针对于 Scrapy 爬虫框架的搭建与解析
Scrapy
pip install scrapy
1、Scrapy 爬虫框架
爬虫框架:
- 爬虫框架是实现爬虫功能的一个软件结构和功能组件集合。
- 爬虫框架是一个半成品,能够帮助用户实现专业的网络爬虫。
解析Scrapy爬虫框架:
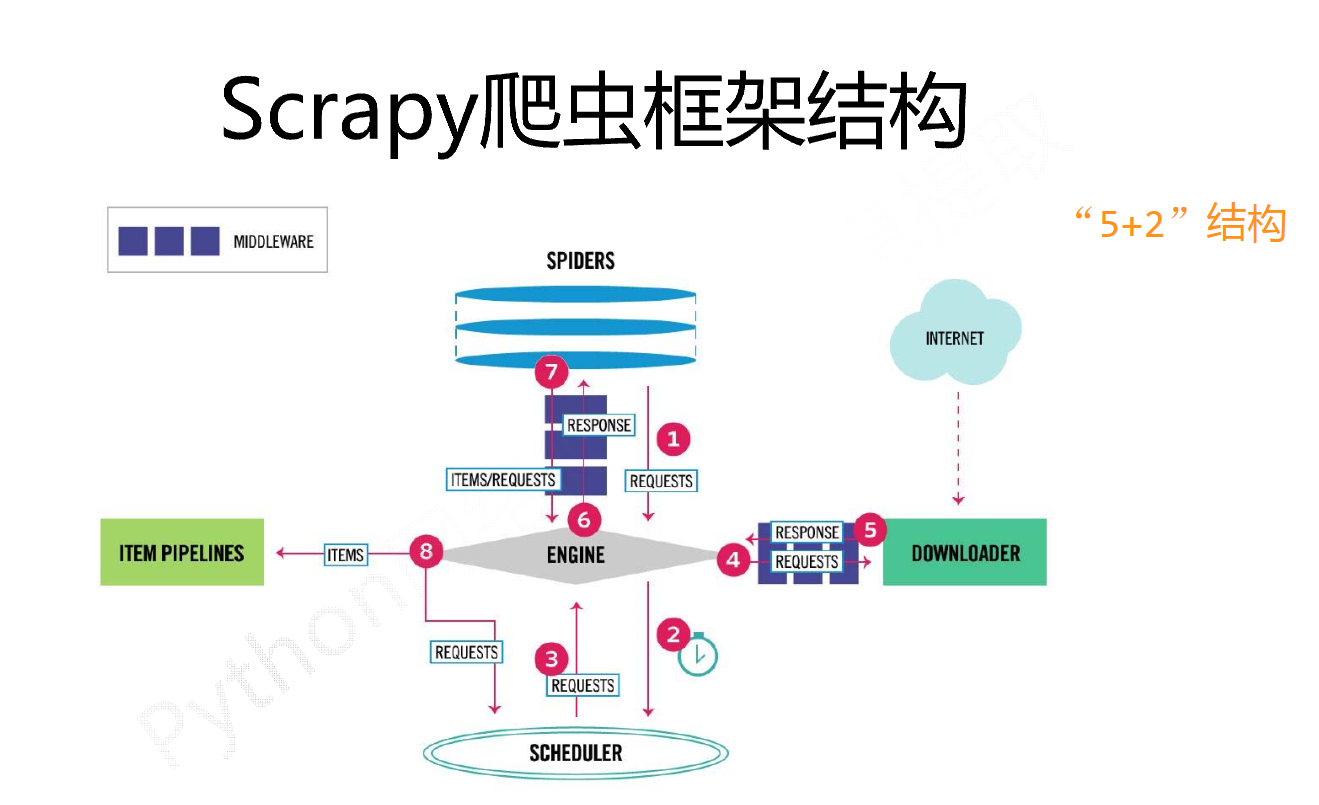
Scrapy 爬虫框架包含 ”5 +2“ 结构,他有五个主模块以及两个中间键构成。
engine 模块:整个框架的中心,控制整个模块的数据流,任何模块之间的数据流动,都要通过ENGINE模块来完成调度。
downloader 模块:根据请求下载网页。
scheduler 模块:对于所有的爬取请求进行调度管理。
engine-----downloader 中间键:downloader Middleware ,对于 engine,scheduler 和 downloader 之间进行用户可配置的控制。用户可以编写配置代码,对请求 request 或者 response 进行修改、丢弃或者新增。
spider 模块:解析 downloader 返回的响应,产生爬取项,以及产生额外的爬取请求。
item pipelines 模块:以流水线的方式处理 spider 产生的爬取项,由一组操作顺序组成,类似流水线,每个操作是一个item pipeline 类型,可能操作包括:清理、检验和查重爬取项中的 html 数据,将数据存储到数据库。
spider-----engine 中间键:对 spider 产生的请求和爬取项再处理,用户可以在这里编写配置代码,对请求和爬取项进行修改,丢弃,新增的操作。
2、Requests VS Scrapy
相同点:
- 两个库都可以进行页面的请求和爬取,Python 爬虫的两个重要技术路。
- 两个库的可用性都比较好,文档丰富,入门简单。
- 两者都没有处理 js,提交表单,应对验证码等功能(可扩展)。
不同点

3、Scrapy 爬虫的常用命令
C:\Users\LENOVO>scrapy -h
Scrapy 2.9.0 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy <command> -h" to see more info about a command
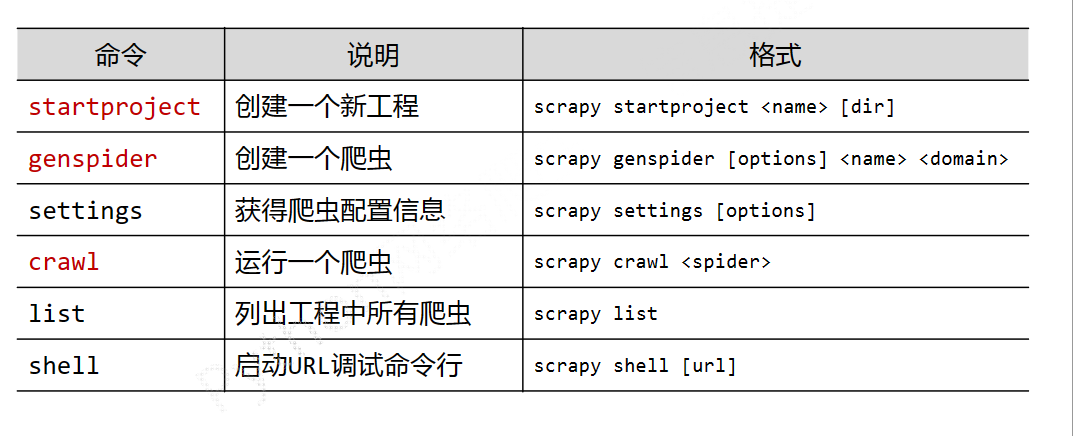
Scrapy 采用命令行来创建和运行爬虫,因为命令行相对比图形界面更容易自动化,适合脚本控制。本质上,Scrapy 是给程序员使用的。
4、Scrapy 爬取实例
程序结构设计:
- 建立一个 Scrapy 爬虫工程
scrapy startproject python123demo
生成的文件目录
python123demo 外层目录
│ items.py Items 代码模板(继承类)
│ middlewares.py Middlewares 代码模板(继承类)
│ pipelines.py Pipelines 代码模板(继承类)
│ settings.py Scrapy 爬虫的配置文件
│ __init__.py 初始化脚本
│
├─spiders Spiders 代码模板目录(继承类)
│ │ demo.py
│ │ __init__.py 初始化脚本
│ │
│ └─__pycache__
│ demo.cpython-39.pyc
│ __init__.cpython-39.pyc
│
└─__pycache__ 缓存目录,无需修改
settings.cpython-39.pyc
__init__.cpython-39.pyc
- 在工程中产生一个 Scrapy 爬虫
scrapy gensipider demo python123.io
该命令的作用是生成一个 demo 的 spider,在 spiders 目录下增加代码文件 demo.py。
- 配置产生的 spider 爬虫
打开 spiders 目录下 demo.py 代码文件
import scrapy
class DemoSpider(scrapy.Spider):
name = "demo"
# allowed_domains = ["python123.io"]
start_urls = ["http://python123.io/ws/demo.html"]
def parse(self, response):
fname = response.url.split("/")[-1]
with open(fname, "wb") as f:
f.write(response.body)
self.log("Save file %s." % fname)
parse() 方法用于处理响应,解析内容形成字典,发现新的URL爬取请求。
- 运行爬虫,获取网页
scrapy crawl demo
- 分析spiders 目录下 demo.py 代码文件

4、yield 关键字
yield = 生成器,包含 yield 语句的函数是一个生成器函数,生成器每次产生一个值(yield 语句),函数被冻结,被唤醒后再产生一个值,生成器是一个不断产生值得函数。
实例:
def gen(n):
for i in range(n):
yield i**2
for i in gen(5):
pring(i, "", end="")
0 1 4 9 16
分析这个实例,生成器每次调用 yield 位置产生一个值,直到函数执行结束。
那么大家想一想为什么要有生成器呢?
分析一下下面这实例:
def square(n):
ls = [i**2 for in range(n)]
return ls
for i in square(5):
print(i, "", end= "")
这个实例和上面那个实例其实一样的功能,都是求一组树的平方值,生成器相对比一次列出所有内容的优势:
- 更节省存储空间
- 响应更迅速
- 使用更灵活
- 如果 n= 1,10,10,100000... 或者更大呢?
5、Request,Response,Item
回顾一下 Scrapy 爬虫的使用步骤
- 创建一个工程和 spider 模板
- 编写 spider
- 编写 Item Pipeline
- 优化配置策略
在 Scrapy 框架下,这个四个步骤中会涉及到三个类,Request 类,Response 类,Item 类。
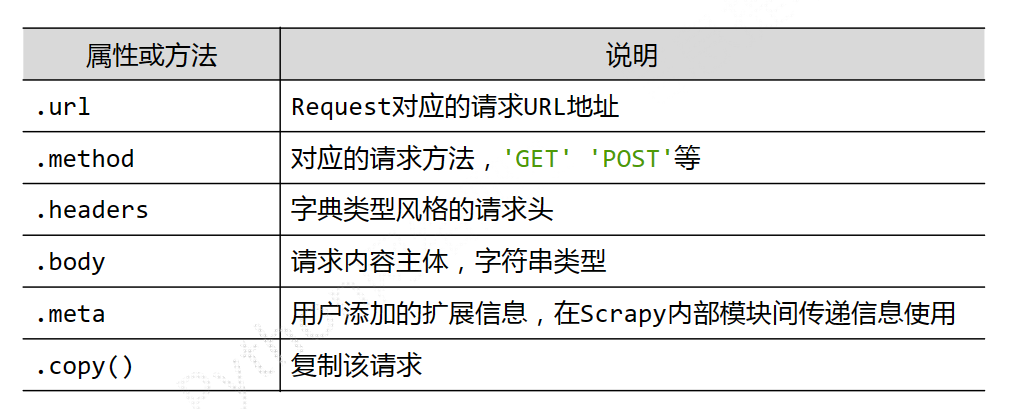
Request 类
class scrapy.http.Request()
Request 对象表示一个 http 请求,由 Spider 生成,由 downloader 执行。
Reqest 类的常见属性或方法介绍:
Response 类
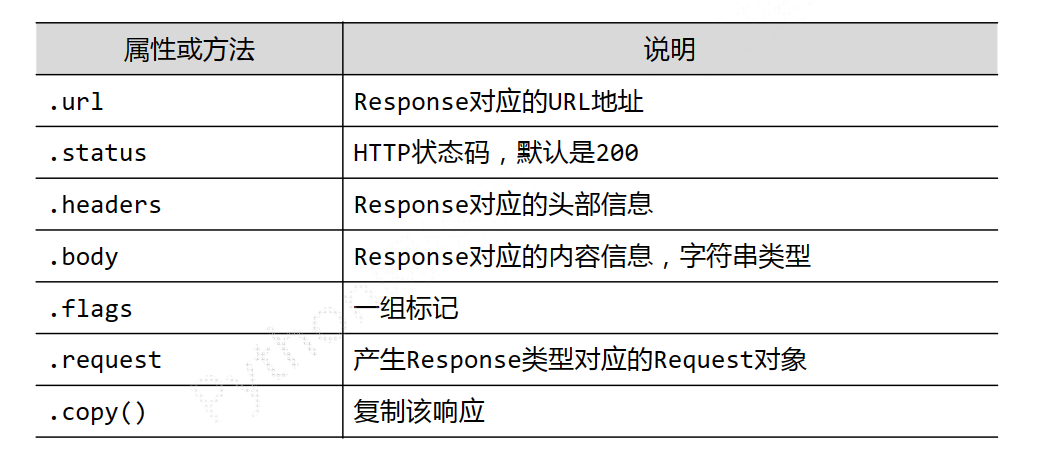
class scrapy.http.Response()
Response 对象表示一个 http 响应,由 downloader 生成,由 spider 处理。
Response 类常见的属性或方法介绍:
Item 类
class scrapy.item.Item()
Item 对象表示从一个 html 页面中提取的信息内容,由 spider 生成,由 Item pipeline 处理,Item 类似字典类型,可以按照字典类型操作。
下面介绍一下 Scrapy 爬虫的提取信息的方法都有哪些:
- Beautiful Soup
- lxml
- re
- Xpath Selector
- Css Selector
重点介绍一下 Css Selector 的基本使用,
<HTML>.css("a::attr(href)").extract()
标签名称 标签属性


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?