

midterm_review
图灵机
图灵机的语法
图灵机的原始描述如下:
-
一台含有一条1无限长的纸带的有限状态自动机 (FSM, Finite State Machine)。
-
纸带从最左端2开始向右无限延伸。纸带被分割为单元,每个单元上有一个字符或空字符 。纸带拥有一个读写头,指向纸带的某个单元,自动机每次转移时可向左或右移动读写头一个3单元,已经处于最左侧时向左移动将什么都不会发生4。
-
最开始,输入串 写在纸带的前 个单元里5,其他单元均为空字符。自动机在一个特殊的开始状态,正如 DFA 那样。读写头在最左侧6。
-
自动机每次读取读写头所在单元的符号,根据当前所在的自动机状态和这个符号,在同位置7覆盖写某个符号,转移到另一个自动机状态,并将读写头向左或向右移动。
-
有两种特殊的自动机状态 和 ,每种各一个8,一旦走到,图灵机停机 (halt)。
上标表示这些地方的描述可以有等价的变种,因此看起来描述得十分随意。
形式化的定义如下。
|
图灵机的定义(语法部分) 一个图灵机是一个七元组 ,其中
|
需要注意的是,根据定义,图灵机是可数无穷多的。我们可以将其与 一一对应,记作 ,在许多时候,通常具体如何映射是不重要的。
图灵机的语义
|
定义 图灵机一个配置 (configuration) 包含了自动机状态、纸带内容、读写头位置,写作 |
e.g.
|
图灵机的定义(语义部分)
其中 是两个字符串,表示左边和右边那些没有被改动的字符。 称所有 的配置为停机配置。 对于输入字符集 上的图灵机 ,其语言定义为 其中 的过程可以描述为:存在配置 ,使得
|
对于一个字符串 ,如果 ,则图灵机一定会在 上停机。但 时,图灵机要么在 上停机,要么不停机(永远循环下去)。
也就是说,除非能够证明其一定停机,我们无法通过将 送入图灵机,等待其输出结果来得知其是否属于 。这与一个 parser,比如 DFA 或者 DPDA 的行为不一致。
对于那些总是会停机的图灵机 ,我们称 ,这样的语言是可判定的 (decidable),称为递归 (recursive) 语言。
否则称 ,这样的语言是可识别 (recognizable) 的,称为递归可枚举 (recursively enumerable) 语言。
“递归”一词是说其与一般递归函数的能力等价,后文会证明这一点。“递归可枚举”是说我们可以通过某种方式枚举语言中所有的字符串,后文也会提到这一点。
如果 是 recognizable 的,则称 是 co-recongnizable 的,也就是,对 来说, 总是能停机,而 和不停机无法区分。
是 decidable 的当且仅当 是 recognizable 且 co-recognizable 的。
需要注意的是,这里我们只能在抽象层面来描述两种语言的区别,如果我们能用操作性的语言直接地描述这两种语言的区别(比如操作性地给出一个不是可判定的语言,如之前的 之于正规语言那样),那就违背可计算性理论的基本论题,即丘奇-图灵论题。
图灵机的变种
图灵机有许多等价变种。这些变种都是在原先图灵机的原始定义上增加一些操作的便捷性。但这些便捷性并不会增强图灵机的能力。图灵机也不可能通过仅仅是语法学上的努力增强能力。
由于我们考虑的是可计算性,而不是计算复杂性,使用原始图灵机对这些图灵机变种的模拟并不需要高效,有些时候我们甚至不知道是否存在一种高效的模拟(e.g. )。
多带图灵机
多带图灵机拥有 条纸带。转移函数的定义变为
其中 是为方便引入的记号,表示不移动读写头,这可以通过修改 FSM 的状态做到。
使用原始图灵机可以按照如下方式模拟多带图灵机:
- 从左向右顺序地写下每一条纸带上的内容,用一个特殊字符 # 分隔。
- 当多带图灵机的某条纸带向右扩展其长度时(即覆盖某个 时),原图灵机的读写头指向了一个 #,此时命令其走到 FSM 的一个特殊子模组上,将右侧的所有内容向右移一位。
- 为了记录每条纸带的位置信息,将纸带字符集 扩充为 ,第二维的 表示读写头正在这个位置上。每两个 # 之间有且仅有一个状态的第二维是 。
- 模拟时,从左向右读那些第二维状态为 的位置,将他们写到一个特殊的纸带位置上,比如最左侧,对当前读到第几个纸带可以使用 FSM 的状态记忆。读取到全部内容之后,做出决策并修改纸带。
非确定性图灵机 (NTM, Nondeterministic TM)
同 NFA 之于 DFA 一样,NTM 将其转移的输出改为了原来的幂集。
NTM 接受一个串的过程与 TM 一致,只需要修改生成过程为
- 如果 那么 生成 。
- 如果 那么 生成 。
也即,NTM 接受 当且仅当以 作为纸带的输入,存在一条在 上停机的合法路径。
此时, 当且仅当其所有分支都会停机。也即,对那些 , 以 为输入时,所有分支都到达了 。
我们可以使用 条纸带的图灵机模拟一个 NTM。
我们尝试枚举每一种输入。由于我们要支持仅仅是 recognizable 的语言,DFS 是不可取的,因为停机的实例可能会有不停机的分支。
我们将纸带 作为只读的,用于保留原始输入,纸带 用于模拟 DTM,纸带 记录所有做过的决策。我们按照字典序枚举决策,将其写入纸带 。注意字典序是优先按照长度从小往大排序的。确定了决策之后,将输入从纸带 拷贝到纸带 上,用纸带 模拟。如果每个决策都合法,且最终恰好走到了 ,返回 。按字典序枚举决策可以通过由当前决策的编码推导出下一个决策的编码来实现。
需要注意的是,在一个 NTM 中,即使有一部分转移不存在 nondeterministic 的情况,这些状态和转移也可能可以造成无限循环,因此枚举决策需要在所有的步骤都进行,即使某些步骤是 deterministic 的。
另一个需要注意的点是,这种模拟的模式所有的负例都是不停机的。如果 NTM ,我们称 是一个 decider。如果想要模拟一个 decider,使得那些负例也总是停机,那我们需要不再枚举那些某个前缀已经走到了 或 的决策。决策的枚举过程会在我们发现对某个 ,长度不小于 的所有的决策都被停机状态覆盖了时停止。
枚举器 (Enumerator)
一个枚举器是一个具有只写的纸带,即“打印机”的图灵机。
为什么被图灵机识别的语言被称为递归可枚举语言?这是因为一个语言是递归可枚举语言当且仅当我们可以用一个枚举器枚举出其所有字符串并依次打印在只写纸带上(或许有重复)。
考虑这样的过程
- 将合法的输入与自然数一一对应。
- 对
- 对
- 将 作为 的输入,运行 步。
- 如果 ,输出 。
- 对
不难看出,每一个 的字符串都会被输出至少一次。
通用图灵机
通用图灵机是这样一个图灵机,输入 ,其中 是一个图灵机(需要先进行编码),其运行结果与 在 上运行的结果一致。
我们可以用 条纸带的图灵机来模拟通用图灵机,纸带 只读,提供 的信息,纸带 模拟 的纸带,纸带 记录当前在 FSM 的哪个状态。
丘奇-图灵论题
“论题” (thesis) 是说那些有些模糊,无法被形式化地声明或者验证的,但是对工作有益的猜想。
丘奇-图灵论题首先基于对可计算性的形式化描述的等价性。
- (Gödel, Herbrand, 1933) 一般递归函数。
- (Church, 1936) -演算。
- (Turing, 1936) 图灵机。
这三份工作,都想要使用严格的数学语言刻画所有可计算的过程,而它们被严格证明是等价的。
定理 一个函数是 -可计算的当且仅当其是图灵可计算的,也当且仅当其是一般递归的。
之后,他们讨论了不依赖于数学定义的,作为直觉或概念上的可计算性,即能行可计算 (effective computability). 能行方法 (effective method) 的描述如下:“其每一步骤都是精确预定的,并且一定会在有限的步骤中产生答案”。
这个定理给予了当时的人一种信心,于是他们断言,
丘奇-图灵论题 (Church-Turing thesis) 能行可计算与图灵可计算一致。
也就是说,这是一种公认的信念,认为这三种等价的形式化描述准确地描绘 (characterize) 了可计算性的理念或者本性 (nature)。
这件事在图灵机上更容易被看出,图灵在其原论文中也做了一些解释。对于计算机还没有诞生的三十年代,当我们想要描述一个可操作的计算过程时,可以使用的工具是纸和笔。纸和笔对应着纸带,而操作者此时的“心灵”对应着有限自动机,这是因为当操作者严格遵循一个形式化的过程时,其下一步的操作总是取决于他目前的心灵状态与纸带上的内容,而心灵状态是有限的。可计算的函数无外乎可用纸和笔与大脑完成的计算,而其形式化后就是图灵机。
有了这种信念,我们可以直接用自然语言描述一系列操作,它一定是图灵可计算的,也一定是一般递归的。
不可判定问题
我们开始学习那些不可判定问题与对应的递归可枚举语言。
丘奇-图灵论题解释了为什么我们无法通过显式的描述来刻画可计算性的边界(如 之于正规语言, 之于上下文无关语言),因为这样的描述是通过其操作来给出其定义的,因此必然是能行可计算的,也必然会包含在图灵机的能力之中。
不过我们可以用对角线证明的方法构造出
命题
是不可判定的。
|
证明 图灵机是可数无穷多的,因此存在这样一张二维表格,每一行表示一个图灵机,每一列表示一种输入,每一个格子有三种可能 。 构造图灵机 ,使得其在第 种输入中与第 行第 列的输出恰好相反,即当第 行第 列是 时, 输出 ,其他情况输出 。 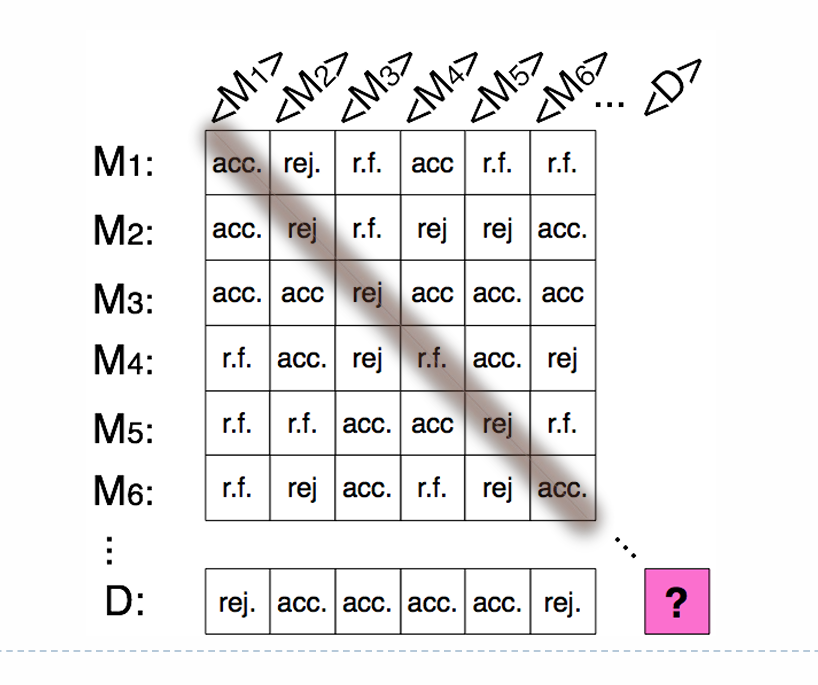
若 是可判定的,则 也是。假设 在表格的第 行,则第 行第 列既是 又是 ,矛盾。 因此这样的 不能存在,也即, 是不可判定的, 一定会在某一行不停机。 |
虽然 是不可判定的,但是根据其定义,其是可识别的,因此 是不可识别的,即
是不可识别的。现在考虑 。如果 是可判定的,那么 也是可判定的。考虑函数
G(<M, w>) { if H(<M, w>) rejects then reject. else return M(<w>). }
也即,如果我总是能区分 和 ,则所有可识别的语言都是可判定的,故 (在图灵归约下),事实上也有 。
两种可归约性
我们已经见到了一个归约的例子,即“如果 是可判定的则 也是”,也就是说, 是不难于 的问题,即使两者都不在 effective computability 的范畴中。
图灵可归约性
我们可以使用 oracle TM 来避开可计算性的壁垒。这与 NPC 归约是相当类似的。而在这里,归约过程要求是可计算的。
|
定义 如果存在 oracle TM ,则称语言 可以图灵归约 (Turing reducible) 到 ,记作 。 |
。
同证明一个问题是 NPC 的过程,如果我们想要证明一个语言是不可判定的,只用将一个已知是不可判定的语言图灵归约到它上即可。
命题 是不可判定的。
|
证明 考虑函数 如果 则 ,因此存在 ,从而说明 是不可判定的。 推论 是不可判定的。 |
命题 是不可判定的。
|
证明 考虑函数 如果 ,,不是正规的。否则 ,是正规的。因此 。 |
看完上述两个归约,我们不难发现,对于随意一个关于 的性质,我们都可以通过先模拟 ,根据其结果构造一对正例与反例,来把 归约到它。这个动机可以一般化为
定理 (Rice's Theorem) 递归可枚举语言的任何非平凡的性质,都是不可判定的。即,令 为一类递归可枚举语言的集合,则 是可判定的当且仅当 或 为所有的递归可枚举语言。
有一类比较常见的归约方式,通过模拟一个图灵机的纸带的历史记录来将 或类似的语言归约到它。
最经典的一例,叫做波斯特对应问题 (Post Correspondence Problem):有若干种纸片,每个纸片有两行,每行一个字符串,现在要求如果每种纸片有无限多个,是否存在一个有限的纸片序列,使得第一行的字符串拼接起来形成的长字符串等于第二行的。
命题
是不可判定的。
|
证明 考虑对图灵机 和输入 ,构造纸片集合 ,其中包括
后续会证明,不失一般性地,我们可以假设
我们从第一种纸片开始,此时第二行比第一行领先一个状态。对于一个合法的纸带序列,第一行总是会模仿第二行的行为,也即复制上一个状态,根据我们纸片的设计,第二行会生成下一个状态。 最终,第二行将会走到 ,使用 补齐第一行。 特殊标记可以通过在纸片上加特殊字符实现。对所有纸片,在字符串的每两个字符中间加入特殊字符 ,对有特殊标记的纸片,在两个字符串的头加入 ,但只在第二行的字符串的尾加入 ;其他的纸片只在第一行的字符串的头和第二行的字符串的尾加入 ,比如 改为 。同理,匹配时第二行会领先第一行一个 。最终我们再将 改为 即可。 |
命题
是不可判定的。
|
证明 考虑将 归约到 。如果 ,那就存在一个合法的计算历史,否则就不存在。因此我们可以构造一个 PDA 生成 在 上运行的所有不合法的计算历史,根据其是否在 中可以得到运行结果。 不合法的历史 有三种情况
前两种都是一次性的操作,可以通过有限状态机实现。 对于最后一种,我们知道 不是 CFL,因此 也大概会不是。所以我们需要反转后一半,将历史记录以 的方式记录。 假设 在栈中,我们将其与 比对,由于两者至多有常数个地方不同,可以通过有限状态机实现判断。 通过 Nondeterministic PDA 实现对每个 的枚举。 |
对于 CFG,有许多不可判定的问题,比如
- (Universality) 给定 CFG ,是否有 。
- (Equivalence) 给定 CFG ,是否有 。
- (Ambiguity) 给定 CFG ,是否有 无二义。
也有许多可判定的
- (Emptiness) 是否有 。
- (Finiteness) 是否有 有限。
- (Membership) 是否有 。
映射可归约性
|
定义 如果存在递归函数 使得对两种语言 ,,则称语言 可以映射归约 (mapping reducible) 到语言 。记作 。 |
如果 ,则有
- 若 是可判定的则 是可判定的。
- 若 是可识别的则 是可识别的。
需要注意的是,存在 使得 并不代表着 ,也即,映射可归约性对取补操作是敏感的,它不能做到类似于
accept, if the oracle reject. reject, if the oracle accept.
或者说,相比于图灵归约,映射归约要求了归约的最后一步一定是正向地调用 oracle B。因此图灵归约一般用于证明不可判定性,而映射归约一般用于证明不可识别性。
命题 令 ,则 和 均是不可识别的。
|
证明 这个任务类似于识别某个递归可枚举语言的性质,我们将 归约到 和 上。 考虑函数 这样我们把 的一个输入转化为了 (或 )的输入。
而我们已知 是不可识别的,因此 和 均是不可识别的。 |
递归定理
递归定理正向地刻画了可计算性的本性,它指出任何计算过程都无法逃脱“自我指涉”的魔咒。这是第三次数学危机所考虑的一个重点。
定理 对每个递归函数 ,存在图灵机 使得 与 对应的图灵机等价。
|
证明 考虑函数 令 ,则 符合条件。因为 而 ,因此两者均等价于 。 |
更紧凑的一种解释:
- 构造 使得 .
- 令 ,则有 。
- 令 ,则 符合条件。
不难看出关键点在于第一步的构造。这其实是一种对角化方法。我们构造一个 ,使其在第一种输入上和第一个图灵机一致,第二种输入上和第二个图灵机一致,以此类推。
与 不可判定的证明恰好相反,这样构造出来的 是一定在这个列表中的,因此就会有黄色的对角线与绿色的 逐列相同。因此对任意 ,都有 。
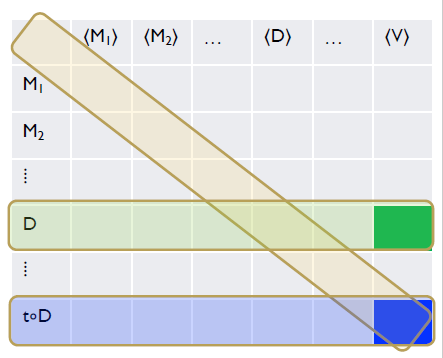
进一步地,我们可以说,在可数的情况中,指出系统内在的“自我指涉”性都可以通过讨论对角线上的元素(或取反后)构成的行是否也在这张表里。而每一行都和对角线必定有交,由此导出结论(或矛盾)。
定理 (Kleene 递归定理) 对每个递归函数 ,存在图灵机 使得对所有输入 ,
这是原递归定理的推论。这个定理指出,一个计算过程可以免费获得其自身的图灵机编号。通过
- 首先根据需求构造图灵机 ,使其接收一个图灵机 的编号(此时 与 无关)并在 和 上计算。
- 根据 Kleene 递归定理,存在图灵机 使得 ,因此 在 和 上,进行与 等价的计算。
也就是说,我们可以直接写出如下的代码
SELF(x): Obtain, via the recursion theorem, own description <SELF>; ...
因此对于任意图灵完备且可以输出的编程语言,都存在 quine 解。因为一个图灵完备的编程语言无非提供了一种源代码到图灵机的满射。
|
Kleene 递归定理的证明 考虑函数 根据递归定理,存在图灵机 使得 与 对应的图灵机等价,即 |
由于递归定理的内容与证明都涉及到了“自我指涉”性,它也可以用于相关问题的反证。
命题 是不可判定的。
|
证明 假设 ,考虑函数 则 ,矛盾。 |
命题 是不可判定的。
|
证明 如果 是可判定的,则存在枚举器 枚举所有的 。考虑函数 则 ,,矛盾。 |
如果我们把语言改为仅包含 个最小的这样的 ,则这个语言一定是可判定的,说明 ,而只有枚举器是在变化的,也就是说枚举器的编码增长速率不慢于 。这也说明不存在一个枚举 的枚举器。
Kolmogorov 复杂度
我们来把上面的最后一段话一般化。
|
定义 一个二进制字符串 的最小描述 定义为最短的字符串 ,满足 在 上停机并在纸带上留下 。 的 Kolmogorov 复杂度定义为最小描述的长度,。 |
对于所有的 ,有 ,其中 为不依赖于 的常数。这是因为我们总是可以令 , 为把输入直接输出的图灵机。
同理,。,因为只需要 的空间存储 。
从信息论出发,我们知道大部分的字符串是不可被压缩的。定义 是 -compressible 的如果 ,那么长度为 的字符串有 种,长度 的描述有 种,因此
是不可判定的。考虑函数
M(n): For all y in lexicographical order If (y, n) not in COMPRESS, print y and halt.
这样对所有 ,都有 ,矛盾。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!