
他爬取了B站所有番剧信息,发现了这些……

本文来自「楼+ 之数据分析与挖掘实战 」第 4 期学员 —— Yueyec 的作业。他爬取了B站上所有的番剧信息,发现了很多有趣的数据~

关键信息:最高播放量 / 最强up主 / 用户追番数据 / 云追番?
起源
「数据分析」从「数据挖掘」开始,Yueyec 同学选择了 BeautifulSoup 来爬取B站的番剧信息。部分代码如下:


完整的代码可在文末查看。
数据清洗
数据分析前,我们要对数据进行清洗。
爬取数据后,发现有些视频的播放次数为-1,可能是由于版权、封号等问题下架的视频,大约有1000多个。
data[-1 == data['观看次数']]

清洗掉这些脏数据,清洗完成后,就可以分析拿到手的数据了。
data.drop(data[-1 == data['观看次数']].index, inplace=True)
最勤劳的up主
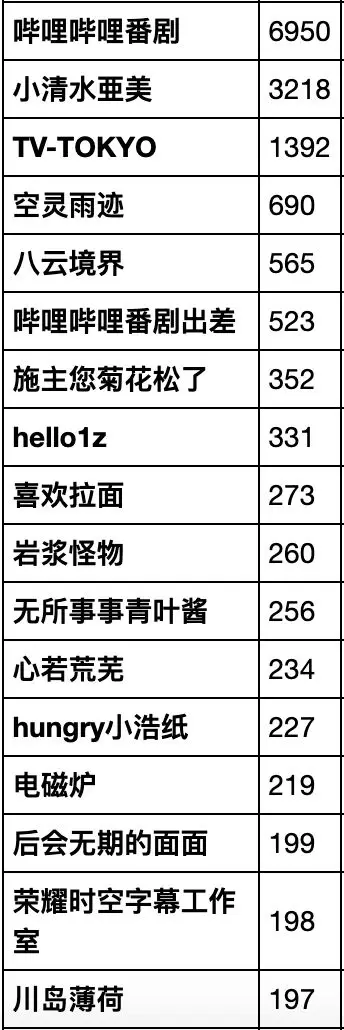
开始数据分析环节,我们先来看看谁是最勤劳的up主,他贡献了全站四分之一的番剧,猜猜他是谁?

统计发现:大致四分之一是 哔哩哔哩官方 发布的,排第二的则为「小清水亜美」,搬运了3218 集的番剧,第三位为 东京电视台。
完整的代码可在文末查看。
收藏量和播放量最高的番剧
收藏量和播放量最高的番剧都是哪部?结果可能会大大出于意料……
data.sort_values("收藏", ascending=False).reset_index(drop=True)
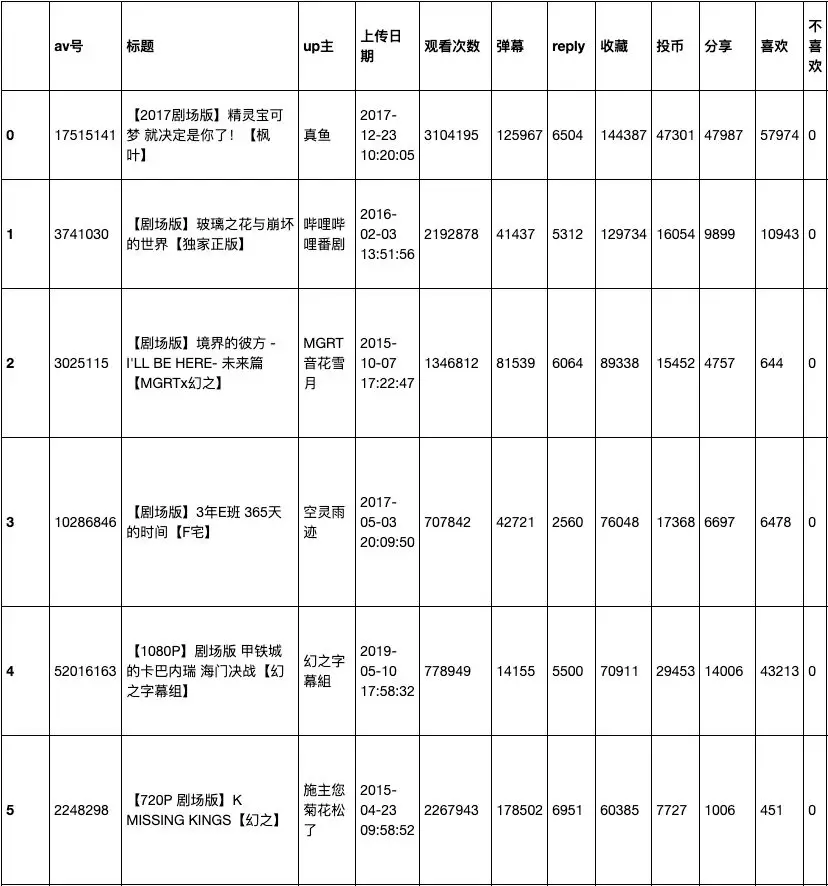
收藏数量排序
统计发现,收藏的番剧中,很多都是剧场版,可能是相对于TV版,剧场版制作更精良的缘故。在具体排序中,排第五的居然是本月10号上传的番剧,这点很意外。
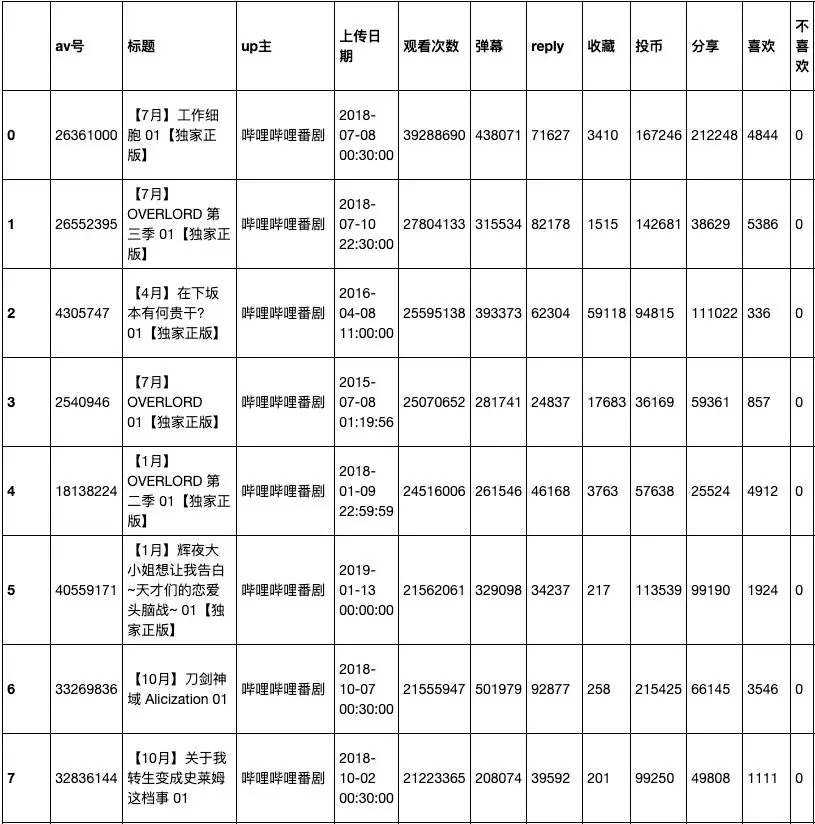
播放量最高的番剧又是哪个呢 :
data.sort_values("观看次数", ascending=False).reset_index(drop=True)
分析结果:
- 排名最高的「工作细胞」的播放量几乎达到了4000千万,远超第二部。

2. 前五名中,「Overlord」出现了三次,果然是公认的B站霸权的番剧。
- 排名靠前的几部,都是番剧的第一集。
![]()
XX云番剧?
根据用户喜好,智能推荐音乐的应用我们都见过很多,但智能推荐番剧的好像挺少,能不能基于用户数据,做一个推荐番剧的系统呢?
Yueyec 同学进行了实验:
“另外爬取了用户的追番信息来做关联分析,可以查看到哪些番剧是关联比较大的。”
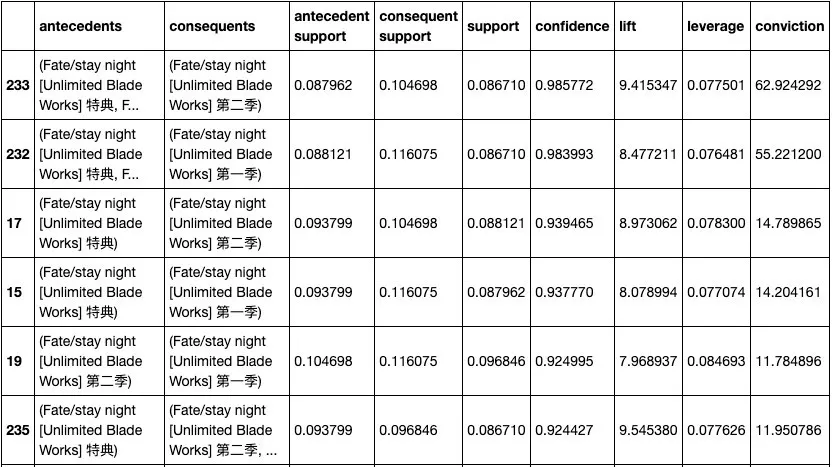
“可以看到,其中很多是同一个番剧,只是季数不同。但不少番剧之间也与很高的置信度,我觉得可以用此得到一个简单的推荐算法。”
中肯的总结和建议
-
通过这次6周的学习,补充了不少知识,加深了 Pandas 的使用,也了解了时间序列、自然语言等的处理方法。
-
虽然时间不长,但是对整个过程都有所了解,为将来学习机器学习建立了基石。
-
部分挑战太简单,建议把挑战换成从头到尾自己实现模型,更能加深印象和具有挑战难度。
-
第五周的内容展现了不同类型的分析模板,加强了见识也提供了很多扩展的内容。因为并没有完全看完,所以接下来会花部分时间来学习这部分。

除了 Yueyec 同学,还有很多优秀的同学的作品:

这些作品的代码,你可以在浏览器中输入这个链接,或点击阅读原文,再点击「查看更多优秀作品」来查阅。
https://github.com/shiyanlou/louplus-dm/tree/master/Assignments
如果你也想像这位同学一样,系统地学习数据挖掘和数据分析技能,可以了解一下《数据分析与挖掘实战》这门课程,目前已经开到第六期,一线大牛授课,带你在6周内成长为有真实工作能力的数据科学工程师。
现在扫码添加小姐姐微信,还可领取:100元优惠券 + 数据分析与挖掘学习脑图~

我在实验楼等你!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号