Deep Learning基础--随时间反向传播 (BackPropagation Through Time,BPTT)推导
1. 随时间反向传播BPTT(BackPropagation Through Time, BPTT)
RNN(循环神经网络)是一种具有长时记忆能力的神经网络模型,被广泛用于序列标注问题。一个典型的RNN结构图如下所示:
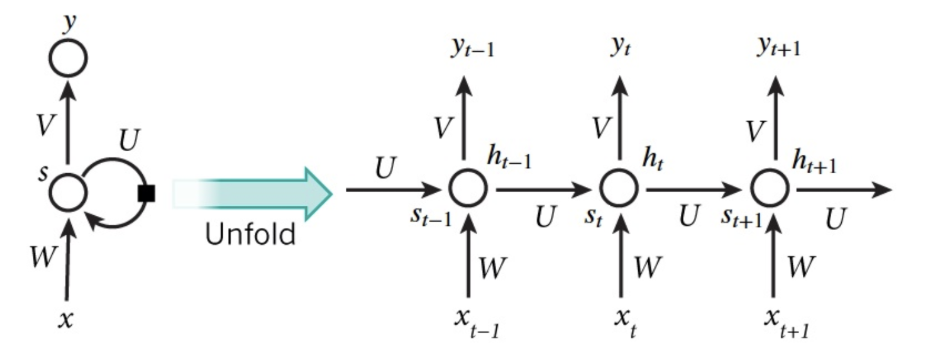
从图中可以看到,一个RNN通常由三小层组成,分别是输入层、隐藏层和输出层。与一般的神经网络不同的是,RNN的隐藏层存在一条有向反馈边,正是这种反馈机制赋予了RNN记忆能力。要理解左边的图可能有点难度,我们将其展开成右边的这种更加直观的形式,其中RNN的每个神经元接受当前时刻的输入以及上一时刻隐单元的输出,计算出当前神经元的输入。三个权重矩阵, 和就是要通过梯度下降来拟合的参数。整个优化过程叫做BPTT(BackPropagation Through Time, BPTT)。
形式化如下:
同样地,定义交叉熵损失函数如下:
下面我们将举个具体的例子。
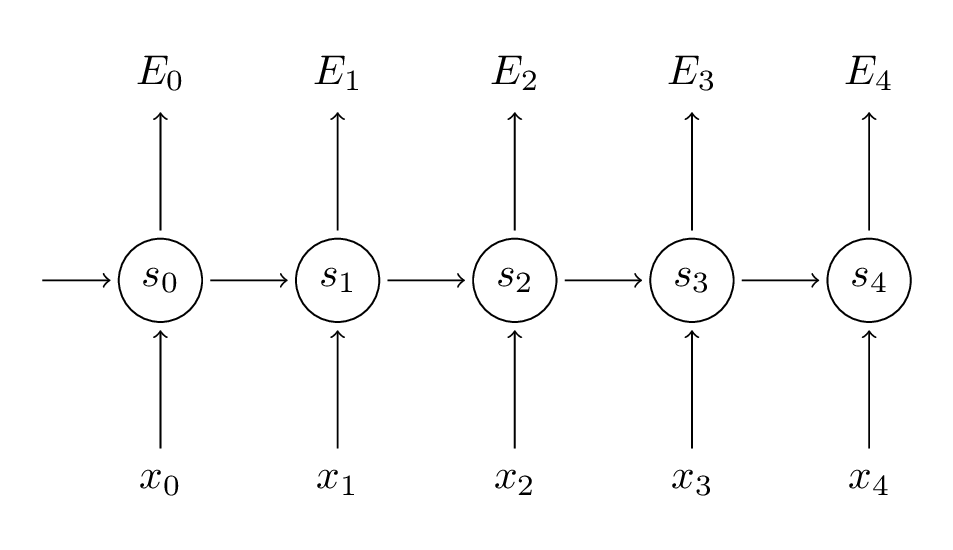
我们的目标是通过梯度下降来拟合参数矩阵, 和。如同求损失时的加和,有。
为了计算这些梯度,我们使用链式法则。我们将以为例,做如下推导。
在上面式子中,,表示两个向量的外积。对的偏导是简单的,因为时间步的对的偏导只与,和有关。但是,对于就没有这么简单了,如图:
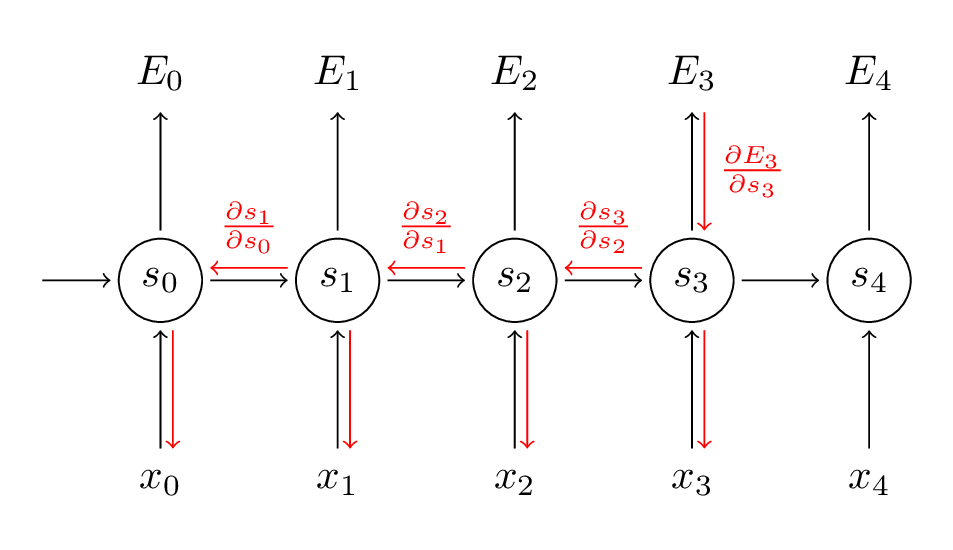
推导过程如下:
上式中,我们可以看到,这与标准的BP算法并无太多不同,唯一的区别在于需要对各时间步求和。这也是标准RNN难以训练的原因:序列(句子)可能很长,可能是20个字或更多,因此需要反向传播多个层。在实践中,许多人将时间步进行截断来控制传播层数。
BPTT实现的代码如下:

def bptt(self, x, y): T = len(y) # Perform forward propagation o, s = self.forward_propagation(x) # We accumulate the gradients in these variables dLdU = np.zeros(self.U.shape) dLdV = np.zeros(self.V.shape) dLdW = np.zeros(self.W.shape) delta_o = o delta_o[np.arange(len(y)), y] -= 1. # For each output backwards... for t in np.arange(T)[::-1]: dLdV += np.outer(delta_o[t], s[t].T) # Initial delta calculation: dL/dz delta_t = self.V.T.dot(delta_o[t]) * (1 - (s[t] ** 2)) # Backpropagation through time (for at most self.bptt_truncate steps) for bptt_step in np.arange(max(0, t-self.bptt_truncate), t+1)[::-1]: # print "Backpropagation step t=%d bptt step=%d " % (t, bptt_step) # Add to gradients at each previous step dLdW += np.outer(delta_t, s[bptt_step-1]) dLdU[:,x[bptt_step]] += delta_t # Update delta for next step dL/dz at t-1 delta_t = self.W.T.dot(delta_t) * (1 - s[bptt_step-1] ** 2) return [dLdU, dLdV, dLdW]
2. 梯度消失问题
标准RNN难以学习到文本的上下文依赖,例如“The man who wore a wig on his head went inside”,句子要表达的是带着假发的男人进去了而不是假发进去了,这一点对于标准RNN的训练很难。为了理解这个问题,我们先看看上面的式子:
注意,其中的仍然包含着链式法则,例如。
所以上面的式子(5)可以重写为式子(6),即逐点导数的雅克比矩阵:
而tanh函数和其导数图像如下:
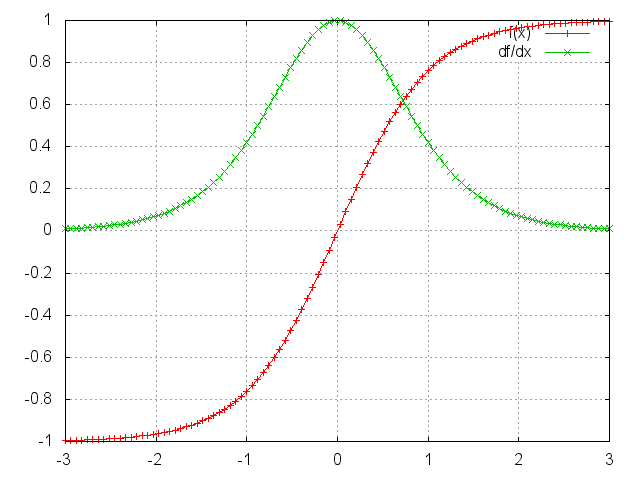
可见,tanh函数(sigmoid函数也不例外)的两端都有接近0的导数。当出现这种情况时,我们认为相应的神经元已经饱和。参数矩阵将以指数方式快速收敛到0,最终在几个时间步后完全消失。来自“遥远”的时间步的权重迅速为0,从而不会对现在的学习状态产生贡献:学不到远处上下文依赖。
很容易想象,根据我们的激活函数和网络参数,如果雅可比矩阵的值很大,将会产生梯度爆炸。首先,梯度爆炸是显而易见的,权重将渐变为NaN(不是数字),程序将崩溃。其次,将梯度剪切到预定义的阈值是一种非常简单有效的梯度爆炸解决方案。当然,梯度消失问题影响更加恶劣,因为要知道它们何时发生或如何处理它们并不简单。
目前,已经有几种方法可以解决梯度消失问题。正确初始化矩阵可以减少消失梯度的影响。正规化也是如此。更优选的解决方案是使用Relu代替tanh或S形激活函数。ReLU导数是0或1的常数,因此不太可能遇到梯度消失。更流行的解决方案是使用长短期记忆单元(LSTM)或门控循环单元(GRU)架构。LSTM最初是在1997年提出的,也是今天NLP中使用最广泛的模型。GRU,最初于2014年提出,是LSTM的简化版本。这两种RNN架构都明确地设计用于处理梯度消失并有效地学习远程依赖性。
参考英文博客:http://www.wildml.com/2015/10/recurrent-neural-networks-tutorial-part-3-backpropagation-through-time-and-vanishing-gradients/


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端