【UE4 C++ 基础知识】<5> 容器——TArray
概述
- TArray 是UE4中最常用的容器类。其速度快、内存消耗小、安全性高。
- 其设计时未考虑扩展问题,因此建议在实际操作中勿使用 新建(new) 和 删除(delete) 创建或销毁 TArray 实例
- TArray元素为数值类型时,被销毁时其中的元素也将被销毁。若在另一TArray中创建TArray变量,其元素将复制到新变量中,且不会共享状态。
创建
TArray<int32> IntArray;
添加元素
-
init填充多个相同值IntArray.Init(10, 5); //==>[10,10,10,10,10] -
Add可添加重复元素,添加时会创建临时变量再复制 -
AddUnique不可添加重复元素 -
Emplace添加时不会创建临时变量,性能好于AddTArray<FString> StrArr; StrArr.Add(TEXT("Hello")); IntArray.AddUnique(TEXT("Hello")); StrArr.Emplace(TEXT("World")); //==>["Hello","World"] -
Append可一次性添加其他 TArray 中的多个元素,,或者指向常规C数组的指针及该数组的大小FString Arr[] = { TEXT("of"), TEXT("Tomorrow") }; StrArr.Append(Arr, ARRAY_COUNT(Arr)); //==>["Hello","World","of","Tomorrow"] -
Insert在给定索引处添加单个元素或元素数组的副本StrArr.Insert(TEXT("Brave"), 1); //==>["Hello","Brave","World","of","Tomorrow","!"] -
SetNum函数可直接设置数组元素的数量。- 如新数量大于当前数量,则使用元素类型的默认构造函数新建元素
- 如新数量小于当前数量,SetNum 将移除元素。
StrArr.SetNum(8); //==>["Hello","Brave","World","of","Tomorrow","!","",""] StrArr.SetNum(6); //==>["Hello","Brave","World","of","Tomorrow","!"]
迭代
-
范围-for(ranged-for)功能FString JoinedStr; for (auto& Str :StrArr) { JoinedStr += Str; JoinedStr += TEXT(" "); } // JoinedStr == "Hello Brave World of Tomorrow !" -
常规forfor (int32 Index = 0; Index != StrArr.Num(); ++Index) { JoinedStr += StrArr[Index]; JoinedStr += TEXT(" "); } -
迭代器
函数 CreateIterator 和 CreateConstIterator 可分别用于元素的读写和只读访问for (auto It = StrArr.CreateConstIterator(); It; ++It) { JoinedStr += *It; JoinedStr += TEXT(" "); }
排序
-
SortStrArr.Sort(); //==>["!","Brave","Hello","of","Tomorrow","World"] -
二进制谓词提供不同的排序语意
StrArr.Sort([](const FString& A, const FString& B){ return A.len() < B.len(); }); //按字符串长度排序, ==>["!","of","Hello","Brave","World","Tomorrow"] -
HeapSort
无论带或不带二元谓词,均可用于执行对排序。是否选择使用它则取决于特定数据和与 Sort 函数之间的排序效率对比。和 Sort 一样,HeapSort 并不稳定StrArr.HeapSort([](const FString& A, const FString& B) { return A.Len() < B.Len(); }); //==>["!","of","Hello","Brave","World","Tomorrow"] -
StableSort可在排序后保证等值元素的相对排序。StableSort 作为归并排序实现StrArr.StableSort([](const FString& A, const FString& B) { return A.Len() < B.Len(); }); //==>["!","of","Brave","Hello","World","Tomorrow"]
查询
-
Num查询元素数量int32 Count = StrArr.Num(); // Count == 6 -
GetData函数返回指向数组中元素的指针,该操作直接访问数组内存。
仅在数组存在且未执行更改数组的操作时,此指针方有效。仅 StrPtr 的首个 Num 指数才可被解除引用FString* StrPtr = StrArr.GetData(); // StrPtr[0] == "!" // StrPtr[1] == "of" // ... // StrPtr[5] == "Tomorrow" // StrPtr[6] - undefined behavior -
GetTypeSize 获取单个元素的大小
uint32 ElementSize = StrArr.GetTypeSize(); // ElementSize == sizeof(FString) -
[]索引运算符获取元素,返回的是一个引用,可用于操作数组中的元素(假定数组不为常量):FString Elem1 = StrArr[1]; // Elem1 == "of" StrArr[3] = StrArr[3].ToUpper(); //==>["!","of","Brave","HELLO","World","Tomorrow"] -
使用 IsValidIndex 函数询问容器,可确定特定索引是否有效(0≤=索引<Num())
bool bValidM1 = StrArr.IsValidIndex(-1);// bValidM1 == false bool bValid0 = StrArr.IsValidIndex(0); // bValid0 == true bool bValid5 = StrArr.IsValidIndex(5); // bValid5 == true bool bValid6 = StrArr.IsValidIndex(6); // bValid6 == false -
Last函数从数组末端反向索引,索引默认为零。 -
Top返回最后一个元素,不接受索引FString ElemEnd = StrArr.Last(); // ElemEnd == "Tomorrow" FString ElemEnd0 = StrArr.Last(0); // ElemEnd0 == "Tomorrow" FString ElemEnd1 = StrArr.Last(1); // ElemEnd1 == "World" FString ElemTop = StrArr.Top(); // ElemTop == "Tomorrow" -
Contains查询是否包含特定元素bool bHello = StrArr.Contains(TEXT("Hello")); // bHello == true bool bGoodbye = StrArr.Contains(TEXT("Goodbye")); // bGoodbye == false -
ContainsByPredicate查询是否包含与特定谓词匹配的元素bool bLen5 = StrArr.ContainsByPredicate([](const FString& Str){ return Str.Len() == 5; }); // bLen5 == true bool bLen6 = StrArr.ContainsByPredicate([](const FString& Str){ return Str.Len() == 6; }); // bLen6 == false -
Find确定元素是否存在并返回找到的首个元素的索引int32 Index; if (StrArr.Find(TEXT("Hello"), Index)){ // Index == 3 } int32 Index2 = StrArr.Find(TEXT("Hello")); // Index2 == 3 int32 IndexNone = StrArr.Find(TEXT("None")); // IndexNone == INDEX_NONE(实质上是-1) -
FindLast确定元素是否存在并返回找到的最末元素的索引int32 IndexLast; if (StrArr.FindLast(TEXT("Hello"), IndexLast)){ // IndexLast == 3, because there aren't any duplicates } int32 IndexLast2 = StrArr.FindLast(TEXT("Hello")); // IndexLast2 == 3 -
IndexOfByKey返回首个匹配到的元素的索引;如果没有找到元素,则返回INDEX_NONE-
IndexOfByKey 工作方式相似,但允许元素与任意对象进行对比。通过Find函数进行的搜索开始前,参数将被实际转换为元素类型(此例中的FString)。使用IndexOfByKey ,则直接对”键”进行对比,以便在键类型无法直接转换到元素类型时照常进行搜索。
-
IndexOfByKey 可用于运算符 == (ElementType、KeyType)存在的任意键类型;然后这将被用于执行比较。
int32 Index = StrArr.IndexOfByKey(TEXT("Hello")); // Index == 3 -
-
IndexOfByPredicate函数用于查找与特定谓词匹配的首个元素的索引;如未找到,同样返回特殊 INDEX_NONE 值:int32 Index = StrArr.IndexOfByPredicate([](const FString& Str){ return Str.Contains(TEXT("r")); }); // Index == 2 -
FindByKey可以将元素和任意对象对比,并返回首个匹配到的元素的指针,如果未匹配到,则返回nullptrauto* OfPtr = StrArr.FindByKey(TEXT("of"))); // OfPtr == &StrArr[1] auto* ThePtr = StrArr.FindByKey(TEXT("the"))); // ThePtr == nullptr -
FindByPredicate的使用方式和IndexOfByPredicate相似,不同的是,它的返回值是指针,而不是索引auto* Len5Ptr = StrArr.FindByPredicate([](const FString& Str){ return Str.Len() == 5; }); // Len5Ptr == &StrArr[2] auto* Len6Ptr = StrArr.FindByPredicate([](const FString& Str){ return Str.Len() == 6; }); // Len6Ptr == nullptr -
FilterByPredicate函数可获取与特定谓词匹配的元素数组auto Filter = StrArray.FilterByPredicate([](const FString& Str){ return !Str.IsEmpty() && Str[0] < TEXT('M'); });
移除元素
-
Remove函数族用于移除数组中的元素。TArray<int32> ValArr; int32 Temp[] = { 10, 20, 30, 5, 10, 15, 20, 25, 30 }; ValArr.Append(Temp, ARRAY_COUNT(Temp)); //==>[10,20,30,5,10,15,20,25,30] ValArr.Remove(20); //==>[10,30,5,10,15,25,30] -
RemoveSingle也可用于擦除数组中的首个匹配元素。ValArr.RemoveSingle(30); //==>[10,5,10,15,25,30] -
RemoveAt函数也可用于按照从零开始的索引移除元素。
可使用IsValidIndex确定数组中的元素是否使用计划提供的索引,将无效索引传递给此函数会导致运行时错误:ValArr.RemoveAt(2); // 移除下标为2的元素, ==>[10,5,15,25,30] ValArr.RemoveAt(99); // 引发错误,越界 -
RemoveAll也可用于函数移除与谓词匹配的元素。ValArr.RemoveAll([](int32 Val) { return Val % 3 == 0; }); //移除为3倍数的所有数值, ==> [10,5,25] -
RemoveSwap、RemoveAtSwap、RemoveAllSwap
移动过程存在开销。如不需要剩余元素排序,可使用 RemoveSwap、RemoveAtSwap 和 RemoveAllSwap 函数减少此开销。此类函数的工作方式与其非交换变种相似,不同之处在于其不保证剩余元素的排序,因此可更快地完成任务:TArray<int32> ValArr2; for (int32 i = 0; i != 10; ++i) ValArr2.Add(i % 5); //==>[0,1,2,3,4,0,1,2,3,4] ValArr2.RemoveSwap(2); //==>[0,1,4,3,4,0,1,3] ValArr2.RemoveAtSwap(1); //==>[0,3,4,3,4,0,1] ValArr2.RemoveAllSwap([](int32 Val) { return Val % 3 == 0; }); //==>[1,4,4] -
Empty函数移除数组中所有元素ValArr2.Empty(); //==>[] -
Reset与Empty函数类似,该函数将不释放内存。ValArr2.Reset (); //==>[]
运算符
数组是常规数值类型,可使用标准复制构造函数或赋值运算符进行复制。由于数组严格拥有其元素,复制数组的操作是深层的,因此新数组将拥有其自身的元素副本
TArray<int32> ValArr3;
ValArr3.Add(1);
ValArr3.Add(2);
ValArr3.Add(3);
auto ValArr4 = ValArr3; // ValArr4 == [1,2,3];
ValArr4[0] = 5; // ValArr4 == [5,2,3]; ValArr3 == [1,2,3];
-
+=运算符 可替代Append函数进行数组连接ValArr4 += ValArr3; //==>[5,2,3,1,2,3] -
MoveTemp函数可将一个数组中的内容移动到另一个数组中,源数组将被清空ValArr3 = MoveTemp(ValArr4); // ValArr3 == [5,2,3,1,2,3]; ValArr4 == [] -
==运算符和!=运算符可对数组进行比较。
元素的排序很重要:只有元素的顺序和数量相同时,两个数组才被视为相同TArray<FString> FlavorArr1; FlavorArr1.Emplace(TEXT("Chocolate")); FlavorArr1.Emplace(TEXT("Vanilla")); // FlavorArr1 == ["Chocolate","Vanilla"] auto FlavorArr2 = FlavorArr1; // FlavorArr2 == ["Chocolate","Vanilla"] bool bComparison1 = FlavorArr1 == FlavorArr2; // bComparison1 == true for ( auto& Str : FlavorArr2 ) { Str = Str.ToUpper(); } // FlavorArr2 == ["CHOCOLATE","VANILLA"] bool bComparison2 = FlavorArr1 == FlavorArr2; // bComparison2 == true,因为FString的对比忽略大小写 Exchange(FlavorArr2[0], FlavorArr2[1]); // FlavorArr2 == ["VANILLA","CHOCOLATE"] bool bComparison3 = FlavorArr1 == FlavorArr2; // bComparison3 == false,因为两个数组内的元素顺序不同
堆
TArray 拥有支持二叉堆数据结构的函数。堆是一种二叉树,其中父节点的排序等于或高于其子节点。作为数组实现时,树的根节点位于元素0,索引N处节点的左右子节点的指数分别为2N+1和2N+2。子节点彼此间不存在特定排序。
-
Heapify函数可将现有数组转换为堆。此会重载为是否接受谓词,无谓词的版本将使用元素类型的运算符<确定排序:树中的节点按堆化数组中元素的排序从左至右、从上至下读取。
注意:数组在转换为堆后无需排序。排序数组也是有效堆,但堆结构的定义较为宽松,同一组元素可存在多个有效堆。TArray<int32> HeapArr; for (int32 Val = 10; Val != 0; --Val){ HeapArr.Add(Val); } // HeapArr == [10,9,8,7,6,5,4,3,2,1] HeapArr.Heapify(); // HeapArr == [1,2,4,3,6,5,8,10,7,9]
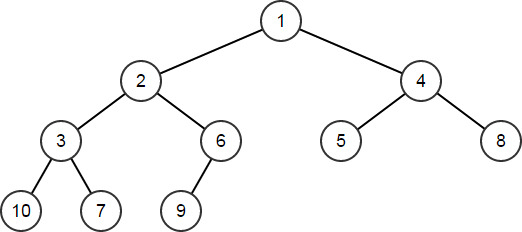
-
HeapPush函数可将新元素添加到堆,对其他节点进行重新排序,以对堆进行维护HeapArr.HeapPush(4); // HeapArr == [1,2,4,3,4,5,8,10,7,9,6]
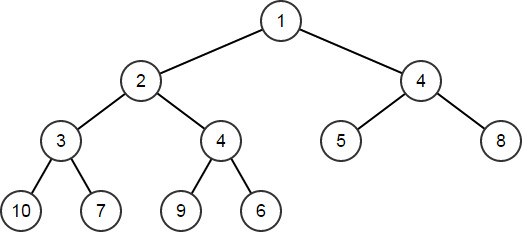
-
HeapPop和HeapPopDiscard函数用于移除堆的顶部节点。
这两个函数的区别在于前者引用元素的类型来返回顶部元素的副本,而后者只是简单地移除顶部节点,不进行任何形式的返回。两个函数得出的数组变更一致,重新正确排序其他元素可对堆进行维护int32 TopNode; HeapArr.HeapPop(TopNode); // TopNode == 1; HeapArr == [2,3,4,6,4,5,8,10,7,9]
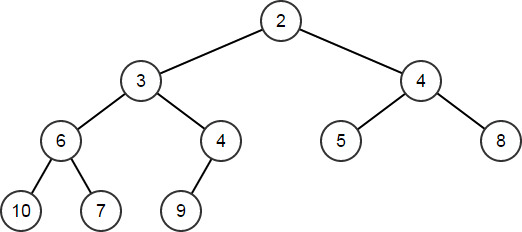
-
HeapRemoveAt将删除数组中给定索引处的元素,然后重新排列元素,对堆进行维护HeapArr.HeapRemoveAt(1); // HeapArr == [2,4,4,6,9,5,8,10,7]
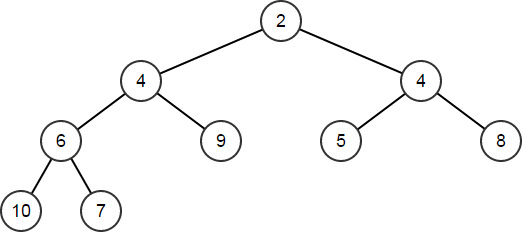
-
HeapTop函数可查看堆的顶部节点,无需变更数组int32 Top = HeapArr.HeapTop(); // Top == 2
- 以下较为底层
Slack
因为数组的尺寸可进行调整,因此它们使用的是可变内存量。为避免每次添加元素时需要重新分配,分配器通常会提供比需求更多的内存,使之后进行的Add调用不会因为重新分配而出现性能损失。同样,删除元素通常不会释放内存。
-
容器中现有的元素数量和下次分配之前可添加的元素数量之差成为Slack
-
默认构建的数组不分配内存,slack初始为0。
-
GetSlack函数即可找出数组中的slack量,相当于Max() - Num() -
Max函数可获取到容器重新分配之前数组可保存的最大元素数量。 -
分配器确定重新分配后容器中的Slack量。因此 Slack 不是常量。
TArray<int32> SlackArray; // SlackArray.GetSlack() == 0 // SlackArray.Num() == 0 // SlackArray.Max() == 0 SlackArray.Add(1); // SlackArray.GetSlack() == 3 // SlackArray.Num() == 1 // SlackArray.Max() == 4 SlackArray.Add(2); SlackArray.Add(3); SlackArray.Add(4); SlackArray.Add(5); // SlackArray.GetSlack() == 17 // SlackArray.Num() == 5 // SlackArray.Max() == 22 -
虽然无需管理Slack,但可管理Slack对数组进行优化,以满足需求。
例如,如需要向数组添加大约100个新元素,则可在添加前确保拥有可至少存储100个新元素的Slack,以便添加新元素时无需分配内存。上文所述的Empty函数接受可选Slack参数SlackArray.Empty(); // SlackArray.GetSlack() == 0 // SlackArray.Num() == 0 // SlackArray.Max() == 0 SlackArray.Empty(3); // SlackArray.GetSlack() == 3 // SlackArray.Num() == 0 // SlackArray.Max() == 3 SlackArray.Add(1); SlackArray.Add(2); SlackArray.Add(3); // SlackArray.GetSlack() == 0 // SlackArray.Num() == 3 // SlackArray.Max() == 3 -
Reset函数与Empty函数类似,不同之处是若当前内存分配已提供请求的Slack,该函数将不释放内存。但若请求的Slack较大,其将分配更多内存:SlackArray.Reset(0); // SlackArray.GetSlack() == 3 // SlackArray.Num() == 0 // SlackArray.Max() == 3 SlackArray.Reset(10); // SlackArray.GetSlack() == 10 // SlackArray.Num() == 0 // SlackArray.Max() == 10 -
Shrink函数可移除所有Slack。此函数将把分配重新调整为所需要的大小,使其保存当前的元素序列,而无需实际移动元素SlackArray.Add(5); SlackArray.Add(10); SlackArray.Add(15); SlackArray.Add(20); // SlackArray.GetSlack() == 6 // SlackArray.Num() == 4 // SlackArray.Max() == 10 SlackArray.Shrink(); // SlackArray.GetSlack() == 0 // SlackArray.Num() == 4 // SlackArray.Max() == 4
原始内存
-
本质上而言,TArray 只是分配内存的包装器。直接修改分配的字节和自行创建元素即可将其用作包装器,此操作十分实用。Tarray 将尽量利用其拥有的信息进行执行,但有时需降低一个等级。
-
利用以下函数可在较低级别快速访问 TArray 及其数据,但若利用不当,可能会导致容器无效和未知行为。在调用此类函数后(但在调用其他常规函数前),可决定是否将容器返回有效状态。
-
AddUninitialized和InsertUninitialized函数可将未初始化的空间添加到数组。两者工作方式分别与 Add 和 Insert 函数相同,只是不调用元素类型的构造函数。若要避免调用构造函数,建议使用此类函数。类似以下范例的情况中建议使用此类函数,其中计划用 Memcpy 调用完全覆盖结构体int32 SrcInts[] = { 2, 3, 5, 7 }; TArray<int32> UninitInts; UninitInts.AddUninitialized(4); FMemory::Memcpy(UninitInts.GetData(), SrcInts, 4*sizeof(int32)); // UninitInts == [2,3,5,7]也可使用此功能保留计划自行构建对象所需内存
TArray<FString> UninitStrs; UninitStrs.Emplace(TEXT("A")); UninitStrs.Emplace(TEXT("D")); UninitStrs.InsertUninitialized(1, 2); // 第一个参数指明插入开始位置的索引,第二个参数指明插入几个元素 new ((void*)(UninitStrs.GetData() + 1)) FString(TEXT("B")); // GetData()返回数组头指针 new ((void*)(UninitStrs.GetData() + 2)) FString(TEXT("C")); // UninitStrs == ["A","B","C","D"] -
AddZeroed和InsertZeroed的工作方式相似,不同点是会将添加/插入的空间字节清零struct S { S(int32 InInt, void* InPtr, float InFlt) :Int(InInt) , Ptr(InPtr) , Flt(InFlt) { } int32 Int; void* Ptr; float Flt; }; TArray<S> SArr; SArr.AddZeroed(); // SArr == [{ Int:0, Ptr: nullptr, Flt:0.0f }] -
SetNumUninitialized和SetNumZeroed函数的工作方式与 SetNum 类似,不同之处在于新数量大于当前数量时,将保留新元素的空间为未初始化或按位归零。与 AddUninitialized 和 InsertUninitialized 函数相同,必要时需将新元素正确构建到新空间中SArr.SetNumUninitialized(3); new ((void*)(SArr.GetData() + 1)) S(5, (void*)0x12345678, 3.14); new ((void*)(SArr.GetData() + 2)) S(2, (void*)0x87654321, 2.72); // SArr == [ // { Int:0, Ptr: nullptr, Flt:0.0f }, // { Int:5, Ptr:0x12345678, Flt:3.14f }, // { Int:2, Ptr:0x87654321, Flt:2.72f } // ] SArr.SetNumZeroed(5); // SArr == [ // { Int:0, Ptr: nullptr, Flt:0.0f }, // { Int:5, Ptr:0x12345678, Flt:3.14f }, // { Int:2, Ptr:0x87654321, Flt:2.72f }, // { Int:0, Ptr: nullptr, Flt:0.0f }, // { Int:0, Ptr: nullptr, Flt:0.0f } // ]
应谨慎使用"Uninitialized"和"Zeroed"函数族。如函数类型包含要构建的成员或未处于有效按位清零状态的成员,可导致数组元素无效和未知行为。此类函数适用于固定的数组类型,例如FMatrix和FVector。
其他
BulkSerialize函数是序列化函数,可用作替代运算符<<,将数组作为原始字节块进行序列化,而非执行逐元素序列化。如使用内置类型或纯数据结构体等浅显元素,可改善性能。CountBytes和GetAllocatedSize函数用于估算数组当前内存占用量。CountBytes接受FArchive,可直接调用GetAllocatedSize。此类函数常用于统计报告。Swap和SwapMemory函数均接受两个指数并交换此类指数上的元素值。这两个函数相同,不同点是Swap会对指数执行额外的错误检查,并断言索引是否超出范围。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号