
Databricks缓存提升Spark性能--为什么NVMe固态硬盘能够提升10倍缓存性能(原创翻译)
我们兴奋的宣布Databricks缓存的通用可用性,作为统一分析平台一部分的 Databricks 运行时特性,它可以将Spark工作负载的扫描速度提升10倍,并且这种改变无需任何代码修改。
1、在本博客中,我们将介绍这个新特性的两个主要特点:易用性和性能。
2、不同于Spark显示缓存,Databricks缓存能够自动地为用户缓存热输入数据,并且在集群中负载均衡。利用NVMe SSD硬件的先进性能和最先进的压缩技术,它能够将交互式和报告工作的负载性能提升10倍。更重要的是它缓存的数据量是Spark的缓存数量的30多倍。
Spark显式缓存
Spark中一个关键特性是显式缓存。它是一个多功能的工具,因为它可以用于存放任意计算结果(包括输入和中间结果),以便它们可以重复使用。例如,迭代机器学习算法的实现可以选择缓存特征化数据,并且每次迭代将从内存中读取这些数据。
一种特别重要和广泛使用的方式就是缓存扫描操作的结果。通过这种方式可以避免用户低速率地读取远程数据。因此,许多打算重复运行相同或类似工作量的用户决定花费额外的开发时间来手动优化他们的应用程序,通过指示Spark确切缓存什么文件以及何时进行缓存,从而实现“显式缓存”。
对于Spark缓存有如上功能,它还有一些缺点。首先,把数据保存在主内存中时,它需要占用内存空间,而这些空间能够更好用于其他用途,例如,用于Shuffle或者哈希表。其次,当数据缓存在磁盘,读取需要反序列化--该过程太慢以至于无法充分利用NVMe SSD通常所提供的高读取带宽。
最后,由于需要提前并详细指定需要缓存的数据,这个对于那些想交互地导出数据或者创建报告是一个挑战。虽然Spark缓存提供数据工程师所有调优开关,数据科学经常发现推断这些内存太困难了,特别是在多租户的设置中,工程师仍然需要尽快返回结果以保证迭代时间更短。
NVMe SSD面临的调整
固态硬盘或者SSD已经成为标准存储技术。尽管最初以其随机搜索低延迟闻名,但在过去的几年中,SSD也大幅度提供了读写吞吐量。
NVMe接口创建用于克服SATA和ARCI设计的极限,并且允许最大可能使用现代SSD所提供出色的性能。这包括利用基于闪存存储设置的内部并行性和极低读延迟的能力。NVMe使用多种长命令队列以及其他增强功能,允许驱动器高效处理海量并发请求。这种面向并行的架构完美地补充了现代多核CPU和如Spark数据处理系统的并行线。
通过NVMe接口,SSD比低速磁盘驱动器在属性和性能上更加接近主内存。因此它们是存储缓存数据的理想地方。
然而为完全利用NVMe SSD的潜力,仅仅把远程数据复制到本地存储是远远不够。我们在AWS i3实例所进行的实验表明当从本地SSD读取常用文件格式时,它只是使用一部分可用的I/O带宽。
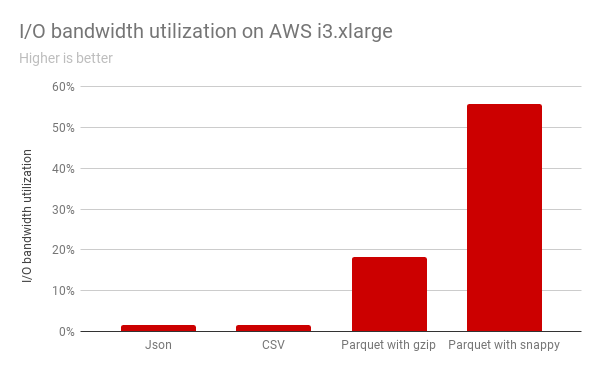
上图显示了在Spark针对EC2 i3实例类型的本地NVMe SSD的I/O带宽利用率。根据图示,现有数据格式不能充分利用I/O带宽,CPU密集解码速度无法跟上SSD的速度。
自适应运行
当设计Databricks缓存时,我们不仅关注于实现优化的读性能,并且关注于创建一种“自适应运行”的方案,该方案无需用户任何参与。该缓存考虑到:
1、自动选择数据缓存----无论何时访问远程文件时,该数据转码副本会立即存放到缓存中
2、替换长时间未使用的数据----当磁盘空间不足时,缓存自动删除最近最少使用的数据
3、负载均衡----缓存的数据均匀地分发到集群的所有节点上,并且自动扩展和/或调整不同节点不均匀使用情况
4、数据安全----在缓存数据通过同样的方式与临时文件保持加密,例如Shuffle文件
5、数据更新----缓存能够自动发现在远程地方文件的增加和删除,并且显示数据最新的状态
从Databricks运行时3.3以来,在AWS i3实例类型中所有集群都预置并默认启用Databricks内存。由于这种实例类型具有较高的写入吞吐量,数据能够转码并保存在缓存中,而无需降低读取远程数据的查询性能。喜欢选择其他类型工作节点的用户可以使用Spark配置来启用缓存(请参考文档以了解更多细节)。
对于那些需预先缓存所需要数据的用户,我们实现了CACHE SELECT命令。它将提供选择部分数据装载到缓存中。用户可以指定垂直(如:选择列)或者水平(如:满足查询条件的行)切片数据保存在缓存中。
性能
为了充分利用NVMe SSD,不是采取直接缓存输入的“原始数据”,而是新功能会自动将数据转换为高度优化新的临时磁盘缓存格式,该功能提供了出色的解码速度,从而获得了更佳的I/O带宽利用率。这种转码是异步操作,从而把数据加载到缓存的查询开销降低到最小。
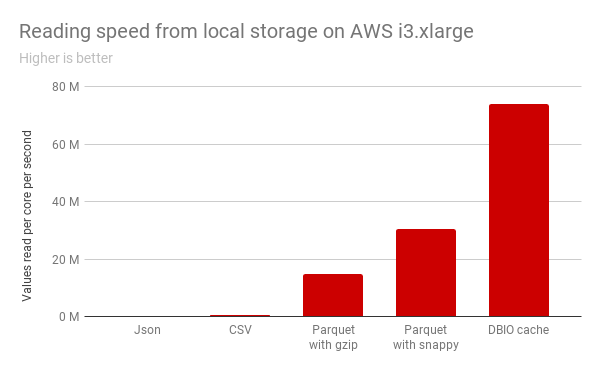
增强读取性能(在前面所提到的通常在访问远程数据避免高延迟的能力)导致了各种查询速度取得了显著的提升。例如,在如下TPC-DS查询的子集,相对于从AWS S3读取Parquet数据,我们看到在每个简单查询都取得了持续的改进,并且在查询53中速度有5.7倍的提升。
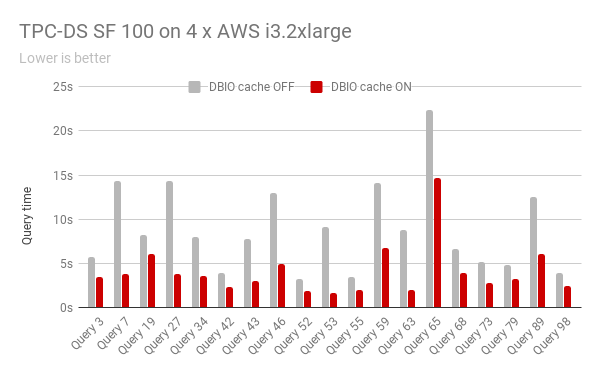
来自于我们私人测试程序的一些客户工作中,我们看到性能有10倍的提升。
对比Spark缓存和Databricks缓存
Spark缓存和Databricks缓存可以搭配使用,事实上,它们之间相得益彰:Spark缓存提供存储任意中间计算结果数据的能力,而Databricks缓存提供了对输入数据提供自动和出色的性能。
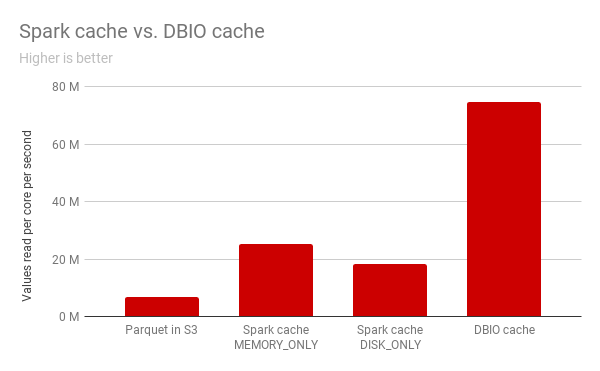
在我们的实验中,Databricks缓存相对于Spark缓存的DISK_ONLY读模式达到了4倍的速度。对比MEMORY_ONLY模式,Databricks缓存仍然提供了3倍的加速,而且还保持了较小的内存占用。
Databricks缓存配置
对于运行Databricks运行时3.3+版本的所欲AWS i3实例类型,对于所有Parquet文件缓存选择默认开启,并且缓存功能也可以与Databricks delta无缝协作。
要在其他Azure或AWS实例类型中使用新缓存,在集群配置中需要设置如下配置参数:
1 spark.databricks.io.cache.enabled true
2 spark.databricks.io.cache.maxDiskUsage "{DISK SPACE PER NODE RESERVED FOR CACHED DATA}"
3 spark.databricks.io.cache.maxMetaDataCache "{DISK SPACE PER NODE RESERVED FOR CACHED METADATA}"
结论
Databricks缓存为Databricks用户提供了大量好处--无论是易用性还是查询性能。它可以与Spark缓存进行混合搭配结合,使用最优的工具来完成任务。随着即将更进一步的性能提升和对其他数据格式的支持,Databricks缓存将成为各种工作负载的主要工具。
将来,我们讲发布更多性能提升和扩展支持其他文件格式的功能。
要尝试此新功能,请立即在我们统一分析平台选择一个i3实例类型的集群。
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。如果觉得还有帮助的话,可以点一下右下角的【推荐】,希望能够持续的为大家带来好的技术文章!想跟我一起进步么?那就【关注】我吧。

