The Linux Command Line——21. 文本处理

cat

在这个例子里,我们创建了一个测试文件 foo.txt 的新版本,其包含两行文本,由两个空白行分开。经由带有-ns 选项的 cat 程序处理之后,多余的空白行被删除,并且对保留的文本行进行编号。然而这并不是多个进程在操作这个文本,只有一个进程。
sort
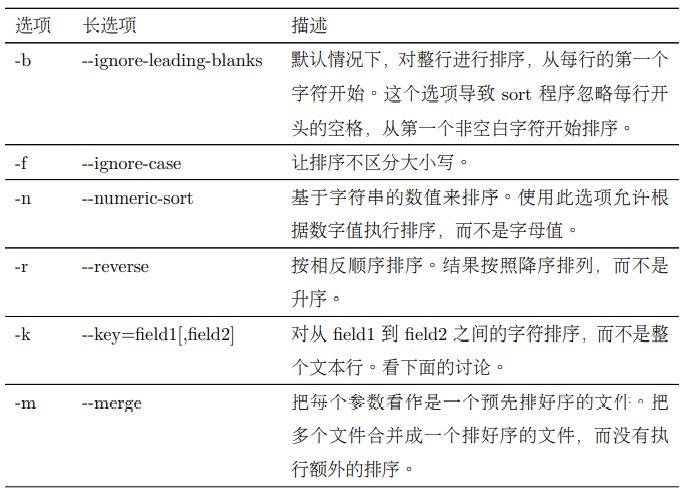
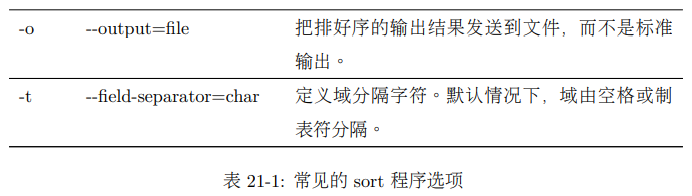
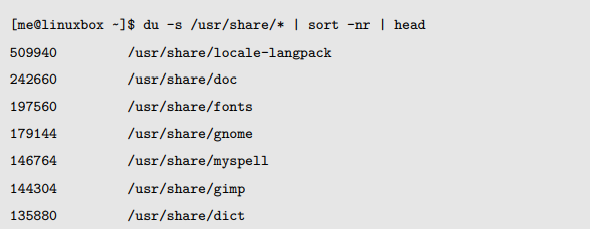
在这个例子里面,我们把结果管道到 head 命令,把输出结果限制为前 10 行。我们能够产生一个按数值排序的列表,来显示 10 个最大的空间消费者。通过使用此 -nr 选项,我们产生了一个反向的数值排序,最大数值排列在第一位。
uniq
当给定一个排好序的文件(包括标准输出),uniq 会删除任意重复行,并且把结果发送到标准输出。
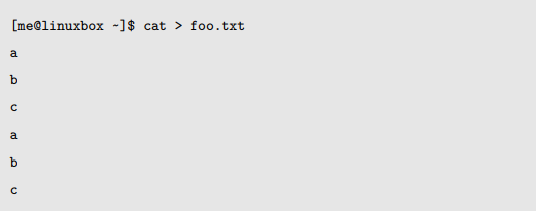
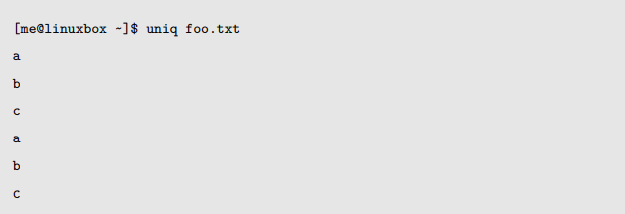
输出结果与原始文件没有差异;重复行没有被删除。实际上,uniq 程序能完成任务,其输入必须是排好序的数据
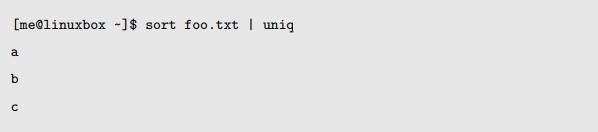
这是因为 uniq 只会删除相邻的重复行。
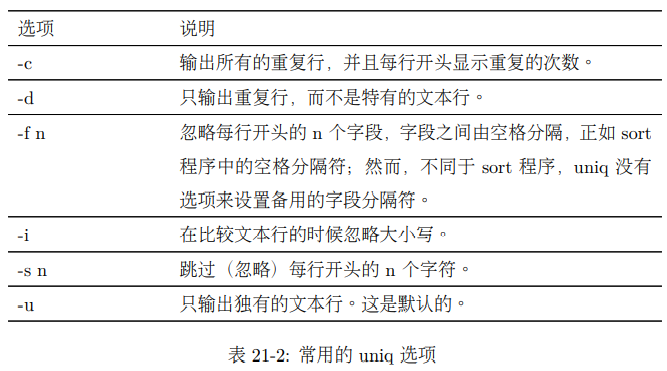
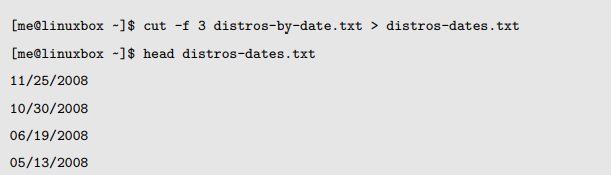
cut
cut 程序被用来从文本行中抽取文本,并把其输出到标准输出。它能够接受多个文件参数或者标准输入。


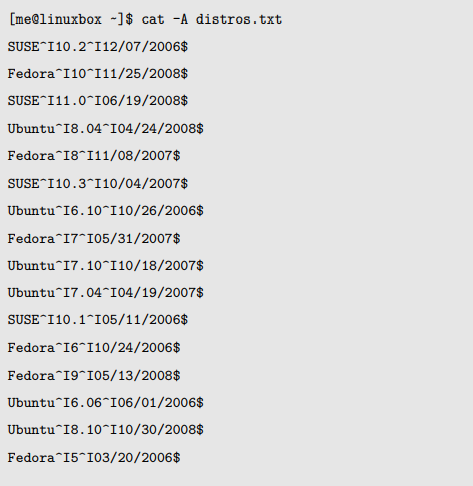
字段之间仅仅是单个 tab 字符,没有嵌入空格。因为这个文件使用了 tab 而不是空格,我们将使用 -f 选项来抽取一个字段:
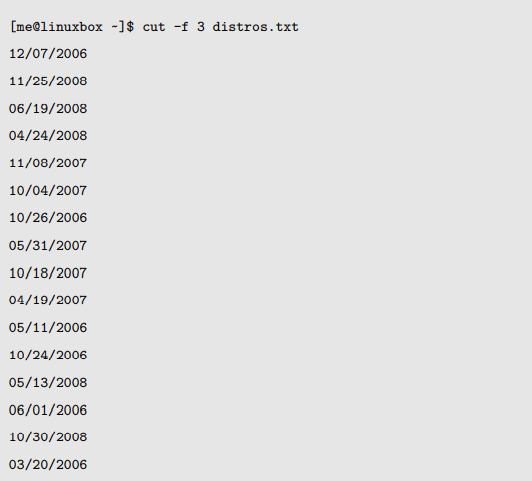
因为我们的 distros 文件是由 tab 分隔开的,最好用 cut 来抽取字段而不是字符。这是因为一个由 tab 分离的文件,每行不太可能包含相同的字符数,这就使计算每行中字符的位置变得困难或者是不可能。
使用-d 选项,我们能够指定冒号做为字段分隔符。
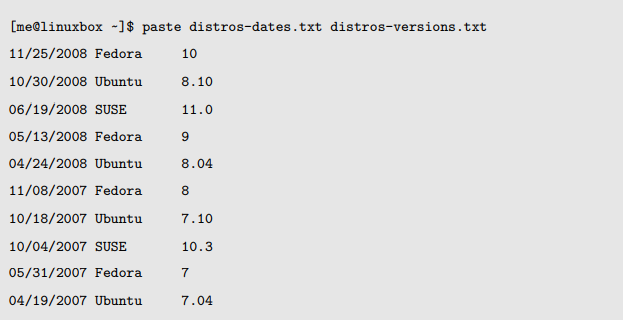
paste
它会添加一个或多个文本列到文件中,而不是从文件中抽取文本列。它通过读取多个文件,然后把每个文件中的字段整合成单个文本流,输入到标准输出。
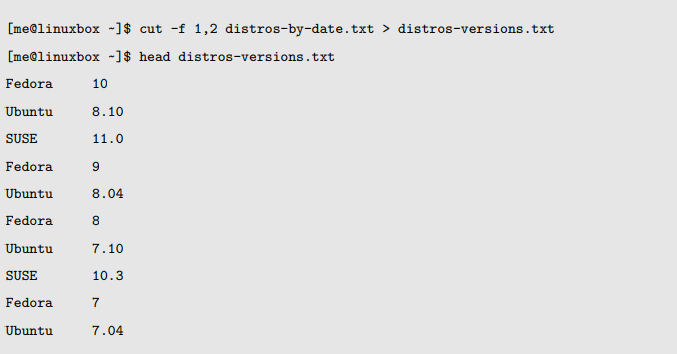
首先我们将产生一个按照日期排序的发行版列表,并把结果存储在一个叫做 distros-by-date.txt 的文件中:

comm
这个 comm 程序会比较两个文本文件,并且会显示每个文件特有的文本行和共有的文本行。
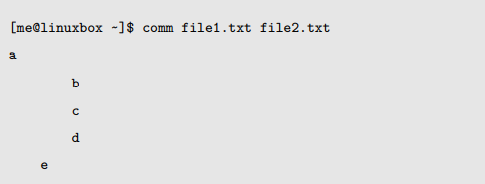
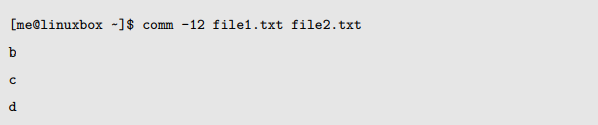
comm 命令产生了三列输出。第一列包含第一个文件独有的文本行;第二列,文本行是第二列独有的;第三列包含两个文件共有的文本行。comm 支持 -n 形式的选项,这里 n 代表 1,2 或 3。这些选项使用的时候,指定了要隐藏的列。
diff
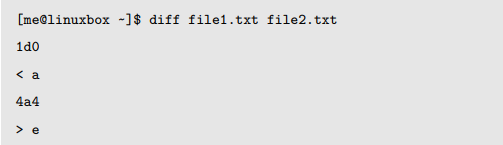
软件开发员经常使用 diff 程序来检查不同程序源码版本之间的更改,diff 能够递归地检查源码目录,经常称之为源码树。

当使用上下文模式(带上 -c 选项),我们将看到这些:
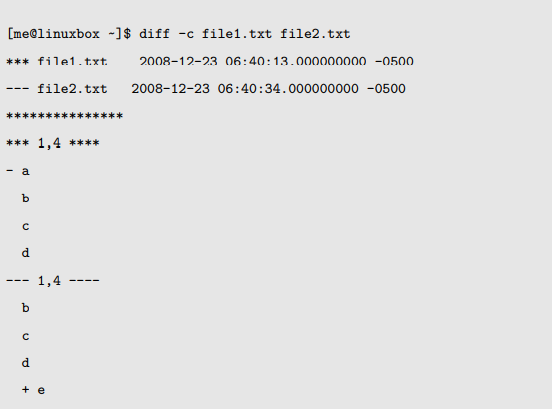
这个输出结果以两个文件名和它们的时间戳开头。第一个文件用星号做标记,第二个文件用短横线做标记。纵观列表的其它部分,这些标记将象征它们各自代表的文件。

patch
这个 patch 程序被用来把更改应用到文本文件中。它接受从 diff 程序的输出,并且通常被用来把较老的文件版本转变为较新的文件版本。

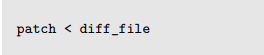
old_file 和 new_file 部分不是单个文件就是包含文件的目录。这个 r 选项支持递归目录树。一旦创建了 diff 文件,我们就能应用它,把旧文件修补成新文件。

在这个例子中,我们创建了一个名为 patchfile.txt 的 diff 文件,然后使用 patch 程序,来应用这个补丁。注意我们没有必要指定一个要修补的目标文件,因为 diff 文件(在统一模式中)已经在标题行中包含了文件名。一旦应用了补丁,我们能看到,现在 file1.txt 与 file2.txt 文件相匹配了。
tr
这个 tr 程序被用来更改字符。我们可以把它看作是一种基于字符的查找和替换操作。换字是一种把字符从一个字母转换为另一个字母的过程。


aspell
一款交互式的拼写检查器。



在显示屏的顶部,我们看到我们的文本中有一个拼写可疑且高亮显示的单词。在中间部分,我们看到十个拼写建议,序号从 0 到 9,然后是一系列其它可能的操作。最后,在最底部,我们看到一个提示符,准备接受我们的选择。
如果我们按下 1 按键,aspell 会用单词“jumped”代替错误单词,然后移动到下一个拼写错的单词,就是“laxy”。如果我们选择替代物“lazy”,aspell 会替换“laxy”并且终止。一旦aspell 结束操作,我们可以检查我们的文件,会看到拼写错误的单词已经更正了。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号