【c++ Prime 学习笔记】第17章 标准库特殊设施
17.2 bitset类型
- 标准库定义的
bitset使位操作更容易,而且能处理超过整型大小的位集合 bitset是类模板,定义在头文件bitset
17.2.1 定义和初始化bitset
- bitset是类模板,实例化时需指定一个模板非类型参数,表示有多少个bit。实例化后大小固定,类似
array - 由于位集合的大小是模板参数,故必须是
constexpr - bitset中的二进制位是匿名的,通过位置编号访问。最
低位编号为0,最高位对应最大编号

用 unsigned 值初始化 bitset
- 使用整型值初始化bitset时,该值先被转换为
unsigned long long然后被当作位模式,bitset中的位是它的副本:- 若bitset的位数多于该unsigned long long,则bitset低位填充高位置0
- 若bitset的位数少于该unsigned long long,则只使用低位,高位被丢弃
bitset<13> bitvec1(0xbeef); //ull更长,高位被丢弃:1 1110 1110 1111
bitset<20> bitvec2(0xbeef); //bitset更长,高位填0:0000 1011 1110 1110 1111
bitset<128> bitvec3(~0ULL); //bitset更长,高位填0:低64位是1,高64位是0
从一个 string 初始化 bitset
- 可从字符串(string或字符数组指针)来初始化bitset,此时字符直接表示bit
- 使用字符串初始化bitset时,字符串下标最小的字符对应高位,即左侧是高位。
- 可使用字符串的子串来初始化bitset
bitset<32> bitvec4("1100"); //字符串下标小的字符对应高位,初始化为1100
string str("1111111000000011001101");
bitset<32> bitvec5(str,5,4); //取子串, 从str[5]开始取4个比他,初始化为1100
bitset<32> bitvec6(str,ste.size()-4); //取子串,从倒数第4个开始直到末尾,初始化为1101
17.2.2 bitset操作

bitset<32> bitvec(1U);
//不接受参数的操作
bool is_set=bitvec.any(); //是否有任何一位是1
bool is_not_set=bitvec.none(); //是否全为0
bool all_set=bitvec.all(); //是否全为1
size_t onBits=bitvec.count(); //1的个数
size_t sz=bitvec.size(); //有多少位
bitvec.flip(); //翻转所有位
bitvec.reset(); //所有位置0
bitvec.set(); //所有位置1
//接受参数的操作
bitvec.flip(0); //将最低位翻转
bitvec.set(bitvec.size()-1); //将最高位置1
bitvec.set(0,0); //将最低位置0
bitvec.reset(i); //将第i位置0
bitvec.test(0); //最低位是否为1
//下标操作
bitvec[0]=0; //下标可写
bitvec[31]=bitvec[0]; //下标可读可写
bitvec[0].flip(); //可对某一位使用bitset操作
~bitvec[0]; //可对某一位使用内置类型的位运算
bool b=bitvec[0]; //可将某一位赋值给(转换为)bool
//转换为unsigned long
unsigned long ulong=bitvec.to_ulong(); //转为unsigned long
cout<<"ulong="<<ulong<<endl;
//IO算符
bitset<16> bits;
cin>>bits; //将输入的'0'/'1'读为string并初始化bitset
cout<<"bits:"<<bits<<endl; //将bitset中的bit转为'0'/'1'打印
//兼容内置类型的位运算
unsigned long quizA=0; //用unsigned long表示至少32个bit
quizA|=1UL<<27; //将第27位置1
bool status=quizA&(1UL<<27); //求第27位的状态
quizA&=~(1UL<<27); //将第27位置0
//与位运算等价的bitset操作,有更好的可读性
bitset<30> quizB; //只需30个bit,用大小为30的bitset
quizB.set(27); //将第27位置1
status=quizB[27]; //求第27位的状态
quizB.reset(27); //将第27位置0
17.3 正则表达式
- 正则表达式是一种描述字符序列的方法,
正则表达式库(RE),定义于头文件regex

regex类表示一个正则表达式,可进行初始化/赋值/其他特定操作regex_match/regex_search/regex_replace函数用于确定给定的字符序列和给定regex是否匹配:- 若整个输入序列与表达式匹配,则regex_match返回true
- 若输入序列的子串与表达式匹配,则regex_search返回true
- regex_replace用于在输入序列中查找并替换
sregex_iterator是迭代器适配器,用于遍历输入序列中所有匹配的子串smatch是容器,用于保存匹配的相关信息(搜索结果等)ssub_match是容器,用于保存子表达式匹配的相关信息- regex_match/regex_search的参数见表17.5,它们都返回bool值表示匹配是否成功
- 接受3个参数的版本仅查找并返回bool
- 接受4个参数的版本,额外参数是smatch,若匹配成功则用于存放匹配的相关信息

17.3.1 使用正则表达式库
regex默认使用的正则表达式语言是ECMAScript
/* ECMAScript正则表达式语法:
* [^c]匹配任意非'c'的字符
* [^c]ei匹配任意非c的字符后接ei的字符串
* [[:alpha:]]匹配任意字母
* +和*分别表示“一个或多个”和“零个或多个”匹配
* [[:alpha:]]*匹配零个或多个字母
* 综上,[[:alpha:]]*[^c]ei[[:alpha:]]*表示:匹配出现任意非c的字符后接ei的字符串的单词
*/
string pattern("[^c]ei");
pattern="[[:alpha:]]*"+pattern+"[[:alpha:]]*"; //构建正则表达式的字符串描述
regex r(pattern); //创建正则表达式regex对象
smatch results; //创建匹配的结果对象
string test_str="receipt freind theif receive"; //要查找模式的字符串
//regex_search匹配字符串的子串,如果匹配成功,返回true并将结果存在results中
if(regex_search(test_str,results,r))
cout<<results.str()<<endl; //打印匹配的结果,输出将是freind(匹配到的第一个)
指定regex对象选项
- 表17.6的最后6个标志指出编写正则表达式使用的语言,必须指定其中之一。默认使用ECMAScript,即使用
ECMA-262规范,这是很多web浏览器使用的正则表达式语言 - 表17.6的另外3个标志指定与正则表达式无关的方面,如是否忽略大小写、保存子表达式、权衡性能等

/* ECMAScript正则表达式语法:
* [[:alnum:]]匹配字母或数字
* [[:alnum:]]+匹配一个或多个字母或数字
* .匹配任意字符
* 由于.在正则表达式语法中有特殊含义,故加上\
* 由于\在c++字符串中有特殊含义,故再加一个\
* 综上,\\.匹配字符串中的字符'.'
* cpp|cxx|cc是或逻辑,匹配cpp或cxx或cc
* (cpp|cxx|cc)加上括号是子表达式
*/
regex r("[[:alnum:]]+\\.(cpp|cxx|cc)$",regex::icase); //匹配时忽略大小写
smatch results;
string filename;
while(cin>>filename)
if(regex_search(filename,results,r))
cout<<results.str()<<endl;
指定或使用正则表达式时的错误
- 可将正则表达式本身看作一种简单的程序设计语言编写的“程序”,它在运行时regex对象被初始化或赋予新模式时被“编译”
- 正则表达式的编写可能不符合正则表达式的语法规范,导致错误
- 正则表达式编写错误时,在运行时抛出一个
regex_error类型的异常:- 该类型有一个
what成员函数用于描述错误 - 该类型有一个
code成员函数用于返回错误类型对应的数值编码,其返回值由具体实现定义
- 该类型有一个
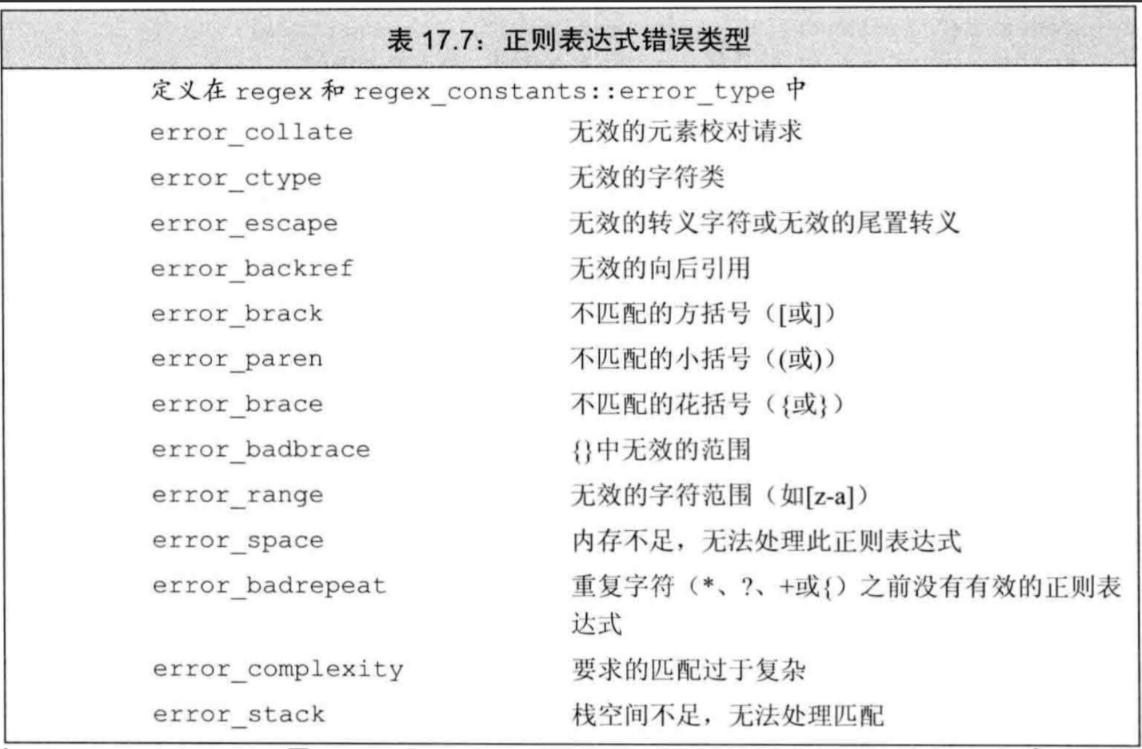
try{
//创建正则表达式时可能抛出异常(由于正则表达式书写错误),用try捕获异常
regex r("[[:alnum:]]+\\.(cpp|cxx|cc)$",regex::icase); //书写错误:[[:alnum:]应为[[:anum:]]
}
catch(regex_error e){
//创建正则表达式时抛出的异常regex_error有what和code两个成员函数
cout<<e.what()<<" \ncode: "<<e.code()<<endl;
}
- 正则表达式所表示的“程序”是在运行时“编译”的,这个操作非常慢。即创建正则表达式非常慢。如果使用循环,应该在循环外创建它。
- 构造regex对象以及向regex对象赋值都很耗时,应尽量避免
正则表达式类和输入序列类型

- regex类根据名字前是否有w,分为2种:
regex类由string/char数组初始化wregex类由wstring/wchar_t数组初始化
- match/sub_match/regex_iterator根据名字s和c,以及名字前是否有w,分为4种:
- 前面是
s的版本由string初始化 - 前面是
c的版本由const char *初始化 - 前面是
ws的版本由wstring初始化 - 前面是
wc的版本由const wchar_t *初始化
- 前面是
//regex不区分string和字符数组
regex r("[[:alnum:]]+\\.(cpp|cxx|cc)$",regex::icase);
smatch results; //结果存在string中
if(regex_search("myfile.cc",results,r)) //错,"myfile.cc"是字符数组,与smatch不统一
cout<<results.str()<<endl;
cmatch results; //结果存在字符数组中
if(regex_search("myfile.cc",results,r)) //对,输入序列"myfile.cc"和cmatch统一
cout<<results.str()<<endl;
17.3.2 匹配与regex迭代器类型
- 使用regex_search得到的搜索结果默认只取第一个匹配的子串。使用迭代器sregex_iterator可获得所有匹配
sregex_iterator迭代器是一种迭代器适配器,被绑定到一个输入序列和一个regex对象

使用 sregex_iterator
初始化sregex_iterator时,- 若使用输入字符串/字符数组和regex来初始化,则调用regex_search在输入字符串/字符数组中查找第一个匹配
- 默认初始化为尾后迭代器
解引用regex_iterator时,得到对应最近一次搜索结果的match对象递增regex_iterator时,调用regex_search在输入字符串/字符数组中查找下一个匹配

string pattern("[^c]ei");
pattern="[[:alpha:]]*"+pattern+"[[:alpha:]]*";
regex r(pattern,regex::icase);
//假定file是string类型,保存要搜索的字符串
//创建两个sregex_iterator,第一个初始化为第一个匹配,第二个初始化为尾后迭代器
//使用递增来遍历每一个匹配位置
for(sregex_iterator it(file.begin(),file.end(),r),end_it;it!=end_it;++it)
cout<<it->str()<<endl;
使用匹配数据
- 使用match对象来表示一次匹配的结果时,不仅可用str成员函数来得到匹配部分的内容,还能得到其他信息

- 匹配时经常不仅要知道匹配部分,还要知道其上下文。可使用match的prefix和suffix成员函数得到:
prefix成员函数返回一个sub_match对象,表示输入字符串/字符数组中匹配部分之前的部分suffix成员函数返回一个sub_match对象,表示输入字符串/字符数组中匹配部分之后的部分
- sub_match类有两个名为str和length的成员,分别返回其代表的字符串/字符数组与其大小

/* for之前的部分和上一个例子一样 */
for(sregex_iterator it(file.begin(),file.end(),r),end_it;it!=end_it;++it){
auto pos=it->prefix.length();
pos=pos>40?pos-40:0; //若前面不足40个字符,则完整打印前面部分,否则打印前面40个字符
cout<<it->prefix().str().substr(pos) //打印匹配部分的上文
<<"\n\t>>> "<<it->str()<<" <<<\n" //打印匹配部分,并在两侧加上箭头强调
<<it->suffix().str().substr(0,40) //打印匹配部分的下文
<<endl;
}
17.3.3 使用子表达式
- 正则表达式中的模式通常包含一个或多个
子表达式,它是模式的一部分,表示部分匹配。 - 正则表达式的语法通常用括号表示子表达式
- 对于含有子表达式的正则表达式,其匹配结果match对象的str成员函数可以有参数:0代表整个匹配部分,1代表第1个子串,以此类推。例如,正则表达式”[[:alnum:]]+.(cpp|cxx|cc)$”,输入字符串"foo.cpp”,则匹配结果的
str(0)是"foo.cpp”,str(1)是"foo”,str(2)是"cpp”
子表达式用于数据验证
- 子表达式的常见用途是验证必须匹配特定格式的数据。即分别验证多个子式,然后验证它们之间必须满足某种关系
- ECMAScript正则表达式的一些语法:
\{d}表示单个数字,\{d}{n}表示n个数字的序列。如\{d}{3}表示3个数字的序列- 方括号
[]中的字符集合表示匹配它们中的任一个,.在方括号中没有特殊含义。如[-.]表示匹配’-‘或’.’ - 后接
?的组件是可选的。如\{d}{3}[-. ]?\{d}{4}匹配三个数字后接四个数字,中间可以有’-‘或’.‘或’ ' - 在字符前加反斜线
\表示是字符本身而不是其特殊含义(类似C++语法)。如\(和\)表示’(‘和’)‘本身而不是特殊字符 - 由于
\也是C++的特殊字符,故每次正则表达式需要转义时都需要两个\
使用子匹配操作
- 对于有子表达式的正则表达式,其
match对象包含多个sub_match对象作为其元素。位置[0]表示整个匹配,[1]表示第一个子表达式的匹配,以此类推。 - 每个sub_match表示在完整匹配中,这个子表达式匹配的结果

/* ECMAScript正则表达式语法:
* (\\()?是子表达式,匹配字符'(',表示区号部分可选的左括号
* (\\d{3})是子表达式,匹配3个数字,表示区号
* (\\))?是子表达式,匹配字符')',表示区号部分可选的右括号
* ([-. ])?是子表达式,匹配字符'-'或'.'或' ',表示区号部分可选的分隔符
* (\\d{3})是子表达式,匹配3个数字,表示号码下三位数字
* ([-. ])?是子表达式,匹配字符'-'或'.'或' ',表示可选的分隔符
* (\\d{4})是子表达式,匹配4个数字,表示号码最后四位
*/
string phone="(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-. ])?(\\d{4})";
regex r(phone);
smatch m;
srting s;
//判断一个被正则表达式匹配到的字符串是否是电话号码(即是否符合进一步的标准)
bool valid(const smatch &m){
if(m[1].matched)
//若左边括号被匹配到,则右边括号必须也被匹配,且满足某个先验
return m[3].matched && (m[4].matched==0 || m[4].str()==" ");
else
//若左边括号未被匹配到,则右边括号也必须未被匹配,且满足某个先验
return !m[3].matched && m[4].str()==m[6].str();
}
//逐行处理匹配到的电话号码
while(getline(cin,s)){
//使用sregex_iterator遍历一行中的所有匹配
for(sregex_iterator it(s.begin(),s.end(),r),end_it;it!=end_it;++it)
//对每个匹配到的结果通过valid分析子串,进一步判断是否是电话号码
if(valid(*it))
cout<<"valid: "<<it->str()<<endl;
else
cout<<"not valid: "<<it->str()<<endl;
}
17.3.4 使用regex_replace
- 使用regex_replace可在输入序列中查找并替换一个正则表达式。除匹配需要一个正则表达式描述匹配格式外,还需要一个字符串用于描述输出(即替换后)的形式

- 输出的字符串可由匹配的子串组成,用符号$后跟子表达式的索引号来表示该子表达式
string phone="(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-. ])?(\\d{4})";
regex r(phone);
string fmt="$2.$5.$7"; //定义输出格式为第2,5,7个子串,中间用'.'分隔
string number="(908) 555-1800"; //输入(908) 555-1800
cout<<regex_replace(number,r,fmt)<<endl; //输出908.555.1800
只替换输入序列的一部分
同上,用大文件替换简单的号码
用来控制匹配和格式的标志
- 标准库定义了在替换过程中控制匹配或格式的标志,它们可传递给函数regex_search/regex_match,或是类match的format成员
- 匹配和格式化标志都是值,它们类型都是
match_flag_type,定义在命名空间regex_constants,经常使用using namespace std::regex_constants;来引入该命名空间的所有名字
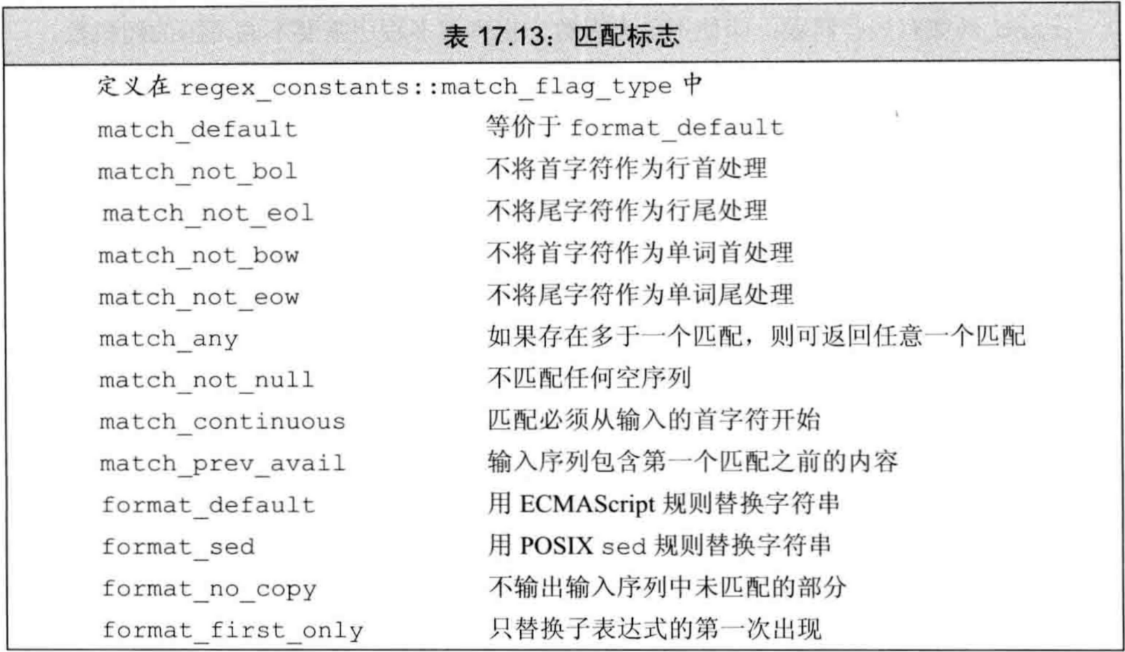
使用格式标志
- 默认regex_replace返回整个输入序列,仅将匹配部分替换为指定格式,未匹配部分原样输出。可用format_no_copy来阻止保留未匹配部分
string phone="(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-. ])?(\\d{4})";
regex r(phone);
string fmt="$2.$5.$7 "; //定义输出格式为第2,5,7个子串,中间用'.'分隔,末尾加空格
string number="morgan (201) 555-2368 862-555-0123"; //输入morgan (201) 555-2368 862-555-0123
cout<<regex_replace(number,r,fmt)<<endl; //输出morgan 201.555.2368 862.555.0123
cout<<regex_replace(number,r,fmt,format_no_copy)<<endl; //输出201.555.2368 862.555.0123
17.4 随机数
- 在C++11之前,C和C++都依赖一个简单的C库函数
rand来生成随机数。rand函数生成均匀分布的伪随机整数,范围在0和最大值(与系统相关,至少为32767)之间 - 很多时候需要不同范围的随机数、随机浮点数、非均匀分布的随机数,程序员在转换rand生成的随机数的范围、类型、分布时,经常引入非随机性。
- C++11在头文件
random中定义了随机数库,通过一组协作的类来生成随机数:随机数引擎类用于生成一系列unsigned随机数的序列随机数分布类使用引擎类生成指定类型、指定范围、指定分布的随机数
17.4.1 随机数引擎和分布
- 随机数引擎是函数对象类,它们定义了调用算符
(),该算符不接受参数,返回一个随机unsigned整数 - 通过调用随机数引擎对象来生成一个
原始随机数,每次调用生成的原始随机数是随机序列中的一个值
default_random_engine e; //随机数引擎是可调用对象
for(size_t i=0;i<10;++i)
cout<<e()<<" "; //每次调用生成原始随机序列中的一个值
- 标准库定义了多个随机数引擎类,它们的性能和随机性质量不同,由编译器指定哪一个作为default_random_engine类型。
- 大多数场合不能直接使用随机数引擎的输出(原始随机数),因为范围、类型、分布并非所需,而正确转换很难

分布类型和引擎
-
为得到指定范围内的随机数,需使用分布类型的对象
-
分布
uniform_int_distribution是模板类,用于生成均匀分布。模板参数提供生成随机数的类型,构造函数形参指定取值范围。 -
分布类型也是函数对象类,它们定义了调用算符,接受一个随机数引擎对象,使用这个引擎生成原始随机数并映射到自己的分布。
-
传递给分布对象的是引擎对象本身而不是其原始随机数,因为某些分布可能需要多次调用引擎才能得到一个值
uniform_int_distribution<unsigned> u(0,9); //分布类,指定生成随机数的范围、类型、分布 default_random_engine e; //引擎类,用于生成原始随机数 for(size_t i=0;i<10;++i) cout<<u(e)<<" "; //使用引擎类对象调用分布类对象,生成随机数 -
随机数发生器是指分布对象和引擎对象的组合
比较随机数引擎和 rand 函数
- 调用引擎类default_random_engine对象的输出类似C库函数rand的输出,区别在于:
- 随机数引擎生成的unsigned在系统定义的范围内,该范围可通过调用引擎对象的
min和max成员函数获得 - rand生成的unsigned在0到
RAND_MAX之间。
- 随机数引擎生成的unsigned在系统定义的范围内,该范围可通过调用引擎对象的
引擎生成一个数值序列
- 同样的随机数发生器产生的随机数序列相同:
- 对于一个给定的随机数发生器,每次运行程序时给出的随机数序列都是相同的。解决方案:每次运行时使用不同的种子
- 程序内多次以相同的设置来初始化随机数发生器,产生的随机数序列也是相同的。解决方案:将随机数发生器声明为static
- 程序中需要从同一随机数发生器中多次取随机数时,应将引擎和分布对象都声明为
static。因为若每次都以相同的设置创建随机数发生器,则每次生成的序列都相同。
//每次调用都创建随机数发生器,则每次调用生成的随机序列都相同
vector<unsigned> bad_randVec(){
default_random_engine e;
uniform_int_distribution<unsigned> u(0,9);
vector<unsigned> ret;
for(size_t i=0;i<100;++i)
ret.push_back(u(e));
return ret;
}
//每次调用bad_randVec都重新创建随机数发生器,故v1和v2内容相同
vector<unsigned> v1(bad_randVec());
vector<unsigned> v2(bad_randVec());
//将随机数发生器声明为static,避免多次创建。从同一序列中取随机数,保证每次取的值都不同
vector<unsigned> good_randVec(){
static default_random_engine e;
static uniform_int_distribution<unsigned> u(0,9);
vector<unsigned> ret;
for(size_t i=0;i<100;++i)
ret.push_back(u(e));
return ret;
}
//每次调用good_randVec都使用同一个随机数发生器,保证不重复
vector<unsigned> v3(good_randVec());
vector<unsigned> v4(good_randVec());
设置随机数发生器种子
- 随机数发生器生成相同的随机数序列这一特性在调试时很有用,但希望每次运行程序都得到不同的随机数序列,则可在每次运行时提供不同的种子。
种子是一个数值,引擎利用种子从序列的一个新位置重新开始生成随机数。只要种子不同,生成的随机序列就不同- 为引擎设置种子有两种方式:
- 创建引擎对象时提供种子
- 调用引擎对象的seed成员
default_random_engine e1; //e1不指定种子
default_random_engine e2(2147483646); //e2创建时提供种子2147483646
default_random_engine e3;
e3.seed(32767); //e3使用seed函数提供种子32767
default_random_engine e4(32767); //e4创建时提供种子32767
for(seize_t i=0;i!=100;++i){
if(e1()==e2())
cout<<"unseeded match at iteration: "<<i<<endl; //e1和e2种子不同,生成不同的序列
if(e3()!=e4())
cout<<"seeded differs at iteration: "<<i<<endl; //e3和e4种子相同,生成相同的序列
}
- 选择恰当的种子很难,经常使用C系统函数time。该函数定义在头文件ctime中
- 它返回一个特定时刻到当前共经过了多少秒
- 它接受单个指针参数,指向用于写入时间的数据结构,若该指针为空则简单的返回时间
- time返回的时间以秒计,故该方法只适合生成种子的间隔为秒级或更长的应用
- 若程序周期性运行,或周期性取time,则它生成的值可能是相同的,不适合当种子
default_random_engine e1(time(0));
17.4.2 其他随机数分布
- 程序经常需要不同类型、不同分布的随机数,标准库定义不同的随机数分布对象来满足这些需求,分布对象和引擎对象协同工作。
- 程序经常需要随机浮点数,特别是0到1之间的随机数。
- C++11之前经常用rand()的结果除以RAND_MAX,但这样精度太低,可生成的数量只有RAND_MAX个
- C++11之后可使用uniform_real_distribution分布类,让标准库处理随机整数到随机浮点数的映射
生成随机实数

default_random_engine e; //随机数引擎
uniform_real_distribution<double> u(0,1); //随机数分布,生成0到1之间的均匀随机数
for(size_t i=0;i<10;++i)
cout<<u(e)<<" "<<endl;
使用分布的默认结果类型
- 分布类型都是模板,且有一个模板类型参数表示生成随机数的类型(
bernoulli_distribution是例外,它不是模板类,总是返回bool值)。这些分布类型只能生成浮点数或整型数 - 每个分布模板都有一个默认模板实参,生成浮点值的分布类型默认生成
double,生成整型值的分布类型默认生成int。使用默认模板实参时也需要空的尖括号
生成非均匀分布的随机数
- C++11可生成非均匀分布的随机数,它定义了20种分布类型,见附录A.3
//正态分布
default_random_engine e; //随机数引擎
normal_distribution<> n(4,1.5); //随机数分布,生成均值为4标准差为1.5的正态分布
vector<unsigned> vals(9); //用vector存放每个区间内随机数的数量
for(size_t i=0;i!=200;++i){ //生成200个随机数
unsigned v=lround(n(e)); //将正态分布的随机数向下取整
if(v<vals.size()) //只需判断一侧边界是因为unsigned把负数移到最大值处
++vals[v]; //区间内计数增加
}
for(size_t j=0;j!=vals.size();++j)
cout<<j<<": "<<string(vals[j],'*')<<endl; //以字符'*'的数量可视化区间内随机数的数量
bernoulli_distribution 类
- 二项分布
bernoulli_distribution不是类模板,故不接受模板参数,它总是返回bool值。 - bernoulli_distribution返回true的概率是常数,构造时指定,默认为0.5
17.5 IO库再探
三个更特殊的IO库特性:格式控制、未格式化IO、随机访问
17.5.1 格式化输入与输出
- 除
条件状态外,每个iostream对象还维护一个格式状态来控制IO的细节,如整型是几进制、浮点值精度、输出元素宽度等 - 标准库定义一组
操纵符来修改流的格式状态。一个操纵符是一个函数或对象,能用作输入/输出算符的运算对象,并能影响流的状态。 - 操纵符返回它所处理的流对象(类似输入/输出算符),故可在语句中组合使用操纵符和数据
endl是一个操纵符,它不是一个值而是一个操作,将其写到输出流的效果是输出一个换行符并刷新缓冲

很多操纵符改变格式状态
- 操纵符用于两大类输出控制: 控制数值的输出形式、控制补白的数量和位置。
- 操纵符改变流的格式状态时,通常改变后的状态对所有后续IO都生效
- 大多数改变格式状态的操纵符都是
设置/复原成对的:一个操纵符将格式状态设置为新值,另一个操纵符将其复原 - 利用操纵符对格式的改变是持久的这一特性,可在一个流上叠加多个操纵符。但不需要特殊格式时应尽快恢复到默认
控制布尔值的格式
- 默认将bool值打印为0/1,使用
boolalpha/noboolalpha可设置bool值打印为0/1或true/false
cout<<"default bool values: "<<true<<" "<<false //默认设置下打印bool
<<"\nalpha bool values: "<<boolalpha<< //使用操纵符boolalpha设置流,后续打印bool都是true/false
<<true<<" "<<false //使用boolalpha的设置下打印bool
<<noboolalpha<<endl; //恢复为默认状态noboolalpha,后续打印bool都是0/1
指定整型值的进制
- 默认整型值的输入输出使用十进制,可使用操纵符
hex/oct/dec将其改为十六进制/八进制/十进制,它们只影响整型值,不影响浮点值 - 默认打印整型值时不打印表示进制的
前导字符,可使用操纵符showbase/noshowbase使流打印整型值时显示/不显示进制:前导0x是十六进制,前导0是八进制,无前导是十进制 - 默认十六进制的值和前导字符都以小写打印,可使用操纵符
uppercase/nouppercase使十六进制的值和前导字符以大写打印
//调整进制
cout<<"default: "<<20<<" "<<1024<<endl; //打印:20 1024
cout<<"octal: "<<oct<<20<<" "<<1024<<endl; //打印:24 2000
cout<<"hex: "<<hex<<20<<" "<<1024<<endl; //打印:14 400
cout<<"decimal: "<<dec<<20<<" "<<1024<<endl; //打印:20 1024
//调整前导字符
cout<<showbase;
cout<<"default: "<<20<<" "<<1024<<endl; //打印:20 1024
cout<<"octal: "<<oct<<20<<" "<<1024<<endl; //打印:024 02000
cout<<"hex: "<<hex<<20<<" "<<1024<<endl; //打印:0x14 0x400
cout<<"decimal: "<<dec<<20<<" "<<1024<<endl; //打印:20 1024
cout<<noshowbase;
//调整十六进制的大小写
cout<<uppercase<<showbase<<hex //设置以十六进制打印,打印前导字符,以大写打印
<<"printed in hexadecimal: "<<20<<" "<<1024 //打印:0X14 0X400
<<nouppercase<<noshowbase<<dec<<endl; //复原成默认设置
指定打印精度
- 可以控制浮点数输出三种格式:
- 以多高精度/多少个数字打印浮点值,默认按六位数字精度打印
- 打印为十六进制/定点十进制/科学记数法,默认非常大和非常小的值打印为科学记数法,其他值打印为定点十进制
- 无小数点的浮点数是否打印小数点,默认对无小数点的浮点数不打印小数点
- 精度控制打印的数字的总数,打印时浮点值按当前精度舍入。可通过调用IO对象的precision成员函数或setprecision操纵符来改变打印精度。
precision成员函数是重载的,一个版本接受int值用于指定精度,并返回旧精度值,另一个版本不接受参数,返回当前精度值setprecision操纵符接受一个参数,用于设置精度
- setprecision和其他接受参数的操纵符都定义在头文件
iomanip中
//precision成员函数得到当前精度
cout<<"precision: "<<cout.precision()
<<", value: "<<sqrt(2.0)<<endl;
//precision成员函数将精度设置为12,precision成员函数得到当前精度
cout.precision(12); //使用precision成员函数的形式是cout调用
cout<<"precision: "<<cout.precision()
<<", value: "<<sqrt(2.0)<<endl;
//setprecision操纵符将精度设置为3,precision成员函数得到当前精度
cout<<setprecision(3); //使用setprecision操纵符的形式是用输出算符输出
cout<<"precision: "<<cout.precision()
<<", value: "<<sqrt(2.0)<<endl;
指定浮点数计数法
- 操纵符
scientific可使流使用科学记数法,操纵符fixed可使流使用定点十进制 - C++11可用操纵符
hexfloat使流使用十六进制,可用操纵符defaultfloat将流恢复到默认状态,即根据打印值的大小选择科学记数法/定点十进制 - 浮点数操纵符会改变精度的默认含义:
- 执行scientific/fixed/hexfloat后,精度值是指小数点后的数字位数
- 执行defaultfloat后(即默认状态下),精度值是指数字的总位数
- 默认十六进制数字和科学计数法中的e都是小写,可用
uppercase操纵符将它们打印为大写,nouppercase操纵符恢复默认行为
cout<<"default format: "<<100*sqrt(2.0)<<'\n' //打印:141.421
<<"scientific: "<<scientific<<100*sqrt(2.0)<<'\n' //打印:1.414214e+002
<<"fixed decimal: "<<fixed<<100*sqrt(2.0)<<'\n' //打印:141.421356
<<"hexadecimal: "<<hexfloat<<100*sqrt(2.0)<<'\n'; //打印:0x1.1ad7bcp+7
<<"use defaults: "<<defaultfloat<<100*sqrt(2.0)<<'\n'; //打印:141.421
打印小数点
- 默认小数部分为0的浮点值不打印小数点和小数部分,可用
showpoint操纵符设定为打印小数点和小数部分,noshowpoint操纵符恢复默认行为
cout<<10.0<<endl; //打印:10
cout<<showpoint<<10.0 //打印:10.000
<<noshowpoint<<endl; //恢复默认的不打印小数点和小数部分
输出补白
按列打印时,需要用操纵符精细地控制数据格式
setw指定下一个数字或字符串值的最小空间(特例,只设置下一个值,不设置整个流)left指定左对齐输出right指定右对齐输出,右对齐是默认internal控制负数的负号位置,它左对齐负号,右对齐数值,用空格填满中间setfill允许指定一个字符来补白输出,默认是空格

int i=-16;
double d=3.14159;
cout<<"i: "<<setw(12)<<i<<"next col\n" //打印:i: -16next col
<<"d: "<<setw(12)<<d<<"next col\n"; //打印:d: 3.14159next col
cout<<left
<<"i: "<<setw(12)<<i<<"next col\n" //打印:i: -16 next col
<<"d: "<<setw(12)<<d<<"next col\n" //打印:d: 3.14159 next col
<<right;
cout<<right
<<"i: "<<setw(12)<<i<<"next col\n" //打印:i: -16next col
<<"d: "<<setw(12)<<d<<"next col\n"; //打印:d: 3.14159next col
cout<<internal
<<"i: "<<setw(12)<<i<<"next col\n" //打印:i: - 16next col
<<"d: "<<setw(12)<<d<<"next col\n"; //打印:d: 3.14159next col
cout<<setfill('#')
<<"i: "<<setw(12)<<i<<"next col\n" //打印:i: -#########16next col
<<"d: "<<setw(12)<<d<<"next col\n" //打印:d: #####3.14159next col
<<setfill(' ');
控制输入格式
- 默认输入算符会忽略空白符(空格符/制表符/换行符/换纸符/回车符),操纵符noskipws会让输入算符读取空白符,操纵符skipws恢复默认行为
char ch;
while(cin>>ch)
cout<<ch;
//默认不读取空白
/* 输入:a b c
* d
* 输出:abcd
*/
//使用noskipws读取空白
cin>>noskipws;
while(cin>>ch)
cout<<ch;
cin>>skipws; //恢复默认行为
/* 输入:a b c
* d
* 输出:a b c
* d
*/
17.5.2 未格式化的输入/输出操作
- 多使用
格式化IO操作,即使用输入输出算符>>/<<根据读取/写入的数据类型来格式化它们。输入算符忽略空白,输出算符应用空白、精度等规则 未格式化IO是标准库提供的底层操作,它们将流当作未解释的字节序列来处理
单字节操作
- 有几个未格式化操作每次一个字节地处理流,它们会读取空白符

将字节放回输入流
- 有时候需要读取一个字符才能知道还未准备好处理它,此时希望将字符放回流中。标准库有3种方法从流中退回字符:
peek返回输入流中下一个字符的副本,但不会将它从流中删除unget使输入流向后移动,最后读取的值又回到流中putback是特殊的unget,它退回从流中读取的最后一个值。但它接受一个参数,该参数必须与最后读取的值相同
- 一般在读取下一个值之前,标准库保证可退回至多一个值。即,标准库不保证在中间不进行读取操作的情况下可连续调用putback/unget
从输入操作返回的int值
- peek和无参的get都以
int(而非char)类型从输入流中返回字符,原因:- char无法表示EOF
- char是unsigned还是signed取决于机器
- 返回int的函数将它们要返回的字符先转换为unsigned char,然后将结果提升为int。因此即使字符集中有字符映射到负值,这些操作返回的int也是正值
- 标准库用负值表示EOF,这样可保证与任何合法字符都不同。头文件
cstdio定义了名为EOF的const,可用它来检测一个值是否是文件尾,而不必记住文件尾的实际数值
int ch; //使用int保存流中读取的字符,不可用char
while((ch=cin.get())!=EOF) //使用EOF常量,不需要记住其具体数值
cout.put(ch);
多字节操作
- 一些未格式化IO操作一次处理多个字符,它们速度较快但容易出错,需要程序员自己分配/管理用于存储数据的字符数组
get和getline函数接受相同的参数,表中的sink都是保存数据用的char数组,两函数都一直读数据,直到:已读取size1个字符/遇到分隔符delim/遇到文件尾- get遇到分隔符时不读取,将其留作istream的下一个字符
- getline遇到分隔符时读取并丢弃

确定读取了多少个字符
- 某些操作从输入读取未知个数的字节,可调用
gcount来确定最后一次未格式化的输入操作读取了多少个字符 - 应在任何后续的未格式化输入操作之前调用gcount,特别的,将字符退回流的单字符操作也是未格式化的输入,若在peek/unget/putback之后调用gcount,则其返回0
小心:底层函数容易出错
- 一般应使用标准库提供的高层抽象来处理IO,避免使用底层IO
- 底层IO通常用于读取二进制值的场合,且这些二进制不能直接映射到普通字符和数值
- 一个常见的错误是用char而非int来存储get/peek的返回值,且该错误不能被编译器发现
17.5.3 流随机访问
- 各种流类型通常(除iostream外)都支持对数据的随机访问。可重定位流,使其跳过一些数据
- 标准库提供了一对函数:
seek用于定位到流中的指定位置tell返回当前的位置
- 随机IO本质上依赖系统,使用这些特性需查询系统文档
- 虽然标准库为所有流类型都定义了seek/tell,但它们的意义取决于设备。在多数系统中,对于绑定到
cin/cout/cerr/clog的流进行随机访问是无意义的,对它们调用seek/tell会在运行时报错并将流置于无效状态 istream/ostream类型通常不支持随机访问,使用随机访问的情形经常是fstream/sstream
seek 和 tell 函数
- 为支持随机访问,IO类型维护一个
标记来确定下一个读写操作在哪里进行,它提供两个函数- seek通过将标记定位到给定位置来重定位它
- tell告知标记的当前位置
- 标准库定义了两对seek/tell,见表17.21
- 后缀是
g的版本用于输入流,表示读取数据(get) - 后缀是
p的版本用于输出流,表示写入数据(put)
- 后缀是

只有一个标记
- 逻辑上,只能对可读的流使用g版本,只能对可写的流使用p版本:
- 只能对istream及其派生出的ifstream/istringstream使用g版本
- 只能对ostream及其派生出的ofstream/ostringstream使用p版本
- iostream/fstream/stringstream既可用g版本又可用p版本
- 标准库对一个流只维护一个标记,g版本和p版本共用标记,不存在独立的“读标记”和“写标记”
重定位标记
- seek函数有两个重载的版本,一个移动到绝对地址,另一个移动到指定位置的指定偏移量
- 表17.21中seek函数的形参pos类型是pos_type,形参off的类型是off_type,它们定义于头文件istream和ostream
pos_type类型表示文件中的绝对位置off_type类型表示文件中位置的偏移量,可正可负
访问标记
- tell函数返回一个pos_type类型的值表示标记的当前位置,通常用来记住一个位置以便稍后定位回来
/* 任务:给定文件,在文件尾添加一行,记录每一行的起始在文件中的位置(除第一行外)
/* 输入:
* abcd
* efg
* hi
* j
*/
/* 输出:
* abcd
* efg
* hi
* j
* 5 9 12 14
*/
//打开文件,定位到末尾,并以可读可写模式打开
std::fstream inOut("copyOut",std::fstream::ate|std::fstream::in|std::fstream::out);
//打开文件操作无效时报错并退出
if(!inOut){
std::cerr<<"Unable to open file!"<<std::endl;
return EXIT_FAILURE;
}
//记录文件尾的位置,由于打开时已定位到末尾,故返回的是当前位置
auto end_mark=inOut.tellg();
//重定位到文件开始,使用相对位置时可从fstream::beg/fstream::cur/fstream::end开始
inOut.seekg(0,std::fstream::beg);
size_t cnt=0; //计数器记录当前位置
std::string line; //string存储每次读取的一行
//当流还有效、未读到末尾、成功取到一行时
while(inOut && inOut.tellg()!=end_mark && getline(inOut,line)){
cnt+=line.size()+1; //计数
auto mark=inOut.tellg(); //记录当前位置
inOut.seekp(0,std::fstream::end); //将流定位到文件末尾
inOut<<cnt; //将计数写入文件末尾
if(mark!=end_mark) //若未到达打开时的文件尾,则打印空格,准备写入下一个行号
inOut<<" ";
inOut.seekg(mark); //回到计数时的位置
}
inOut.seekp(0,std::fstream::end);
inOut<<"\n"; //在文件末尾写入换行符
作者:砥才人
出处:https://www.cnblogs.com/shiroe
本系列文章为笔者整理原创,只发表在博客园上,欢迎分享本文链接,如需转载,请注明出处!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号