultScanner = table.getScanner(scan);
printResultScanner(resultScanner);
}catch (Exception e){
e.printStackTrace();
}
}
通过FamilyFilter与 BinaryPrefixComparator 过滤出列簇以i开头的列簇下的所有数据
//二进制前缀比较器 BinaryPrefixComparator
BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator(Bytes.toBytes("i"));
//创建列簇过滤器
FamilyFilter familyFilter = new FamilyFilter(CompareOperator.EQUAL, binaryPrefixComparator);
列名过滤器:QualifierFilter
通过QualifierFilter与SubstringComparator查询列名包含ge的列的值
/**
* 通过QualifierFilter与SubstringComparator查询列名包含 ‘级’ 的列的值
*/
@Test
public void qualifierFilterAndSubstringFun(){
try {
TableName students = TableName.valueOf("students2");
Table table = conn.getTable(students);
Scan scan = new Scan();
//创建包含比较器
SubstringComparator substringComparator = new SubstringComparator("级");
//创建列名过滤器
//public QualifierFilter(final CompareOperator op, final ByteArrayComparable qualifierComparator)
QualifierFilter qualifierFilter = new QualifierFilter(CompareOperator.EQUAL, substringComparator);
scan.setFilter(qualifierFilter);
ResultScanner scanner = table.getScanner(scan);
printResultScanner(scanner);
}catch (Exception e){
e.printStackTrace();
}
}
列值过滤器:ValueFilter
通过ValueFilter与BinaryPrefixComparator过滤出所有的cell中值以 "张" 开头的学生 只会查询出列值是张前缀的这一列,其他列不查
/**
* 通过ValueFilter与BinaryPrefixComparator过滤出所有的cell中值以 "张" 开头的学生
*/
@Test
public void valueFilterAndBinaryPrefixFun(){
try {
TableName students = TableName.valueOf("students2");
Table table = conn.getTable(students);
Scan scan = new Scan();
//创建二进制前缀比较器
BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator(Bytes.toBytes("张"));
//创建列值过滤器
//public ValueFilter(final CompareOperator valueCompareOp, final ByteArrayComparable valueComparator)
ValueFilter valueFilter = new ValueFilter(CompareOperator.EQUAL, binaryPrefixComparator);
scan.setFilter(valueFilter);
ResultScanner scanner = table.getScanner(scan);
printResultScanner(scanner);
}catch (Exception e){
e.printStackTrace();
}
}
专用过滤器
单列值过滤器:SingleColumnValueFilter
SingleColumnValueFilter会返回满足条件的cell所在行的所有cell的值(即会返回一行数据)
列值排除过滤器:SingleColumnValueExcludeFilter
与SingleColumnValueFilter相反,会排除掉指定的列,其他的列全部返回
rowkey前缀过滤器:PrefixFilter
通过PrefixFilter查询以15001001开头的所有前缀的rowkey
分页过滤器PageFilter
通过PageFilter查询三页的数据,每页10条
使用PageFilter分页效率比较低,每次都需要扫描前面的数据,直到扫描到所需要查的数据
可设计一个合理的rowkey来实现分页需求
# 注意事项:
客户端进行分页查询,需要传递 startRow(起始 RowKey),知道起始 startRow 后,就可以返回对应的 pageSize 行数据。这里唯一的问题就是,对于第一次查询,显然 startRow 就是表格的第一行数据,但是之后第二次、第三次查询我们并不知道 startRow,只能知道上一次查询的最后一条数据的 RowKey(简单称之为 lastRow)。
我们不能将 lastRow 作为新一次查询的 startRow 传入,因为 scan 的查询区间是[startRow,endRow) ,即前开后闭区间,这样 startRow 在新的查询也会被返回,这条数据就重复了。
同时在不使用第三方数据库存储 RowKey 的情况下,我们是无法通过知道 lastRow 的下一个 RowKey 的,因为 RowKey 的设计可能是连续的也有可能是不连续的。
由于 Hbase 的 RowKey 是按照字典序进行排序的。这种情况下,就可以在 lastRow 后面加上 0 ,作为 startRow 传入,因为按照字典序的规则,某个值加上 0 后的新值,在字典序上一定是这个值的下一个值,对于 HBase 来说下一个 RowKey 在字典序上一定也是等于或者大于这个新值的。
所以最后传入 lastRow+0,如果等于这个值的 RowKey 存在就从这个值开始 scan,否则从字典序的下一个 RowKey 开始 scan。
25 个字母以及数字字符,字典排序如下:
'0' < '1' < '2' < ... < '9' < 'a' < 'b' < ... < 'z'
需要注意的是在多台 Regin Services 上执行分页过滤的时候,由于并行执行的过滤器不能共享它们的状态和边界,所以有可能每个过滤器都会在完成扫描前获取了 PageCount 行的结果,这种情况下会返回比分页条数更多的数据,分页过滤器就有失效的可能。
包装过滤器
SkipFilter过滤器
SkipFilter包装一个过滤器,当被包装的过滤器遇到一个需要过滤的 KeyValue 实例时,则拓展过滤整行数据。下面是一个使用示例:
// 定义 ValueFilter 过滤器
Filter filter1 = new ValueFilter(CompareOperator.NOT_EQUAL,
new BinaryComparator(Bytes.toBytes("xxx")));
// 使用 SkipFilter 进行包装
Filter filter2 = new SkipFilter(filter1);
WhileMatchFilter过滤器
WhileMatchFilter 包装一个过滤器,当被包装的过滤器遇到一个需要过滤的 KeyValue 实例时,WhileMatchFilter 则结束本次扫描,返回已经扫描到的结果。
多过滤器综合查询
以上都是讲解单个过滤器的作用,当需要多个过滤器共同作用于一次查询的时候,就需要使用 FilterList。FilterList 支持通过构造器或者 addFilter 方法传入多个过滤器。
布隆过滤器
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
实际上,布隆过滤器广泛应用于网页黑名单系统、垃圾邮件过滤系统、爬虫网址判重系统等,Google 著名的分布式数据库 Bigtable 使用了布隆过滤器来查找不存在的行或列,以减少磁盘查找的 IO 次数,Google Chrome 浏览器使用了布隆过滤器加速安全浏览服务。
在很多 Key-Value 系统中也使用了布隆过滤器来加快查询过程,如 Hbase,Accumulo,Leveldb,一般而言,Value 保存在磁盘中,访问磁盘需要花费大量时间,然而使用布隆过滤器可以快速判断某个 Key 对应的 Value 是否存在,因此可以避免很多不必要的磁盘 IO 操作。
通过一个 Hash 函数将一个元素映射成一个位阵列(Bit Array)中的一个点。这样一来,我们只要看看这个点是不是 1 就知道可以集合中有没有它了。这就是布隆过滤器的基本思想。
运用场景
1、目前有 10 亿数量的自然数,乱序排列,需要对其排序。限制条件在 32 位机器上面完成,内存限制为 2G。如何完成?
2、如何快速在亿级黑名单中快速定位 URL 地址是否在黑名单中?(每条 URL 平均 64 字节)
3、需要进行用户登陆行为分析,来确定用户的活跃情况?
4、网络爬虫-如何判断 URL 是否被爬过?
5、快速定位用户属性(黑名单、白名单等)?
6、数据存储在磁盘中,如何避免大量的无效 IO?
7、判断一个元素在亿级数据中是否存在?
8、缓存穿透。
实现原理
假设我们有个集合 A,A 中有 n 个元素。利用k个哈希散列函数,将A中的每个元素映射到一个长度为 a 位的数组 B中的不同位置上,这些位置上的二进制数均设置为 1。如果待检查的元素,经过这 k个哈希散列函数的映射后,发现其 k 个位置上的二进制数全部为 1,这个元素很可能属于集合A,反之,一定不属于集合A。
比如我们有 3 个 URL
{URL1,URL2,URL3},通过一个hash 函数把它们映射到一个长度为 16 的数组上,如下:
若当前哈希函数为
Hash1(),通过哈希运算映射到数组中,假设Hash1(URL1) = 4,Hash1(URL2) = 6,Hash1(URL3) = 6,如下:
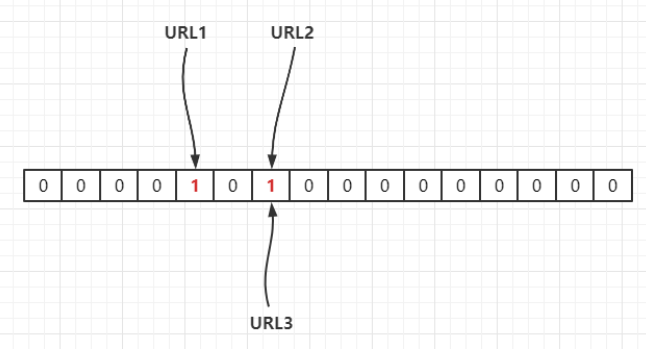
因此,如果我们需要判断
URL1是否在这个集合中,则通过Hash(urL1)计算出其下标,并得到其值若为 1 则说明存在。由于 Hash 存在哈希冲突,如上面
URL2,URL3都定位到一个位置上,假设 Hash 函数是良好的,如果我们的数组长度为 m 个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳m/100个元素,显然空间利用率就变低了,也就是没法做到空间有效(space-efficient)。解决方法也简单,就是使用多个 Hash 算法,如果它们有一个说元素不在集合中,那肯定就不在,如下:
Hash1(URL1) = 3,Hash2(URL1) = 5,Hash3(URL1) = 6
Hash1(URL2) = 5,Hash2(URL2) = 7,Hash3(URL2) = 13
Hash1(URL3) = 4,Hash2(URL3) = 7,Hash3(URL3) = 10
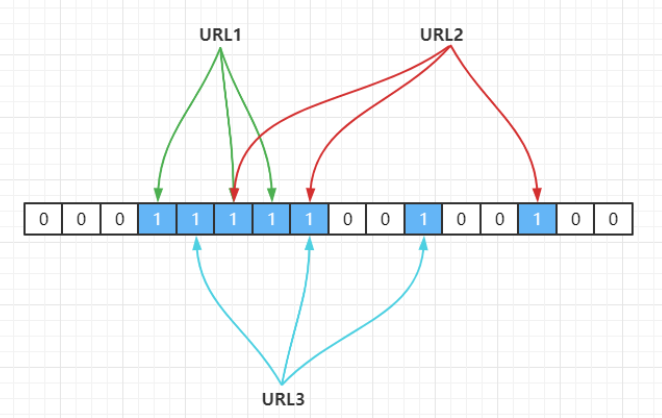
以上就是布隆过滤器做法,使用了k个哈希函数,每个字符串跟 k 个 bit 对应,从而降低了冲突的概率。
误判现象
上面的做法同样存在问题,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断这个值存在。比如此时来一个不存在的
URL1000,经过哈希计算后,发现 bit 位为下:
Hash1(URL1000) = 7,Hash2(URL1000) = 8,Hash3(URL1000) = 14
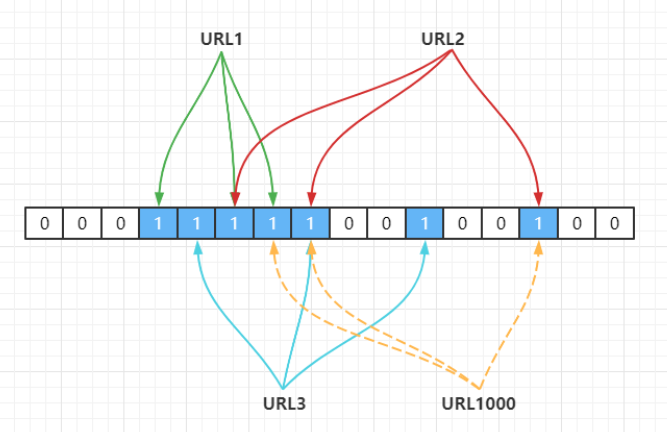
但是上面这些 bit 位已经被
URL1,URL2,URL3置为 1 了,此时程序就会判断URL1000值存在。这就是布隆过滤器的误判现象,所以,布隆过滤器判断存在的不一定存在,但是,判断不存在的一定不存在。
布隆过滤器可精确的代表一个集合,可精确判断某一元素是否在此集合中,精确程度由用户的具体设计决定,达到 100% 的正确是不可能的。但是布隆过滤器的优势在于,利用很少的空间可以达到较高的精确率。
控制粒度
a)ROW
根据KeyValue中的行来过滤storefile
举例:假设有2个storefile文件sf1和sf2,
sf1包含kv1(r1 cf:q1 v),kv2(r2 cf:q1 v)
sf2包含kv3(r3 cf:q1 v),kv4(r4 cf:q1 v)
若是设置了CF属性中的bloomfilter为ROW,那么得(r1)时就会过滤sf2,get(r3)就会过滤sf1
b)ROWCOL
根据KeyValue中的行+限定符来过滤storefile
举例:假设有2个storefile文件sf1和sf2,
sf1包含kv1(r1 cf:q1 v),kv2(r2 cf:q1 v)
sf2包含kv3(r1 cf:q2 v),kv4(r2 cf:q2 v)
若是设置了CF属性中的布隆过滤器为ROW,不管获得(R1,Q1)仍是获得(R1,Q2),都会读取SF1 + SF2;而若是设置了CF属性中的布隆过滤器为 ROWCOL,那么GET(R1, q1)就会过滤sf2,get(r1,q2)就会过滤sf1
c)NO
默认的值,默认不开启布隆过滤器
实现:
在建立表时加入一个参数就能够了
try {
//使用HTableDescriptor类创建一个表对象
HTableDescriptor students = new HTableDescriptor("students");
//在创建表的时候,至少指定一个列簇
HColumnDescriptor info = new HColumnDescriptor("info");
info.setBloomFilterType(BloomType.ROW); //<===========================================
//将列簇添加到表中
students.addFamily(info);
//真正的执行,是由HMaster
//hAdmin
hAdmin.createTable(students);
System.out.println(Bytes.toString(students.getName()) + "表 创建成功。。。");
} catch (IOException e) {
e.printStackTrace();
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号