kafka 生产者发送消息的分区策略
生产者发送消息的分区策略
分区是实现负载均衡以及高吞吐量的关键。
Kafka为了增加系统的伸缩性(Scalability),引入了分区(Partitioning)的概念。
Kafka 中的分区机制指的是将每个主题划分成多个分区(Partition),每个分区是一组有序的消息日志。主题下的每条消息只会保存在某一个分区中,而不会在多个分区中被保存多份。
通过这个设计,就可以以分区这个粒度进行数据读写操作,每个Broker的各个分区独立处理请求,进而实现负载均衡,提升了整体系统的吞吐量。
分区策略是决定生产者将消息发送到哪个分区的算法。
默认的分区器
org.apache.kafka.clients.producer.internals.DefaultPartitioner
创建消息时,根据你的参数决定发送到哪个分区:
-
指明partition的情况下,直 接将指明的值作为partition值; 例如partition=0,所有数据写入 分区0
-
没有指明partition值但有key的情况下,将key的hash值与topic的 partition数进行取余得到partition值;
例如:key1的hash值=5, key2的hash值=6 ,topic的partition数=2,那 么key1** 对应的value1写入1号分区,key2对应的value2写入0号分区。 -
既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器),会随机选择一个分区,并尽可能一直 使用该分区,待该分区的batch已满或者已完成,Kafka再随机一个分区进行使用(和上一次的分区不同)。
例如:第一次随机选择0号分区,等0号分区当前批次满了(默认16k)或者linger.ms设置的时间到, Kafka再随机一个分区进 行使用(如果还是0会继续随机)。
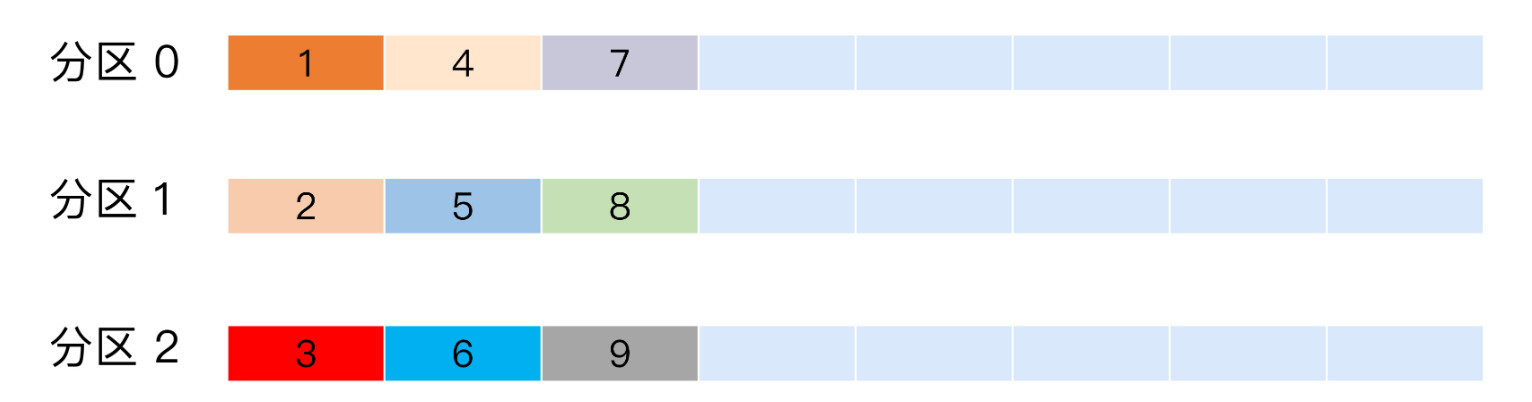
轮询策略
即按消息顺序进行分区顺序分配(比如图中消息顺序1,2,3,4...会按顺序分配在各个分区中)
随机策略
这是老版本Kafka的默认策略。
Key-ordering策略
有点类似哈希桶算法,对于有key的数据,用key的哈希值对分区数取模计算对应的分区。
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return Math.abs(key.hashCode()) % partitions.size();
Kafka默认:
- 如果指定了 Key,那么默认实现按Key-ordering策略;
- 如果没有指定 Key,则使用轮询策略。
自定义分区策略:
Step1: 定义类实现 Partitioner 接口
Step2: 重写 partition()方法。
Step3: 设置partitioner.class。
@Component
public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
String msgValues = value.toString();
int partition;
if (msgValues.contains("test")){
partition = 0;
}else {
partition = 1;
}
return partition;
}
@Override
public void close() {
//Nothing to close
}
@Override
public void configure(Map<String, ?> configs) {
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号