大数据框架之一——Hadoop学习第一天
首先我们来了解一下大数据
什么是大数据?
高速:指数据产生的速度非常快,对于用户的使用记录等日志信息,产生的速度会非常快,那么对这部分数据做数据采集分析,要求速度也非常快 所以需要应用分布式处理技术,而大数据所学习的都是分布式处理应用,该应用可以在多个服务器中进行使用,并获取其计算资源,帮助我们完成对应的任务
大量:对于长期积累的数据,数据量非常大,使用什么样的计量单位可以表现数据量大? 对于企业做大数据通常数据量能够达到百TB级以上,数据量的统计关系可以从图中看出
多样化: 大数据所处理的数据种类会非常多,包括结构化(关系型数据库中的数据)和半结构化的数据(日志或者JSON数据)
价值: 能够为企业发展或者决策层做决定提供数据支撑。
真实: 历史发生过的一些数据,都称为有效真实数据
1、Hadoop简介
Hadoop是一个适合海量数据的分布式存储和分布式计算的平台。
Hadoop 解决了两方面问题:一个是数据的存储 另一个是数据的计算
为什么需要使用Hadoop解决海量数据的存储和计算?
当有1T的数据量,拿过来需要对其进行做存储和计算
单个计算机 做数据存储 和 数据计算,那么压力非常大,如何解决单个节点的资源不足问题?
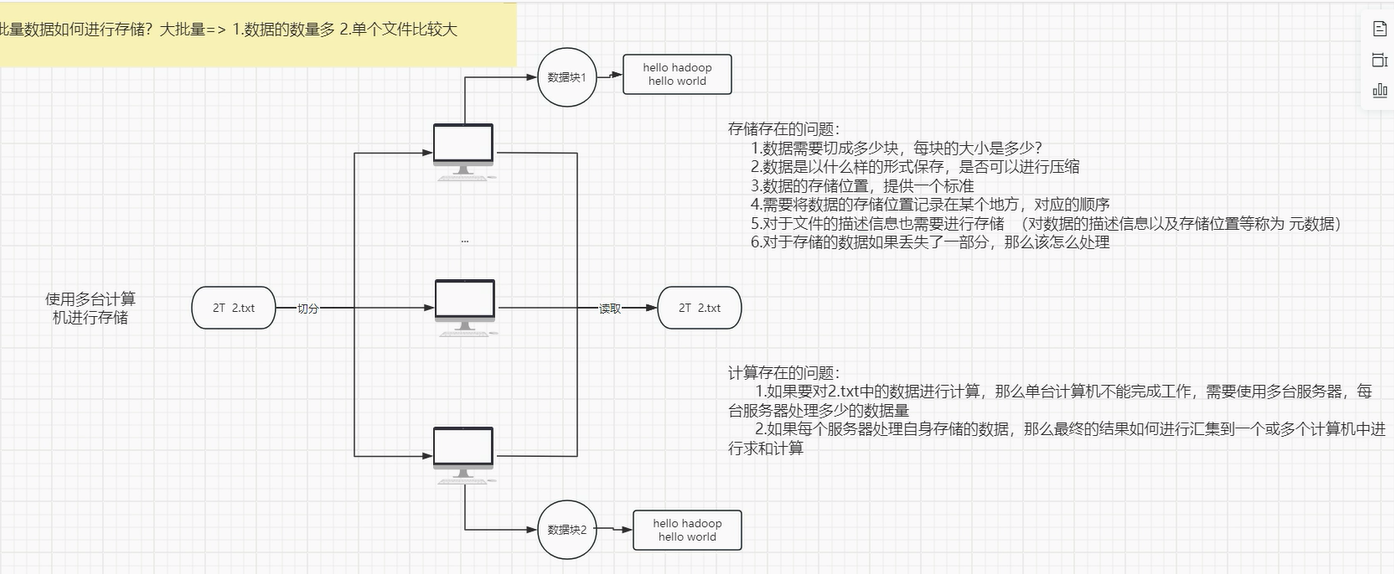
分而治之:
可以将1T数据量,分成10份,由 10个节点(计算机)做数据的存储和计算,每个计算机处理的数据量大概为100G
问题:如何实现对多个节点同时处理同一批数据?
对于同一个文件,那么需要通过切分,将数据分别存放到多个节点中进行做数据存储,那么如果有读取数据的需求,那么就得知道每个切分的数据块,应该存放在哪个节点的哪个路径上,并且是第N个数据块?
同时对于同一个文件,做简单的单词统计,那么每个节点计算自身的数据结果,得到结果后,如何将结果进行做汇总 ?
对于不同的文件,那么需要有一个管理文件的中心,需要读取数据时,要从管理数据的中心获取数据所在位置,再到对应节点上下载读取数据 ?
对于不同文件做数据计算,文件会被切分到部分节点中,如果做数据计算时,当前数据所在节点,不能做数据计算,那么就需要将数据分发给空闲节点做计算,那么如何分发,其他节点做完计算后,如何对数据进行合并?
对于计算过程中,如果计算的数据需要从另外一个计算节点中获取中间结果,那么又需要怎么操作?
同时对数据的权限管理,和计算资源的管理如何实现?
**对于开发人员来说,不可能自己在计算过程中解决如上问题 Hadoop 可以帮助我们在做数据计算过程中,不需要考虑如上问题 **
- Hadoop是一个适合海量数据的分布式存储和分布式计算的平台。
- Hadoop的处理思想是分而治之。
Hadoop组件介绍
- hadoop是一个统称,目前hadoop主要包含三大组件:
- HDFS:是一个分布式存储框架,适合海量的数据存储。
- Map Reduce:是一个分布式计算框架,适合海量的数据计算
- Yarn:是一个资源调度平台,负责给计算框架分配计算资源。
2、Hadoop的分布式搭建
-
Linux桌面模式关闭
# 设置 systemctl set-default multi-user.target # 重启 reboot -
防火墙关闭
systemctl status firewalld systemctl stop firewalld # 关闭开机自启 systemctl disable firewalld -
配置Java环境
echo $JAVA_HOME java -version # Java配置 # 上传jar包并解压 tar -zxvf ...jdk.jar # 配置环境变量 vim /etc/profile JAVA_HOME=/usr/local/soft/jdk1.8.0_171 export PATH=$JAVA_HOME/bin:$PATH -
网络环境
# 查看IP ifconfig # vim /etc/sysconfig/network-scripts/ifcfg-ens33 1 TYPE=Ethernet 2 PROXY_METHOD=none 3 BROWSER_ONLY=no 4 BOOTPROTO=static 5 DEFROUTE=yes 6 IPV4_FAILURE_FATAL=no 7 IPV6INIT=yes 8 IPV6_AUTOCONF=yes 9 IPV6_DEFROUTE=yes 10 IPV6_FAILURE_FATAL=no 11 IPV6_ADDR_GEN_MODE=stable-privacy 12 NAME=ens32 13 UUID=9d8db489-1d03-49dd-9a72-c106b667af6a 14 DEVICE=ens32 15 ONBOOT=yes 16 IPADDR=192.168.44.100 17 netmask=255.255.255.0 18 GATEWAY=192.168.44.2 # 关闭网络管理器 systemctl status NetworkManager systemctl stop NetworkManager # 取消防火墙自启 systemctl disable NetworkManager -
修改主机名称
三台分别执行 vim /etc/hostname 在当前虚拟机中设置Master 之后克隆的三个节点需要设置node1 node2 -
克隆另外两台从节点 node1 node2
选中当前节点 关机 -> 右键 ->管理 -> 克隆 -> 当前状态 -> 创建完整克隆 -> 选择路径修改名称 -> 完成
注意:选中的路径最好是 SSD 固态 同时磁盘空间三个节点最少保证大于70G
-
修改克隆主机 一定要修改
先启动node1节点,配置好之后再启动node2
1.修改网络
vim /etc/sysconfig/network-scripts/ifcfg-ens33
systemctl restart network
2.修改主机名
vim /etc/hostname
reboot
-
修改IP映射
当node1 node2 配置完成后,再启动Master 修改IP映射
vim /etc/hosts # 安装自己的IP修改映射关系 192.168.44.100 master 192.168.44.110 node1 192.168.44.120 node2 -
配置主节点和其他节点之间的免密登录
免密登录
当在Master节点中需要控制node1 和 node2 节点启动相关的一些命令任务
需要使用 ssh root@ip/hostname
后续Hadoop启动会切换到从节点启动任务,需要密码非常麻烦,所以需要配置免密登录
# 在Masetr节点中执行如下命令: # > 需要三次回车 ssh-keygen -t rsa # 将密码复制到 master node1 node2 > 需要输入密码 ssh-copy-id master ssh-copy-id node1 ssh-copy-id node2 # 验证:ssh node1 ctrl + d 退出登录 -
校验时间是否同步
使用xshell对当前所有会话同时发送命令 date 查看系统时间 如果时间不同步 ,那么需要配置
yum install ntp ntpdate time.windows.com -
正式开始配置Hadoop
上传Hadoop并解压
# 使用xftp上传压缩包至master解压 tar -zxvf hadoop-3.1.3.tar.gz -
配置环境变量
vim /etc/profile HADOOP_HOME=/usr/local/soft/hadoop-3.1.3 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH source /etc/profile -
Hadoop相关目录的作用解释
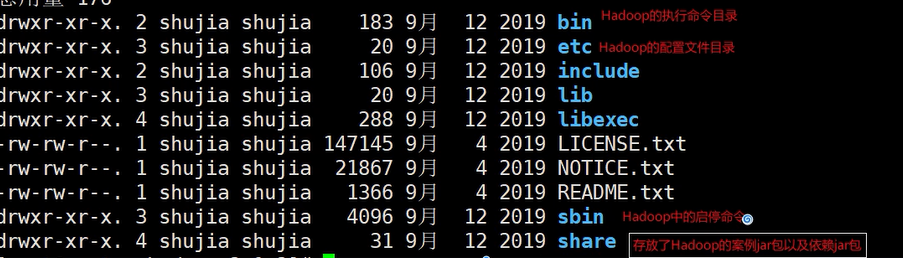
-
修改配置文件
1.core-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <!-- 指定hadoop数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/soft/hadoop-3.1.3/data</value> </property> <!-- 一天的时间存储在HDFS的垃圾回收站里 --> <property> <name>fs.trash.interval</name> <value>1440</value> </property>2.hdfs-site.xml
dfs.namenode.http-address master:50070 该配置项设置网页的访问端口 对于3.x版本的Hadoop其端口为9870
<!-- 2nn web端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:9868</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property>3.yarn-site.xml
- yarn同时也分为主节点和从节点两部分
- resourcemanager就是其主节点,在master上执行
<!-- 指定MR走shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定ResourceManager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <!-- yarn容器允许分配的最大最小内存 --> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>4096</value> </property> <!-- yarn容器允许管理的物理内存大小 --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> <!-- 关闭yarn对物理内存(真实的内存)和虚拟内存的限制检查 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>4.mapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property>workers
直接vim workers 编辑内容
在该文件中主要是对从节点的名称进行配置
node1
node25.hadoop-env.sh
Hadoop的执行环境
# 在最后加入以下配置 export JAVA_HOME=/usr/local/soft/jdk1.8.0_171 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root - yarn同时也分为主节点和从节点两部分
-
分发Hadoop到node1、node2
scp表示远程复制
-r 表示复制的为目录
root@node1 表示用户及IP 由于配置了免密登录所以不需要密码
:
pwdpwd 表示当前所在的目录路径 :需要指定目标位置的路径scp -r hadoop-3.1.3 root@node1:`pwd` scp -r hadoop-3.1.3 root@node2:`pwd` -
初始化Hadoop
# 初始化 hdfs namenode -format只能在Master中执行一次
-
启动Hadoop集群
start-all.sh -
检查
-
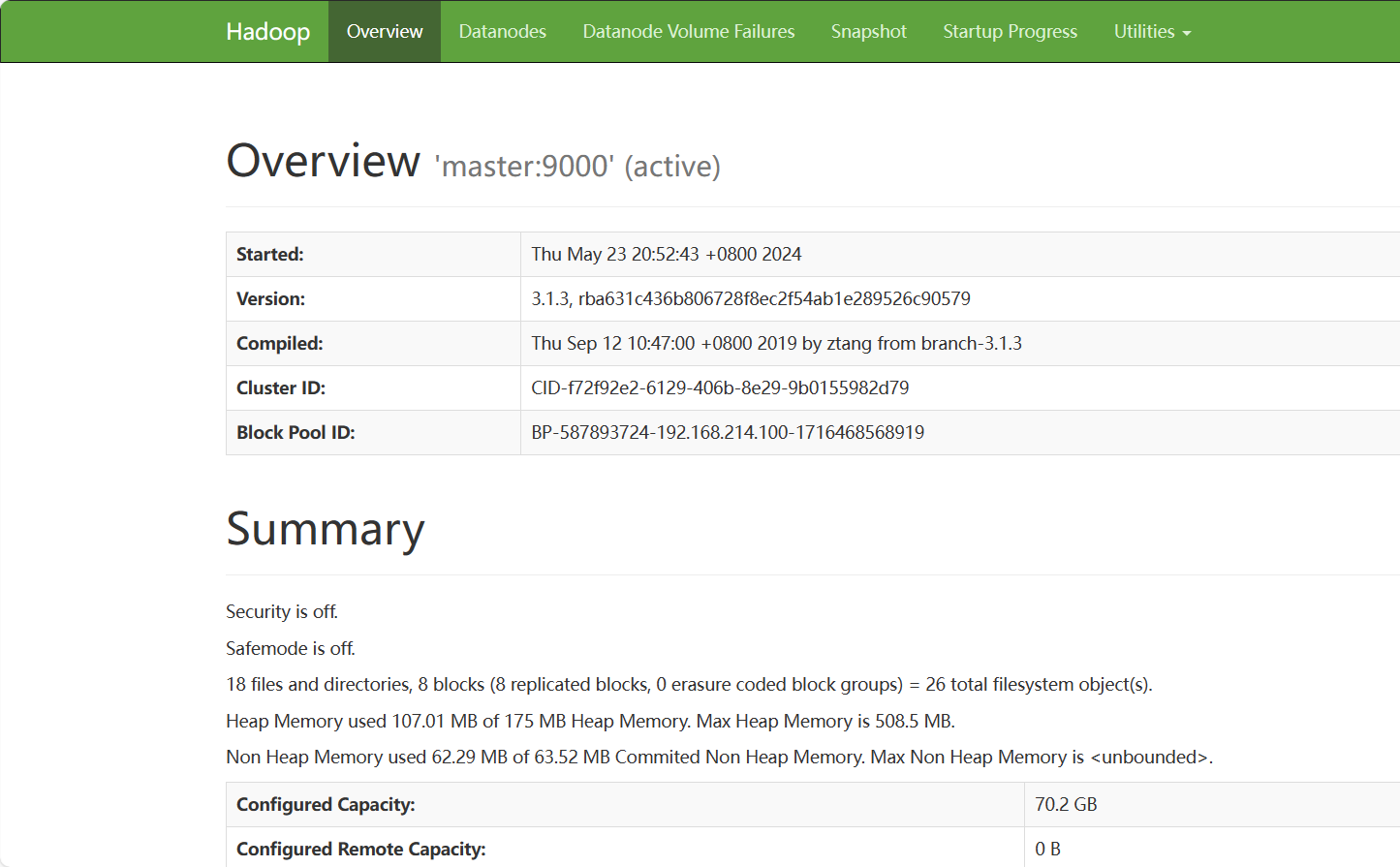
页面
HDFS的访问页面 http://IP:9870/
![image.png]()
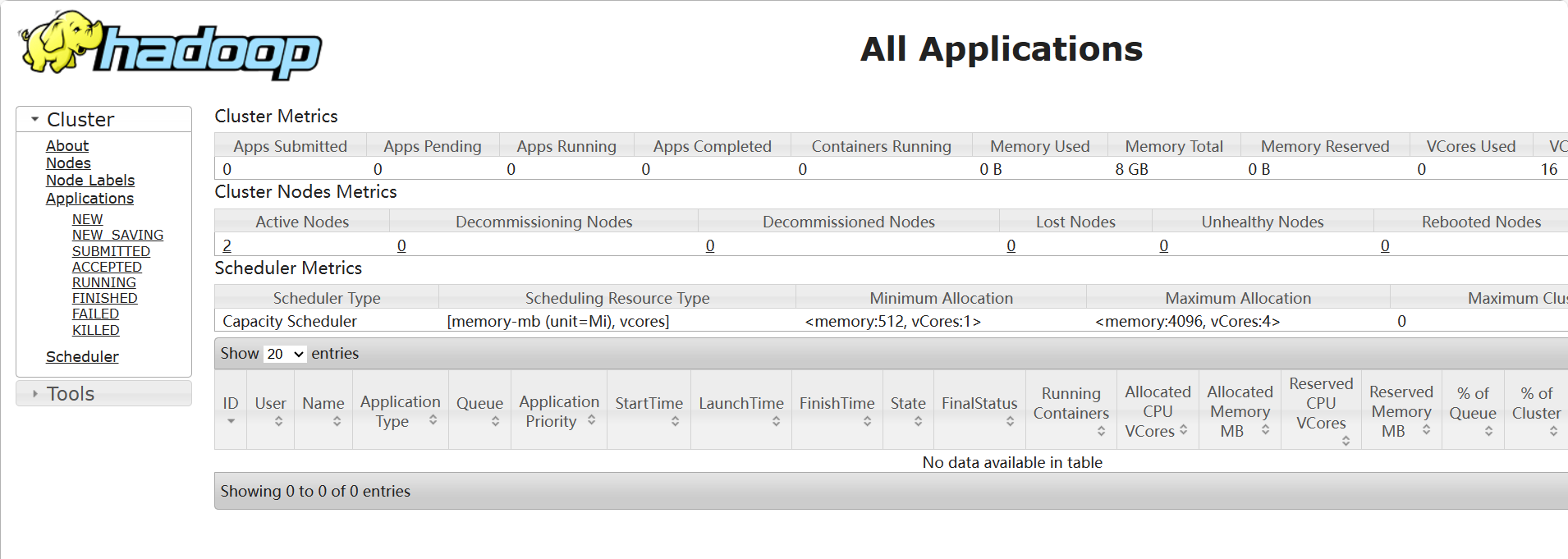
Yarn的访问页面http://master:8088/
![image.png]()
-
查看进程
jps # Master节点 3273 NameNode 3548 SecondaryNameNode 3807 ResourceManager # node1节点 2977 NodeManager 2862 DataNode # node2节点 2977 NodeManager 2862 DataNode
-
-
Hadoop安装或运行过程出现问题
-
1.查看日志
在当前安装目录中找到logs 并分析哪个进程宕机,可以查看进程对应的日志文件
-
2.重新安装
1.删除所有节点中的data目录
2.寻找正确的配置文件,进行替换,并将所有节点进行同步
3.重新格式化
-
3、Hadoop存储
在Hadoop中数据存储是由HDFS组件决定的,可以通过9870端口进行访问,在Hadoop2.x版本中端口为50070
3.1HDFS
3.1.1HDFS的查看文件
- HDFS可以看成是一个文件管理系统,该系统和Linux一致,也是有一个根路径 /
- group:所属组
- replication:副本数
- 上传文件到HDFS中
#在当前的hadoop-3.1.3目录下
hdfs dfs -put ./words.txt /
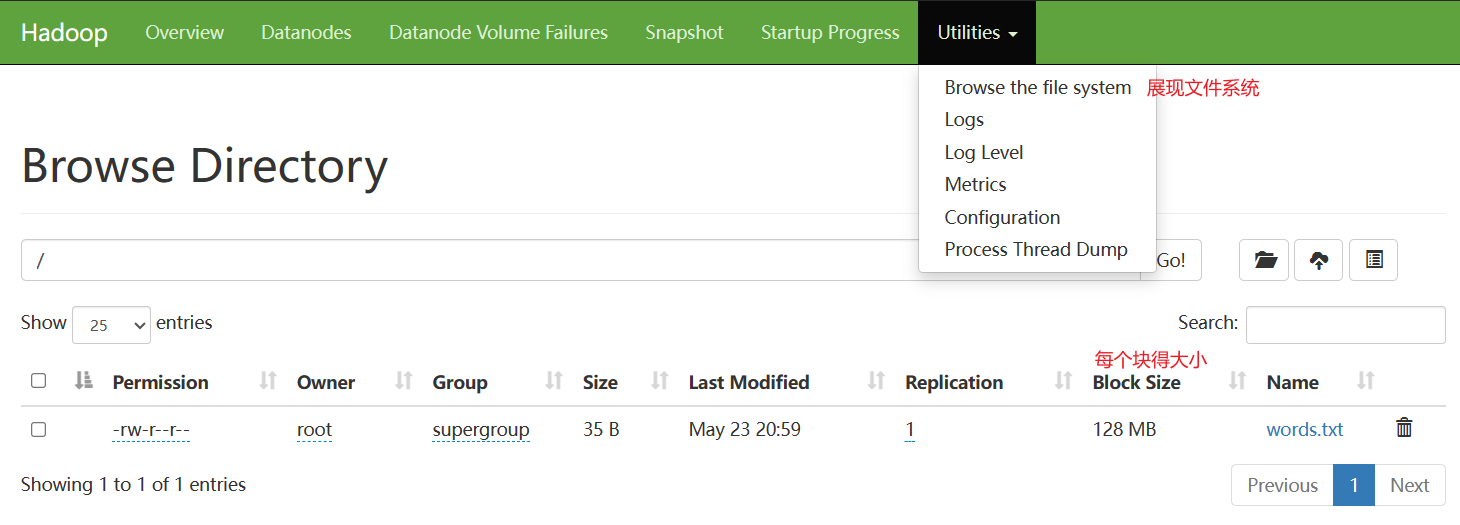
3.1.2HDFS分布式原理
- HDFS具有主从架构。
- HDFS集群由单个名称节点组成,主服务器管理文件系统名称空间并控制客户机对文件的访问。此外,还有许多数据节点,通常是集群中每个节点一个,它们管理连接到运行它们的节点的存储。
3.1.3分布式存储介绍
- 在分布式存储系统中,分散在不同节点中的数据可能属于同一个文件。
- 为了组织众多的文件,把文件可以放到不同的文件夹中,文件夹可以一级一级的包含。我们把这种组织形式称为命名空间(namespace)。命名空间管理着整个服务器集群中的所有文件。
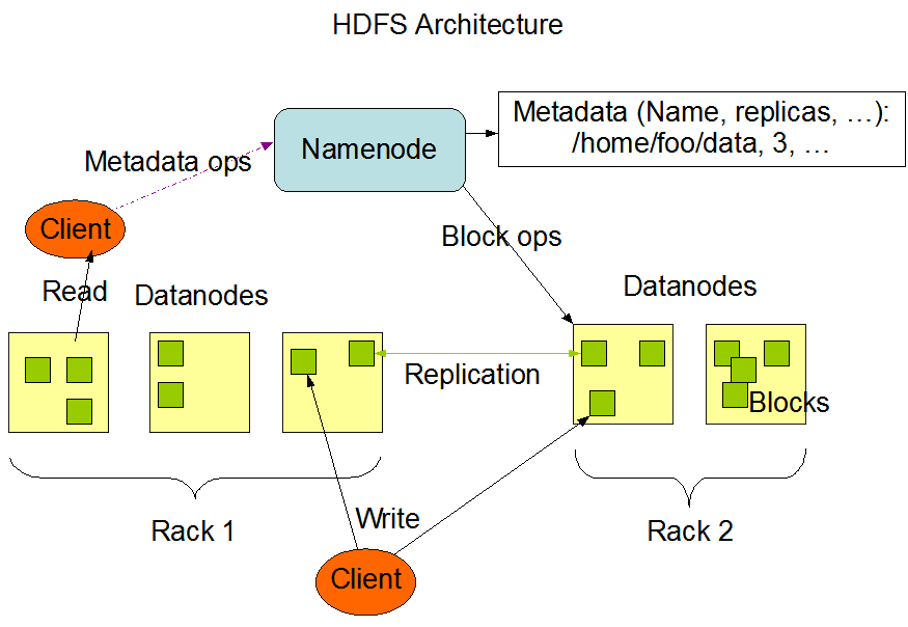
- 集群中不同的节点承担不同的职责。
- 负责命名空间职责的节点称为主节点(master node)
- 负责存储真实数据职责的节点称为从节点(slave node)。
- 主节点负责管理文件系统的文件结构,从节点负责存储真实的数据,称为主从式结构(master-slaves),主节点中是不存储真实数据的。
- 用户操作时,应该先和主节点打交道,查询数据在哪些从节点上存储,然后再到从节点读取。
- 在主节点上,为了加快用户访问的速度,会把整个命名空间信息都放在内存中,当存储的文件越多时,那么主节点就需要越多的内存空间。
- 在从节点存储数据时,有的原始数据文件可能很大,有的可能很小,大小不一的文件不容易管理,那么可以抽象出一个独立的存储文件单位,称为块(block)。
- 数据存放在集群中,可能因为网络原因或者节点硬件原因造成访问失败,最好采用副本(replication)机制,把数据同时备份到多台节点中,这样数据就安全了,数据丢失或者访问失败的概率就小了。
- 方便理解:
- 将Hadoop看成是一个应用
- HDFS相当于一个应用程序
- HDFS中的NameNode和Data Node都是两个进程,同时前者在HDFS中是主节点,用于存储元数据,后者在HDFS中是从节点,用于存储真实的数据。
- 每一个节点里包含的块可以看作是一个线程。
- 解释的流程图
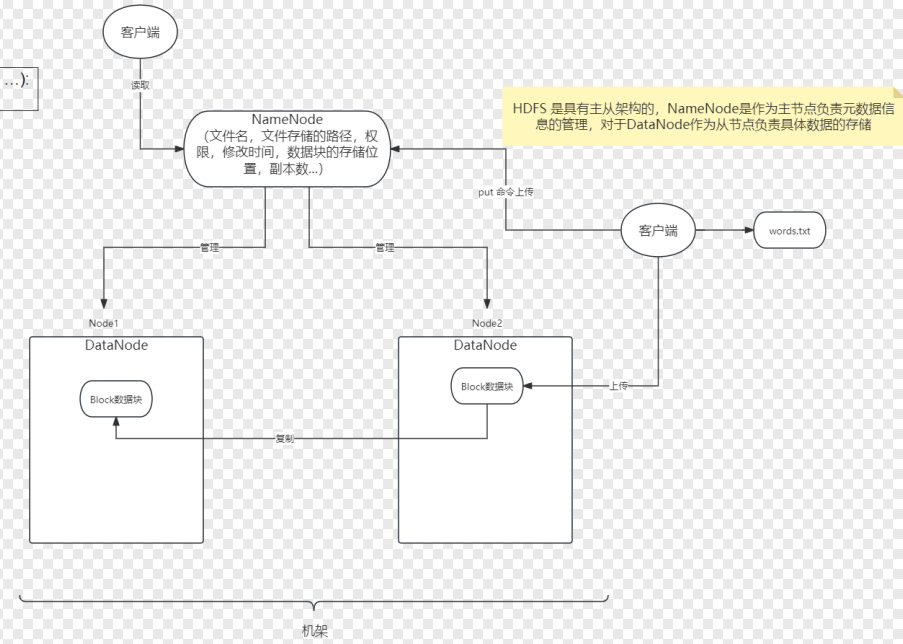
Hadoop分布式计算
- 运行word count实例
#先在HDFS文件系统中新建一个data文件夹
hdfs dfs -mkdir /data
#再将words.txt文件上传到data文件夹中
hdfs dfs -put words.txt /data/
#再执行wordcount命令
hadoop jar hadoop-mapreduce-examples-3.1.3.jar wordcount /data /output
#在HDFS中生成了一个output文件夹,里面会出现一个part-r-00000文件,这个文件就是计算的结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号