
豆瓣评论9.5的《Effective Python》,帮你解决80%难题!
 《 Effective Python :编写高质量 Python 代码的 90 个有效方法》实战课程来喽!教你更好理解这本书!
《 Effective Python :编写高质量 Python 代码的 90 个有效方法》实战课程来喽!教你更好理解这本书!
上周五晚上 11 点,我在浏览蓝桥云课代码交流Q时,无意看到了一条这样的消息:“最近看到豆瓣推荐,正在看《 Effective Python :编写高质量 Python 代码的 90 个有效方法》,受益匪浅!但难度好大,理解也太费劲了!”
看到这条消息,我火速赶去豆瓣,吃下这波安利。豆瓣评分 9.5 分,真不愧是一本经典的 Pyhon 学习书籍!

但是,这本书是 Python 编程进阶必备手册,并不适合 Python 零基础小白。之前,我也说过很多次, Python 入门易,进阶难,这本书能让有一定 Python 基础的人更上一层。
蓝桥云课推出了这本书的课程——《 Effective Python :编写高质量 Python 代码的 90 个有效方法》,通过90个实验的方式,帮助你更好地理解这本书,并且提升使用 Python 代码的技能。(Tips:文末有超大福利礼包哦~)
01 查询自己使用的 Python 版本
很多电脑都预装了多个版本的标准 Cpython 运行时环境,然而,在命令行中输入 python 命令之后,系统究竟会执行哪个版本则是很难确定的。
在某些操作系统里面,python 通常是 python 2.7 的别名,但也有可能是 python 2.6 或 python 2.5 等旧版 python 的别名。
大家可以用 --version 标志运行 python 命令,准确找出所使用的具体 python 版本。
python --version
如果你要用的不是 python 2 而是 python 3,那么通常可以输入 python3 命令来启动。
python3 --version
运行结果如图所示:
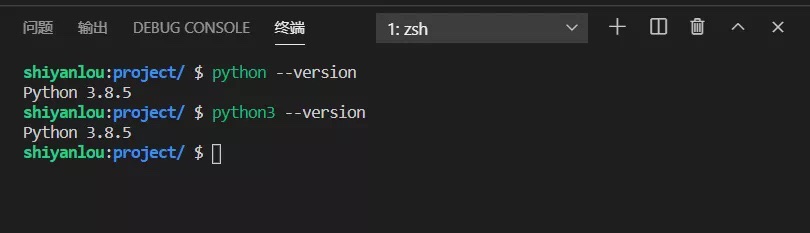
可以看出,当前实验环境 python 的默认版本是 python 3.8.5。
也可以通过 python 内置的 sys 模块查询相关的值确定当前使用的 python 版本。
import sysprint(sys.version_info)print(sys.version)
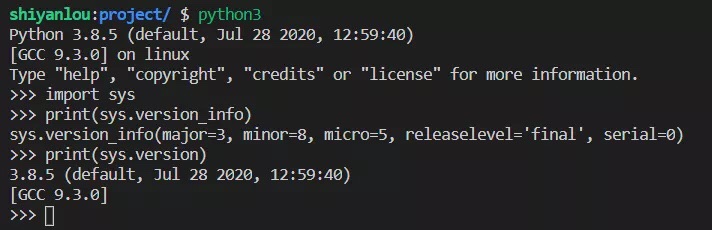
python 的核心开发者与广大用户都在积极地更新 python3,并不断地改进。
实验中会提到 python3 的许多新功能,这些功能都很强大。比较常见的 python 开源程序库都兼容 python3,并且通常都会把重点放在 python3。
我强烈推荐大家用 python3 来开发所有的项目,这里我给大家以下 3 点注意事项,在实验开始前一定要确认清楚:
python 3 是最新版的 python,而且受到了很好的支持,大家应该用 python 3 开发项目;
在操作系统的命令行界面运行 python 时,要确认该 python 的版本是否跟你要使用的版本相同;
不要再用 python 2 做开发了,因为该版本已于 2020 年 1 月 1 日停止更新维护。
02 遵循 PEP 8 风格指南
PEP 8 是一份针对 Python 代码格式而编订的风格指南。尽管只要语法正确,代码随便怎么写都行,但采用一致的风格可以使代码更易读、更易懂。
如果你的代码风格和其他 Python 程序员的相同,那么你就能够更加顺利地与大家一起做项目。即便你的代码只给自己看,也应该按照这套风格来写,以便以后修改更加容易一些,而且能够避开很多常见的错误。
PEP 8 非常详细地描述了如何编写清晰的 Python 代码,而且会随着 Python 语言的发展持续更新。所以,大家应该把完整指南阅读一遍(PEP 8)。
这几条规则你绝对应该遵循:
1.与空白有关的建议
在 Python 中,空白(whitespace)在语法上相当重要。Python 程序员对空白字符的用法尤其在意,因为它们会影响代码的清晰程度。
用空格(space)表示缩进,而不要用制表符(tab)。
和语法相关的每一层缩进都用 4 个空格表示。
每行不超过 79 个字符。
对于占据多行的长表达式来说,除了首行之外的其余各行都应该在通常的缩进级别之上再加 4 个空格。
在同一份文件中,函数与类之间用两个空行隔开。
在同一个类中,方法与方法之间用一个空行隔开。
使用字典(dict)时,键与冒号之间不加空格,写在同一行的冒号和值之间应该加一个空格。
给变量赋值时,赋值符号的左边和右边各加一个空格,并且只加一个空格就好。
给变量的类型做注解(annotation)时,不要把变量名和冒号隔开,但在类型信息前应该有一个空格。
2.与命名有关的建议
PEP 8 建议采用不同的方式来给 Python 代码中的各个部分命名,这样在阅读代码时, 就可以根据这些名称看出它们在 Python 语言中的角色。
函数、变量及属性用小写字母来拼写,各单词之间用下划线相连,例如:lowercase_underscore 。
受保护的实例属性,用一个下划线开头,例如:_leading_underscore 。
私有的实例属性,用两个下划线开头,例如: __double_leading_underscore 。
类(包括异常)命名时,每个单词的首字母均大写,例如: CapitalizedWord 。
模块级别的常量,所有字母都大写,各单词之间用下划线相连,例如:ALL_CAPS 。
类中的实例方法,应该把第一个参数命名为 self,用来表示该对象本身。
类方法的第一个参数,应该命名为cls,用来表示这个类本身。
3.与表达式和语句有关的建议
The Zen of Python 中提到:“每件事都应该有简单的做法,而且最好只有一种。”PEP 8 就试着运用这个理念,来规范表达式和语句的写法。
采用行内否定即把否定词直接写在要否定的内容前面,而不要放在整个表达式的前面,例如应该写 if a is not b,而不是 if not a is b 。
不要通过长度判断容器或序列是不是空的,例如不要通过 if len(somelist) == 0 判断 somelist 是否为 [] 或 '' 等空值,而是应该采用 if not somelist 这样的写法来判断,因为 Python 会把空值自动评估为 False 。
如果要判断容器或序列里面有没有内容(比如要判断 somelist 是否为 [1] 或 'hi ' 这样非空的值),也不应该通过长度来判断,而是应该采用 if somelist 语句,因为 Python 会把非空的值自动判定为 True 。
不要把 if 语句、for 循环、while 循环及 except 复合语句挤在一行。应该把这些语句分成多行来写,这样更加清晰。
如果表达式一行写不下,可以用括号将其括起来,而且要适当地添加换行与缩进,以便于阅读。
多行的表达式,应该用括号括起来,而不要用 \ 符号续行。
4.与引入有关的建议
import 语句(含 from x import y)总是应该放在文件开头。
引入模块时,总是应该使用绝对名称,而不应该根据当前模块路径而使用相对名称。例如,要引入 bar 包中的 foo 模块,应该完整地写出 from bar import foo, 即便当前路径为 bar 包里,也不应该简写为 import foo 。
如果一定要用相对名称来编写 import 语句,那就应该明确地写成:from . import foo 。
文件中的 import 语句应该按顺序划分成三个部分:首先引入标准库里的模块,然后引入第三方模块,最后引入自己的模块。属于同一个部分的 import 语句按字母顺序排列。
实验总结:
编写 Python 代码时,总是应该遵循 PEP 8 风格指南。
与广大 Python 开发者采用同一套代码风格,可以使项目更利于多人协作。
采用一致的风格编写代码,代码的后续修改更容易。
03了解 bytes 与 str 的区别
bytes 实例包含的是原始数据,即 8 位的无符号值(通常按照 ASCII 编码标准来显示)。
a = b'h\x65llo'print(a)print(list(a))print(type(a))
运行效果如下:
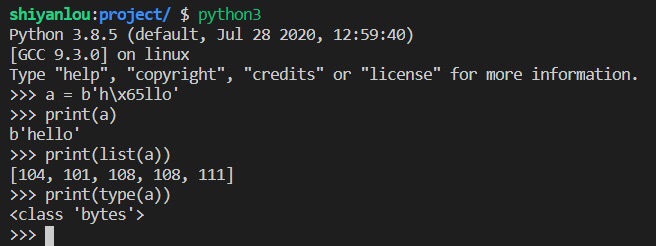
str 实例包含的是 Unicode 码点(code point,也叫做代码点),这些码点与人类语言之中的文本字符相对应。
b = 'a\u0300 propos'print(b)print(list(b))print(type(b))
运行效果如下:
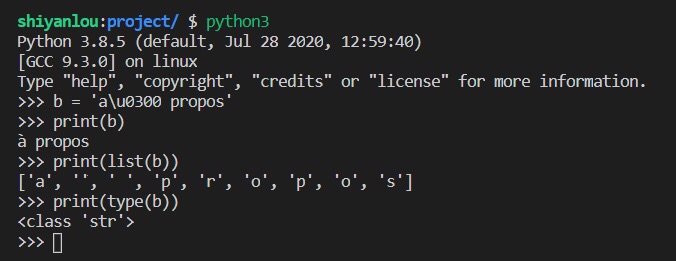
大家一定要记住:str 实例不一定非要用某一种固定的方案编码成二进制数据,bytes 实例也不一定非要按照某一种固定的方案解码成字符串。
要把 Unicode 数据转换成二进制数据,必须调用 str 的 encode 方法。要把二进制数据转换成 Unicode 数据,必须调用 bytes 的 decode 方法。
调用这些方法的时候,可以明确指出自己要使用的编码方案,也可以采用系统默认的方案,通常是指 UTF-8(但有时也不一定,下面就会讲到这个问题)。
编写 Python 程序的时候,一定要把解码和编码操作放在界面最外层来做,让程序的核心部分,可以使用 Unicode 数据来运作,这种办法通常叫做 Unicode 三明治(Unicode sandwich)。
程序的核心部分,应该用 str 类型来表示 Unicode 数据,并且不要锁定到某种字符编码上面。
这样可以让程序接受许多种文本编码(例如 Latin-1 、Shift JIS 及 Big5),并把它们都转化成 Unicode,也能保证输出的文本信息都是用同一种标准(最好是 UTF-8)来编码的。
两种不同的字符类型与 Python 中两种常见的使用情况相对应:
开发者需要操作原始的 8 位值序列,序列里面的这些 8 位值合起来表示一个应该按 UTF-8 或其他标准编码的字符串。
开发者需要操作通用的 Unicode 字符串,而不是操作某种特定编码的字符串。
我们通常需要编写两个辅助函数(helper function),以便在这两种情况之间转换,确保输入值类型符合开发者的预期形式。第一个辅助函数接受 bytes 或 str 实例,并返回 str:
def to_str(bytes_or_str):
if isinstance(bytes_or_str, bytes):
value = bytes_or_str.decode('utf-8') else:
value = bytes_or_str return value # Instance of strprint(repr(to_str(b'foo')))print(repr(to_str('bar')))
运行效果如下:
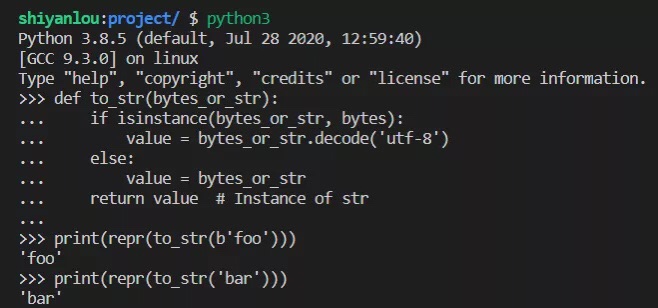
第二个辅助函数也接受 bytes 或 str 实例,但它返回的是 bytes:
def to_bytes(bytes_or_str):
if isinstance(bytes_or_str, str):
value = bytes_or_str.encode('utf-8') else:
value = bytes_or_str return value # Instance of bytesprint(repr(to_bytes(b'foo')))print(repr(to_bytes('bar')))
运行效果如下:
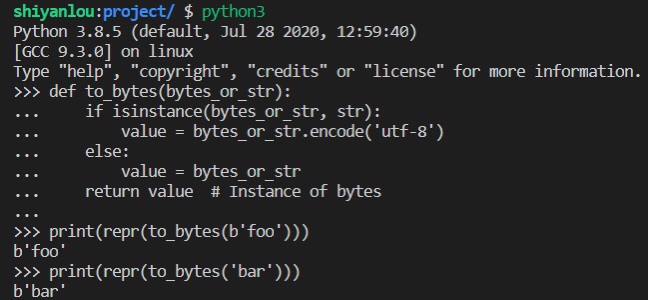
在 Python 中使用原始的 8 位值与 Unicode 字符串时,有两个问题要注意:
第一个问题,bytes 与 str 这两种类型似乎是以相同的方式工作的,但其实例并不相互兼容,所以在传递字符序列的时候必须考虑好其类型。
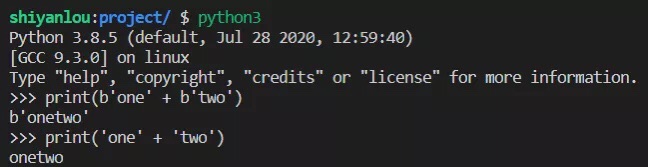
可以用 + 操作符将 bytes 添加到 bytes , str 也可以这样。
print(b'one' + b'two')print('one' + 'two')
运行效果如下:
但是不能将 str 实例添加到 bytes 实例上面:
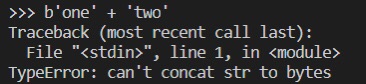
也不能将 bytes 实例添加到 str 实例上面:

bytes 与 bytes 之间可以用二元操作符(binary operator)来比较大小,str 与 str 之间也可以:
assert b'red' > b'blue'assert 'red' > 'blue'
但是 str 实例不能与 bytes 实例比较:

判断 bytes 与 str 实例是否相等,总是会评估为假(False),即便这两个实例表示的字符完全相同,它们也不相等。例如在下面这个例子里,它们表示的字符串都相当于 ASCII 编码之中的 foo 。

两种类型的实例都可以出现在 % 操作符的右侧,用来替换左侧那个格式字符串(format string)里面的 %s 。
print(b'red %s' % b'blue')print('red %s' % 'blue')
运行效果如下:
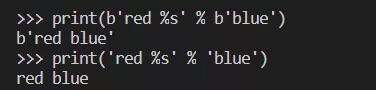
如果格式字符串是 bytes 类型,那么不能用 str 实例来替换其中的 %s,因为 Python 不知道这个 str 应该按照什么方案来编码。

但反过来却可以,也就是说如果格式字符串是 str 类型,则可以用 bytes 实例来替换其中的 %s ,问题是,这可能跟你想要的结果不一样。

这样做,会让系统在 bytes 实例上面调用 repr 方法(参见第 75 条),然后用这次调用所得到的结果替换格式字符串里的 %s ,因此,程序会直接输出 b'blue ',而不是像你想的那样,输出 blue 本身。
第二个问题,发生在操作文件句柄的时候,这里的句柄指由内置的 open 函数返回的句柄。这样的句柄默认需要使用 Unicode 字符串操作,而不能采用原始的 bytes。
习惯了 Python 2 的开发者,尤其容易碰到这个问题,进而导致程序出现奇怪的错误。例如,向文件写入二进制数据的时候,下面这种写法其实是错误的。
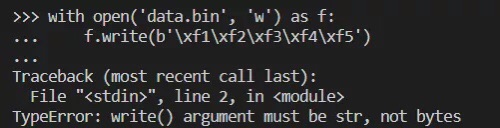
程序发生异常是因为在调用 open 函数时,指定的是 'w ' 模式,所以系统要求必须以文本模式写入。
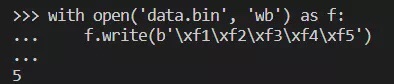
如果想用二进制模式,那应该指定 'wb' 才对。在文本模式下,write 方法接受的是包含 Unicode 数据的 str 实例,不是包含二进制数据的 bytes 实例。所以,我们得把模式改成 'wb' 来解决该问题。
读取文件的时候也有类似的问题。例如,如果要把刚才写入的二进制文件读出来,那么不能用下面这种写法。
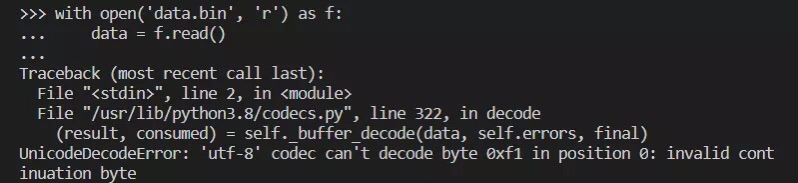
程序出错,是因为在调用 open 函数时指定的是 'r ' 模式,所以系统要求必须以文本模式来读取。
若要用二进制格式读取,应该指定 'rb'。以文本模式操纵句柄时,系统会采用默认的文本编码方案处理二进制数据。所以,上面那种写法会让系统通过 bytes.decode 把这份数据解码成 str 字符串,再用 str.encode 把字符串编码成二进制值。
然而对于大多数系统来说,默认的文本编码方案是 UTF-8,所以系统很可能会把 '\xf1\xf2\xf3\xf4\xf5 '当成 UTF-8 格式的字符串去解码,于是就会出现上面那样的错误。
为了修正错误,需要把模式改成 'rb'。

另一种改法是在调用 open 函数的时候,通过 encoding 参数明确指定编码标准,以确保平台特有的一些行为不会干扰代码的运行效果。
例如,假设刚才写到文件里的那些二进制数据表示的是一个采用 'cp1252 ' 标准(cp1252 是一种老式的 Windows 编码方案)来编码的字符串,则可以这样写:

这样程序就不会出现异常了,但返回的字符串也与读取原始字节数据所返回的有很大区别。
通过这个例子,我们要提醒自己注意当前操作系统默认的编码标准(可以执行 python3 -c 'import locale; print(locale.getpreferredencoding())' 命令查看),了解它与你所期望的是否一致。如果不确定,那就在调用 open 时明确指定 encoding 参数。

实验总结:
bytes 包含的是由 8 位值所组成的序列,str 包含的是由 Unicode 码点所组成的序列。
我们可以编写辅助函数来确保程序收到的字符序列确实是期望要操作的类型(要知道自己想操作的到底是 Unicode 码点,还是原始的 8 位值。用 UTF-8 标准给字符串编码,得到的就是这样的一系列 8 位值)。
bytes 与 str 这两种实例不能在某些操作符(例如 > 、== 、+ 、% 操作符)上面混用。
从文件中读取二进制数据(或者把二进制数据写入文件)时,应该用 'rb'('wb') 这样的二进制模式打开文件。
如果要从文件中读取(或者要写入文件之中)的是 Unicode 数据,那么必须注意系统默认的文本编码方案。若无法肯定,可通过 encoding 参数明确指定。
以上内容出自蓝桥云课训练营《 Effective Python :编写高质量 Python 代码的 90 个有效方法》,但由于内容比较多,我就不再一一展开。
04 福利 Tips
现在加入蓝桥云课训练营《 Effective Python :编写高质量 Python 代码的 90 个有效方法》,可享受八折优惠。

