Machine Learning系列--隐马尔可夫模型的三大问题及求解方法
本文主要介绍隐马尔可夫模型以及该模型中的三大问题的解决方法。
隐马尔可夫模型的是处理序列问题的统计学模型,描述的过程为:由隐马尔科夫链随机生成不可观测的状态随机序列,然后各个状态分别生成一个观测,从而产生观测随机序列。
在这个过程中,不可观测的序列称为状态序列(state sequence), 由此产生的序列称为观测序列(observation sequence)。
该过程可通过下图描述:
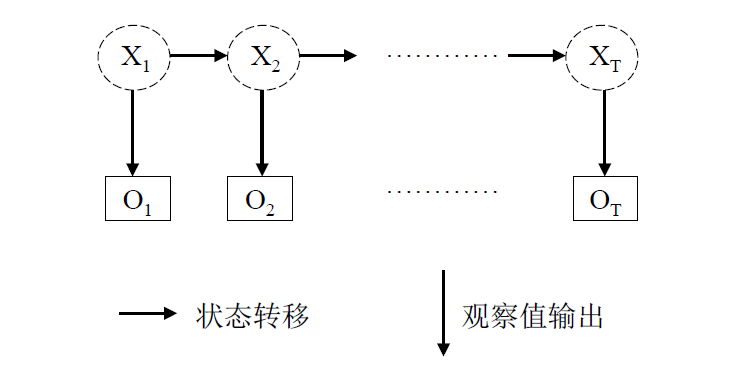
上图中, $X_1,X_2,…X_T$是隐含序列,而$O_1, O_2,..O_T$是观察序列。
隐马尔可夫模型由三个概率确定:
- 初始概率分布,即初始的隐含状态的概率分布,记为$\pi$;
- 状态转移概率分布,即隐含状态间的转移概率分布, 记为$A$;
- 观测概率分布,即由隐含状态生成观测状态的概率分布, 记为$B$。
以上的三个概率分布可以说就是隐马尔可夫模型的参数,而根据这三个概率,能够确定一个隐马尔可夫模型$\lambda = (A, B, \pi)$。
而隐马尔科夫链的三个基本问题为:
- 概率计算问题。即给定模型$\lambda = (A, B, \pi)$和观测序列$O$,计算在模型$\lambda$下观测序列出现的最大概率$P(O|\lambda)$;
- 学习问题。即给定观测序列$O$,估计模型的参数$\lambda$, 使得在该参数下观测序列出现的概率最大,即$P(O|\lambda)$最大;
- 解码问题。给定模型$\lambda = (A, B, \pi)$和观测序列$O$,计算最有可能产生这个观测序列的隐含序列$X$, 即使得概率$P(X|O, \lambda)$最大的隐含序列$X$。
一、概率计算问题
概率计算问题理论上可通过穷举法来解决,即穷举所有可能的隐含状态序列,然后计算所有可能的隐含序列生成观测序列的概率,假设观测序列的长度为$n$, 且每个观测状态对应的可能的隐含状态长度为$m$, 则这种方法的时间复杂度就是$O(m^n)$, 这样的时间复杂度显然是无法接受的,因此在实际中往往不采用这种方法,而是采用前向算法和后向算法, 前向算法和后向算法都是通过动态规划来减少计算的时间复杂度,两者的不同点就是计算的方向不同。
1.1 前向算法
前向算法需要先定义前向概率:
前向概率定义为到时刻$t$为止观测序列为$o_1,o_2,o_3…o_t$,且时刻$t$的隐含状态为所有的隐含状态中的第$i$个(记为$q_i$),则前向概率可记为
$$\alpha_t(i) = P(o_1,o_2,o_3…o_t,x_t = q_i|\lambda)$$
定义了前向概率,便可递归地求解前向概率和观测序列的概率$P(o_1,o_2,o_3…o_t|\lambda)$。
初始的状态为:
$$\alpha_1(i) = \pi_ib_i(o_1)~~i=1,..m$$
上式中的$m$表示隐含状态的数目,$\pi_i$表示各个隐含状态的初始概率,$b_i(o_1)$表示第$i$个隐含状态生成观测状态$o_1$的概率。
则递推的公式为:
$$\alpha_{t+1}(i) = (\sum_{j=1}^N \alpha_t(j) a_{ji} )b_i(o_{t+1})~~i=1,..m$$
上式中的$a_{ji}$表示从隐含状态$j$转移到隐含状态$i$的状态转移概率。通过下图可较直观地看到前向递推公式的过程:
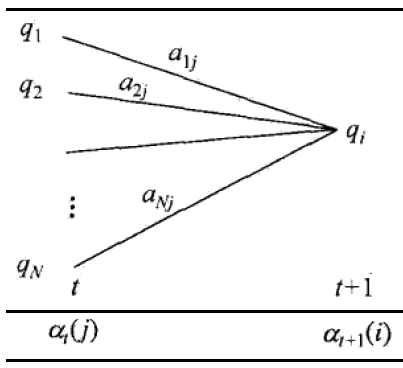
最终计算得到的概率为(其中$T$为观测序列的长度):
$$P(O|\lambda) = \sum_{i=1}^{m}\alpha_T(i)$$
1.2 后向算法
类似前向算法,后向算法也可用于求解这个问题,只是方向是从后到前的。同样的,需要先定义后向概率:
后向概率指时刻$t$的隐含状态为所有隐含状态中的第$i$个(记为$q_i$), 且时刻$t+1$到$T$的观测序列为$o_{t+1}, o_{t+2},….o_T$的概率,记为:
$$\beta_t(i) = P(o_{t+1}, o_{t+2},….o_T, x_t = q_i|\lambda)$$
初始状态定义为:
$$\beta_T(i) = 1~~i=1,2,…m$$
这里概率为1的原因是本来还需要看看时刻$T$后面有什么东西,但因为最后一个时刻$T$后面已经没有时刻,即不需要再观测某个东西,所以随便给个什么状态都可以。
递推公式为:
$$\beta_t(i) = \sum_{j=1}^ma_{ij}b_j(o_{t+1})\beta_{t+1}(j)~~i=1,2,…m$$
上面的式子中的符号与前向算法中的一致,其过程可通过下图更直观理解:
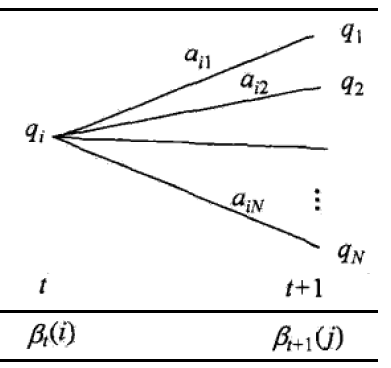
最终计算得到的概率为:
$$P(O|\lambda) = \sum_{i=1}^m \pi_ib_i(o_1)\beta_1(i)$$
分析可知,前向算法和后向算法的时间复杂度均是$O(m^2T)$,$m$为隐含状态的个数,$T$为序列长度。
二、学习问题
学习问题要根据观测序列来推导模型参数,这一类的问题对应到概率论中的极大似估计问题。但是这里是有隐含变量的极大似然估计,因此直接无法通过直接求导进行求解,而要通过EM算法来求解这一类问题。
EM 算法是一类算法,用于解决有隐含变量的概率模型参数的极大似然估计,具体到隐马尔可夫模型中的具体算法是 Baum-Welch 算法。
注:这里采用 EM 算法的前提是问题仅给出了观测序列,假如同时给出了观测序列和隐含序列,可直接通过最大似然估计求解。
这里只给出 Baum-Welch 算法的流程,而省去其推导过程:
1. 初始化模型参数:选取$a_{ij}^{(0)}, b_j^{(0)}, \pi_i^{(0)}$, 得到模型$\pi^{(0)} = (A^{(0)}, B^{(0)}, \pi^{(0)})$;
2. E 步,求解两个中间变量$\gamma_t(i), \xi_t(i,j)$,两者的含义如下:
$\gamma_t(i)$:给定模型$\lambda$和观测序列$O$,在时刻$t$的隐含状态为$q_i$的概率, 即$\gamma_t(i) = P(x_t = q_i | O, \lambda)$;
$\xi_t(i,j)$:给定模型$\lambda$和观测序列$O$,在时刻$t$的隐含状态为$q_i$, 时刻$t+1$的隐含状态为$q_j$的概率, 即$\xi_t(i,j) = P(x_t = q_i, x_{t+1} = q_j | O, \lambda)$.
结合前面的前向概率和后向概率的定义,计算这两个中间变量的公式如下($m$表示隐含状态的总个数):
$$\gamma_t(i) = \frac{\alpha_t(i) \beta_t(i)}{\sum_{j=1}^m \alpha_t(j) \beta_t(j)}$$
$$\xi_t(i,j) = \frac{\alpha_t(i) a_{ij} b_j(o_{t+1})\beta_{t+1}(j)}{\sum_{p=1}^m \sum_{q=1}^m \alpha_t(p) a_{pq} b_q(o_{t+1})\beta_{t+1}(q)}$$
3. M步,同时E步求解出的两个中间变量来求解模型的参数,求解公式如下:
$$a_{ij} = \frac{\sum_{t=1}^T \xi_t(i,j)}{\sum_{t=1}^T \gamma_t(i)}$$
$$b_j(k) = \frac{\sum_{t=1}^T \gamma_t(j)I(o_t = v_k)}{\sum_{t=1}^T \gamma_t(j)}$$
$$\pi_i = \gamma_1(i)$$
上式中的$I(o_t = v_k)$表示时刻$t$的观察状态为$v_k$时, $I(o_t = v_k)$才为1,否则为0.
迭代进行E步骤和M步,将最终收敛的结果作为模型的参数.
三、解码问题
解码问题理论上也可以通过穷举法来解决,就是穷举所有可能的隐含序列并计算在这个隐含序列下观测序列的概率,并选择概率最大的那个隐含序列,但是穷举所有可能的隐含序列的时间复杂度也是指数级别的,跟第一个问题一样,在实际中往往也是不常用的。
实际中,解码问题通过动态规划来降低时间复杂度,并且已经有了成熟的解决方法,就是著名的维特比算法。
转自博文:http://wulc.me/2017/07/14/隐马尔可夫模型的三大问题及求解方法/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号