Machine Learning系列--CRF条件随机场总结
根据《统计学习方法》一书中的描述,条件随机场(conditional random field, CRF)是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,其特点是假设输出随机变量构成马尔科夫随机场。
条件随机场是一种判别式模型。
一、理解条件随机场
1.1 HMM简单介绍
HMM即隐马尔可夫模型,它是处理序列问题的统计学模型,描述的过程为:由隐马尔科夫链随机生成不可观测的状态随机序列,然后各个状态分别生成一个观测,从而产生观测随机序列。
在这个过程中,不可观测的序列称为状态序列(state sequence), 由此产生的序列称为观测序列(observation sequence)。
该过程可通过下图描述:
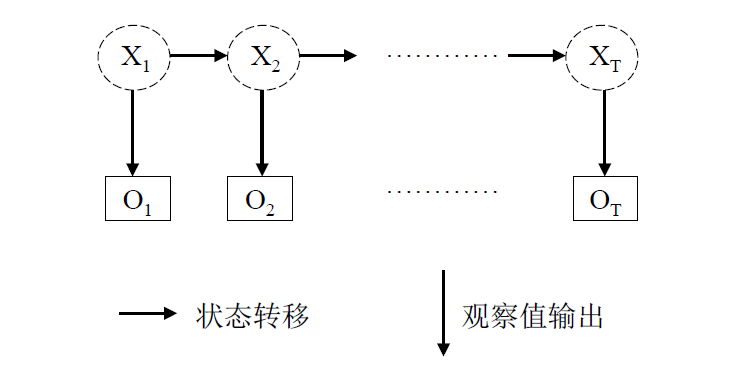
上图中, 是隐含序列,而是观察序列。
隐马尔可夫模型由三个概率确定:
- 初始概率分布,即初始的隐含状态的概率分布,记为;
- 状态转移概率分布,即隐含状态间的转移概率分布, 记为;
- 观测概率分布,即由隐含状态生成观测状态的概率分布, 记为。
以上的三个概率分布可以说就是隐马尔可夫模型的参数,而根据这三个概率,能够确定一个隐马尔可夫模型。
而隐马尔科夫链的三个基本问题为:
- 概率计算问题。即给定模型和观测序列,计算在模型下观测序列出现的最大概率,主要使用前向-后向算法解决;
- 学习问题。即给定观测序列,估计模型的参数, 使得在该参数下观测序列出现的概率最大,即最大,主要使用Baum-Welch算法EM迭代计算(若不涉及隐状态,则使用极大似然估计方法解决);
- 解码问题。给定模型和观测序列,计算最有可能产生这个观测序列的隐含序列, 即使得概率最大的隐含序列,主要使用维特比算法(动态规划思想)解决。
HMM最初用于传染病模型和舆情传播问题,这些问题里面的当前状态可以简化为只与前一状态有关,即具备马尔科夫性质。但是,试想一个语言标注问题,模型不仅需要考虑前一状态的标注,也应该考虑后一状态的标注(例如我爱中国,名词+动词+名词,上下文信息更丰富)。由此,自然会对模型做出更多的假设条件,也就引出了图模型(当前状态与相连的状态都有关)+ 条件模型(当前的状态与隐状态有关)= 条件随机场。
1.2 概率无向图(马尔科夫随机场)
概率无向图模型又称马尔科夫随机场,是一个可以由无向图表示的联合概率分布。有向图是时间序列顺序的,又称贝叶斯网,HMM就属于其中的一种。HMM不能考虑序列的下一状态信息,这是有向图具有“方向性”所不能避免的。而无向图则可以将更多的相连状态考虑在当前状态内,考虑更全面的上下文信息。
概率图模型是由图表示的概率分布,记是由结点集合和边集合组成的图。
首先我们需要明确成对马尔科夫性、局部马尔科夫性和全局马尔科夫性,这三种性质在理论上被证明是等价的。
成对马尔科夫性是指图中任意两个没有边连接的结点所对应的的两个随机变量是条件独立的。
给定一个联合概率分布,若该分布满足成对、局部或全局马尔科夫性,就称此联合概率分布为概率无向图模型或马尔科夫随机场。

局部马尔科夫性(黑色与白色点永远不相邻,即成对马尔科夫性)
1.3 条件随机场
条件随机场(CRF)是给定随机变量的条件下,随机变量的马尔科夫随机场。在实际中,运用最多的是标注任务中的线性链条件随机场(linear chain conditional random field)。这时,在条件概率模型中,是输出变量,表示标记序列,是输入变量,表示需要标注的观测序列(状态序列)。
学习时,利用训练数据集通过极大似然估计或正则化的极大似然估计得到条件概率模型;
预测时,对于给定的输入序列,求出条件概率最大的输出序列。
一般性条件随机场定义如下:
设与是随机变量,是在给定的条件下的条件概率分布。若随机变量构成一个由无向图表示的马尔科夫随机场,即:
对任意结点成立,则称条件概率分布为条件随机场。式中表示在图中与结点有边连接的所有结点,表示结点以外的所有结点,与为结点与对应的随机变量。
类似地,线性链条件随机场有如下定义:
显然,线性链条件随机场是一般性条件随机场的一种特例。
设,均为线性链表示的随机变量序列,若在给定随机变量序列的条件下,随机变量序列的条件概率分布构成条件随机场,即满足马尔科夫性:
则称为线性链条件随机场。在标注问题中,表示输入观测序列,表示对应的输出标记序列或状态序列。
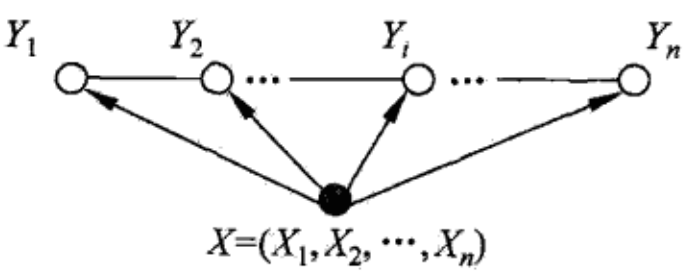
线性链条件随机场

和具有相同图结构的线性链条件随机场
二、条件随机场的概率计算问题
条件随机场的概率计算问题是给定条件随机场,输入序列和输出序列,计算条件概率,以及相应的数学期望的问题。
条件随机场的概率计算和HMM的概率计算的思想没有本质区别,甚至可以说是完全一样的,区别只在于公式上稍作变化。
2.1 前向-后向算法
为了计算每个节点的概率,如书中提到的的概率,对于这类概率计算,用前向或者后向算法其中的任何一个就可以解决。前向或后向算法,都是扫描一遍整体的边权值,计算图的,只是它们扫描的方向不同,一个从前往后,一个从后往前。所以书中的公式:
式中的为前向向量,为后向向量。
按照前向-后向向量的定义,很容易计算标记序列在位置是标记的条件概率和在位置与是标记和的条件概率:
2.2 计算期望
利用前向-后向向量,可以计算特征函数关于联合分布和条件分布的数学期望。
特征函数关于条件分布的数学期望是:
其中,有.
假设经验分布为,特征函数关于联合分布的数学期望是:
其中,有.
2.3 参数学习算法
条件随机场模型实际上是定义在时序数据上的对数线性模型,其学习方法包括极大似然估计和正则化的极大似然估计。具体的优化实现算法有改进的迭代尺度法IIS、梯度下降法以及拟牛顿法。
参数模型算法与最大熵模型算法的理论推导没有什么区别,仍是对训练的对数似然函数求极大值的过程。
训练数据的对数似然函数为:
2.4 预测算法
维特比算法采用了经典的动态规划思想,该算法和HMM又是完全一致的,所以也不需要重新再推导一遍,可直接参看之前博文的【维特比算法】。那么,为什么需要使用维特比算法,而不是像最大熵模型那样,直接代入输入向量x即可?简单来说,是因为在整个图中,每个节点都是相互依赖,所以单纯的代入是行不通的,你没法知道,到底哪个标签与哪个标签是可以联系在一块,所以必须把这个问题给【平铺】开来,即计算每一种可能的组合,但一旦平铺你会发现,如果穷举,那么运行时间是,为标签数,为对应的序列状态数。算法的开销相当大,而采用动态规划的一个好处在于,我们利用空间换时间,在某些中间节点直接记录最优值,以便前向扫描的过程中,直接使用,那么自然地运行时间就下去了。
三、条件随机场与其他模型的联系
3.1 经典对比图

经典对比图,来自论文:Sutton, Charles, and Andrew McCallum. "An introduction to conditional random fields." Machine Learning 4.4 (2011): 267-373.
从图中我们能找到CRF所处的位置,它可以从朴素贝叶斯方法用于分类经过sequence得到HMM模型,再由HMM模型conditional就得到了CRF。或者由朴素贝叶斯方法conditional成逻辑斯蒂回归模型,再sequence成CRF,两条路径均可。
首先来看看朴素贝叶斯的模型:
其中特征向量可以是,由于朴素贝叶斯每个特征独立同分布,所以有:
整理得:
再来看一般形式的逻辑斯蒂回归模型:
其中,为规范化因子。
由朴素贝叶斯的模型继续推导:
这就是从逻辑斯蒂回归模型看贝叶斯模型,我们能得到的结论。首先,逻辑斯蒂回归模型最终模型表达为条件概率,而非联合概率,因为它是判别式模型;其次,两者式中参数后的特征函数不同。贝叶斯模型考虑的是联合概率分布,所以它是生成式模型;而逻辑斯蒂回归模型,并不计算联合概率分布,而是把每个特征的实际值代入式中,计算条件判别概率。根据这样的思路,相信你能更好地理解上面的经典图。
3.2 HMM vs. MEMM vs. CRF
- HMM -> MEMM: HMM模型中存在两个假设:一是输出观察值之间严格独立,二是状态的转移过程中当前状态只与前一状态有关。但实际上序列标注问题不仅和单个词相关,而且和观察序列的长度,单词的上下文,等等相关。MEMM解决了HMM输出独立性假设的问题。因为HMM只限定在了观测与状态之间的依赖,而MEMM引入自定义特征函数,不仅可以表达观测之间的依赖,还可表示当前观测与前后多个状态之间的复杂依赖。
- MEMM -> CRF: CRF不仅解决了HMM输出独立性假设的问题,还解决了MEMM的标注偏置问题,MEMM容易陷入局部最优是因为只在局部做归一化,而CRF统计了全局概率,在做归一化时考虑了数据在全局的分布,而不是仅仅在局部归一化,这样就解决了MEMM中的标记偏置的问题。使得序列标注的解码变得最优解。
- HMM、MEMM属于有向图,所以考虑了与的影响,但没将当做整体考虑进去。CRF属于无向图,没有这种依赖性,克服此问题。
参考内容:
1. 如何用简单易懂的例子解释条件随机场(CRF)模型?它和HMM有什么区别?https://www.zhihu.com/question/35866596
2. 条件随机场学习笔记:https://blog.csdn.net/u014688145/article/details/58055750
3. 《统计学习方法》,李航


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端
2016-12-15 Ubuntu14.04或16.04下Hadoop及Spark的开发配置