
代谢组学学习-基础知识(1)
最近要开始学习代谢组学,先从基础知识做起,了解轮廓,再了解模块,再分析细节。
首先,概念性问题
1. 什么是代谢组学?它能干什么?
代谢组学(Metabonomics/Metabolomics)是研究生物体被扰动后(基因/环境改变),其代谢产物(内源性代谢物质)种类,数量及其变化规律的科学。
代谢组学着重研究的是生物整体、器官或组织 的内源性代谢物质的 代谢途径 及其所受内在或外在因素的影响 和 随时间变化的规律。
通过揭示内在和外在因素影响下代谢整体的变化轨迹 来反映某种 病理生理过程中 所发生的的一系列生物事件。
2. 研究对象与层次?
研究对象:各种代谢路径的底物和产物的小分子代谢物(分子量<1000)
代谢物靶标分析:某一个或几个特定组分的定性和定量分析,如某一类结构、性质相关的化合物(氨基酸、有机酸、顺二醇类)或者某一代谢途径的所有中间产物或多条代谢途径的标志性组分。
代谢物指纹分析:同时对多个代谢物进行分析,不分离鉴定具体单一组分。
代谢轮廓分析:限定条件下对生物体内特定组织内的代谢产物的快速定性和半定量分析。
代谢组分析:对生物体或体内某一特定组织所包含的所有代谢物的定量分析,并研究该代谢物组在外界干预或病理生理条件下的动态变化规律。
代谢组:包含了 做实验部分+生物信息学分析部分

分类:1.非靶标代谢组
2.靶标代谢组(高通量/非高通量):绝对定量,高灵敏度,高特异性,需要标准品;
3.功能代谢组
3. 对我的课题有什么帮助?
3.1 实验部分
由于课题需要,目标:大致了解其原理+过程,质控需要了解以便于确认公司交付的数据合格,并保证能够发文章
3.1.1 样品采集:小鼠肝脏,对照组,模型组,给药组,每组6只重复以上,但为了能够剔除离群点的同时还能保证最低统计学数量(n=6),最好是每组7只以上,以7-10只为宜,为了性价比,8只较好。 小鼠取材后,立即将肝脏用生理盐水洗净(如果能够灌注用生理盐水冲血更好),大约200mg以上立即装于冻存管,放入液氮;冻存管内什么都不要加,也不要高压冻存管,订购后放置于干净的地方,比如在细胞间的超净台等。
3.1.2 样品前处理 :首先是样品运送:这部分交由公司做,样品交付时,使用干冰运输,完全覆盖样品袋,干冰量以运输天数+样品体积进行计算,公司会给出计算公式并提供人员+干冰来收取样本; 然后是公司进行样品前处理,这里在送样品之前,就必须先选定要做什么种类的代谢组,非靶向还是靶向?如果是非靶向则不需要用标准品。
代谢物提取:应该是不同样品处理方法不同,统一来说,需要合适的溶剂来溶解提取样本。 【来源:许国旺-代谢组学:方法与应用】

3.1.3 样品正式上机分析 ,用什么仪器检测?
这里有一个比较几个组学的分析,哈哈,很好玩。“基因/转录组=测核苷酸排列,4种核苷酸组成;蛋白组=测氨基酸排列,20种氨基酸组成;代谢组=测核苷酸+氨基酸+糖+有机酸+脂类等组成,每一类都有N种。”
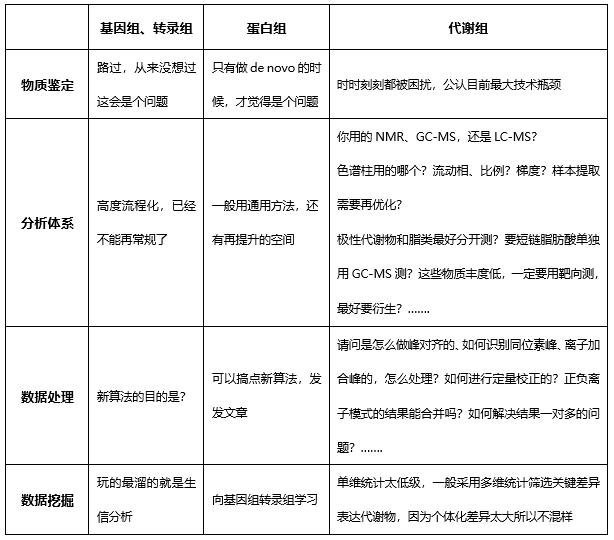
这次做的是非靶向代谢组(TM广靶),定性+半定量分析,主要目的是看肝脏里面有哪些代谢物发生了改变,等拿到结果可以再次做靶向定量代谢组具体测定某一个/类代谢物的含量,更为准确。
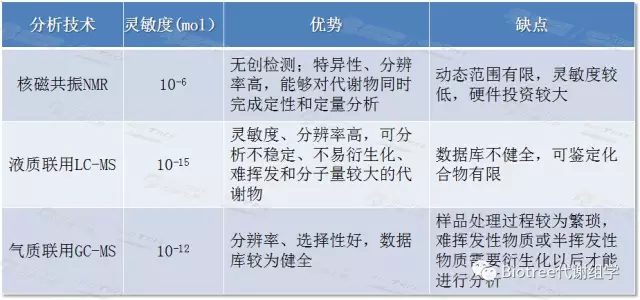
- 非靶向可以用UHPLC-QTOF-MS,UHPLC-QE-MS (这俩是液质联用) HC-TOF-MS,GC-Q-MS(这俩是气质谱联用,需要检测的目标物能够气化才行)
一般是使用液质联用【选择LC-MS做讨论的理由有三:(1)LC-MS平台对代谢物的覆盖最广、灵敏度更高。从文献中已报道的同时使用多种分析平台的数据来看,都是LC-MS获得的数据量显著更多;(2)相比于GC-MS,LC-MS一般无需衍生处理,分析平行性更好,更适合大规模样本的分析;(3)使用LC-MS平台的人员和机构更多,包括很多做NMR和GC-MS的代谢组学专家都已转向LC-MS。】
液质联用的仪器:UHPLC-QTOF-MS是超高效液相色谱-四极杆-飞行时间质谱仪,属于高分辨率,可以定性定量的仪器,总之应该是挺好的;
UHPLC-QE-MS(Agilent 1290 UHPLC-Thermo Q Exactive Focus/Plus/HF)这个没查到太多资料?【赛默飞Q Exactive,早期产品,分辨率典型,扫描速度一般;Focus Q Exactive前一款的简配,分辨率略低,扫描速度一般;Q Exactive HF是的款的加强版,分辨率提高,扫描速度加快】
- 靶向可以用UHPLC-QQQ-MS(Agilent 1290 UHPLC-6460 MS),还没用到,下次再查怎么检测?
3.1.4 怎么测?怎么鉴定?什么原理?
- 上机处理之后(具体的液相怎么调整流动相进行分离工作,质谱怎么工作?一时半会搞不懂先不查了)
- 首先,上机后会出来原始数据(似乎是叫原始谱图信息?),进行预处理(谱图峰匹配,或称峰对齐,使各样本数据得到正确比较,包括降噪,重叠峰解析,峰对齐,峰匹配,标准化,归一化等)后,开始比对数据库进行代谢物的鉴定,重中之重,如果代谢物鉴定错了,后面都没戏。【下图来源:许国旺-代谢组学:方法与应用】

代谢物怎么鉴定呢?了解一下过程+原理+难点,审核公司做的是否严谨并能得到公认,以下是一个科普
【首先,我们先讨论上文提到的代谢组目前最主要的技术瓶颈——代谢物鉴定。因为,物质鉴定是所有结果的基础,即使某检测方法能检测到的数据量再多、定量能力再灵敏、定量结果再精确,如果这个信号是代谢物张三还是代谢物李四不能确定的话,所获得的数据有何意义,也根本无从谈起表达是否有差异、功能是否有变化等后续问题。为了探讨这个问题,我们从业内人士反复提到的名词——代谢物标准品库说起。
标准品库,是指将纯化的、结构已经确证的代谢物的标准品(通常是商业化的),在某一特定分析检测体系下进行检测,获得该代谢物的标准结果信息,包括保留时间、分子量、二级(或多级)质谱图谱等。
在其他组学的分析领域中,通常不会听到,但在代谢组学里,这是个代谢物鉴定的门槛,而且是十分关键的门槛。为什么代谢组鉴定,对标准品库有这么高的要求呢?
下面这两个物质,元素组成完全不同,但是分子量非常相近,从小数点后第三位才开始不一样:
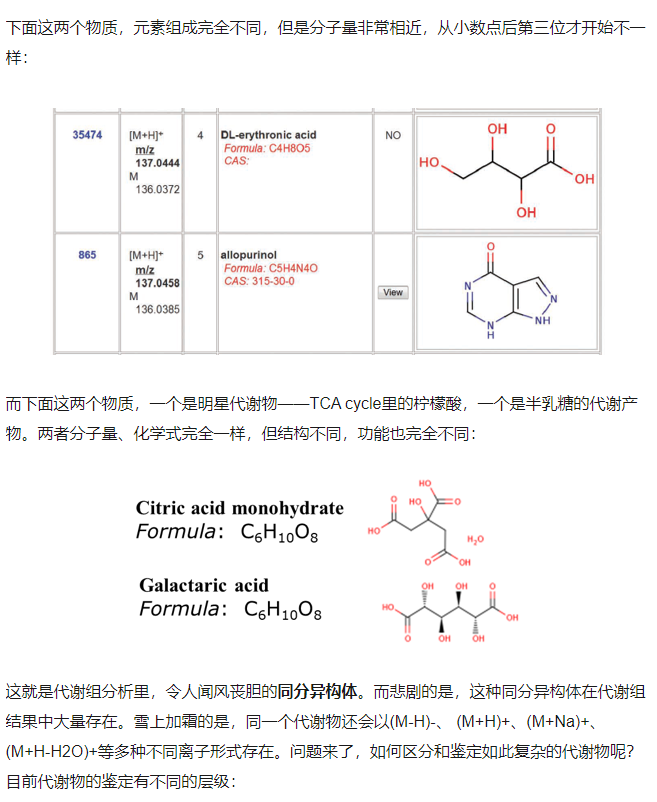
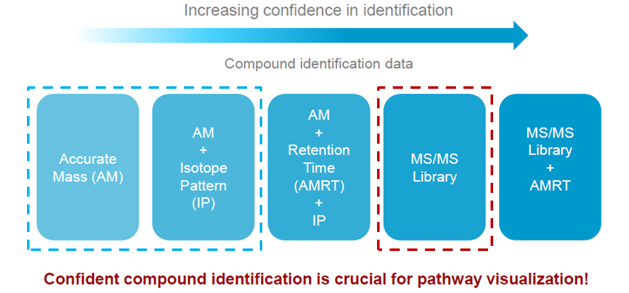
一般认为要鉴定到MS/MS这一级,即质谱的二级图谱水平才能有一定的准确性。这就要用到我们上面说到的标准品图谱库。然而,崩溃的是,对于LC-MS/MS分析,同一个代谢物在不同仪器平台上获得的二级图谱是不同的,仍然以柠檬酸为例: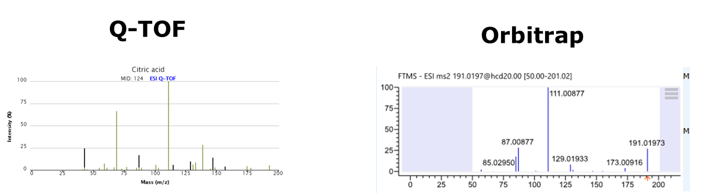
同一个仪器平台上,不同分析条件下获得的图谱也是不同的,以柠檬酸为例: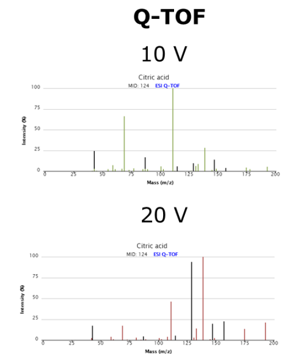
因此,标准品库是较难通用的,最好是在自己的平台上建,而且样本分析时也要采用建库相同的分析条件,这样获得的标准品图谱才能更准确地用于样本中代谢物的比对。所以,即使是标准品库,也分为自建标准品库和公共标准品库两种,两者的效果是有差异的,大家一定要注意。国内代谢组研究最权威的专家,对此的说法更具代表性:利用质谱数据库,但不能盲目相信网上数据库!来源:https://www.sohu.com/a/343456807_465960】
所以,得出的结论是,代谢物鉴定会受到 质谱的对照品数据库,仪器设备,同一仪器不同分析条件的影响,最好是使用公认的数据库较合适?
【一般代谢组学能检测出多少物质?
不同的质谱平台灵敏度及偏向性都不一样,而且不同平台之间具有互补性。一般来说GC/MS检测血清样品能准确定性的物质约200个左右,检测尿液样品定性的物质约200个左右,其他样品(如肝脏,粪便,肠道内容物)也在几百这个数量级。如果采用全二维GC/MS,物质的数量要更多,可达1千以上。LC/MS检测物质的数量要远比GC/MS多,但能准确定性和定量的不多,视不同的平台(TQ、QTOF等)能达到几十至2-3百个物质。】

【来源https://zhuanlan.zhihu.com/p/27386150】
【怎么监控公司做的数据是否准确呢?质控的信息有QC稳定、样品聚类,内标保留时间偏差小,物质的检出率高等,都可以说明实验没问题。 】
3. 其次,代谢物鉴定完毕后,可开始分析差异代谢物或标志代谢物了,这个很重要,可以看出组间差异,即在不同处理条件下,对代谢途径的影响;当然,组内差异也有,但需要focus on的是组间差异,且找的必须是组间>组内差异的代谢物,才能反映出给药对小鼠肝脏代谢的影响。
怎么找差异代谢物呢?
数据分析过程使用模式识别技术,包括非监督(unsupervised)学习方法和有监督(supervised)学习方法,对样本进行归类,采用相应的可视化技术直观地表达出来。下图来源【许国旺-代谢组学:方法与应用】

没看懂,总体上是说只有经过这样的模式分析方法,才能可视化数据,只有谱图得出的代谢物信息没什么用,需要进一步分析,
也就是说用这种计量分析工具,通过组间的对比,帮我们把代谢物经过特定条件干预后 是 如何变化的,变化规律,性质的变化,量的变化来显现出来。这样才能在注释后找到后续有价值的值得分析分析的信息。


