大数据框架之一——Hadoop学习第二天
Hadoop三大组件的介绍
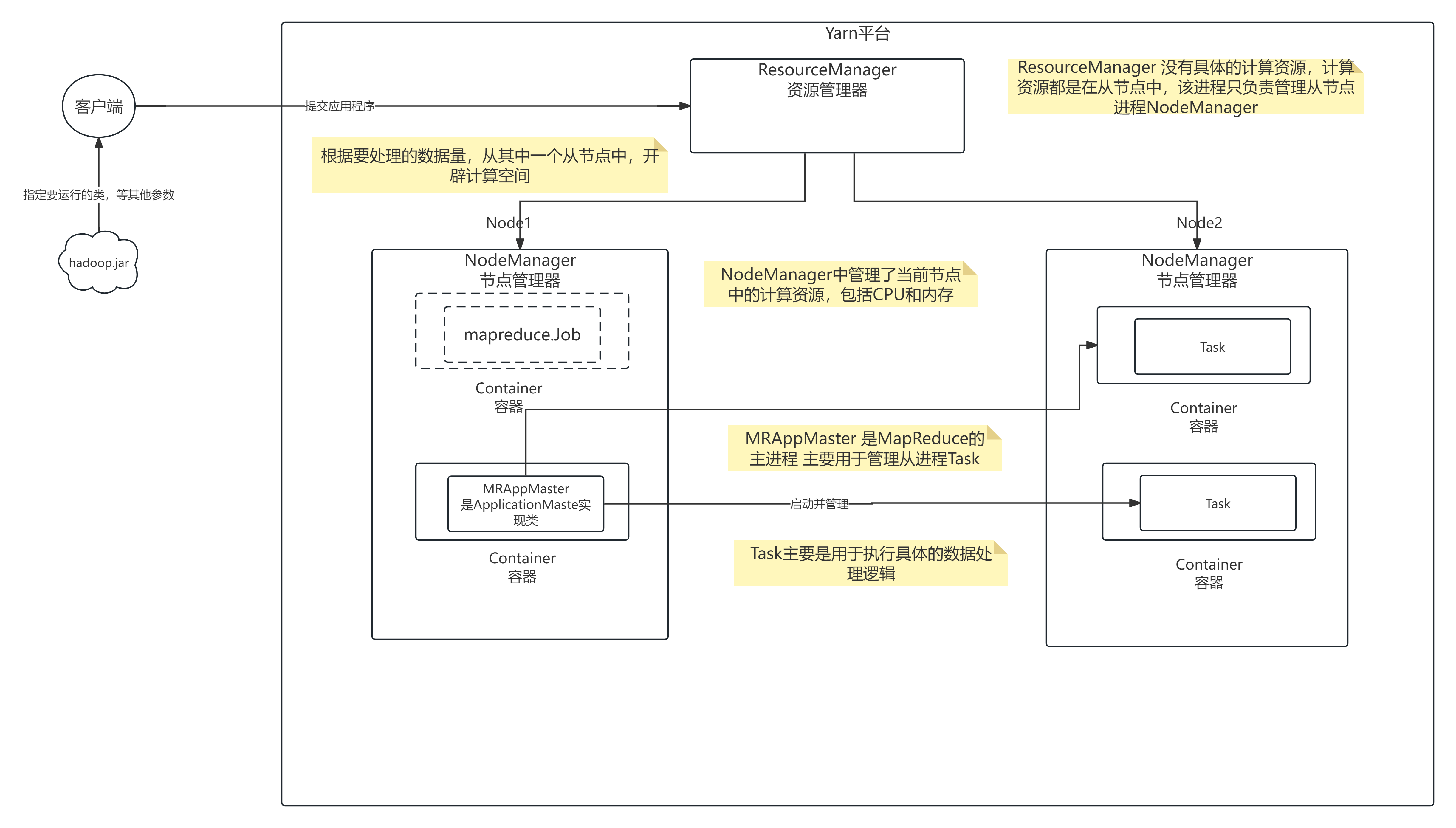
1、yarn架构分析
-
yarn:资源的调度和管理平台。
-
主从结构
- 主节点,可以有2个:ResourceManager
- 从节点,有很多个: NodeManager
-
ResourceManager负责
- 集群资源的分配与调度
- MapReduce、Storm、Spark等应用,必须实现ApplicationMaster接口,才能被RM管理
-
NodeManager负责
- 单节点资源的管理(CPU+内存)
2、mapreduce架构分析
-
mapreduce是依赖磁盘io的批处理计算模型。
-
主从结构
- 主节点,只有一个: MRAppMaster
- 从节点,就是具体的task
-
MRAppMaster负责
- 接收客户端提交的计算任务
-
实时处理和离线处理在Java代码中的解释
- 把计算任务分给NodeManager的Container中执行,即任务调度
- Container是YARN中资源的抽象,它封装了某个节点上一定量的资源(CPU和内存两类资源)
- Container由ApplicationMaster向ResourceManager申请的,由ResouceManager中的资源调度器异步分配给ApplicationMaster
- Container的运行是由ApplicationMaster向资源所在的NodeManager发起的
- 监控Container中Task的执行情况
- Task负责:
- 处理数据
- hadoop概念总结
- 扩容能力(Scalable):能可靠(reliably)地存储和处理PB级别的数据。如果数据量更大,存储不下了,再增加节点就可以了。
- 成本低(Economical):可以通过普通机器组成的服务器集群来分发以及处理数据.这些服务器集群可达数千个节点。
- 高效率(Efficient):通过分发计算程序,hadoop可以在数据所在节点上(本地)并行地(parallel)处理他们,这使得处理非常的迅速
- 可靠性(Reliable):hadoop能够自动地维护数据的多份副本,并且在任务失败后能够自动地重新部署(redeploy)计算任务.
3、HDFS命令
对于HDFS命令形式有两种
hdfs dfs 开头 或者 hadoop fs 开头
-
上传
# 上传文件或目录 hdfs dfs -put 本地文件或目录 hdfs的文件或目录 hadoop fs -put 本地文件或目录 hdfs的文件或目录 -
下载
hdfs dfs -get HDFS路径 本地路径 -
创建目录
hdfs dfs -mkdir HDFS路径 # 迭代创建多级目录 hdfs dfs -mkdir -p HDFS路径 -
查看路径中的文件或目录
hdfs dfs -ls 路径 # 标准化输出路径中的信息 hdfs dfs -ls -h 路径 -
文件内容
# cat是不能进行查看压缩文件 hdfs dfs -cat HDFS路径 # 从文件的末尾获取信息 hdfs dfs -tail HDFS路径 # hdfs dfs -tail -f HDFS路径 监听HDFS中的文件内容 # text对于压缩文件中的文本信息可以进行查看 hdfs dfs -text HDFS路径 可以查看被Hadoop压缩的压缩文件 -
追加信息到文件中
hdfs dfs -appendToFile 本地路径 HDFS中的路径 hdfs dfs -appendToFile -
删除文件
hdfs dfs -rm -r -f /output hdfs dfs -rm -r -f -skipTrash /output -
移动文件
hdfs dfs -mv HDFS中的路径 HDFS中的路径 -
查看空间
hdfs dfs -du -h / 查看指定目录下对应空间占用情况 hdfs dfs -df 查看整个HDFS中空间使用情况 -
复制
hdfs dfs -cp 源路径 目标路径 -
修改文件权限
hdfs dfs -chmod 735 目标路径 hdfs dfs -chmod -R 735 目标路径 迭代目录中所有内容给定权限 # 4表示读 2表示写 1表示执行 hdfs dfs -chmod 124 /output3 hdfs dfs -chmod -R 124 /output3 -
查看状态
hdfs dfsadmin -report
HDFS详细学习
1、HDSFS架构-元数据
包含NameNode、DataNode、Secondary NameNode
1.1HDFS概述
- 什么是分布式文件系统
- 1、数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 。
- 2、是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间。
- 3、通透性。让实际上是通过网络来访问文件的动作,由程序与用户看来,就像是访问本地的磁盘一般。
- 4、容错。即使系统中有某些节点宕机,整体来说系统仍然可以持续运作而不会有数据损失【通过副本机制实现】。
- HDFS只是分布式文件管理系统中的一种,不适合小文件。
- 其架构如下图所示
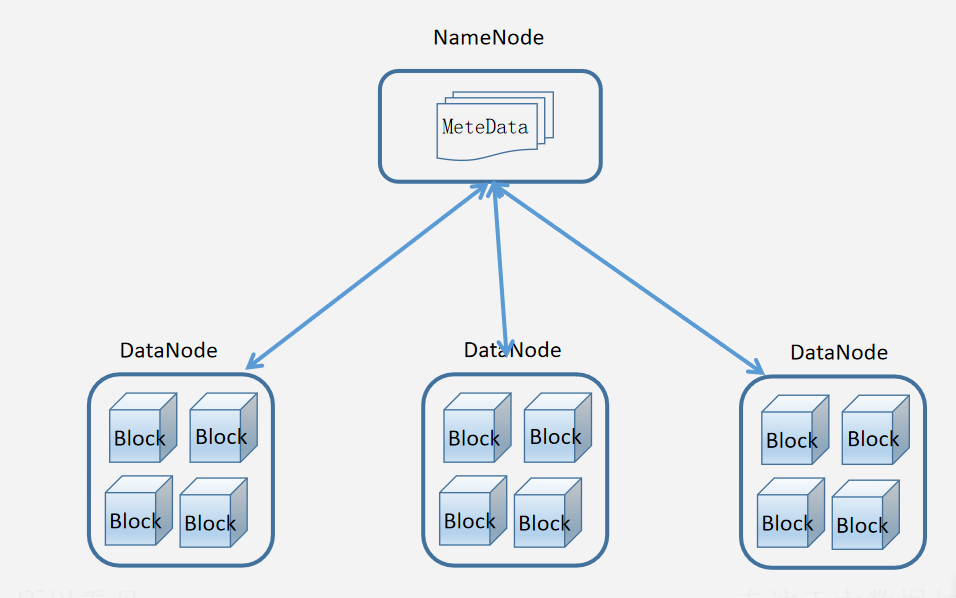
1.2NameNode主节点
- NameNode是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。接收用户的操作请求。
- 文件包括:
- fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息。
- edits:操作日志文件,namenode启动后一些新增元信息日志。
- fstime:保存最近一次checkpoint的时间
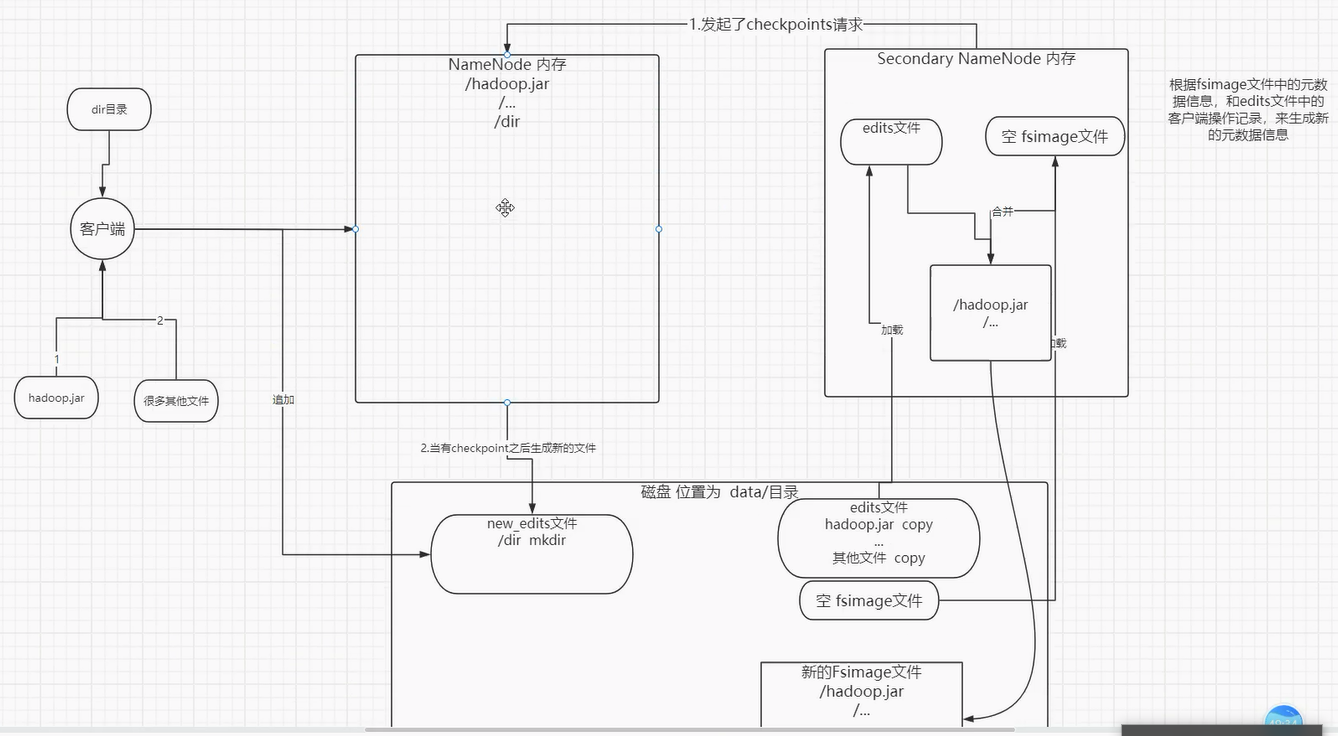
1.3Secondary Namenode
SecondaryNameNode是用来帮助NameNode完成元数据信息合并,从角色上看属于NameNode的“秘书”
-
其工作流程如下
- 1、secondary向NameNode发起Checkpoint请求
- 2、secondary从namenode获得fsimage和edits
- 3、secondary将fsimage载入内存,然后开始合并edits
- 4、secondary将新的fsimage发回给namenode
- 5、namenode用新的fsimage替换旧的fsimage
-
如下图

-
Secondary NameNode的用处:
- 由于NameNode负责的任务非常多,所以需要定义新的进程来完成合并工作。
-
CheckPoint发起时机:
- 1.fs.checkpoint.period 指定两次checkpoint的最大时间间隔,默认3600秒。
- 2.fs.checkpoint.size 规定edits文件的最大值,一旦超过这个值则强制checkpoint,不管是否到达最大时间间隔默认大小是64M。
-
HDFS中内存存储数据面临的问题

#edits文件和fsimage文件所在的路径
/usr/local/soft/hadoop-3.1.3/data/dfs/name/current
#找到最近时间生成的edits和fsimage文件
#通过转换命令查看最近生成的edits文件中的内容
hdfs oev -i edits_inprogress_0000000000000000145 -o edits.xml -p XML
vim edits.xml
#可以发现只有最近的部分信息
#通过转换命令查看最近生成的fsimage文件中的内容
hdfs oiv -i fsimage_0000000000000000144 -o fsimage.xml -p XML
#查看信息
vim fsimage.xml
- 具体的过程如下图
2、DataNode
2.1DataNode介绍
- DataNode作用?
- 为整个集群提供真实文件数据的存储服务,同时管理本节点中所有Block块
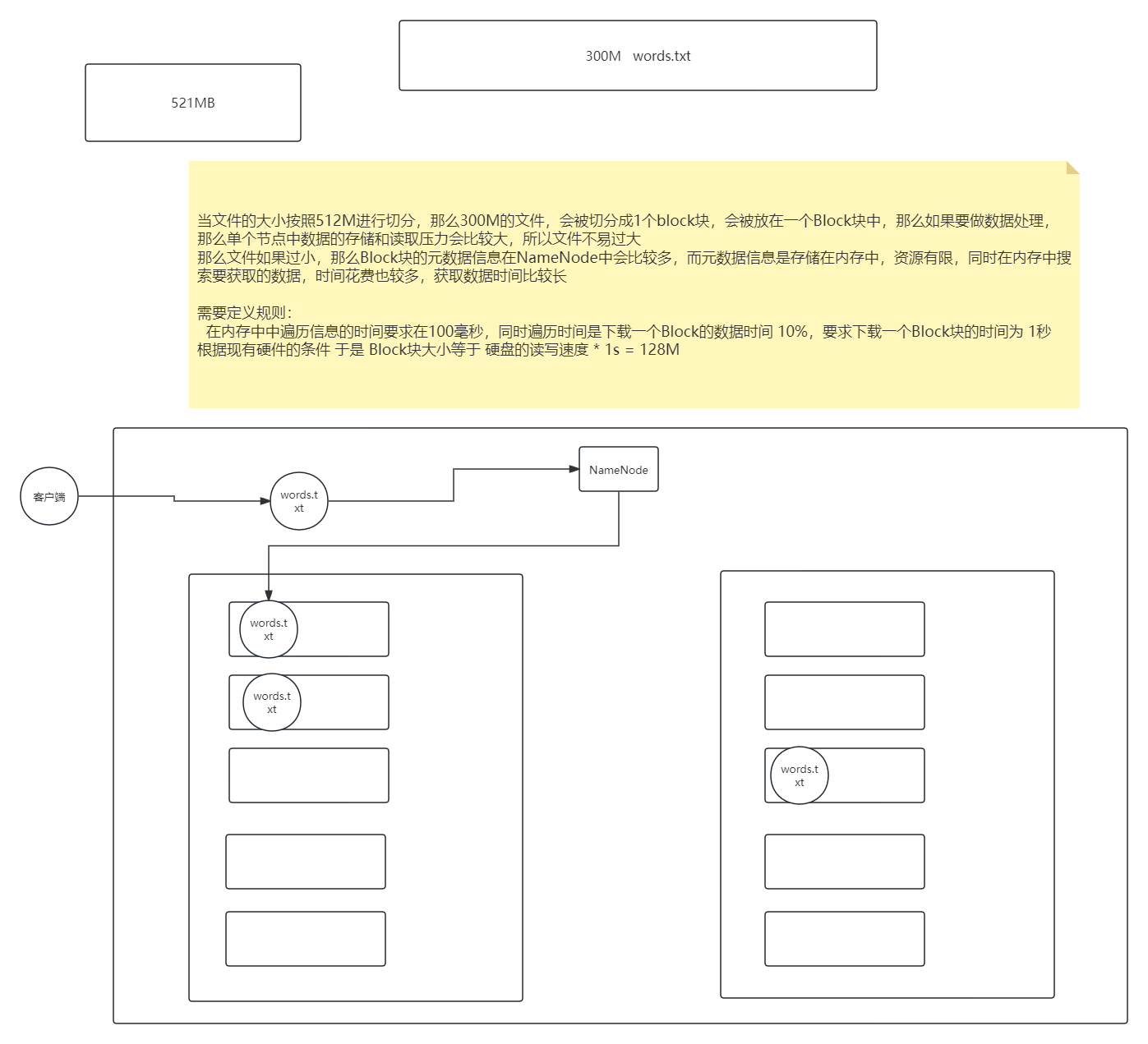
- 什么是Block块?
- 文件块(block):
- 最基本的存储单位。对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。2.0以后HDFS默认Block大小是128MB,以一个256MB文件,共有256/128=2个Block.可以在hdfs-site.xml中dfs.blocksize属性配置Block块
2.2副本机制
- 什么是副本机制?
- HDFS中通过副本方式来保证数据的安全性,并且同一数据的副本是存储在不同节点当中。HDFS默认副本数是三个。可以在hdfs-site.xml的dfs.replication属性中配置对应数量
- 如下图
- 具体的解释
3、HDFS-API使用
- FileSysterm是使用java代码操作hdfs的api接口
- 文件操作
- create 写文件
package com.Hadoop.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
import java.net.URISyntaxException;
public class Demo08Create {
public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException {
/*
TODO 可以创建一个流 写入数据到 HDFS中
*/
// Configuration表示配置类
Configuration entries = new Configuration();
URI uri = new URI("hdfs://master:9000");
FileSystem fileSystem = FileSystem.get(uri,entries,"root");
// TODO 创建HDFS目标路径的IO流
FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path("/data/score.txt"));
// TODO 创建IO流读取本地数据
FileInputStream fileInputStream = new FileInputStream("hadoop/data/score.txt");
byte[] bytes = new byte[100];
int len = 0;
while ((len = fileInputStream.read(bytes))!= -1){
fsDataOutputStream.write(bytes,0,len);
fsDataOutputStream.flush();
}
fsDataOutputStream.close();
fileSystem.close();
// TODO 修改hdfs中的副本数
// TODO 方式1:对于配置信息可以在 Configuration中添加
// entries.set("dfs.replication","1");
// TODO 方式2:可以在resources目录中添加对应的配置文件
}
}
- open 读取文件
package com.Hadoop.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.*;
import java.net.URI;
import java.net.URISyntaxException;
public class Demo09Open {
public static void main(String[] args) throws IOException, InterruptedException, URISyntaxException {
/*
TODO 从HDFS中创建IO流写出数据到本地
*/
Configuration entries = new Configuration();
entries.set("fs.defaultFS","hdfs://master:9000");
URI uri = new URI("hdfs://master:9000");
FileSystem fileSystem = FileSystem.get(uri,entries,"root");
BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter("hadoop/data/words.txt"));
// TODO 当文件不存在时如何进行提示判断
FSDataInputStream open = fileSystem.open(new Path("/data/words.txt"));
// String line = open.readLine(); // 过时
// InputStreamReader 是一个转换流
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(open));
String readLine = null;
while ((readLine = bufferedReader.readLine())!=null){
// 可以对一行数据进行写出到本地
bufferedWriter.write(readLine);
bufferedWriter.newLine();
}
bufferedReader.close();
bufferedWriter.close();
}
}
- delete 删除文件
package com.Hadoop.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class Demo06Delete {
public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException {
delete();
}
public static void delete() throws IOException, URISyntaxException, InterruptedException {
// 没有设置用户信息
Configuration entries = new Configuration();
entries.set("fs.defaultFS","hdfs://master:9000");
URI uri = new URI("hdfs://master:9000");
FileSystem fileSystem = FileSystem.get(uri,entries,"root");
// fileSystem.delete(new Path("/api/1/2"));
fileSystem.delete(new Path("/api"),true);
fileSystem.close();
}
}
- 目录操作
- mkdirs 创建目录
package com.Hadoop.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class Demo05MakeDir {
public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException {
/*
上传数据到HDFS中
*/
mkdir();
}
public static void mkdir() throws IOException, URISyntaxException, InterruptedException {
// 没有设置用户信息
Configuration entries = new Configuration();
entries.set("fs.defaultFS","hdfs://master:9000");
URI uri = new URI("hdfs://master:9000");
FileSystem fileSystem = FileSystem.get(uri,entries,"root");
fileSystem.mkdirs(new Path("/api"));
// fileSystem.mkdirs(new Path("/api/1/2"));
fileSystem.close();
}
}
- delete 删除文件或目录
- listStatus 列出目录的内容
- getFileStatus 显示文件系统的目录和文件的元数据信息
- getFileBlockLocations 显示文件存储位置
package com.Hadoop.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class Demo07Liststatus {
public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException {
getBlockLocation();
}
public static void getBlockLocation() throws IOException, URISyntaxException, InterruptedException {
// 没有设置用户信息
Configuration entries = new Configuration();
entries.set("fs.defaultFS","hdfs://master:9000");
URI uri = new URI("hdfs://master:9000");
FileSystem fileSystem = FileSystem.get(uri,entries,"root");
FileStatus fileStatus = fileSystem.getFileStatus(new Path("/hadoop-3.1.3.tar.gz"));
System.out.println("路径:"+fileStatus.getPath());
System.out.println("长度:"+fileStatus.getLen());
System.out.println("副本数:"+fileStatus.getReplication());
/*
获取一个文件的文件指定开始和结束的部分数据所在的Block块位置
BlockLocation[] getFileBlockLocations(FileStatus file,
long start, long len)
*/
BlockLocation[] fileBlockLocations = fileSystem.getFileBlockLocations(fileStatus, 0, fileStatus.getLen());
for (BlockLocation fileBlockLocation : fileBlockLocations) {
System.out.println("整个长度:"+fileBlockLocation.getLength());
System.out.println("偏移量,从文件的什么位置开始:"+fileBlockLocation.getOffset());
System.out.println("整个主机:"+fileBlockLocation.getHosts());
System.out.println("整个名称:"+fileBlockLocation.getNames());
}
fileSystem.close();
}
//显示文件系统的目录和文件的元数据信息
public static void getFileStatus() throws IOException, URISyntaxException, InterruptedException {
// 没有设置用户信息
Configuration entries = new Configuration();
entries.set("fs.defaultFS","hdfs://master:9000");
URI uri = new URI("hdfs://master:9000");
FileSystem fileSystem = FileSystem.get(uri,entries,"root");
FileStatus fileStatus = fileSystem.getFileStatus(new Path("/hadoop-3.1.3.tar.gz"));
System.out.println("路径:"+fileStatus.getPath());
System.out.println("长度:"+fileStatus.getLen());
System.out.println("副本数:"+fileStatus.getReplication());
fileSystem.close();
}
public static void listStatus() throws IOException, URISyntaxException, InterruptedException {
// 没有设置用户信息
Configuration entries = new Configuration();
entries.set("fs.defaultFS","hdfs://master:9000");
URI uri = new URI("hdfs://master:9000");
FileSystem fileSystem = FileSystem.get(uri,entries,"root");
FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/"));
for (FileStatus fileStatus : fileStatuses) {
if (fileStatus.isFile()) {
long blockSize = fileStatus.getBlockSize();
System.out.println(fileStatus.getPath());
System.out.println("Block块大小:"+blockSize);
System.out.println("长度:"+fileStatus.getLen());
}else {
System.out.println(fileStatus.getPath());
}
}
fileSystem.close();
}
}
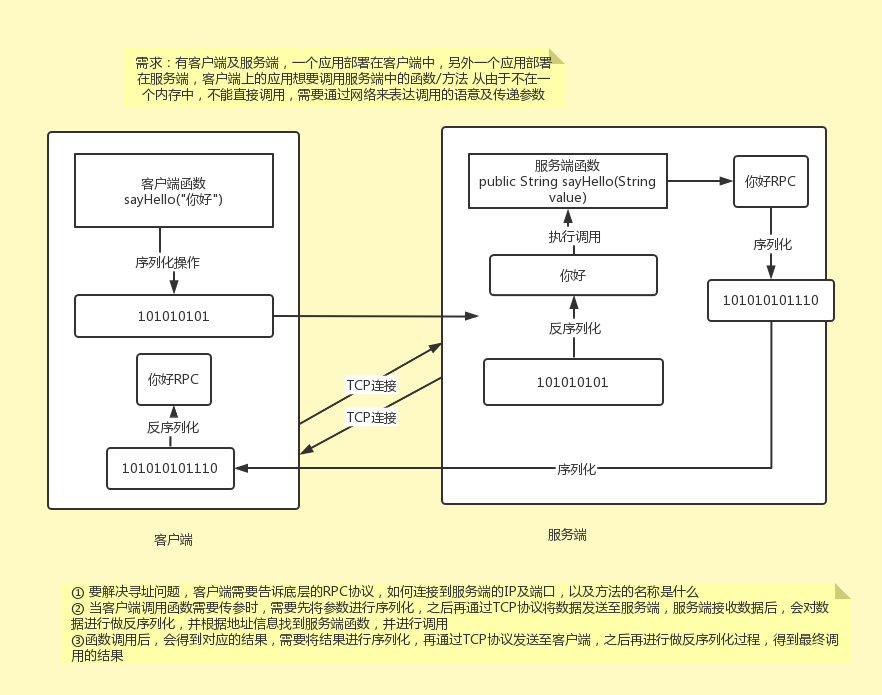
4、RPC协议
- RPC为远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。
- RPC采用客户机(client)/服务器(server)模式。请求程序就是一个客户机,而服务提供程序就是一个服务器。首先,客户机调用进程发送一个有进程参数的调用信息到服务进程,然后等待应答信息。在服务器端,进程保持睡眠状态直到调用信息的到达为止。当一个调用信息到达,服务器获得进程参数,计算结果,发送答复信息,然后等待下一个调用信息,最后,客户端调用进程接收答复信息,获得进程结果,然后调用执行继续进行。
- 如下图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号