

Java数据类型,常量与变量
导航
1.数据类型
2.基本数据类型
3.引用数据类型
4.常量
5.变量
1.数据类型
Java语言是强类型语言,对于每一种数据都定义了明确的具体数据类型。
强类型语言是一种强制类型定义的语言,一旦某一个变量被定义类型,如果不经过强制转换,则它永远就是该数据类型了。
Java的数据类型有两大种,基本数据类型和引用数据类型。
基本数据类型是Java内置的类型,分为整数、小数、字符、布尔这四种类型,共8种。
引用数据类型是基于基本数据类型创建的,包括类、接口、数组、枚举等。JavaSE中提供了一个超级类库,类库中包含了近万种引用数据类型。
2.基本数据类型
基本数据类型是Java内置的类型,分为整数、小数、字符、布尔这四种类型,共8种。
- 8种基本数据类型在内存中占用的字节数
byte: 在内存中占用1个字节,取值范围为-128~127(-2^7~2^7-1)
short:在内存中占用2个字节,取值范围为-2^15~2^15-1
int: 在内存中占用4个字节,取值范围为-2^31~2^31-1
long: 在内存中占用8个字节,取值范围为-2^63~2^63-1
float: 在内存中占用4个字节,取值范围为-3.403E38~3.403E38(E是指数的意思,3.403E38表示3.403乘以10的38次方,E代表的英文是exponent)
double: 在内存中占用8个字节,取值范围为-1.798E308~1.798E308(double的小数点的精度比float的要高)
char: 在内存中占用2个字节,取值范围为0~65535(0~2^16-1)
布尔类型在内存中占用字节大小与JVM有关,取值只有true与false两个值
在Java规范中,并没有明确指出boolean类型占用的字节数。仅仅定义为boolean类型有true何false两个字面值。
因为对虚拟机来说根本就不存在boolean这个类型,boolean类型在编译后会使用其他数据类型来表示。
网上的答案有说一个字节,有说四个字节的
根据《Java虚拟机规范》
虽然定义了boolean这种数据类型,但是只对它提供了非常有限的支持。在Java虚拟机中没有任何供boolean值专用的字节码指令,Java语言表达式所操作的boolean值,在编译之后都使用Java虚拟机中的int数据类型来代替,而boolean数组将会被编码成Java虚拟机的byte数组,每个boolean元素占8位
单个boolean占4个字节,而boolean数组中的boolean元素则占一个字节
Java中每个类型所占的字节大小是一定的,不会因为系统的不同而改变。(指的是在内存中占用的字节)
- byte取值为什么是-128~127?
https://www.cnblogs.com/shizunatsu/p/10617346.html
- 布尔类型在内存中占用几个字节?
在Java规范中,并没有明确指出boolean类型占用的字节数。仅仅定义为boolean类型有true何false两个字面值。
因为对虚拟机来说根本就不存在boolean这个类型,boolean类型在编译后会使用其他数据类型来表示。
网上的答案有说一个字节,有说四个字节的
根据《Java虚拟机规范》
虽然定义了boolean这种数据类型,但是只对它提供了非常有限的支持。在Java虚拟机中没有任何供boolean值专用的字节码指令,Java语言表达式所操作的boolean值,在编译之后都使用Java虚拟机中的int数据类型来代替,而boolean数组将会被编码成Java虚拟机的byte数组,每个boolean元素占8位
单个boolean占4个字节,而boolean数组中的boolean元素则占一个字节
参考:你真的知道Java中boolean类型占用多少个字节吗?
- char在内存中占两个字节如何理解?
一个char类型的变量在内存中存储时占两个字节,char c='a'; 和char c1='你'; 在内存中都是占两个字节。
在内存中的编码,叫做内码。
除了内码,皆是外码。
java中内码(运行内存)中的char使用UTF16的方式编码,一个char占用两个字节。但是某些字符需要两个char来表示。所以,一个字符会占用2个或4个字节。
早期,UTF16采用固定长度2字节的方式编码,两个字节可以表示65536种符号(其实真正能表示要比这个少),足以表示当时unicode中所有字符。但是随着unicode中字符的增加,2个字节无法表示所有的字符,UTF16采用了2字节或4字节的方式来完成编码。Java为应对这种情况,考虑到向前兼容的要求,Java用一对char来表示那些需要4字节的字符。所以,java中的char是占用两个字节,只不过有些字符需要两个char来表示
java中外码中char使用UTF8的方式编码,一个字符占用1~6个字节。(Java的class文件,Java序列化的编码都说的是外码)
UTF16编码中,英文字符占两个字节;绝大多数汉字(尤其是常用汉字)占用两个字节,个别汉字(在后期加入unicode编码的汉字,一般是极少用到的生僻字)占用四个字节。
UTF8编码中,英文字符占用一个字节;绝大多数汉字占用三个字节,个别汉字占用四个字节。
- 数据类型转换
两个数据要做运算,数据类型必须相同。当数值型数据(如byte、short)进行运算时,实际上会先转换成一样的数据类型,再进行运算。
布尔类型boolean不参与数据类型转换,数据类型转换发生在数值型数据之间。
自动转换:小范围数据与大范围数据进行运算时,小范围数据自动转换成大范围数据
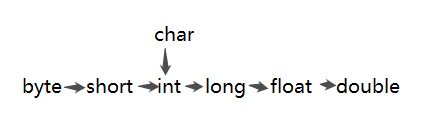
char不能直接转换为short类型的数据,编译器会报“不兼容的类型: 从char转换到short可能会有损失”,因为char的取值范围并不完全包含在short的取值范围内
自动类型转换格式:
范围大的数据类型 变量名 = 范围小的数据类型值; 如下所示
public static void convert_1(){
char c = 'a';
int i = c;//char类型的c自动转换为int类型的i
System.out.println(i);//输出97
}
注意:当 byte 、short 或 char 参与运算时,对应的变量都会提升为int类型,然后再进行运算。
如 byte a=1,b=2,c; byte c = a+b;//这句代码会编译失败,因为byte参与运算,该变量会提升为int类型,所以结果也应该是int类型而不是byte
强制转换:将取值范围大的数据类型强制转换成取值范围小的数据类型
强制类型转换格式:
要转换成的小数据类型 变量名 = (要转换成的小数据类型)取值范围大的数据类型; //注意要转换成的格式要加小括号, () 就是类型转换运算符
强制转换可能会发生数据丢失,如double类型转换成int类型会丢失小数部分,但并不是所有的都是要转换成能转换的最大的,如int类型的200转换成byte类型就是-56。
这是由于数据在计算机底层是采用二进制来存储的,Java中用补码来表示二进制数,int类型的200,其二进制表示为0000 0000 1100 1000,强转为byte类型后,高位被舍弃,则为1100 1000。最高位为1,表示负数,1100 1000的原码为0011 1000(减一,各位取反),绝对值为56,故200强转为byte后为-56。
byte b = (byte)128;输出b的值是-128。因为128是int类型,二进制为 0000 0000 0000 0000 0000 0000 1000 0000。强转为byte类型时,变为 1000 0000 ,最高位是符号位,减一为0111 1111,再按位取反为 1000 0000,转换为十进制是128,加上符号位为-128。计算方式可以按照,byte的取值是-128~127,想象成一个时钟,128就是127+1,127往前走一格就是-128。
- 如何理解Java中默认的整数类型是int类型,默认的浮点数类型是double类型?byte b = 1如何理解?
字面值常量如100,200等在Java中默认都是int类型,底层都是32位二进制数。
编译器具有常量优化机制,当将整数赋值给byte或short时,若整数在byte或short的取值范围内,则系统会自动把该整数转换为byte或short类型,不在对应取值范围则会报错。
如byte b = 1; 1在Java中默认是int类型,1在byte的取值范围内,所以可以自动转换。
而byte b = 128;128也默认是int类型,将128赋值给byte类型的b,编译器会判断出来128不在byte的取值范围内,所以会报错。
long l = 2147483647; //不会报错,因为2147483647是个整数常量,默认是int类型,而且2147483647在int的取值范围内。赋值给long类型的变量l时,会自动转换成long类型
long l = 2147483648;//报错,过大的整数。因为2147483648默认是int类型,而它超出了int的取值范围,也就是说2147483648是个错误的常量
long l = 2147483648L;//正确
在Java中,整数常量如果不在int取值范围内,则必须加上“L”后缀,否则就是错误的常量(因为整数常量默认为int类型,但现在又不在int的取值范围内)
当然,在int取值范围之间整数常量的也可以添加“L”后缀(不区分大小写,最好用大写),添加"L"后缀后就是long类型的常量了。
即,对于超出int取值范围的整数,Java不会自动把它当成long类型来处理,如果希望系统将这个整数当成long类型来处理,则需要在整数值后面加上 L (不区分大小写,最好用大写)。
所有添加了“L”后缀的整数常量都是long类型的,例如:100L、12345678901L都是long类型的常量。
Java中默认的浮点数类型是double类型。包括没有后缀以及使用“D”后缀的。
float类型常量必须添加“F”后缀
float f = 1.0;//报错,因为1.0默认是double类型
float f = 1;//正确,因为 int 类型自动转换成了 float 类型
- 实例
int i = 2147483647 + 1;
编译通过,i的值最终为 -2147483648。
编译可以通过的原因是编译器只会校验每一个操作数2147483647和1是否超过int的取值范围,而不会校验相加之后的结果。
所以如果是int i = 2147483648 + 1; 编译就不会通过了,因为操作数2147483648超过了int的取值范围
那么结果为什么是-2147483648呢?首先2147483647 + 1=2147483648;而2147483648可以用4个字节来表示1000 0000 0000 0000 0000 0000 0000 0000,但最高位为符号位即- 2147483648
int i = 2147483647 + 2147483647;得到的十进制整数4,294,967,294也可以用4个字节来表示1111 1111 1111 1111 1111 1111 1111 1110
int i = 2147483648;//编译失败,过大的整数
byte a=1;byte b=2;byte c=a+b;//编译失败,因为a+b结果是int类型,int类型的值不能赋值给byte
byte a = 1+2;//编译通过,编译器具有常量优化机制,在编译期间能够知道1+2=3,3可以赋值给byte类型的变量
byte b = 127+1;//编译失败,编译时发现128超出了byte的取值范围,所以报错。
byte b = 10;b=b+1;//编译失败,因为1是int型常量,b与1相加时结果是int类型。int类型的数据没有办法直接赋值给byte类型的变量。
1 int i = 0b10000000000000000000000000000111; 2 long binVal1 = 0b10000000000000000000000000000111; 3 long binVal2 = 0b10000000000000000000000000000111L; 4 System.out.println(i);//打印结果-2147483641 5 System.out.println(binVal1);//打印结果-2147483641 6 System.out.println(binVal2);//打印结果2147483655
二进制数0b10000000000000000000000000000111,占用8个字节,若是无符号数的话则对应的十进制是2,147,483,655,若是有符号数的话则对应的十进制数是-2147483641
3.引用数据类型
引用数据类型是基于基本数据类型创建的,包括类、接口、数组、枚举等。JavaSE中提供了一个超级类库,类库中包含了近万种引用数据类型。
可以自己定义类,注意类的名字不能与JDK中已有的类的名字相同。
定义引用类型变量的格式:
数据类型 变量名 = new 数据类型();
调用该类型实例的方法:
变量名.方法名();
要想使用引用数据类型必须需要使用import关键字导入该类所在的包,jang.lang包下的不用导入,默认已经导入了。
import语句必须写在程序中除去注释的最前面,写法如下。
import java.util.Scanner;//注意后面有分号
4.常量
常量就是不变的数据量,包括整数常量,小数常量,布尔常量,字符常量,字符串常量
1.整数常量,有四种进制表示方式
十进制:由数字0-9组成,如 123、45等
二进制:以0b(0B)开头,由数字0-1组成 如0b0011 、0B0011 (Java SE 7开始引入了二进制整数)
八进制:以0开头,由数字0-7组成 如0456、023
十六进制:以0x(0X)开头,由数字0-9及字母a-f(A-F)组成 如0x123
2.小数常量
如12.34、-12.34、5.1e2等
3.布尔常量
true、false
4.字符常量
字符必须使用’’ 包裹,并且其中只能包含一个字符,不能不包含字符。一个空格也是一个字符。
字符分为普通字符和转义字符。普通字符有可以分为可见字符和不可见字符,用到时查ASCII表即可。
如'1','a', ' ','\t'
5.字符串常量
字符串必须使用“”包裹,其中可以包含0~N个字符。
如“asd”,“12345”,“”
5.变量
变量即值可以改变的量,存储在内存中。变量是用来存储数据的。
Java是强类型语言,对于每一种数据都定义了明确的具体数据类型。强类型语言指的是一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这个数据类型了。
如js是弱类型语言,一个变量可以赋不同数据类型的值如 var a="1";a=2; 是完全正确的
定义变量的格式:
数据类型 变量名 = 数据值;
int i = 123;
变量使用时的注意事项:(这里指局部变量)
1.变量必须赋值后才能使用
可以先定义后赋值,也可以定义的时候直接赋值。不赋值不能使用。
变量未赋值但没有使用时编译不会报错,变量未赋值去使用时编译器会报“可能尚未初始化变量”的错误
2.变量使用时有作用域的限制(作用范围在它所在的一对大括号内)
3.变量不能重复定义,即使是在不同的作用域内也不行
public static void main(String[] args){
int x=1;
{
int x=2;
}
System.out.println(x);
}
编译时会报如下错误:
错误: 已在方法 main(String[])中定义了变量 x
int x=2;
- 变量根据数据类型可以分为基本类型变量和引用类型变量
- 对基本类型变量来说,变量值就是所代表的值。
- 对引用变量来说,变量值是取得特定对象的位表示法。
- 引用类型变量可以理解为指向对象的指针,或者说是地址。
- 在Java中我们不会也不应该知道引用变量中实际装载的是什么,它只是用来代表单一的对象。只有Java虚拟机才会知道如何使用引用来取得该对象。
- 我们也不关心引用变量有多大。对于任意一个Java虚拟机来说,所有的引用大小都一样,但不同的Java虚拟机间可能会以不同的方式来表示引用,因此某个Java虚拟机的引用大小可能会大于或小于另一个Java虚拟机的引用。

