数据采集与融合技术作业二
码云仓库👉https://gitee.com/poetry-joy/crawl_project
作业链接👉https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology/homework/13285
注:代码块可滑动
在下052205144张诗悦
一、作业①⛵
要求:在中国气象网(http://www.weather.com.cn)给定城市集的 7 日天气预报,并保存在数据库。
输出信息:
Gitee 文件夹链接👉 实验二/天气数据库.db · 诗悦/2022级数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
代码👉实验二/task1.py · 诗悦/2022级数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
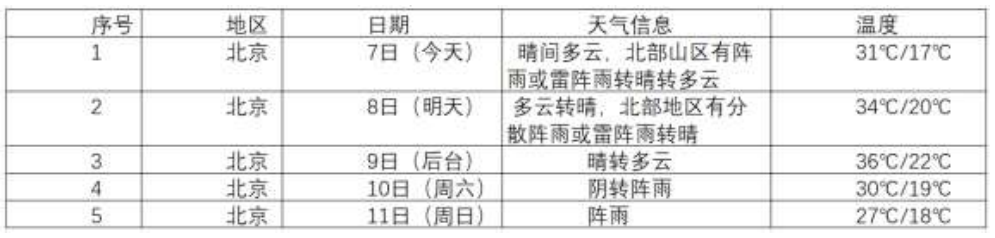
1)作业代码和图片
# _*_ coding : utf-8 _*_
# @Time : 16:35
# @Author : yoyo
# @File : task1
# @Project : pythonProject
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
url="http://www.weather.com.cn/weather/101280601.shtml"
headers={"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"lxml")
lis=soup.select("ul[class='t clearfix'] li")
conn = sqlite3.connect('天气数据库.db')
# 创建一个游标对象
cursor = conn.cursor()
# 创建一个表
cursor.execute('''
CREATE TABLE IF NOT EXISTS temp (
data varchar(10) primary key,
weather TEXT NOT NULL,
temp varchar(50) NOT NULL
)
''')
for li in lis:
date=li.select('h1')[0].text
weather=li.select('p[class="wea"]')[0].text
if li.select('p[class="tem"] span'):
max_temp=li.select('p[class="tem"] span')[0].text
min_temp = li.select('p[class="tem"] i')[0].text
temp = max_temp + "/" + min_temp
else:
max_temp="当前温度为:"
min_temp = li.select('p[class="tem"] i')[0].text
temp = max_temp + min_temp
print(date,weather,temp)
cursor.execute("INSERT INTO temp (data, weather,temp) VALUES (?, ? ,?) " , (date, weather,temp))
conn.commit()
# 关闭连接
conn.close()
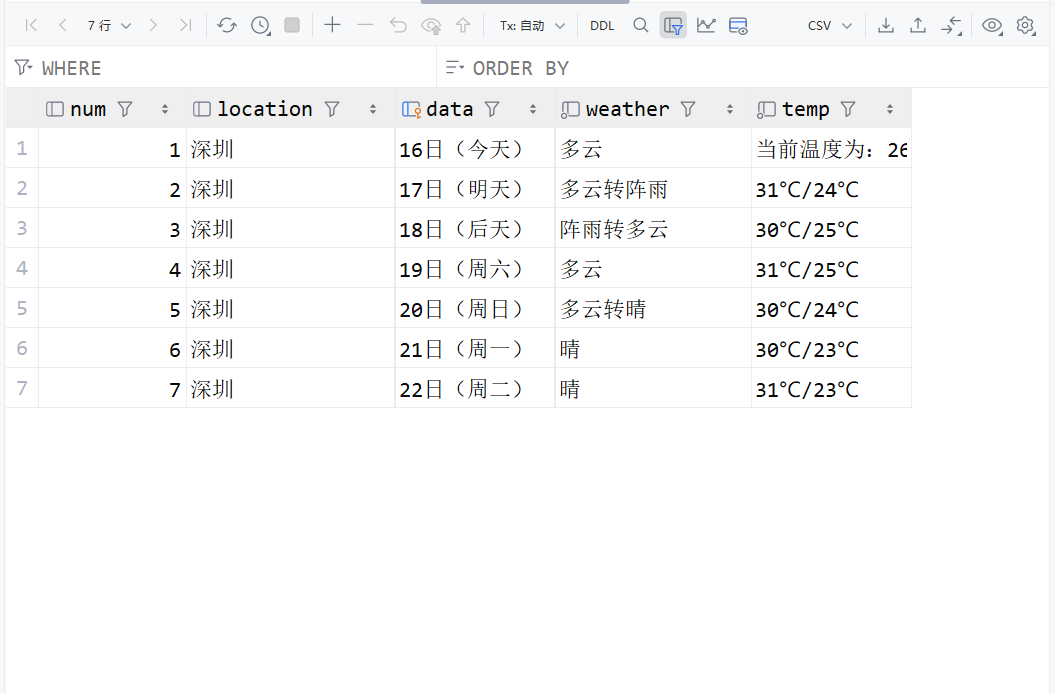
2)作业心得
1、利用urllib和BeautifulSoup库,实现从指定URL抓取网页数据,通过模拟浏览器请求头避免访问限制。
2、使用UnicodeDammit自动检测并处理网页的字符编码问题,确保数据正确解析。
3、通过BeautifulSoup的选择器,精准提取所需天气信息,如日期、天气状况和温度。
4、利用sqlite3数据库,创建表格并存储抓取的数据,便于后续查询和分析。
5、在解析温度信息时,考虑了不同情况下的数据格式,增强了代码的健壮性。
二、作业 ②🐟
要求:用 requests 和 BeautifulSoup 库方法定向爬取股票相关信息,并 存储在数据库中。
候选网站:东方财富网:https://www.eastmoney.com/ 新浪股票:http://finance.sina.com.cn/stock/
技巧:在谷歌浏览器中进入 F12 调试模式进行抓包,查找股票列表加 载使用的 url,并分析 api 返回的值,并根据所要求的参数可适当更改 api 的请求参数。根据 URL 可观察请求的参数 f1、f2 可获取不同的数 值,根据情况可删减请求的参数。 参考链接:https://zhuanlan.zhihu.com/p/50099084
输出信息:
代码👉实验二/task2.py · 诗悦/2022级数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
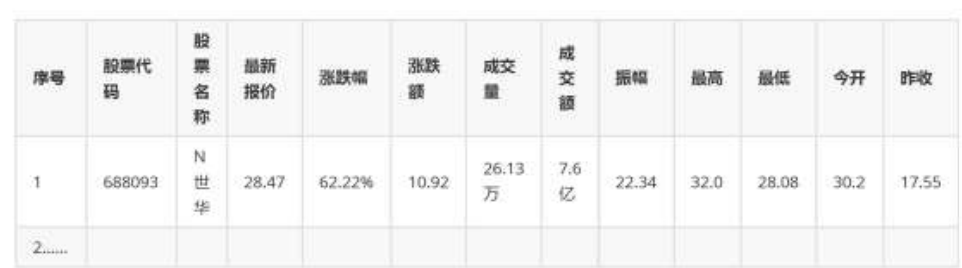
1)作业代码和图片
# _*_ coding : utf-8 _*_
# @Time : 16:35
# @Author : yoyo
# @File : task2
# @Project : pythonProject
import urllib.request
from bs4 import BeautifulSoup
import re
headers={"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
url = "https://54.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112405164563266376507_1728983460925&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1728983460926"
try:
html = urllib.request.urlopen(url)
html = html.read()
html = html.decode()
soup = BeautifulSoup(html, "html.parser")
# print(soup)
regs = ["f2", "f3", "f4", "f5", "f6", "f7", "f15", "f16", "f17", "f18", "f10", "f8", "f9", "f23"]
all = []
count = 0
for reg in regs:
reg_ = f'"{reg}":(.*?),'
match = re.findall(reg_, html)
all.append(match)
# print(match_f2)
print("最新价\t涨跌幅\t涨跌额\t成交价(手)\t成交额\t振幅\t最高\t最低\t今开\t昨收\t量比\t换手率\t市盈率\t市净率")
for i in range(len(all)):
for j in range(len(regs)):
print(all[j][i], end="\t")
print()
except Exception as err:
print(err)

2)作业心得
1、使用了urllib.request库来发送网络请求,获取网页内容。
使用BeautifulSoup库来解析HTML内容,尽管在这个例子中HTML内容实际上是JSON格式的字符串。
2、通过正则表达式(re.findall)从JSON格式的字符串中提取特定字段的数据。
3、从返回的数据中提取了多个字段,包括股票价格、涨跌幅等,并按照一定的格式打印出来。
4、使用try-except块来捕获和处理可能出现的异常,如网络请求失败、数据解析错误等。
异常处理是编写健壮代码的重要部分,能够确保程序在遇到错误时不会崩溃,并能给出有用的错误信息。
5、代码直接对返回的HTML内容(实际上是JSON)使用正则表达式进行解析,这不是最佳实践。更好的方法是使用JSON解析库(如json模块)来解析JSON数据。
6、打印输出时,没有考虑到数据可能不完整或格式不一致的情况,这在实际应用中可能会导致输出错误或格式混乱。
三、作业③
要求:爬取中国大学 2021 主榜 (https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器 F12 调试分析的过程录制 Gif 加 入至博客中。
技巧:分析该网站的发包情况,分析获取数据的 api
输出信息:
Gitee 文件夹链接👉 实验二/大学数据库.db · 诗悦/2022级数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
代码👉实验二/task3.py · 诗悦/2022级数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
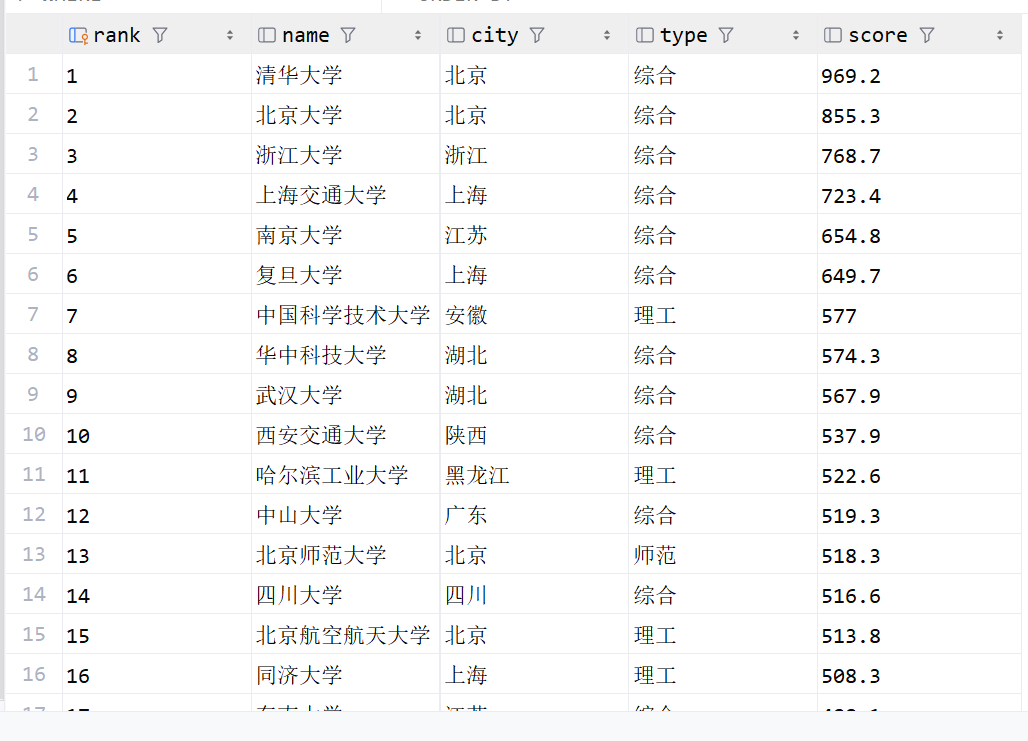
| 排名 | 学校 | 省市 | 类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 969.2 |
1)作业代码和图片
# _*_ coding : utf-8 _*_
# @Time : 16:35
# @Author : yoyo
# @File : task3
# @Project : pythonProject
import requests
import re
import sqlite3
conn = sqlite3.connect('大学数据库.db')
# 创建一个游标对象
cursor = conn.cursor()
# 创建一个表
cursor.execute('''
CREATE TABLE IF NOT EXISTS uni (
rank varchar(10) primary key,
name varchar(50),
city varchar(50),
type varchar(50),
score varchar(50)
)
''')
url = "https://www.shanghairanking.cn/_nuxt/static/1728872418/rankings/bcur/202111/payload.js"
try:
res = requests.get(url)
text= res.text
name = re.findall(',univNameCn:"(.*?)",', text)
score = re.findall(',score:(.*?),', text)
category = re.findall(',univCategory:(.*?),', text)
province = re.findall(',province:(.*?),', text)
print(province)
code_name = re.findall('function(.*?){', text)
start_code = code_name[0].find('a')
# print(code_name)
# print(start_code)
end_code = code_name[0].find('pE')
code_name = code_name[0][start_code:end_code].split(',')
print(code_name)
value_name = re.findall('mutations:(.*?);', text)
# print(value_name)
start_value = value_name[0].find('(')
end_value = value_name[0].find(')')
value_name = value_name[0][start_value + 1:end_value].split(",")
print(value_name)
universities = []
for i in range(len(name)):
province_name = value_name[code_name.index(province[i])][1:-1]
print(value_name[code_name.index(province[i])][1:-1])
category_name = value_name[code_name.index(category[i])][1:-1]
universities.append((i + 1, name[i], province_name, category_name, score[i]))
for uni in universities:
cursor.execute("insert into uni(rank, name, city, type, score) values (?, ?, ?, ?, ?)", (uni[0], uni[1], uni[2], uni[3], uni[4]))
conn.commit()
conn.close()
except Exception as err:
print(err)
2)F12 调试分析的过程录制 Gif

3)作业心得
1、使用requests库发送HTTP请求,从指定的URL获取数据。
2、代码大量使用了re.findall函数,通过正则表达式从返回的文本数据中提取所需的信息,如大学名称、分数、类别和省份等。
3、使用sqlite3库创建并操作SQLite数据库,将数据存储在本地数据库中。
在创建表时,指定了字段的数据类型和长度,确保了数据的规范性和一致性。
通过执行SQL插入语句,将解析后的数据插入到数据库中,方便后续的数据查询和分析。
4、使用try-except块来捕获和处理可能出现的异常,如网络请求失败、数据解析错误等。
异常处理是编写健壮代码的重要部分,能够确保程序在遇到错误时不会崩溃,并能给出有用的错误信息。
5、代码直接对返回的JavaScript代码文本使用正则表达式进行解析,这不是最佳实践。更好的方法是使用JSON解析库(如json模块)来解析JSON格式的数据(如果数据是以JSON格式返回的)。
6、数据库操作(如插入数据)没有使用事务管理,这可能会导致数据的不一致性。在实际应用中,应该使用事务来确保数据的完整性和一致性。
7、代码中没有对数据库连接进行异常处理,如连接失败或查询错误等。在实际应用中,应该对这些异常进行处理,以避免程序崩溃或数据损坏。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号