

自底向上语法分析之 LR parser
原文发表于 。
自底向上(Bottom-Up)语法分析
定义 ,则称 为句型 相对于非终结符 的短语。
注意 句型:,句子:。
定义 改为 ,则为直接短语。
定义 直接短语的 改为 ,则为句柄。
不难发现,此时 一定是一个句子。
引理 对一个文法来说,被这个文法识别的某个句型的句柄不唯一当且仅当文法是二义的。
定义 在当前串中找到某个与产生式右部相匹配的子串,将其用左部替换。这个过程叫做归约。
经过若干次归约后,我们想要将输入串归约到开始符号 。
引理 一个句型可归约的子句型一定是其直接短语。
自底向上分析的实现技术:移进−归约(shift-reduce)分析技术。基本想法如下:
-
从左到右扫描,依次读入字符。
-
在合适的时候对当前的一个后缀进行归约。可知这样归约的一定是句柄,故得到的一定是一个最右推导。满足上两条的分析过程我们称为 分析(Left to right, Rightmost)。
-
通过一个仅根据文法(故可以预处理)确定的特殊下推自动机来决定操作。根据当前状态、栈顶元素和剩余单词序列有如下操作
-
Reduce 对栈顶的短语进行归约。
-
Shift 从输入中读入一个字符放入栈顶。
-
Error 报错。
-
Accept 成功。
-
常用的 分析技术有:,我们之后会证明他们在文法能力上的一些性质,从而说明他们中每一个存在的意义。
不难发现,我们的处理方式是简单与直接的,这要求我们的文法有一些限制。下面介绍在不同限制的文法中我们如何得到这张分析表。
文法
我们知道,我们想找到的实际上是每一个产生式的的句柄以及它们的归约关系。当我们完全匹配了一个句柄时立即归约,故其叫做 文法。(提前预告, 便是在匹配了句柄时再多加一些考虑再归约)
所以我们需要进行维护的,是句柄的每一个前缀的匹配状态,也即,目前匹配到了哪些句柄的哪些前缀。为此我们引入活前缀(viable prefix)的概念。
,则 的任何前缀 均为文法 的活前缀。
如果我们从反方向看,活前缀即,从 开始,每次仅展开一个非终结符,并把从这个位置开始的后缀全部删除,并保留之前的部分,这样递归若干轮。也就是说,由于每次只展开一个,这实际上是一个线性的而非嵌套的过程。从语法树上说,他和从根开始的一条链对应,内容便是这条链左边的并且是未被展开的东西。由此我们有
引理 活前缀的集合是正规语言。
Prove by construction. 为了构造能够识别活前缀的自动机,我们来模拟这个反过程。
称 项目表示在右侧某一位置添加一个圆点(某一种特殊字符)的产生式,表示已经分析过的串与该产生式匹配的位置。
如 就有项目 ,表示还没有匹配,,表示匹配了 ,,表示匹配了 , 表示匹配完成。
那么,我们一步一步匹配活前缀,有两种情况
-
匹配一个字符。它可能是终结符也可能不是。在语法树上体现为,将链向左挪。
-
展开一个字符。在语法树上体现为,向儿子深入一步。
当然,我们要意识到一点,第二种操作,由于不需要输入,所以可能在一轮执行若干次。也即我们要将所有展开的可能全部放到一个状态里。这个过程叫做闭包。
比如有以下文法:
那么, 都能够作为被接收的第一个字符。所以我们定义
定义 一个项目集合 的闭包 为以下操作生成的所有项目的集合
- 若 在集合中,则将所有的项目 加入集合,,重复这一条直至不再有新项目产生。
我们在每一次执行了第一种操作时就做一次闭包,这样就完成了第二种操作。
并且,如果是 文法,也即不向前查看字符的文法,我们可以发现一个项目与其闭包生成的项目是不可区分的,也即,执行多少次第二种操作是不可区分的。所以他们会在同一个状态里。
方便起见,在文法中新增一种非终结符 ,新增一条文法 ,其中 为字符串结束符号。将 视作起始符号,防止 在文法中多次出现造成循环。这样的文法叫做增广文法。
那么,DFA 有一个初态,表示 。在语法树上,表示根。
之后我们执行如下步骤,生成 DFA 的其他状态
- ,表示 DFA 的第 个状态接受符号 后转移到的状态,为 。
也就是说,如果两个项目是无法区分的,并且他们都要一个 ,那他们还是无法区分的。但是他们和那些不要 的区分开了。
我们不停地生成新的 ,直到不再生成了为止。除了表示空集合的那个状态,其他状态都是终态。这样我们就有了一个 DFA。
命题 该 DFA 的语言是所有活前缀。
我们在前面已经以直观的形式说明了,这个 DFA 相当于不断执行两种操作,而执行两种操作和活前缀是等价的。
老师的 ppt 里的例子:
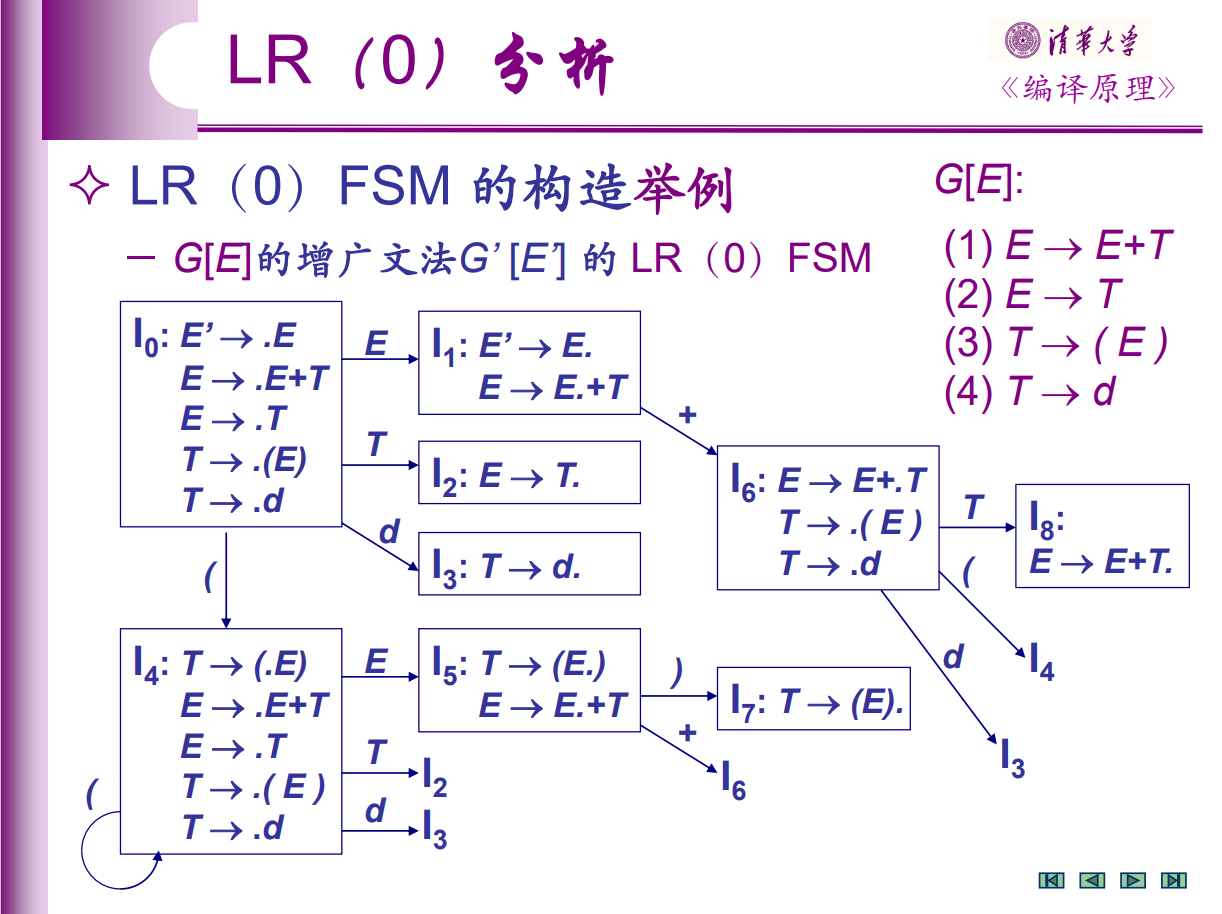
最后,关于这个自动机的状态数,很可惜,它是指数级的。Ukkonen 给出的一个例子是
这样,DFA 的状态有 个。
在实践中,正常语言的 DFA,增长速度也就 左右。
那么,我们回到最初的下推自动机那里。
-
Reduce 如果当前我们获得了一个句柄,那就立刻对栈顶的短语进行归约。此策略称作 ,也即不顾及后面的任何符号就做出判断,与 相对。后者顾及后 个字符再做出判断。之后,若我们使用了 归约,我们把在 DFA 上走的最后 步撤回,并再在 DFA 上走出 这一步。
-
Shift 否则,从输入中读入一个字符放入栈顶。
-
Error 一旦 DFA 走到了空状态,报错。
-
Accept 成功。
我们用一张 分析表来描述这个下推自动机。
分析表分为两部分, 表和 表。
,其中 为栈的状态数,也即 DFA 的状态数; 为字符, 为一个操作。 表示栈顶为状态 ,当前输入字符为 时的操作,若等于 ,表示将状态 移入栈顶,若等于 ,表示按文法第 条产生式归约,若等于 或 ,则表示分析结束。
。 表示归约了 后,我们将栈顶的 个状态弹出,如果目前栈顶元素为 ,就把新状态 放入栈顶。
也就是说, 描述了走终结符, 描述了走非终结符。(好蠢啊,为什么不放在一起,不过为了符号统一性不得不服从了)
当我们发现,一张表的一个位置会有两种填法时,这个文法不是 的。若是多个 冲突,则称其为归约−归约冲突,比如 。若是 和 冲突,则称为移进−归约冲突,比如经典的 。
文法
文法每当找到一个句柄时立即归约,而 多往前看一个字符,如果我们要归约 ,那么接下来的这个字符必须得是 里的元素才对。所以我们多加一个判断,即当且仅当接下来的一个字符是 中的,我们才用 进行归约。
文法
但问题是, 是对非终结符说的,而不是对句柄说的。两个句柄后面可以出现的符号可能不同,即使他们是从同一个非终结符那里推来的。所以 的工作方式有所不妥。我们应该对每一种状态计算其 “”。
具体的做法是,我们将每一个项目后面署上可以接受的 ,形如 。
闭包的计算修改为
- 若 在集合中,则将所有的项目 加入集合,其中 ,,重复这一条直至不再有新项目产生。
DFA 的状态与转移修改为
- ,为 。
初态为 ,其中 表示文本终结字符。
分析表修改为
-
Reduce 如果当前我们获得了一个句柄,并且当前的状态署上了向前看的字符,那就立刻对栈顶的短语进行归约。若我们使用了 归约,我们把在 DFA 上走的最后 步撤回,并再在 DFA 上走出 这一步。
-
Shift 否则,从输入中读入一个字符放入栈顶。
-
Error 一旦 DFA 走到了空状态,报错。
-
Accept 成功。
这样,我们就能避免许多可避免的冲突。我们接下来要说明,这样的做法并非简单的剪枝,而是极其有意义的。有三条重要的结论
-
一个语言的 文法的存在性与 (确定下推自动机)的存在性等价。满足存在 文法或 的语言称作确定上下文无关文法(Definite CFG)。
-
一个语言的 文法的存在性与 文法的存在性等价。(这一点不难猜出,因为二义文法 是怎么也无法解决的,所以)
-
任何 文法都是 文法。
这三条的证明,等我会了再说,之后会补上。(或许是期末后?
所以实际上, 是表示能力相当强的语言了,有许多编程语言都是 的(C++ 是著名的一个反例)。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!