

(5)继承与派生
什么是继承
继承是一种新建类的方式,新建的类称之为子类/派生类,被继承的类称之为父类\基类\超类
继承描述的是一种遗传的关系,父类的属性可以被子类访问到
为何要继承
解决类与类之间代码冗余的问题
如何用继承
在python中继承的特点:
1. 在python中一个子类可以同时继承多个父类
2. 在python3如果一个类没有指明继承的类,默认继承object,在python2如果一个类没有指明继承的类,不会默认继承object
Python中的类分成两种
新式类
但凡继承了object类的子类,以及该子类的子子类都是新式类
经典类
没有继承object类的子类,以及该子类的子子类都是经典类
在python3全都是新式类
在python2中才去分经典类与新式类
class Parent1(object): #Python2中类定义传入参数object就是新式类
pass
继承实例
class Parent1(object): #这是父类 ,传入一个object参数,是为了兼容Python2,所以如果要向下兼容这里必须写
pass
class Parent2(object): #这是父类
pass
class Sub1(Parent1): #这是子类单继承
pass
class Sub2(Parent1,Parent2): #这是子类,而且是多继承
pass
PS:如何继承,就是子类把父类当做参数传入下面的代码中
查看继承的方法__bases__
print(Sub1.__bases__)
print(Sub2.__bases__)
查看父类的继承
print(Parent1.__bases__)
print(Parent2.__bases__)
PS:可以看到是一个类object,在python3如果一个类没有指明继承的类,默认继承object
继承实例
class Animal:
def eat(self):
print("%s 吃 " %self.name)
def drink(self):
print ("%s 喝 " %self.name)
def shit(self):
print ("%s 拉 " %self.name)
def pee(self):
print ("%s 撒 " %self.name)
class Cat(Animal):
def __init__(self, name):
self.name = name
self.breed = '猫'
def cry(self):
print('喵喵叫')
class Dog(Animal):
def __init__(self, name):
self.name = name
self.breed='狗'
def cry(self):
print('汪汪叫')
# ######### 执行 #########
c1 = Cat('小白家的小黑猫')
c1.eat()
c2 = Cat('小黑的小白猫')
c2.drink()
d1 = Dog('胖子家的小瘦狗')
d1.eat()
继承的背景下属性查找
在单继承背景下新式类经典类属性查找都一样: 对象->对象的类->父类->父父类...
class Foo:
# xxx=222
pass
class Bar(Foo):
# xxx=111
pass
obj=Bar()
# obj.xxx=0
print(obj.xxx)
PS:查找xxx属性,如果对象里面没有,则去类里面找,类里面没有则去父类找,父类没有则去object里面找然后会报错,这一点新式类和经典类都一样
练习:self.f1是查找了父类的还是自身的
class Foo:
def f1(self):
print('Foo.f1')
def f2(self):
print('Foo.f2')
self.f1() # obj.f1()
class Bar(Foo):
def f1(self):
print('Bar.f1')
obj = Bar()
obj.f2()
首先创建了一个对象调用的是bar类,然后查找f2属性,bar类下没有,则去父类中查找,父类中有f2这个属性,则查找到,然后f2属性下又调用了自身下的属性f1,所以最终查找的是自己的f1属性,而不是父类下的,因为一开始查找f2的时候自身没有,因为继承了父类的属性,所以又去父类中查找,父类中的f2下调用的是自身,因为一开始查找的时候就将自身传入了父类中去查找,所以最后调用的是自己
在子类派生的新方法中重用父类的功能
方式一
class OldboyPeople:
school = 'Oldboy'
def __init__(self,name,age,gender):
self.name=name
self.age=age
self.gender=gender
class OldboyStudent(OldboyPeople):
def choose_course(self):
print('%s is choosing course' %self.name)
class OldboyTeacher(OldboyPeople):
def __init__(self, name, age, gender,level): #如果父类参数满足不了,则可以重新派生定义一个新的,这里就是定义一个新的派生,用内置方法__init__
OldboyPeople.__init__(self,name, age, gender) #这就是子类派生的新方法中重用父类功能,类调用对象就是调用函数,所以少一个参数都不行,这里就是重用父类的功能
self.level=level #这一段是需要自己增加的代码
def score(self,stu,num):
stu.score=num
print('老师[%s]为学生[%s]打了分[%s] ' %(self.name,stu.name,num))
stu1=OldboyStudent('王大炮',18,'male') #初始化学生的信息
print(stu1.__dict__) #查看有没有初始化成功
tea1=OldboyTeacher('Egon',18,'male',10) #初始化老师的信息,如果有重用父类功能,这里也要传入相应的参数
print(tea1.__dict__) #查看有没有初始化成功
方式二
super(自己的类名,self)得到一个特殊对象,该对象专门用来引用父类的属性,严格依赖于继承,完全参照mro列表
class OldboyPeople:
school = 'Oldboy'
def __init__(self,name,age,gender):
self.name=name
self.age=age
self.gender=gender
class OldboyStudent(OldboyPeople):
def choose_course(self):
print('%s is choosing course' %self.name)
class OldboyTeacher(OldboyPeople):
def __init__(self, name, age, gender,level):
super(OldboyTeacher,self).__init__(name,age,gender) #Python2中要这样写
super().__init__(name,age,gender) #Python3中可以这样简写
self.level=level
def score(self,stu,num):
stu.score=num
print('老师[%s]为学生[%s]打了分[%s] ' %(self.name,stu.name,num))
stu1=OldboyStudent('王大炮',18,'male')
print(stu1.__dict__)
tea1=OldboyTeacher('Egon',18,'male',10)
print(tea1.__dict__)
print(stu1.school)
print(tea1.school)
PS:重写父类OldboyPeople.__init__(self,name, age, gender)和super(OldboyTeacher,self).__init__(name,age,gender)两种方式看喜好使用,但是不要混着用
在多继承背景下(非菱形查找),如果一个子类继承了多个分支的父类,多个分支最终没有汇聚到一个非object类上
新式类经典类属性查找都一样
非菱形下属性查找都一样
class E:
def test(self):
print('E')
pass
class F:
def test(self):
print('F')
pass
class B(E):
def test(self):
print('B')
pass
class C(F):
def test(self):
print('C')
pass
class D:
def test(self):
print('D')
pass
class A(B,C,D):
def test(self):
print('A')
pass
obj=A()
obj.test()
PS:由图可知,A继承了BCD,B继承了E,C继承了F,在查找的时候如果B里面没有则去E里查找,如果E没有则去C,如果C没有则去F,如果F没有则去D,D没有就报错(经典类没有object,只有新式类才有)
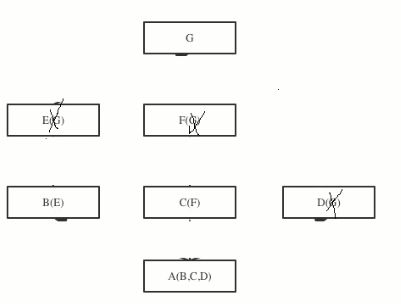
如果一个子类继承了多个分支的父类,多个分支最终汇聚到一个非object类上,称之为菱形继承
在菱形继承的背景下,新式类与经典的属性查找有所不同
经典类和新式类继承下的查找

class G:
def test(self):
print('G')
class E(G):
def test(self):
print('E')
class F(G):
def test(self):
print('F')
class B(E):
def test(self):
print('B')
class C(F):
def test(self):
print('C')
class D(G):
def test(self):
print('D')
class A(B, C, D):
def test(self):
print('A')
obj = A()
print(B.mro()) #只有新式类才有的内置方法,查看属性查找的顺序
print(A.mro())
obj.test()
经典类: 深度优先查找,A->B->E->G->C->F->D
PS:这里的深度就是所谓的一条道走到底,就是从A先一直走到G直到没查询到,然后再走其他的继承直到找到或者没找到
新式类: 广度优先查找,A->B->E->C->F->D->G->object
PS:以哪一个类作为起始查找属性,就会以该类的mro列表为基准来进行属性查找
大前提: 我们是由C为起始引发的属性查找,所以super会参照C的mro列表来进行属性查找
注意: A没有继承B,但是A内super会基于C.mro()继续往后找
class A:
def test(self):
super().test()
class B:
def test(self):
print('from B')
class C(A,B):
pass
c=C()
c.test()
print(C.mro()) #[<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>]
print(A.mro()) #如果用A作为其实触发属性查找就会报错,参照mro字典
obj=A()
obj.test()
PS:super是按照从哪一个类作为起始找的属性,就是参照这个起始类的mro进行查找,super就是重新或者重新的语法
PS:为什么class A里面的super().test()最后会查找到B,因为查询是因为C作为基准引发的,所以就算A和B没有继承关系,C引发了查找,在A里面没有查找到,A里面由引发了一次属性查找,简单理解就是C引发了查找,A里面没有,然后A又引发了一次查找,作为基准就是C没在A里面找到,然后就去B里面找了

