
深入研究Spark SQL的Catalyst优化器(原创翻译)
Spark SQL是Spark最新和技术最为复杂的组件之一。它支持SQL查询和新的DataFrame API。Spark SQL的核心是Catalyst优化器,它以一种新颖的方式利用高级编程语言特性(例如Scala的模式匹配和quasiquotes)来构建可扩展查询优化器。
我们最近发布了一篇关于Spark SQL的论文,该论文将出现在SIGMOD 2015(由Davies Liu,Joseph K. Bradley,Xiangrui Meng,Tomer Kaftan,Michael J. Franklin和Ali Ghodsi合著)中。在这篇博客文章中,我们重述该论文的部分内容,解释Catalyst优化器的内部功能以实现更广泛的应用。
为了实现Spark SQL,我们设计了一个新的可扩展优化器Catalyst,它基于Scala中的函数式编程结构。 Catalyst的可扩展设计有两个目的。首先,我们希望能够轻松地为Spark SQL添加新的优化技术和功能,尤其是为了解决我们在使用大数据时遇到的各种问题(例如,半结构化数据和高级分析)。其次,我们希望使外部开发人员能够扩展优化器 - 例如,通过添加数据源特定规则,可以将过滤或聚合的数据推送到外部存储系统,或者支持新的数据类型。 Catalyst支持基于规则和基于成本的优化。
Catalyst的核心是使用一个通用库生成树并使用规则操作这些树。在该框架的基础上,构建了用于关系查询处理库(例如表达式,逻辑查询计划)和处理执行查询不同阶段的几组规则:分析、逻辑优化、物理计划和代码生成,代码生成将部分查询编译为Java字节码。对于后者,使用了Scala特性quasiquotes,它可以很容易地在运行时由组合表达式生成代码。最后,Catalyst提供了几个公共扩展点,包括外部数据源和用户定义的类型。
树
Catalyst中的主要数据类型是由节点对象组成的树。 每个节点都有一个节点类型和零个或多个子节点。 新的节点类型在Scala中定义为TreeNode类的子类。 这些对象是不可变的,并可以使用函数转换来操作,如下一小节所讨论的。
一个简单的例子,使用非常简单的表达式语言描述三个节点类:
- Literal(值:Int):常数值
- Attribute(名称:String):输入行的属性,例如“x”
- Add(左:TreeNode,右:TreeNode):两个表达式的总和。
这些类可以用来构建树; 例如,表达式x +(1 + 2)的树将在Scala代码中表示如下:
1 Add(Attribute(x), Add(Literal(1), Literal(2)))

规则
可以使用规则来操作树,这些规则是从一棵树到另一棵树的函数。虽然规则可以在其输入树上运行任意代码(因为该树只是一个Scala对象),但最常见的方法是使用一组模式匹配函数来查找和替换具有特定结构的子树。
模式匹配是许多函数式语言的一个特性,它允许从代数数据类型的潜在嵌套结构中提取值。在Catalyst中,树提供了一种转换方法,该方法递归地在树的所有节点上应用模式匹配函数,将每个模式匹配转换为结果。例如,我们可以实现一个在常量之间相加???Add操作的规则,如下所示:
1 tree.transform { 2 case Add(Literal(c1), Literal(c2)) => Literal(c1+c2) 3 }
将此应用于x +(1 + 2)的树会产生新的树x + 3。这里关键是使用了Scala的标准模式匹配语法,它可用于匹配对象的类型和为提取的值(这里为c1和c2)提供名称。
传递给变换的模式匹配表达式是一个部分函数,这意味着它只需要匹配所有输入树的子集。 Catalyst将测试规则适用树的哪些部分,自动跳过并下降到不匹配的子树。这种能力意味着规则只需对给定适用优化的树进行推理,而对那些不适用的数不进行推理。因此,当新的操作符新增到系统中时,这些规则不需要修改。
规则(和一般的Scala模式匹配)可以在同一个变换调用中匹配多个模式,这使得一次实现多个转换来得非常简洁。
1 tree.transform { 2 case Add(Literal(c1), Literal(c2)) => Literal(c1+c2) 3 case Add(left, Literal(0)) => left 4 case Add(Literal(0), right) => right 5 }
实际上,规则可能需要多次执行才能完全转换树。Catalyst将规则形成批处理,并执行每个批处理至固定点,该固定点是树应用其规则后不发生改变。虽然规则运行到固定点意味着每个规则是简单且自包含,但这些规则仍会对树上产生较大的全局效果。在上面的例子中,重复的应用规则会持续折叠较大的树,比如(x + 0)+(3 + 3)。另一个例子,第一个批处理可以分析所有属性指定类型的表达式,而第二批处理可使用这些类型来进行常量折叠。在每批处理完毕后,开发人员还可以对新树进行规范性检查(例如,查看所有属性为指定类型),这些检查一般使用递归匹配来编写。
最后,规则条件及其本身可以包含任意的Scala代码。这使得Catalyst比领域特定语言在优化器上更强大,同时保持简洁特性。
根据经验,对不可变树的函数转换使得整个优化器非常易于推理和调试。规则也支持在优化器中并行化,尽管该特性还没有利用这个。
在Spark SQL中使用Catalyst
Catalyst的通用树转换框架分为四个阶段,如下所示:(1)分析解决引用的逻辑计划,(2)逻辑计划优化,(3)物理计划,(4)代码生成用于编译部分查询生成Java字节码。 在物理规划阶段,Catalyst可能会生成多个计划并根据成本进行比较。 所有其他阶段完全是基于规则的。 每个阶段使用不同类型的树节点; Catalyst包括用于表达式、数据类型以及逻辑和物理运算符的节点库。 这些阶段如下所示:
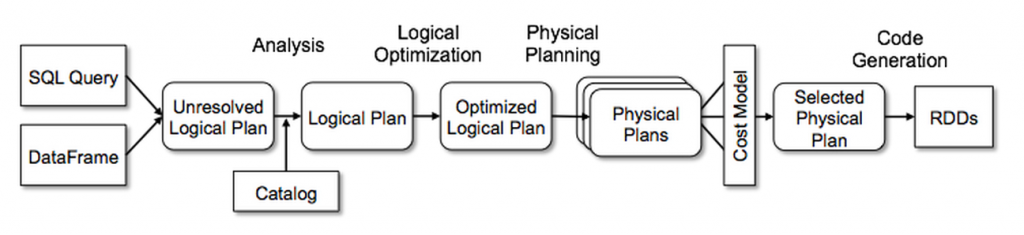
解析
sales”中列的类型,甚至列名是否有效,在查询表sale元数据之前这些都是未知的。如果不知道它的类型或没有将它匹配到输入表(或别名)时,那么该属性称为未解析。Spark SQL使用Catalyst规则和记录所有表元数据的Catalog对象来解析这些属性的。构建具有未绑定属性和数据类型的“未解析的逻辑计划”树后,然后执行以下规则:
1、从Catalog中查找名称关系
2、将命名属性(如col)映射到操作符的子项
3、将那些属性引用相同的值给它们一个唯一的ID(随后遇到如col=col时可以进行优化)
4、通过表达式传递和强制类型:例如,我们无法知道1+col的返回类型,直到解析出col并将其子表达式转换为兼容类型。
经过统计,解析器的规则大约有1000行代码。
逻辑计划优化
在逻辑优化阶段,逻辑计划应用了标准的基于规则的优化。(基于成本的优化通过规则生成多个计划,然后计算其成本来执行。)这些优化包括常量折叠、谓词下推、项目裁剪、空值传播、布尔表达式简化以及其他规则。总的来说,为各种情况添加规则非常简单。例如,当我们将固定精度的DECIMAL类型添加到Spark SQL时,我们想要以较低精度的方式优化DECIMAL的聚合(例如求和和平均值);只需要12行代码编写一个规则便可在SUM和AVG表达式中找到该数,然后将它们转换为未缩放的64位LONG,然后进行聚合,最后将结果转换回来。这个规则的简化版本,只能优化SUM表达式如下所示:
1 object DecimalAggregates extends Rule[LogicalPlan] { 2 /** Maximum number of decimal digits in a Long */ 3 val MAX_LONG_DIGITS = 18 4 def apply(plan: LogicalPlan): LogicalPlan = { 5 plan transformAllExpressions { 6 case Sum(e @ DecimalType.Expression(prec, scale)) 7 if prec + 10 <= MAX_LONG_DIGITS => 8 MakeDecimal(Sum(UnscaledValue(e)), prec + 10, scale) } 9 }
再举一个例子,一个12行代码的规则通过简单的正则表达式将LIKE表达式优化为String.startsWith或String.contains调用。在规则中使用任意Scala代码使得这些优化易于表达,而这些规则超越了子树结构的模式匹配。
经过统计,逻辑优化规则有800行代码。
物理计划
在物理计划阶段,Spark SQL使用逻辑计划生成一个或多个物理计划,这个过程采用了匹配Spark执行引擎的物理运算符。然后使用成本模型选择计划。目前,基于成本的优化仅用于选择连接算法:对于已知很小的关系,Spark SQL使用Spark中的点对点广播工具进行广播连接。不过,该框架支持更深入地使用基于成本的优化,因为可以使用规则对整棵树进行递归估计。因此,我们打算在未来实施更加丰富的基于成本的优化。
物理计划还执行基于规则的物理优化,例如将管道项目或过滤器合并到一个Spark映射操作中。另外,它可以将操作从逻辑计划推送到支持谓词或项目下推的数据源。我们将在后面的章节中描述这些数据源的API。
总的来说,物理计划规则大约有500行代码。
代码生成
查询优化的最后阶段涉及生成Java字节码用于在每台机器上运行。由于Spark SQL经常在内存数据集上运行,其中处理受CPU限制,我们希望Spark SQL支持代码生成以加快执行速度。尽管如此,代码生成引擎的构建通常很复杂,特别是编译器。Catalyst依靠Scala语言的特殊功能quasiquotes来简化代码生成。 Quasiquotes允许在Scala语言中对抽象语法树(AST)进行编程式构建,然后在运行时将其提供给Scala编译器以生成字节码。使用Catalyst将表示SQL表达式的树转换为Scala代码的AST用于描述表达式,然后编译并运行生成的代码。
作为一个简单的例子,参考第4.2节介绍的Add、Attribute和Literal树节点可以写成(x + y)+1表达式。如果没有使用代码生成,这些表达式必须遍历Add、Attribute和Literal节点树行走才能解释每行数据。这会引入大量的分支和虚函数调用,从而减慢执行速度。如果使用了代码生成,可以编写一个函数将特定的表达式树转换为Scala AST,如下所示:
1 def compile(node: Node): AST = node match { 2 case Literal(value) => q"$value" 3 case Attribute(name) => q"row.get($name)" 4 case Add(left, right) => q"${compile(left)} + ${compile(right)}" 5 }
以q开头的字符串是quasiquotes,虽然它们看起来像字符串,但它们在编译时由Scala编译器解析,并代表其代码的AST。 Quasiquotes用$符号表示法将变量或其他AST拼接到它们中。例如,文字(1)将成为1的Scala表达式的AST,而属性(“x”)变为row.get(“x”)。最后,类似Add(Literal(1),Attribute(“x”))的树成为像1 + row.get(“x”)这样的Scala表达式的AST。
Quasiquotes在编译时进行类型检查,以确保只替换合适的AST或文字,使得它们比字符串连接更有用,并且直接生成Scala AST,而非在运行时运行Scala语法分析器。此外,它们是高度可组合的,因为每个节点的代码生成规则不需要知道其子节点返回的树是如何构建的。最后,如果Catalyst缺少表达式级别的优化,则由Scala编译器对结果代码进行进一步优化。下图显示quasiquotes生成代码其性能类似于手动优化的程序。
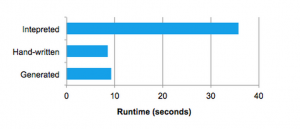
我们发现quasiquotes非常接近于代码生成,并且发现即使是Spark SQL的新贡献者也可以快速为新类型的表达式添加规则。 Quasiquotes也适用于在本地Java对象上运行的目标:当从这些对象访问字段时,可以直接访问所需字段,而不必将对象复制成Spark SQL 行,并使用行访问器方法。最后,将代码生成的评估与对尚未生成代码的表达式的解释评估结合起来很简单,因为编译的Scala代码可以直接使用到表达式解释器中。
Catalyst生成器总共有大约700行代码。
这篇博客文章介绍了Spark SQL的Catalyst优化器内部原理。 通过这种新颖、简单的设计使Spark社区能够快速建立原型、实现和扩展引擎。 你可以在这里阅读其余的论文。
您还可以从以下内容中找到有关Spark SQL的更多信息:
- Spark SQL and DataFrame Programming Guide from Apache Spark
- Data Source API in Spark presentation by Yin Huai
- Introducing DataFrames in Spark for Large Scale Data Science by Reynold Xin
- Beyond SQL: Speeding up Spark with DataFrames by Michael Armbrust
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。如果觉得还有帮助的话,可以点一下右下角的【推荐】,希望能够持续的为大家带来好的技术文章!想跟我一起进步么?那就【关注】我吧。

