数据采集与融合技术作业一
码云仓库👉https://gitee.com/poetry-joy/crawl_project
作业链接👉https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology/homework/13286
注:代码块可滑动
在下052205144张诗悦
一、作业①⛵
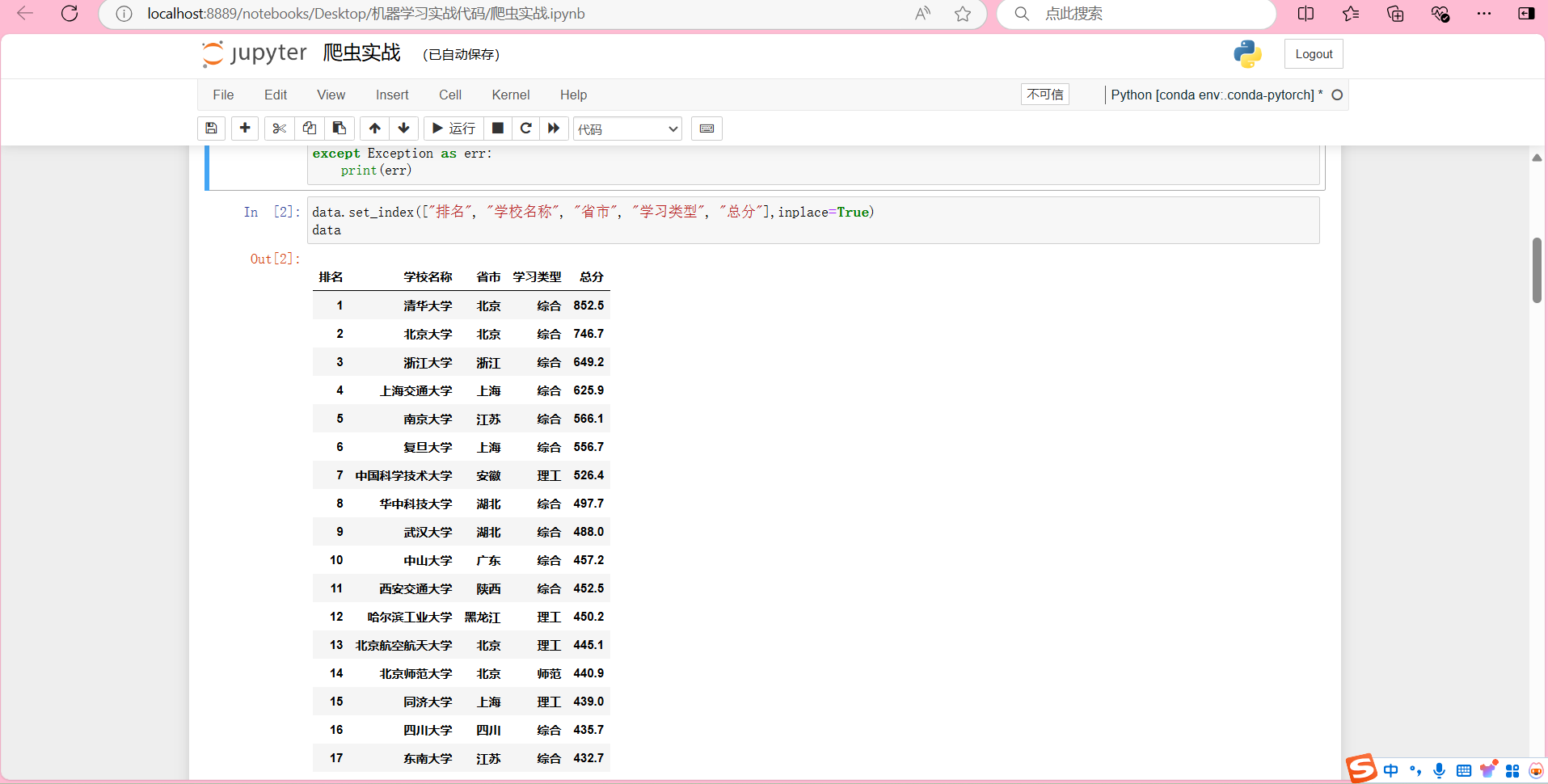
作业要求:用requests和BeautifulSoup库方法定向爬取给定网址 http://www.shanghairanking.cn/rankings/bcur/2020 的数据,屏幕打印爬取的大学排名信息。
输出信息:
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2...... |
1)作业代码和图片
import urllib.request
from bs4 import BeautifulSoup
import pandas as pd
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
try:
html = urllib.request.urlopen(url)
html = html.read()
html = html.decode()
soup = BeautifulSoup(html, "html.parser")
tags1 = soup.find_all("span", {"class": "name-cn"})
tags2 = soup.find_all("td", {"class": ""})
mylist1=[]
mylist2=[]
for tagy in tags2:
mylist1.append(tagy.text.strip())
def split_list_by_size(lst, size):
return [lst[i:i + size] for i in range(0, len(lst), size)]
mylist1 = split_list_by_size(mylist1, 5)
# print(mylist1)
for tagx in tags1:
mylist2.append(tagx.text.strip())
# print(mylist2)
for i in range(len(mylist1)):
mylist1[i].insert(1, mylist2[i])
mylist1[i] = mylist1[i][:-1]
# 将数据转换为DataFrame
data = pd.DataFrame(mylist1,columns=["排名", "学校名称", "省市", "学习类型", "总分"])
pd.set_option('display.width', None)
print(data.to_string(index=False))
data
except Exception as err:
print(err)
2)作业心得
1、使用urllib.request.urlopen从指定URL获取网页数据
2、利用BeautifulSoup库解析HTML内容,通过查找特定标签和类名提取所需数据
3、对数据进行清洗和重组,以及数据分析。
4、使用pandas库的DataFrame结构来存储和处理表格数据,提高了数据的可读性和操作的便捷性。
5、通过try-except结构捕获并打印异常,增强了代码的健壮性和用户体验。
二、作业 ②🐟
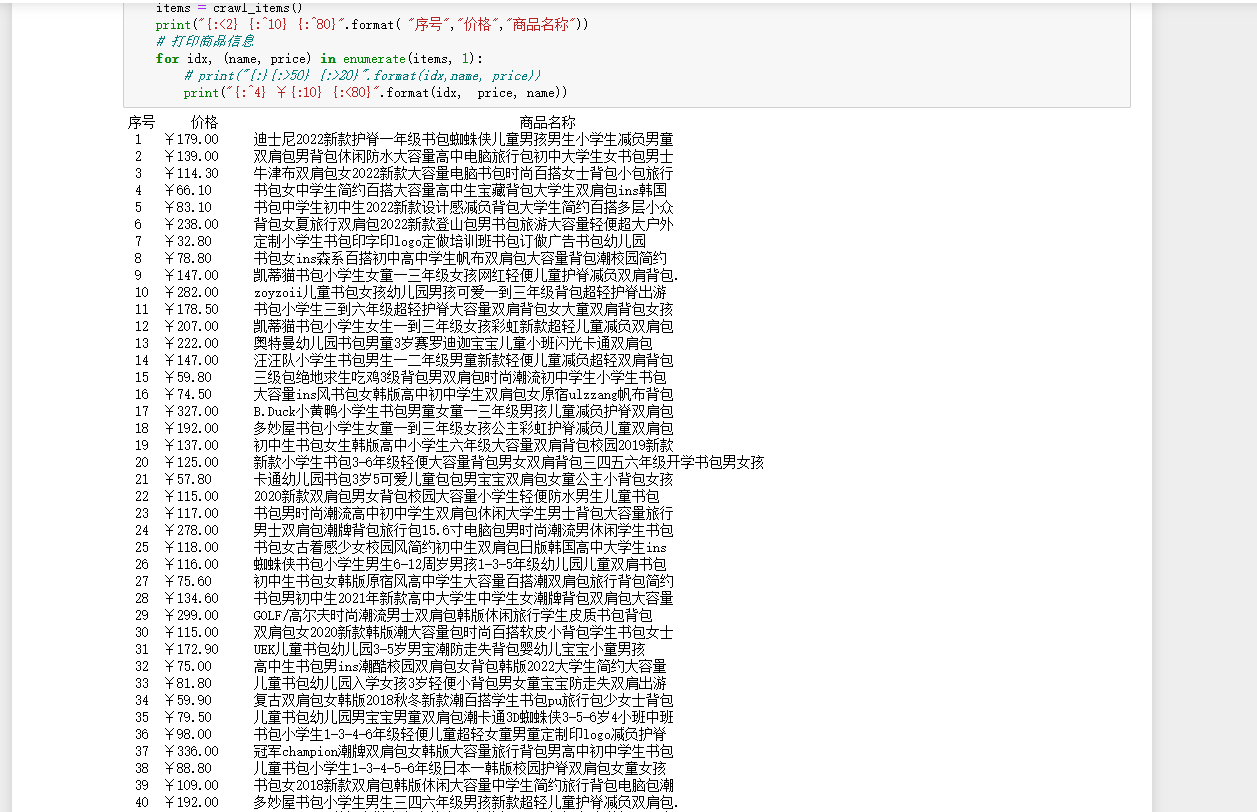
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
输出信息:
| 序号 | 价格 | 商品名 |
|---|---|---|
| 1 | 65.00 | xxx |
| 2...... |
1)作业代码和图片
# _*_ coding : utf-8 _*_
# @Time : 16:33
# @Author : yoyo
# @File : task2
# @Project : pythonProject
import urllib3
import chardet
import re
import urllib.parse
# 定义常量
base_url = "https://search.dangdang.com/" # 当当网搜索接口的URL
search_keyword = "%CA%E9%B0%FC" # 搜索关键词
# print(search_keyword)
max_items = 80 # 爬取商品的最大数量
headers={"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
# 创建 urllib3.PoolManager 实例
http = urllib3.PoolManager()
def fetch_page_data(page_num):
"""爬取当当网某页的商品数据"""
# 构造请求URL,加入页码参数
url = f"{base_url}?key={search_keyword}&act=input&page_index={page_num}" # 控制起始位置(48个商品每页)
# 发送GET请求
try:
response = http.request('GET', url, headers=headers)
if response.status != 200:
print(f"请求失败,状态码:{response.status}")
return None
# 获取响应的内容并解码
detected_encoding = chardet.detect(response.data)['encoding']
page_content = response.data.decode(detected_encoding)
return page_content
except Exception as e:
print(f"请求出错:{e}")
return None
def parse_items_from_page(page_content):
"""使用正则表达式解析页面中的商品名称和价格"""
# 使用正则表达式提取商品名称和价格
item_name_pattern = r'<p class="name"[^>]*><a[^>]*>(.*?)</a></p>'
price_pattern = r'<span class="price_n">([^<]+)</span>'
# 查找所有商品名称和价格
item_names = re.findall(item_name_pattern, page_content)
product_names = []
for match in item_names:
clean_name = re.sub(r'<.*?>', '', match).strip()
product_names.append(clean_name)
prices = re.findall(price_pattern, page_content)
product_prices = []
for match in prices:
clean_price = re.sub(r'¥', '', match).strip() # 去掉¥
product_prices.append(clean_price)
# print(product_prices)
# 组装商品信息
items = list(zip(product_names, product_prices))
return items
def crawl_items():
"""爬取当当网商品,限制最多爬取max_items数量"""
all_items = []
page_num = 0
while len(all_items) < max_items:
# 获取当前页的数据
page_content = fetch_page_data(page_num)
# print(page_content)
if not page_content:
break
# 解析商品信息
items = parse_items_from_page(page_content)
# print(items)
# 添加商品到总列表中
all_items.extend(items)
# 如果已达到爬取的最大数量,则退出
if len(all_items) >= max_items:
all_items = all_items[:max_items] # 截取前max_items项
break
# 翻页
page_num += 1
return all_items
# 执行爬虫并打印结果
if __name__ == "__main__":
items = crawl_items()
print("{:^80} {:>30}".format("商品名称", "价格"))
# 打印商品信息
for idx, (name, price) in enumerate(items, 1):
# print("{:}{:>50} {:>20}".format(idx,name, price))
print("{:<1} {:<80} ¥{:<10}".format(idx, name, price))
2)作业心得
1、在发送HTTP请求和解析页面内容时,代码使用了try-except结构来捕获并处理可能出现的异常,增强了代码的健壮性。
2、使用chardet库自动检测页面内容的编码,并据此进行解码,避免了因编码问题导致的乱码现象。
3、正则表达式:通过正则表达式提取页面中的商品名称和价格信息
4、通过循环和页码参数实现了翻页功能,能够连续爬取多页的数据,直到达到预设的最大商品数量。
5、在HTTP请求中设置了用户代理(User-Agent),用于模拟真实用户的浏览行为,避免被服务器拒绝服务。
6、format()函数的应用,最终输出的商品信息被格式化为整齐的表格,提高了结果的可读性。
三、作业③🦐
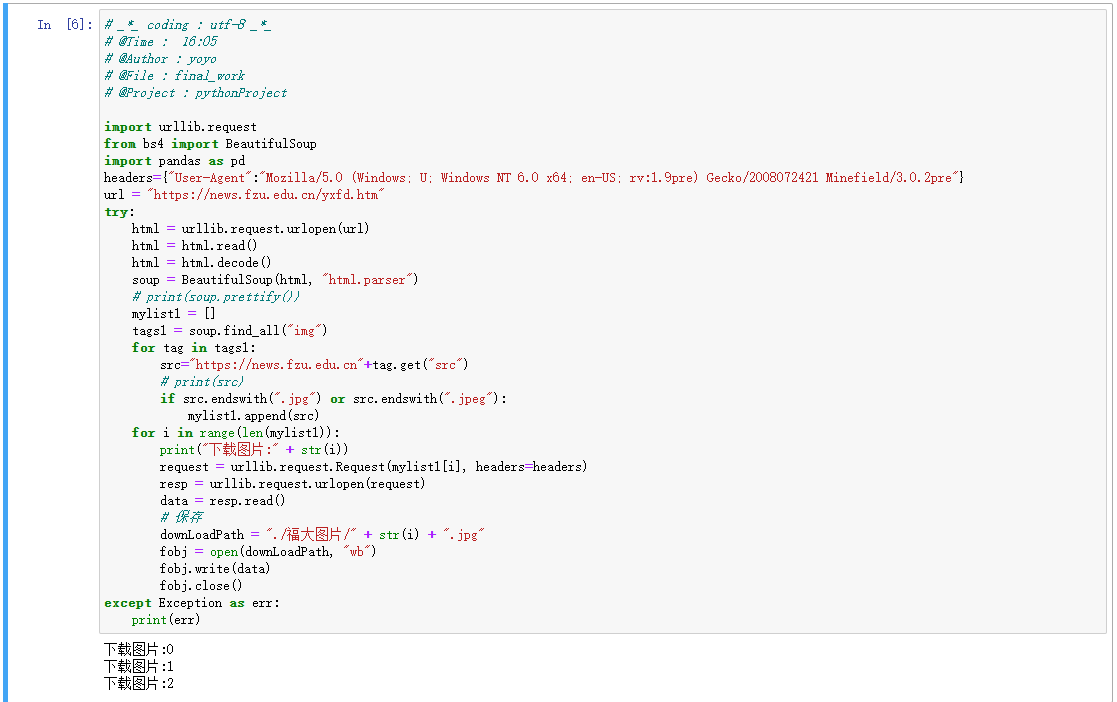
要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)或者自选网页的所有JPEG和JPG格式文件
输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
1)作业代码和图片
# _*_ coding : utf-8 _*_
# @Time : 16:34
# @Author : yoyo
# @File : task3
# @Project : pythonProject
# _*_ coding : utf-8 _*_
import urllib.request
from bs4 import BeautifulSoup
import pandas as pd
headers={"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
url = "https://news.fzu.edu.cn/yxfd.htm"
try:
html = urllib.request.urlopen(url)
html = html.read()
html = html.decode()
soup = BeautifulSoup(html, "html.parser")
# print(soup.prettify())
mylist1 = []
tags1 = soup.find_all("img")
for tag in tags1:
src="https://news.fzu.edu.cn"+tag.get("src")
# print(src)
if src.endswith(".jpg") or src.endswith(".jpeg"):
mylist1.append(src)
for i in range(len(mylist1)):
print("下载图片:" + str(i))
request = urllib.request.Request(mylist1[i], headers=headers)
resp = urllib.request.urlopen(request)
data = resp.read()
# 保存
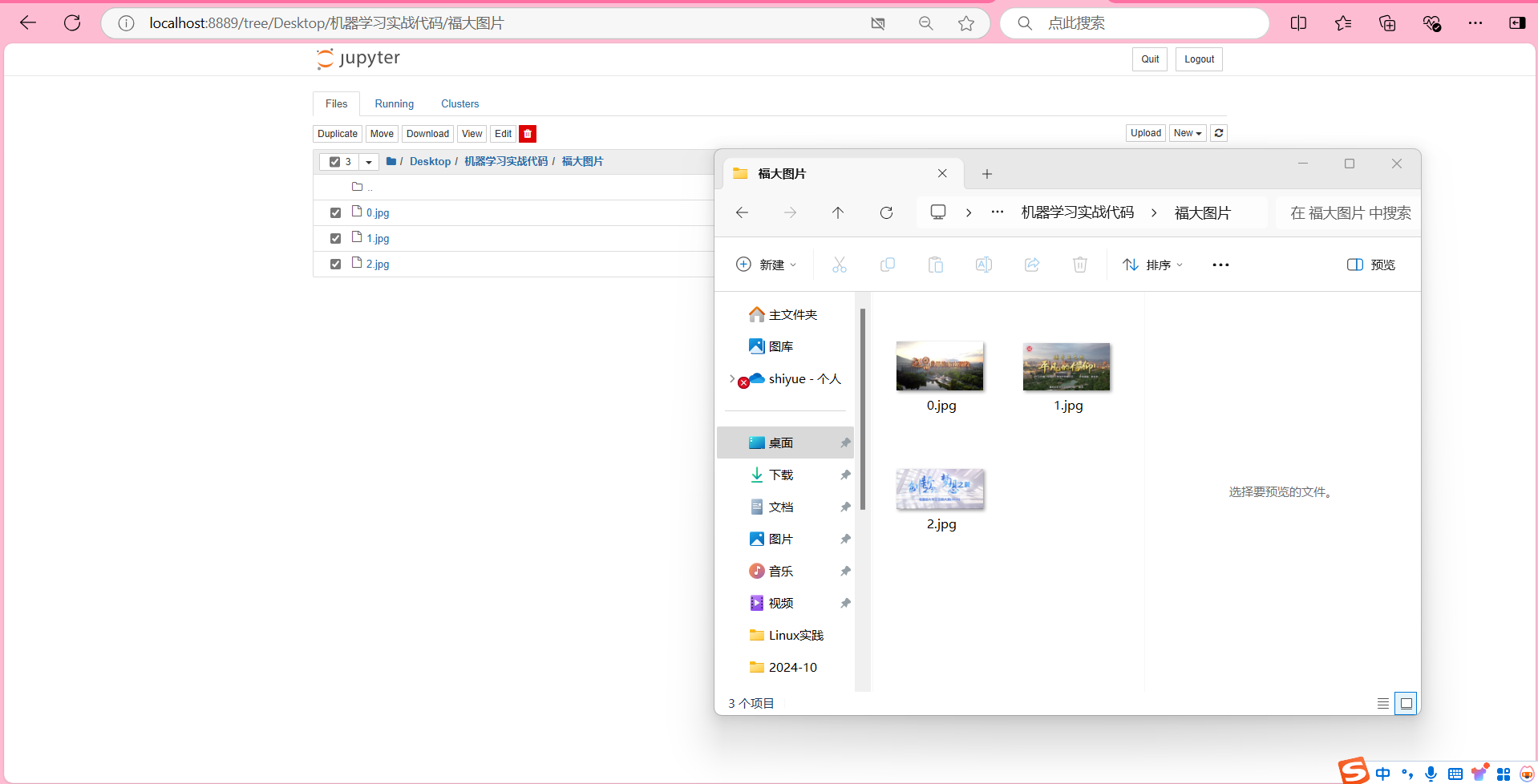
downLoadPath = "./福大图片/" + str(i) + ".jpg"
fobj = open(downLoadPath, "wb")
fobj.write(data)
fobj.close()
except Exception as err:
print(err)
2)作业心得
1、代码有效地利用了urllib.request进行网页请求和图片下载,BeautifulSoup进行HTML解析,以及pandas(尽管在此代码中未直接使用,但可能是为后续数据处理准备的)。这些库是Python爬虫和数据处理的常用工具。
2、通过try-except结构,代码能够捕获并处理在执行过程中可能出现的异常,如网络请求失败、文件写入错误等,提高了程序的健壮性。
3、代码通过查找HTML中的所有<img>标签,并检查其src属性是否以.jpg或.jpeg结尾来筛选图片。然后,它逐个下载这些图片,并保存到本地指定目录中。
4、在发送图片下载请求时,设置了用户代理(User-Agent),这有助于模拟真实用户的浏览行为,可能避免被某些服务器拒绝服务。
5、在保存图片时,代码构建了完整的文件路径,并确保了文件名的唯一性(通过索引号)。


