HBase学习的第三天--hbase的架构和基础命令2
5.4 namespace
hbase中没有数据库的概念 , 可以使用namespace来达到数据库分类别管理表的作用
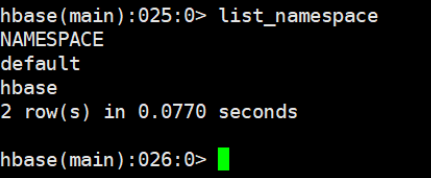
5.4.1 列举命名空间 list_namespace
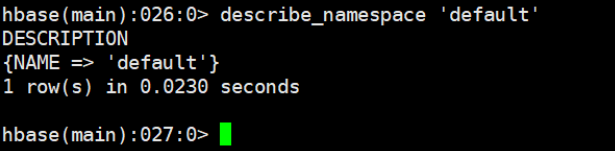
5.4.2 获取命名空间描述 describe_namespace
describe_namespace 'default'
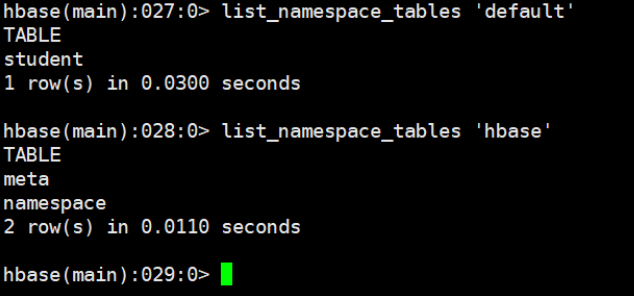
5.4.3 查看命名空间下的所有表 list_namespace_tables
list_namespace_tables 'default'
list_namespace_tables 'hbase'
5.4.4 创建命名空间create_namespace
create_namespace 'bigdata17'
5.4.5 删除命名空间drop_namespace
drop_namespace '命名空间名称'
5.5 DML
- 数据操作语言
5.5.1 插入或者修改数据put

# 语法
# 当列族中只有一个列时'列族名:列名'使用'列族名'
# 类似于Java中的HashMap添加数据的方法
put '表名', '行键', '列族名', '列值'
put '表名', '行键', '列族名:列名', '列值'
# 示例
# 创建表
create 'users', 'info', 'detail', 'address'
# 第一行数据
put 'users', 'rk1001', 'info:id', '1'
put 'users', 'rk1001', 'info:name', '张三'
put 'users', 'rk1001', 'info:age', '28'
put 'users', 'rk1001', 'detail:birthday', '1990-06-26'
put 'users', 'rk1001', 'detail:email', 'abc@163.com'
put 'users', 'rk1001', 'detail:create_time', '2019-03-04 14:26:10'
put 'users', 'rk1001', 'address', '上海市'
# 第二行数据
put 'users', 'rk1002', 'info:id', '2'
put 'users', 'rk1002', 'info:name', '李四'
put 'users', 'rk1002', 'info:age', '27'
put 'users', 'rk1002', 'detail:birthday', '1990-06-27'
put 'users', 'rk1002', 'detail:email', 'xxx@gmail.com'
put 'users', 'rk1002', 'detail:create_time', '2019-03-05 14:26:10'
put 'users', 'rk1002', 'address', '北京市'
# 第三行数据
put 'users', 'rk1003', 'info:id', '3'
put 'users', 'rk1003', 'info:name', '王五'
put 'users', 'rk1003', 'info:age', '26'
put 'users', 'rk1003', 'detail:birthday', '1990-06-28'
put 'users', 'rk1003', 'detail:email', 'xyz@qq.com'
put 'users', 'rk1003', 'detail:create_time', '2019-03-06 14:26:10'
put 'users', 'rk1003', 'address', '杭州市'
5.5.2 全表扫描scan
# 语法
scan '表名'
# 示例
scan 'users' // 效果类似于sql语句中select * from users

扫描整个列簇
# 语法
scan '表名', {COLUMN=>'列族名'}
# 示例
scan 'users', {COLUMN=>'info'}
扫描整个列簇的某个列
# 语法
scan '表名', {COLUMN=>'列族名:列名'}
# 示例
scan 'users', {COLUMN=>'info:age'}
5.5.3 获取数据get
# 语法
get '表名', '行键'
# 示例
get 'users', 'xiaoming'
根据某一行某列族的数据
# 语法
get '表名', '行键', '列族名'
# 示例
get 'users', 'xiaoming', 'info'
# 创建表,c1版本为4, 元数据mykey=myvalue
hbase(main):009:0> create 'test1', {NAME => 'cf1', VERSIONS => 4}
0 row(s) in 2.2810 seconds
=> Hbase::Table - t1
# 添加列族c2, c3
hbase(main):010:0> alter 'test1', 'c2', 'c3'
Updating all regions with the new schema...
1/1 regions updated.
Done.
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 3.8320 seconds
# 出入数据,c1 插入4个版本的值
hbase(main):011:0> put 'test1', 'r1', 'c1', 'v1'
0 row(s) in 0.1000 seconds
hbase(main):012:0> put 't1', 'r1', 'c1', 'v11'
0 row(s) in 0.0180 seconds
hbase(main):013:0> put 'test1', 'r1', 'c1', 'v111'
0 row(s) in 0.0140 seconds
hbase(main):014:0> put 'test1', 'r1', 'c1', 'v1111'
0 row(s) in 0.0140 seconds
# 插入c2、c3的值
hbase(main):015:0> put 'test1', 'r1', 'c2', 'v2'
0 row(s) in 0.0140 seconds
hbase(main):016:0> put 'test1', 'r1', 'c3', 'v3'
0 row(s) in 0.0210 seconds
# 获取rowKey=r1的一行记录
hbase(main):017:0> get 'test1', 'r1'
COLUMN CELL
c1: timestamp=1552819382575, value=v1111
c2: timestamp=1552819392398, value=v2
c3: timestamp=1552819398244, value=v3
3 row(s) in 0.0550 seconds
# 获取rowKey=r1并且 1552819392398 <= 时间戳范围 < 1552819398244
hbase(main):018:0> get 'test1', 'r1', {TIMERANGE => [1552819392398, 1552819398244]}
COLUMN CELL
c2: timestamp=1552819392398, value=v2
1 row(s) in 0.0090 seconds
# 获取指定列的值
hbase(main):019:0> get 'test1', 'r1', {COLUMN => 'c1'}
COLUMN CELL
c1: timestamp=1552819382575, value=v1111
1 row(s) in 0.0160 seconds
# 获取指定列的值,多个值使用数组表示
hbase(main):020:0> get 'test1', 'r1', {COLUMN => ['c1', 'c2', 'c3']}
COLUMN CELL
c1: timestamp=1552819382575, value=v1111
c2: timestamp=1552819392398, value=v2
c3: timestamp=1552819398244, value=v3
3 row(s) in 0.0170 seconds
# 获取c1的值,获取4个版本的值,默认是按照时间戳降续排序的
hbase(main):021:0> get 'test1', 'r1', {COLUMN => 'c1', VERSIONS => 4}
COLUMN CELL
c1: timestamp=1552819382575, value=v1111
c1: timestamp=1552819376343, value=v111
c1: timestamp=1552819368993, value=v11
c1: timestamp=1552819362975, value=v1
4 row(s) in 0.0180 seconds
# 获取c1的3个版本值
hbase(main):027:0* get 'test1', 'r1', {COLUMN => 'c1', VERSIONS => 3}
COLUMN CELL
c1: timestamp=1552819382575, value=v1111
c1: timestamp=1552819376343, value=v111
c1: timestamp=1552819368993, value=v11
3 row(s) in 0.0090 seconds
# 获取指定时间戳版本的列
hbase(main):022:0> get 'test1', 'r1', {COLUMN => 'c1', TIMESTAMP => 1552819376343}
COLUMN CELL
c1: timestamp=1552819376343, value=v111
1 row(s) in 0.0170 seconds
hbase(main):023:0> get 'test1', 'r1', {COLUMN => 'c1', TIMESTAMP => 1552819376343, VERSIONS => 4}
COLUMN CELL
c1: timestamp=1552819376343, value=v111
1 row(s) in 0.0130 seconds
# 获取rowKey=r1中的值等于v2的所有列
hbase(main):024:0> get 'test1', 'r1', {FILTER => "ValueFilter(=, 'binary:v2')"}
COLUMN CELL
c2: timestamp=1552819392398, value=v2
1 row(s) in 0.0510 seconds
hbase(main):025:0> get 'test1', 'r1', {COLUMN => 'c1', ATTRIBUTES => {'mykey'=>'myvalue'}}
COLUMN CELL
c1: timestamp=1552819382575, value=v1111
1 row(s) in 0.0100 seconds
5.5.4 删除某个列族中的某个列delete
# 语法
delete '表名', '行键', '列族名:列名'
delete 'users','xiaoming','info:age'
create 'tbl_test', 'columnFamily1'
put 'tbl_test', 'rowKey1', 'columnFamily1:column1', 'value1'
put 'tbl_test', 'rowKey1', 'columnFamily1:column2', 'value2'
delete 'tbl_test', 'rowKey1', 'columnFamily1:column1'
5.5.5 删除某行数据deleteall
# 语法
deleteall '表名', '行键'
# 示例
deleteall 'users', 'xiaoming'
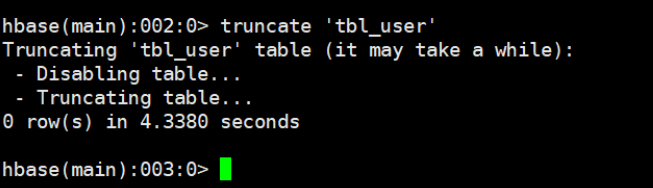
5.5.6 清空整个表的数据truncate
先disable表,然后再drop表,最后重新create表
truncate '表名'
5.5.7 自增incr
# 语法
incr '表名', '行键', '列族:列名', 步长值
# 示例
# 注意:incr 可以对不存的行键操作,如果行键已经存在会报错,如果使用put修改了incr的值再使用incr也会报错
# ERROR: org.apache.hadoop.hbase.DoNotRetryIOException: Field is not a long, it's 2 bytes wide
incr 'tbl_user', 'xiaohong', 'info:age', 1
5.5.8 计数器get_counter
# 点击量:日、周、月
create 'counters', 'daily', 'weekly', 'monthly'
incr 'counters', '20240415', 'daily:hits', 1
incr 'counters', '20110101', 'daily:hits', 1
get_counter 'counters', '20110101', 'daily:hits'
5.5.9 修饰词
1、修饰词
# 语法
scan '表名', {COLUMNS => [ '列族名1:列名1', '列族名1:列名2', ...]}
# 示例
scan 'tbl_user', {COLUMNS => [ 'info:id', 'info:age']}
2、TIMESTAMP 指定时间戳
# 语法
scan '表名',{TIMERANGE=>[timestamp1, timestamp2]}
# 示例
scan 'tbl_user',{TIMERANGE=>[1551938004321, 1551938036450]}
3、VERSIONS
默认情况下一个列只能存储一个数据,后面如果修改数据就会将原来的覆盖掉,可以通过指定VERSIONS时HBase一列能存储多个值。
create 'tbl_test', 'columnFamily1'
describe 'tbl_test'
# 修改列族版本号
alter 'tbl_test', { NAME=>'columnFamily1', VERSIONS=>3 }
put 'tbl_test', 'rowKey1', 'columnFamily1:column1', 'value1'
put 'tbl_test', 'rowKey1', 'columnFamily1:column1', 'value2'
put 'tbl_test', 'rowKey1', 'columnFamily1:column1', 'value3'
# 默认返回最新的一条数据
get 'tbl_test','rowKey1','columnFamily1:column1'
# 返回3个
get 'tbl_test','rowKey1',{COLUMN=>'columnFamily1:column1', VERSIONS=>3}
# 返回2个
get 'tbl_test','rowKey1',{COLUMN=>'columnFamily1:column1', VERSIONS=>2}
4、STARTROW
ROWKEY起始行。会先根据这个key定位到region,再向后扫描
包括起始行的
# 语法
scan '表名', { STARTROW => '行键名'}
# 示例
scan 'tbl_user', { STARTROW => 'vbirdbest'}
5、STOPROW :截止到STOPROW行,STOPROW行之前的数据,不包括STOPROW这行数据
# 语法
scan '表名', { STOPROW => '行键名'}
# 示例
scan 'tbl_user', { STOPROW => 'xiaoming'}
6、LIMIT 返回的行数
# 语法
scan '表名', { LIMIT => 行数}
# 示例
scan 'tbl_user', { LIMIT => 2 }
5.5.10 FILTER条件过滤器
过滤器之间可以使用AND、OR连接多个过滤器。
1、ValueFilter 值过滤器
# 语法:binary 等于某个值
scan '表名', FILTER=>"ValueFilter(=,'binary:列值')"
# 语法 substring:包含某个值
scan '表名', FILTER=>"ValueFilter(=,'substring:列值')"
# 示例
scan 'tbl_user', FILTER=>"ValueFilter(=, 'binary:26')"
scan 'tbl_user', FILTER=>"ValueFilter(=, 'substring:6')"
2、ColumnPrefixFilter 列名前缀过滤器
# 语法 substring:包含某个值
scan '表名', FILTER=>"ColumnPrefixFilter('列名前缀')"
# 示例
scan 'tbl_user', FILTER=>"ColumnPrefixFilter('birth')"
# 通过括号、AND和OR的条件组合多个过滤器
scan 'tbl_user', FILTER=>"ColumnPrefixFilter('birth') AND ValueFilter(=,'substring:26')"
3、rowKey字典排序
Table中的所有行都是按照row key的字典排序的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号