HBase学习的第四天--HBase的进阶与API
HBase进阶与API
一、Hbase shell
1、Region信息观察
创建表指定命名空间
在创建表的时候可以选择创建到bigdata17这个namespace中,如何实现呢?
使用这种格式即可:‘命名空间名称:表名’
针对default这个命名空间,在使用的时候可以省略不写
create 'hbase01:t1','info'
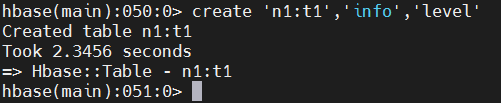
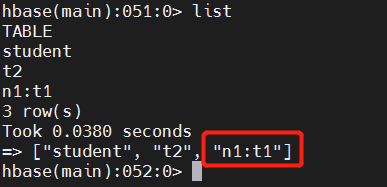
此时使用list查看所有的表
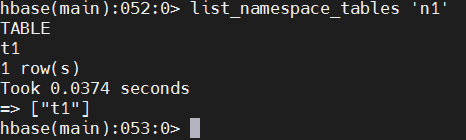
如果只想查看bigdata17这个命名空间中的表,可以使用命令list_namespace_tables
list_namespace_tables 'n1'
查看region中的某列簇数据
hbase hfile -p -f /hbase/data/default/tbl_user/92994712513a45baaa12b72117dda5e5/info/d84e2013791845968917d876e2b438a5
# 行键的设计在hbase中有三大设计原则:唯一性 长度不宜过长 散列性
put 'students_test1','1500100001','info:name','施笑槐'
put 'students_test1','1500100001','info:age','22'
put 'students_test1','1500100001','info:gender','女'
put 'students_test1','1500100001','info:clazz','文科六班'
put 'students_test1','1500100002','info:name','吕金鹏'
put 'students_test1','1500100002','info:age','24'
put 'students_test1','1500100002','info:gender','男'
put 'students_test1','1500100002','info:clazz','文科六班'
put 'students_test1','1500100003','info:name','单乐蕊'
put 'students_test1','1500100003','info:age','22'
put 'students_test1','1500100003','info:gender','女'
put 'students_test1','1500100003','info:clazz','理科六班'
put 'students_test1','1500100004','info:name','葛德曜'
put 'students_test1','1500100004','info:age','24'
put 'students_test1','1500100004','info:gender','男'
put 'students_test1','1500100004','info:clazz','理科三班'
1500100005,宣谷芹,22,女,理科五班
put 'students_test1','1500100005','info:name','宣谷芹'
put 'students_test1','1500100005','info:age','22'
put 'students_test1','1500100005','info:gender','女'
put 'students_test1','1500100005','info:clazz','理科五班'
刷新数据:flush 'tb'
合并数据:major_compact 'tb'
1.1 查看表的所有region
list_regions '表名'

1.2 强制将表切分出来一个region
# 切分的行键是包括在下一行里的
split '表名','行键'

但是在页面上可以看到三个:过一会会自动的把原来的删除
1.2 查看某一行在哪个region中
locate_region '表名','行键'

可以hbase hfile -p -f xxxx 查看一下
查看命令使用(指定4个切割点,就会有5个region)
help 'create'
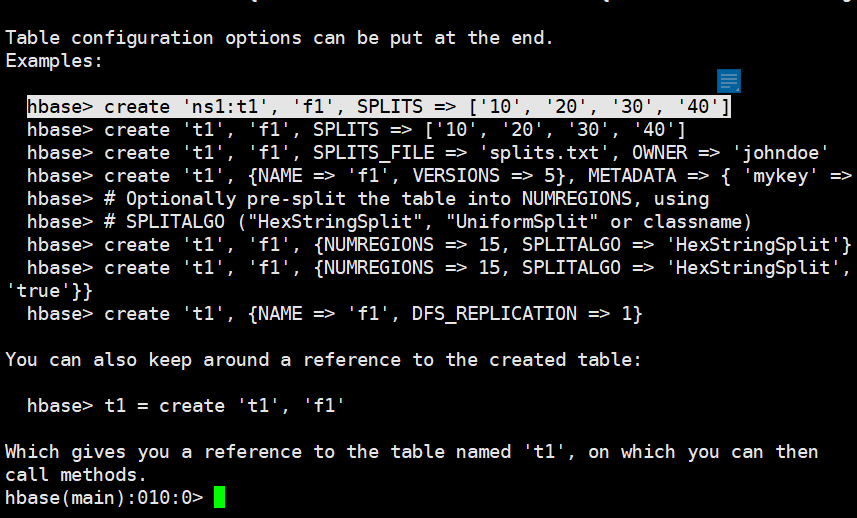
create 'tb_split','cf',SPLITS => ['e','h','l','r']
list_regions 'tb_split'

添加数据试试
put 'tb_split','c001','cf:name','first'
put 'tb_split','f001','cf:name','second'
put 'tb_split','z001','cf:name','last'
hbase hfile -p --f xxxx 查看数据
如果没有数据,因为数据还在内存中,需要手动刷新内存到HDFS中,以HFile的形式存储
3、日志查看
演示不启动hdfs 就启动hbase
日志目录:
/usr/local/soft/hbase-1.7.1/logs
start-all.sh发现HMaster没启动,hbase shell客户端也可以正常访问
再启动hbase就好了
4、scan进阶使用
查看所有的命名空间
list_namespace
查看某个命名空间下的所有表
list_namespace_tables 'default'
修改命名空间,设置一个属性
alter_namespace 'bigdata25',{METHOD=>'set','author'=>'wyh'}
查看命名空间属性
describe_namespace 'bigdata17'
删除一个属性
alter_namespace 'bigdata17',{METHOD=>'unset', NAME=>'author'}
删除一个命名空间
drop_namespace 'bigdata17'
创建一张表
create 'teacher','cf'
添加数据
put 'teacher','tid0001','cf:tid',1
put 'teacher','tid0002','cf:tid',2
put 'teacher','tid0003','cf:tid',3
put 'teacher','tid0004','cf:tid',4
put 'teacher','tid0005','cf:tid',5
put 'teacher','tid0006','cf:tid',6
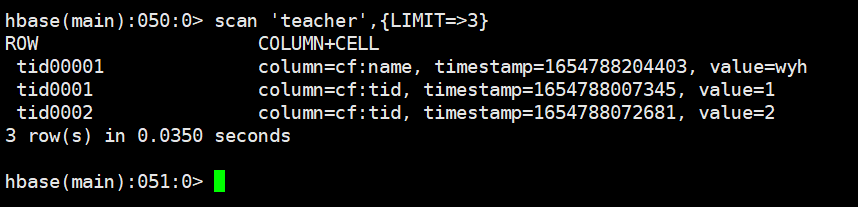
显示三行数据
scan 'teacher',{LIMIT=>3}
put 'teacher','tid00001','cf:name','wyh'
scan 'teacher',{LIMIT=>3}
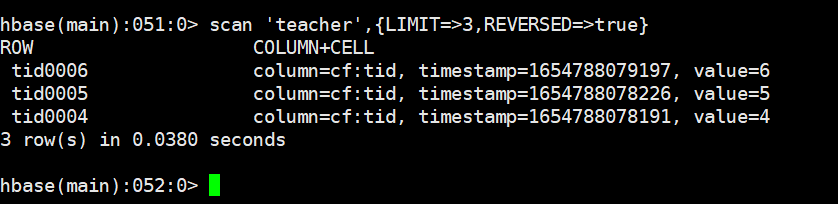
从后查三行
scan 'teacher',{LIMIT=>3,REVERSED=>true}
查看包含指定列的行
scan 'teacher',{LIMIT=>3,COLUMNS=>['cf:name']}

简化写法:
scan 'teacher',LIMIT=>3,COLUMNS=>['cf:name']
在已有的值后面追加值
append 'teacher','tid0001','cf:name','123'
5、get进阶使用
简单使用,获取某一行数据
get 'teacher','tid0001'
获取某一行的某个列簇
get 'teacher','tid0001','cf'
获取某一行的某一列(属性 )
get 'teacher','tid0001','cf:name'
可以新增一个列簇数据测试
查看历史版本
1、修改表可以存储多个版本
alter 'teacher',NAME=>'cf',VERSIONS=>3
2、put四次相同rowkey和列的数据
put 'teacher','tid0001','cf:name','xiaohu1'
put 'teacher','tid0001','cf:name','xiaohu2'
put 'teacher','tid0001','cf:name','xiaohu3'
put 'teacher','tid0001','cf:name','xiaohu4'
3、查看历史数据,默认是最新的
get 'teacher','tid0001',COLUMN=>'cf:name',VERSIONS=>2
修改列簇的过期时间 TTL单位是秒,这个时间是与插入的时间比较,而不是现在开始60s
alter 'teacher',{NAME=>'cf2',TTL=>'10'}
6、插入时间指定时间戳
put 'teacher','tid0007','info:clazz','bigdata30',1718356919312
数据时间:数据产生那一刻的时间
事务时间(操作时间):接收到数据并处理的那一刻时间
7、delete(只能删除一个单元格,不能删除列簇)
删除某一列
delete 'teacher','tid0004','cf:tid'
8、deleteall(删除不了某个列簇,但是可以删除多个单元格)
删除一行,如果不指定列簇,删除的是一行中的所有列簇
deleteall 'teacher','tid0006'
删除单元格
deleteall 'teacher','tid0006','cf:name','cf2:job'
9、incr和counter
统计表有多少行(统计的是行键的个数)
count 'teacher'
新建一个自增的一列
incr 'teacher','tid0001','cf:cnt',1
每操作一次,自增1
incr 'teacher','tid0001','cf:cnt',1
incr 'teacher','tid0001','cf:cnt',10
incr 'teacher','tid0001','cf:cnt',100
配合counter取出数据,只能取incr字段
get_counter 'teacher','tid0001','cf:cnt'
10、获取region的分割点,清除数据,快照
获取region的分割点
get_splits 'tb_split'
清除表数据
truncate 'teacher'
拍摄快照
snapshot 'teacher','teacher_20240614'
列出所有快照
list_table_snapshots 'tb_split'
再添加一些数据
put 'tb_split','k001','cf:name','wyh'
恢复快照(先禁用)
disable 'tb_split'
restore_snapshot 'teacher_20240614'
enable 'tb_split'
二、JAVA API
pom文件
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.2.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.6</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.6</version>
</dependency>
package com.hbase.base;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.*;
public class HBaseAPI {
private Connection conn;
private Admin admin;
/**
* 在所有Test方法执行之前执行
*/
@Before
public void getConnection() {
try {
//1、获取hbase集群的配置文件对象
//0.90.0之前旧版本的写法:
// HBaseConfiguration conf = new HBaseConfiguration();
//新版本的写法:调用静态方法public static Configuration create()
Configuration conf = HBaseConfiguration.create();
Properties prop = new Properties();
prop.load(new BufferedReader(new FileReader("src/main/resources/hbase.properties")));
String zk = (String)prop.get("hbase.zookeeper.quorum");
//2、因为hbase的数据都有一条元数据,而元数据也存储在一张表中,这张元数据表也有元数据,存储在zookeeper中
//配置文件要设置你自己的zookeeper集群
conf.set("hbase.zookeeper.quorum",zk); //前提时windows中配置了hosts映射
//3、获取数据库的连接对象
conn = ConnectionFactory.createConnection(conf);
//4、获取数据库操作对象
// HBaseAdmin hBaseAdmin = new HBaseAdmin(conn);
//新版本的做法
admin = conn.getAdmin(); //使用连接对象获取数据库操作对象
System.out.println("数据库连接对象获取成功!!" + conn);
System.out.println("数据库操作对象获取成功!!" + admin);
System.out.println("==========================================");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 需求1: 1、如何创建一张表
* create 'students','info' 必须要有表名和列簇的名
*/
@Test
public void createOneTable() {
try {
//先将表名封装成一个TableName的对象
TableName tn = TableName.valueOf("students2");
//HTableDescriptor类已经在2.0.0版本之后就过时了,并且在3.0.0之后完全被删除
//新版本不能使用这个类
// HTableDescriptor students = new HTableDescriptor(tn);
//新版本使用 TableDescriptorBuilder 类来创建并获取表描述器对象
//public static TableDescriptorBuilder newBuilder(final TableName name)
TableDescriptorBuilder students = TableDescriptorBuilder.newBuilder(tn);
//旧版本创建列簇描述器对象
// HColumnDescriptor info = new HColumnDescriptor("info");
//新版本中ColumnFamilyDescriptorBuilder.of(String).
ColumnFamilyDescriptor info = ColumnFamilyDescriptorBuilder.of("info");
//将列簇与表进行关联
//旧版本中表描述器调用addColumnFamily方法将列簇描述器添加到表中
// students.addColumnFamily(info);
//新版本中使用setColumnFamily
students.setColumnFamily(info);
//调用方法,创建表
// createTable(TableDescriptor desc)
// TableDescriptorBuilder
admin.createTable(students.build());
System.out.println(tn + "表创建成功!!!");
} catch (Exception e) {
System.out.println("表创建失败!!");
e.printStackTrace();
}
}
/**
* 需求:2、如何删除一张表
* disable 'students'
* drop 'students'
*/
@Test
public void dropOneTable() {
try {
//先将表名封装成一个TableName的对象
TableName tn = TableName.valueOf("tb_split2");
//判断表是否存在
if (admin.tableExists(tn)) {
//先禁用表
admin.disableTable(tn);
//使用admin对象调用方法删除表
//void deleteTable(TableName tableName)
admin.deleteTable(tn);
System.out.println(tn + "表成功被删除");
} else {
System.out.println(tn + "表不存在!!");
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 需求:3、如何向一张表中添加一条数据
* put 'students','1001','info:name','小虎'
*/
@Test
public void putOneDataToTable() {
try {
//先将表名封装成一个TableName的对象
TableName tn = TableName.valueOf("students");
//判断表是否存在
if (admin.tableExists(tn)) {
//获取表对象
Table students = conn.getTable(tn);
//创建Put对象
// Put put = new Put("1001".getBytes());//行键的字节数组形式
// //对put对象进行设置,添加列簇,列名和列值
// put.addColumn("info".getBytes(),"name".getBytes(),"小虎".getBytes());
//hbase自带的一个工具类Bytes,可以将字符串转字节数组
Put put = new Put(Bytes.toBytes("1001"));//行键的字节数组形式
//对put对象进行设置,添加列簇,列名和列值 以前的写法
// put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("name"),Bytes.toBytes("小虎"));
//public Put add(Cell cell) 新版本另外一种设置put对象的方式
//Cell 是一个接口,无法被实例化,使用实现类KeyValue来创建对象
//KeyValue(final byte [] row, final byte [] family, final byte [] qualifier, final byte [] value)
put.add(new KeyValue(Bytes.toBytes("1001"),
Bytes.toBytes("info"),
Bytes.toBytes("age"),
Bytes.toBytes(18)));
//void put(Put put)
//需要先将我们添加的列数据封装成一个Put对象
students.put(put);
} else {
System.out.println(tn + "表不存在!!");
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 需求:4、如何向一张表中同时添加一批数据
*/
@Test
public void putMoreDataToTable() {
BufferedReader br = null;
try {
//先将表名封装成一个TableName的对象
TableName tn = TableName.valueOf("students2");
//创建字符输入缓冲流
br = new BufferedReader(new FileReader("data/students.csv"));
String[] colNameArray = {"", "name", "age", "gender", "clazz"};
//判断表是否存在
if (admin.tableExists(tn)) {
//获取表对象
Table students = conn.getTable(tn);
//循环读取数据
String line = null;
while ((line = br.readLine()) != null) {
String[] info = line.split(",");
byte[] rowKey = Bytes.toBytes(info[0]);
//创建这一行的Put对象
Put put = new Put(rowKey);
//第一列作为行键唯一标识,从第二列开始,每一列都要被封装成Put对象
for (int i = 1; i < info.length; i++) {
byte[] colName = Bytes.toBytes(info[i]);
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes(colNameArray[i]), Bytes.toBytes(info[i]));
//添加该列数据
students.put(put);
}
}
System.out.println("学生表数据添加完毕!!!!");
} else {
System.out.println(tn + "表不存在!!");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (br != null) {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**
* 需求:5、如何获取一条数据
* get 'students','1500101000'
*/
@Test
public void getOneData() {
try {
//将表名封装TableName对象
TableName sd = TableName.valueOf("students");
//获取表的对象
Table students = conn.getTable(sd);
//传入行键的字节数组的形式
Get get = new Get(Bytes.toBytes("1500101000"));
//default Result get(Get get)
Result result = students.get(get);
// System.out.println(result);
/**
* Result类中的常用方法:
* getRow() : 获取行键的字节数组形式
* getValue(byte [] family, byte [] qualifier): 根据列簇和列名,获取列值的字节数组形式
* List<Cell> listCells():获取所有单元格,单元格中存储了行键,列簇,列名,版本号(时间戳),列值
*/
String id = Bytes.toString(result.getRow());
//在已经知道列名的前提之下获取对应的列值
// String name = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")));
// String age = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("age")));
// String gender = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("gender")));
// String clazz = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("clazz")));
// System.out.println("学号:"+id+",姓名:"+name+",年龄:"+age+",性别:"+gender+",班级:"+clazz);
//当不清楚列名的时候该如何获取呢?
//获取一行中的所有单元格组合的集合
List<Cell> cells = result.listCells(); //获取的结果值的顺序是hbase中存储排序后的顺序
//遍历集合得到每个单元格,获取每个列值
/**
* hbase中除了提供一个Bytes工具类给我们使用以外,还提供了另外的一个工具类:CellUtil
* 该工具类主要的操作对象是Cell类的对象
*/
//遍历方式1:普通for循环遍历
//遍历方式2:增强for循环遍历
// for (Cell cell : cells) {
// String colName = Bytes.toString(CellUtil.cloneQualifier(cell));
// String colValue = Bytes.toString(CellUtil.cloneValue(cell));
// System.out.println(colName + ":" + colValue);
// }
//遍历方式3:forEach + lambda表达式
// cells.forEach(e -> {
// String colName = Bytes.toString(CellUtil.cloneQualifier(e));
// String colValue = Bytes.toString(CellUtil.cloneValue(e));
// System.out.println(colName + ":" + colValue);
// });
//遍历方式4:jdk1.8新特性遍历,转流处理
cells.stream().map(e -> {
String colName = Bytes.toString(CellUtil.cloneQualifier(e));
String colValue = Bytes.toString(CellUtil.cloneValue(e));
// System.out.println(colName + ":" + colValue);
return colName + ":" + colValue;
}).forEach(System.out::println);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 6、如果获取一批数据 第一种方式
*/
@Test
public void getMoreData() {
try {
//将表名封装TableName对象
TableName sd = TableName.valueOf("students");
//获取表的对象
Table students = conn.getTable(sd);
//创建List集合,存储多个Get对象
//1500100001 ~ 1500101000
ArrayList<Get> gets = new ArrayList<>();
for (int i = 1500100001; i <= 1500101000; i++) {
gets.add(new Get(Bytes.toBytes(String.valueOf(i))));
}
//default Result[] get(List<Get> gets)
Result[] results = students.get(gets);
//1、先遍历results得到每一个result(每一行)
//2、遍历每一个result中的每一列
for (Result result : results) {
List<Cell> cells = result.listCells();
if (cells != null) {
cells.stream().map(cell -> {
String colName = Bytes.toString(CellUtil.cloneQualifier(cell));
String colValue = Bytes.toString(CellUtil.cloneValue(cell));
// System.out.println(colName + ":" + colValue);
return colName + ":" + colValue;
}).forEach(System.out::println);
System.out.println("-----------------");
} else {
System.out.println("是空");
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 7、如果获取一批数据 第二种方式
* scan 'students' 默认情况下获取表所有数据
* scan 'students',LIMIT=>3
*/
@Test
public void ScanData() {
try {
TableName sd = TableName.valueOf("students");
Table students = conn.getTable(sd);
//创建Scan对象
Scan scan = new Scan(); //查询表中的所有行
//设置开始行和结束行
//旧版本写法
// scan.setStartRow(Bytes.toBytes("1500100001"));
// scan.setStopRow(Bytes.toBytes("1500100004"));
//新版本写法
// scan.withStartRow(Bytes.toBytes("1500100001"));
// scan.withStopRow(Bytes.toBytes("1500100004"), true);
//设置取前几行
scan.setLimit(10);
//default ResultScanner getScanner(Scan scan)
ResultScanner resultScanner = students.getScanner(scan);
//通过观察源码发现,可以先获取迭代器对象
Iterator<Result> iterator = resultScanner.iterator();
while (iterator.hasNext()) {
Result result = iterator.next();
// String id = Bytes.toString(result.getRow());
//在已经知道列名的前提之下获取对应的列值
// String name = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")));
// String age = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("age")));
// String gender = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("gender")));
// String clazz = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("clazz")));
// System.out.println("学号:" + id + ",姓名:" + name + ",年龄:" + age + ",性别:" + gender + ",班级:" + clazz);
printResult(result);
System.out.println("-----------------");
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 需求:7、如何创建预分region表
* 将来对于某一个RegionServer而言,可能会接收大量的并发请求,超出了该RegionServer承受的压力,有可能会导致该子节点崩溃
* 如果大量的并发请求查询的数据是多种多种多样的,只不过巧合的是都在一个RegionServer上管理
* 解决的思路:分散查询的数据到不同的RegionServer上,这样请求也会随着被分散到不同的RegionServer上,就达到了减轻某一个RegionServer压力过大情况,解决了单点故障的问题
*/
@Test
public void createPreviewTable(){
try {
//先将表名封装成TableName对象
TableName tb = TableName.valueOf("tb_split2");
//创建表描述器对象
TableDescriptorBuilder tbSplit2 = TableDescriptorBuilder.newBuilder(tb);
//创建列簇描述器对象
ColumnFamilyDescriptor info = ColumnFamilyDescriptorBuilder.of("info");
//将列簇添加到表中
tbSplit2.setColumnFamily(info);
//创建分割键的二维数组
byte[][] splitKeys = {
Bytes.toBytes("f"),
Bytes.toBytes("k"),
Bytes.toBytes("p")
};
//调用方法创建表
// admin.createTable(tbSplit2.build());
//调用另外一个方法,传入表描述器的同时,传入分割点,创建预分region表
//void createTable(TableDescriptor desc, byte[][] splitKeys)
admin.createTable(tbSplit2.build(),splitKeys);
System.out.println("预分region表创建成功!!!");
}catch (Exception e){
e.printStackTrace();
}
}
public void printResult(Result result) {
String id = Bytes.toString(result.getRow());
//在已经知道列名的前提之下获取对应的列值
String name = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")));
String age = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("age")));
String gender = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("gender")));
String clazz = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("clazz")));
System.out.println("学号:" + id + ",姓名:" + name + ",年龄:" + age + ",性别:" + gender + ",班级:" + clazz);
// System.out.println("-----------------");
}
/**
* 释放Before创建的资源,在每个Test之后执行
*/
@After
public void closeSource() {
try {
if (admin != null) {
admin.close();
}
if (conn != null) {
conn.close();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号