数据采集与融合技术作业三
码云仓库👉https://gitee.com/poetry-joy/crawl_project
作业链接👉https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology/homework/13287
注:代码块可滑动
在下052205144张诗悦
一、作业①⛵
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总下载的图片数量(学号尾数后2位)限制爬取的措施。
输出信息:
Gitee 文件夹链接👉实验三/task1 · 诗悦/2022级数据采集与融合技术 - 码云 - 开源中国
结果👉实验三/task1/task1/images · 诗悦/2022级数据采集与融合技术 - 码云 - 开源中国
1)作业代码和图片
①myspider.py
import scrapy
from ..items import BimagItem
class mySpider(scrapy.Spider):
name = "myspider"
allowed_domains = ["www.weather.com.cn"]
start_urls = ["http://www.weather.com.cn"]
maxitems=44
count=0
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url=url, callback=self.parse)
def download(self, response):
item = BimagItem()
item["bimg"] = response.body
yield item
def parse(self, response, *args, **kwargs):
data = response.body.decode('utf-8')
selector = scrapy.Selector(text=data)
imgs = selector.xpath("//img/@src")
for img in imgs:
# if(i>=self.maxitems):
# break
# self.start_urls=img.extract()
print(img.extract())
yield scrapy.Request(img.extract(), callback=self.download)
②item.py
import scrapy
class BimagItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
bimg = scrapy.Field()
③pipelines.py
class Task1Pipeline:
def __init__(self):
self.count=0
self.maxitems=48
def process_item(self, item, spider):
# print(item["bimg"])
self.count +=1
if self.count<=self.maxitems:
fobj = open("images\\" + str(self.count)+".jpg", "wb")
fobj.write(item["bimg"])
fobj.close()
print("downloaded " + str(self.count))
return item
④并发线程
settings.py
CONCURRENT_REQUESTS = 48
⑤运行结果截图
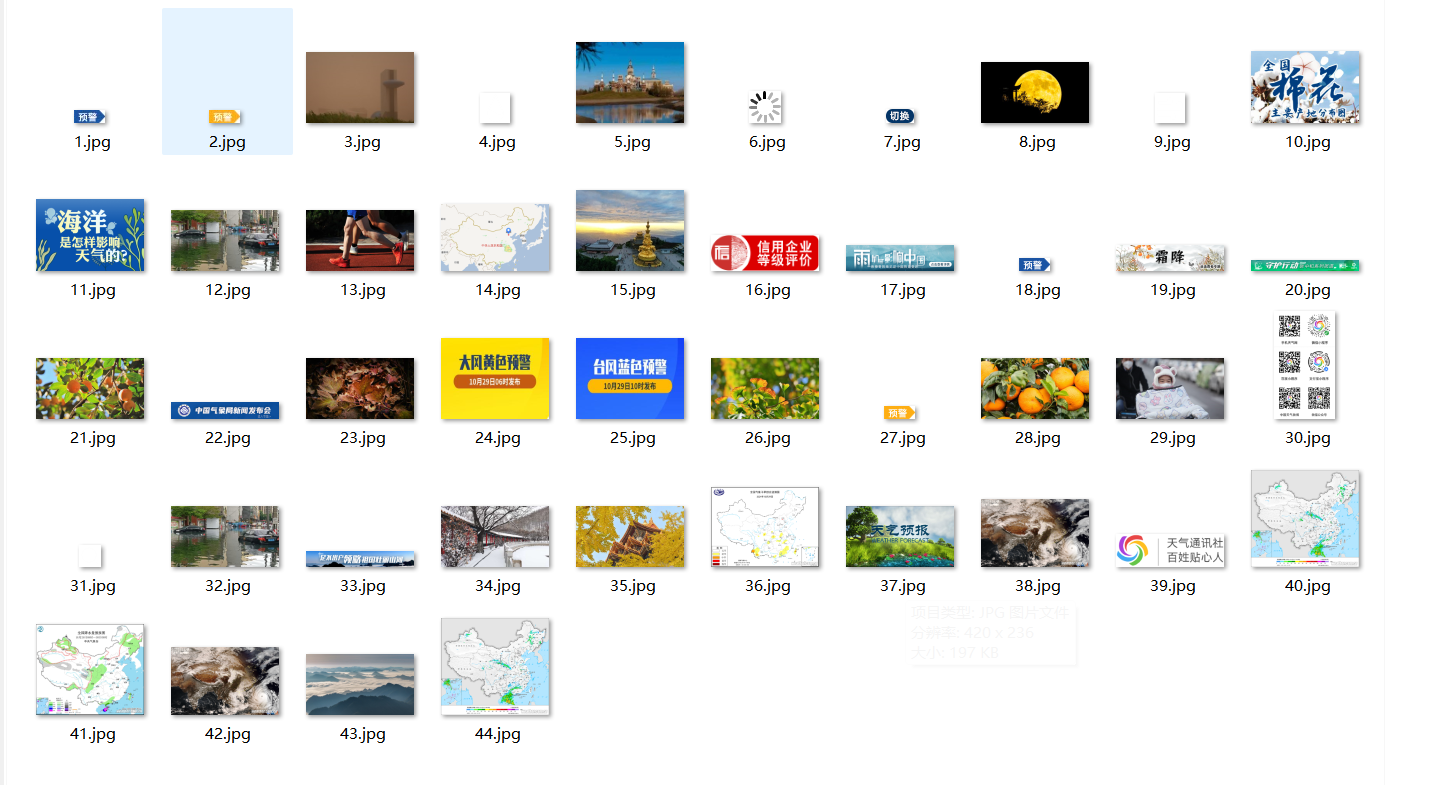
2)作业心得
1、Scrapy是一个非常强大的爬虫框架,它提供了一系列便捷的功能,如自动处理请求、解析网页、下载文件等。这使得构建爬虫程序变得更加高效和简单。
2、在实现单线程和多线程爬取时,我深刻感受到了多线程爬取在效率上的优势。单线程爬取时,速度相对较慢,而多线程爬取可以显著提高爬取速度,但同时需要注意线程安全和资源消耗问题。
3、作业中要求根据学号尾数来控制爬取的页数和图片数量,这让我意识到在实际应用中控制爬取范围的重要性。无节制的爬取不仅可能违反网站的使用政策,还可能导致资源浪费和不必要的法律风险。
4、将下载的图片存储在指定的images子文件夹中,并在控制台输出下载的URL信息,这样的设计有助于清晰地查看爬取结果和进行后续的数据分析。同时,截图的要求也确保了爬取结果的可视化验证。
5、在编写爬虫程序时,我尽量将代码模块化,使得单线程和多线程的实现可以共享大部分代码逻辑。这不仅提高了代码的可读性,也方便了后续的维护和扩展。
6、在爬取过程中,我遇到了反爬虫机制、网页结构变化等问题。通过调整爬取策略、增加异常处理等方式,我成功地解决了这些问题,并更加深入地理解了爬虫的实战技巧。
二、作业 ②🐟
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
技巧:在谷歌浏览器中进入 F12 调试模式进行抓包,查找股票列表加 载使用的 url,并分析 api 返回的值,并根据所要求的参数可适当更改 api 的请求参数。根据 URL 可观察请求的参数 f1、f2 可获取不同的数 值,根据情况可删减请求的参数。 参考链接:https://zhuanlan.zhihu.com/p/50099084
输出信息:
Gitee 文件夹链接👉实验三/task3 · 诗悦/2022级数据采集与融合技术 - 码云 - 开源中国
结果👉实验三/task3/task3/stock.csv · 诗悦/2022级数据采集与融合技术 - 码云 - 开源中国

1)作业代码和图片
①myspider.py
import scrapy
import re
import json
from ..items import Task3Item
class MySpider(scrapy.Spider):
name = "myspider"
start_urls = [
"https://54.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112405164563266376507_1728983460925&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1728983460926"
]
def parse(self, response):
# 提取JSONP中的JSON部分
jsonp_match = re.search(r'\((.*?)\)', response.text)
print(jsonp_match)
if jsonp_match:
json_data = json.loads(jsonp_match.group(1))
data_list = json_data.get('data', {}).get('diff', [])
# 遍历并处理数据
for data in data_list:
# print(f"股票名称: {data.get('f14')}, 最新价: {data.get('f2')}")
item=Task3Item()
item["sno"]=data.get('f12')
item["sname"]=data.get('f14')
item["sprice"]=data.get('f2')
item["rate"]=str(data.get('f3'))+"%"
item["ratee"]=data.get('f4')
item["num"]=str(data.get('f5'))+"万"
item["price"]=str(data.get('f6'))+"亿"
item["rating"]=data.get('f7')
item["max"]=data.get('f15')
item["min"]=data.get('f16')
item["today"]=data.get('f17')
item["yesterday"]=data.get('f18')
yield item
②item.py:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class Task3Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
sno = scrapy.Field()
sname = scrapy.Field()
sprice=scrapy.Field()
rate=scrapy.Field()
ratee=scrapy.Field()
num=scrapy.Field()
price=scrapy.Field()
rating=scrapy.Field()
max=scrapy.Field()
min=scrapy.Field()
today=scrapy.Field()
yesterday=scrapy.Field()
③pipelines.py:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import sqlite3
class Task3Pipeline(object):
def __init__(self):
self.con = None
self.cursor = None
self.opened = False
self.count = 0
def open_spider(self, spider):
print("opened")
self.con = sqlite3.connect('股票数据库.db')
self.cursor = self.con.cursor()
self.con.execute('''CREATE TABLE stock (
序号 INTEGER PRIMARY KEY,
股票代码 TEXT NOT NULL,
股票名称 TEXT NOT NULL,
最新报价 TEXT NOT NULL,
涨跌幅 TEXT NOT NULL,
涨跌额 TEXT NOT NULL,
成交量 TEXT NOT NULL,
成交额 TEXT NOT NULL,
振幅 TEXT NOT NULL,
最高 TEXT NOT NULL,
最低 TEXT NOT NULL,
今开 TEXT NOT NULL,
昨收 TEXT NOT NULL
);''')
self.opened = True
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "条数据")
def process_item(self, item, spider):
print(item["sname"])
print(item["sprice"])
print()
if self.opened:
self.cursor.execute("INSERT INTO stock (股票代码, 股票名称, 最新报价, 涨跌幅,涨跌额 ,成交量,成交额, 振幅, 最高, 最低, 今开, 昨收) VALUES (?,?,?,?,?,?,?,?,?,?,?,?)", (item["sno"], item["sname"],item["sprice"],item["rate"],item["ratee"],item["num"],item["price"],item["rating"],item["max"],item["min"],item["today"],item["yesterday"]))
self.count += 1
return item
④结果截图
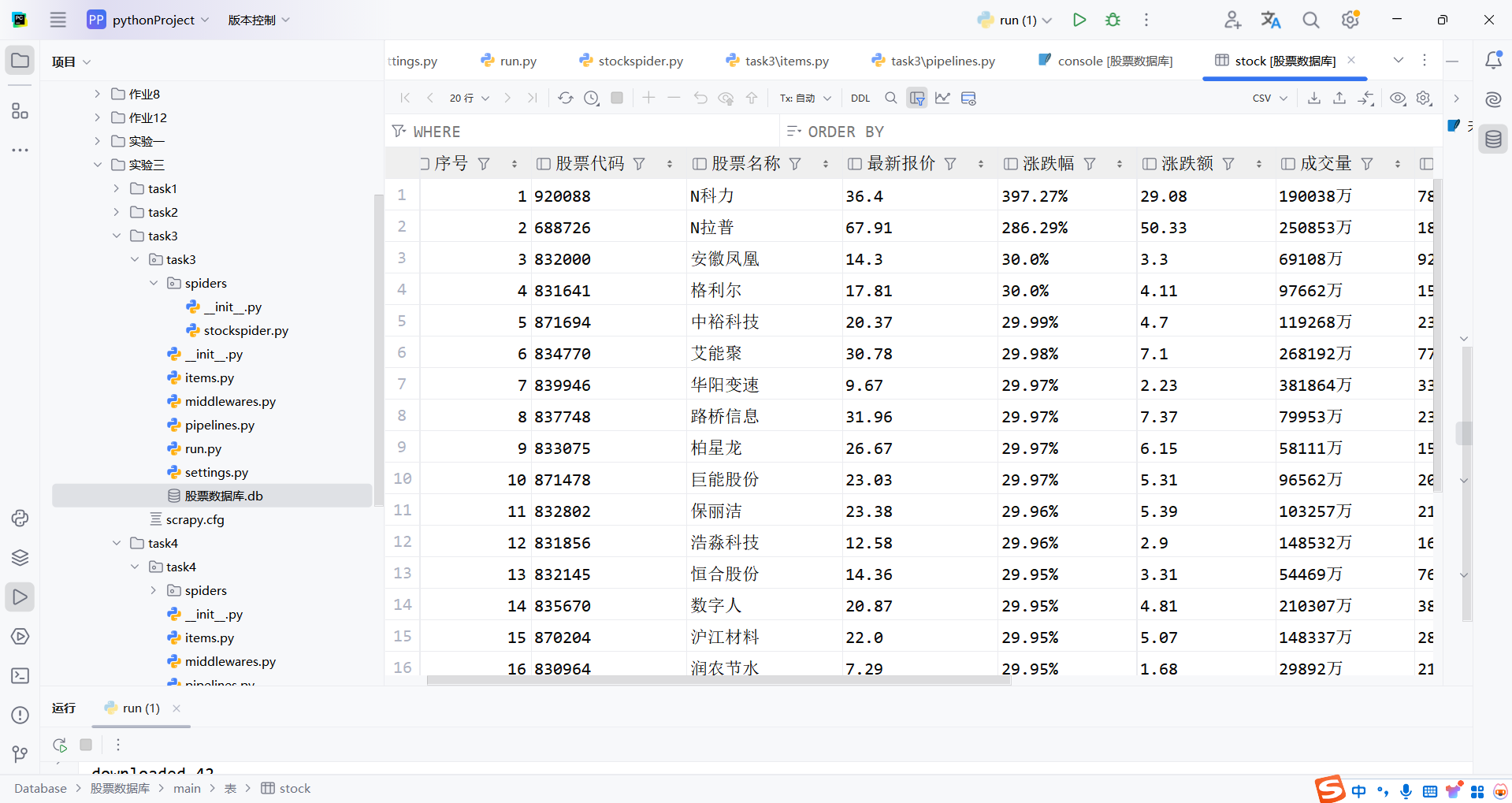
2)作业心得
1、通过此次作业,我进一步熟悉了Scrapy框架中的数据流处理,特别是Item和Pipeline的配合使用。Item用于定义数据结构,而Pipeline则负责数据的清洗、处理和存储,这样的设计使得爬虫程序更加模块化和易于维护。
2、将爬取到的股票信息存储到MySQL数据库中,让我对数据库的操作有了更深入的理解。从创建数据库和表,到插入和查询数据,我都能够熟练操作,并且学会了如何通过Python与MySQL进行交互。
3、在设计数据表时,我仔细考虑了字段的命名、数据类型和约束条件。通过合理的表结构设计,我确保了数据的完整性和一致性,同时也方便了后续的数据查询和分析。
4、在爬取和存储数据的过程中,我遇到了不少异常情况和脏数据。通过添加异常处理逻辑和数据清洗步骤,我成功地解决了这些问题,保证了数据的准确性和可靠性。
5、在编写爬虫程序时,我注重代码的复用性和模块化设计。通过定义通用的函数和类,我减少了重复代码的数量,提高了代码的可读性和可维护性。
6、在作业过程中,我遇到了网站反爬虫机制、数据格式不一致等问题。通过调整爬取策略、增加数据验证和清洗步骤等方式,我成功地克服了这些困难,并更加深入地理解了爬虫的实战技巧。
三、作业③
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
输出信息:
Gitee 文件夹链接👉 实验三/task4 · 诗悦/2022级数据采集与融合技术 - 码云 - 开源中国
结果👉实验三/task4/task4/stock.csv · 诗悦/2022级数据采集与融合技术 - 码云 - 开源中国
| Currency | TBP | CBP | TSP | CSP | Time |
|---|---|---|---|---|---|
| 阿联酋迪拉姆 | 198.58 | 192.31 | 199.98 | 206.59 | 11:27:14 |
1)作业代码和图片
①myspider.py
import scrapy
from ..items import Task4Item
class MyspiderSpider(scrapy.Spider):
name = "myspider"
# allowed_domains = ["127.0.0.1:5000"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
data = response.body.decode('utf-8')
selector = scrapy.Selector(text=data)
td_element=selector.xpath("//tr/td")
td_texts = []
for td in td_element:
text = td.xpath("text()").extract_first() # 提取第一个文本节点
td_texts.append(text if text is not None else '') # 如果没有文本,则添加空字符串
print(td_texts)
item = Task4Item()
for i in range(2,len(td_texts)-10):
if i%8==2:
Currency=td_texts[i]
item["Currency"] = Currency
if i%8==3:
TBP = td_texts[i]
item["TBP"] = TBP
if i%8==4:
CBP = td_texts[i]
item["CBP"] = CBP
if i%8==5:
TSP = td_texts[i]
item["TSP"] = TSP
if i%8==6:
CSP = td_texts[i]
item["CSP"] = CSP
if i%8==1:
Time = td_texts[i]
item["Time"] = Time
yield item
②item.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class Task4Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Currency=scrapy.Field()
TBP=scrapy.Field()
CBP=scrapy.Field()
TSP=scrapy.Field()
CSP=scrapy.Field()
Time=scrapy.Field()
③pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import sqlite3
class Task4Pipeline(object):
def __init__(self):
self.con = None
self.cursor = None
self.opened = False
self.count = 0
def open_spider(self, spider):
print("opened")
self.con = sqlite3.connect('银行数据库plus.db')
self.cursor = self.con.cursor()
self.con.execute('''CREATE TABLE data (
Currency TEXT NOT NULL,
TBP FLOAT ,
CBP FLOAT ,
TSP FLOAT ,
CSP FLOAT ,
Time TEXT
);''')
self.opened = True
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "条数据")
def process_item(self, item, spider):
if self.opened:
self.cursor.execute("INSERT INTO data (Currency,TBP,CBP,TSP,CSP,Time) VALUES (?,?,?,?,?,?)", (item["Currency"], item["TBP"],item["CBP"],item["TSP"],item["CSP"],item["Time"]))
self.count += 1
return item
④运行结果截图
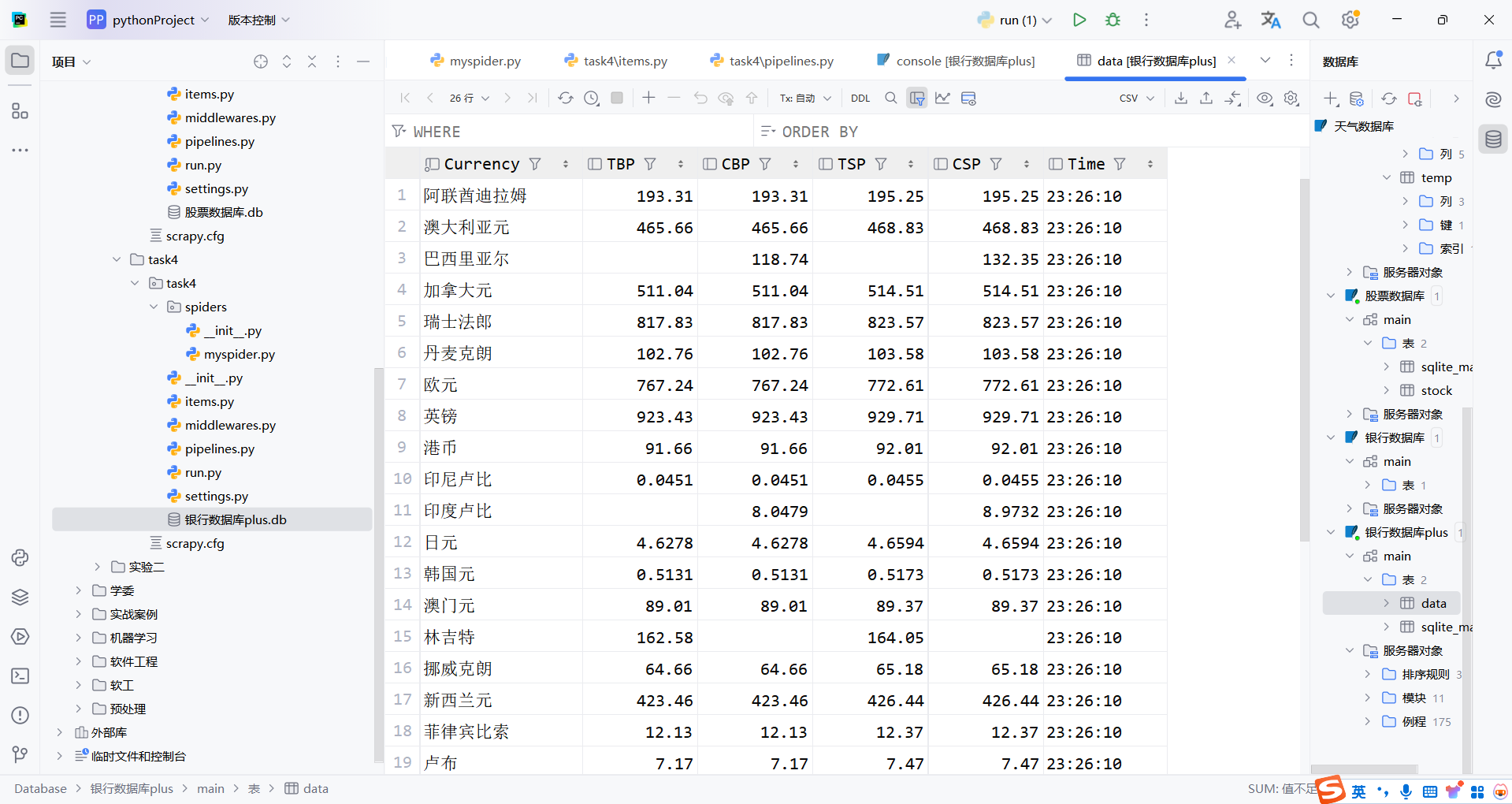
3)作业心得
1、外汇数据相比股票数据有其独特性,它涉及到多种货币之间的汇率,并且这些汇率是实时变动的。因此,在爬取外汇数据时,我需要更加关注数据的时效性和准确性。通过中国银行网这样的权威网站获取数据,可以确保数据的可靠性。
2、在爬取外汇网站数据时,我再次深刻体会到了XPath选择器的灵活性。由于外汇数据的结构相对固定,我可以利用XPath精确地定位到需要的数据节点,从而高效地提取出货币名称、汇率等信息。
3、在Scrapy的Pipeline中,我根据外汇数据的特点进行了定制化的处理。例如,对于汇率数据,我需要进行数值转换和格式化;对于时间数据,我需要进行时间戳的转换等。这些定制化的处理使得数据更加符合存储和分析的需求。
4、针对外汇数据的特点,我对MySQL数据库的设计进行了优化。我创建了专门的表来存储外汇数据,并设置了合理的字段类型和索引,以提高数据查询和插入的效率。同时,我还考虑了数据的冗余和一致性,确保了数据库的可靠性和稳定性。
5、由于外汇数据的实时性要求较高,我在爬取策略上进行了调整。我设置了较短的爬取间隔,并采用了增量爬取的方式,只获取更新的数据,从而减少了不必要的网络请求和数据处理负担。
6、在爬取外汇数据时,我也遇到了网络异常、数据格式变化等问题。通过完善异常处理逻辑,我能够及时地捕获并处理这些异常,保证了爬虫程序的稳定性和健壮性。

