

python处理txt数据写入columns和index
一、parsivel雨滴谱数据:

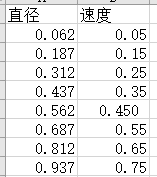
二、数据介绍:

总结一下就是,第一行数据是第一个速度对应的全部32个尺度粒子个数,第二行数据是第二个速度对应的全部32个尺度粒子个数。
三、速度、尺度一览表:


四、先将速度、尺度数据放入原雨滴谱txt数据中,以方便后期计算:
(1)先按时间进行分组
(2)再按行读取,将每个部分变成列表,放入dataframe里
(3)最后插入雨滴谱速度尺度文件

#!usr/bin/env python # -*- coding:utf-8 -*- """ @author: Suyue @file: speedeeinsert.py @time: 2024/04/07 @desc: """ import numpy as np import pandas as pd df1 = pd.read_excel('G:/尺度速度.xls') file_path = 'G:/NM004-20230627224400-20230627224859-0.txt' # 读整个txt文件读取到单个字符串 with open(file_path, 'r', errors='ignore') as file: file_content = file.read() # 按时间戳拆分内容以查找单独的部分 # 时间戳的格式为 YYYY-MM-DD HH:MM:SS,因此我们将使用正则表达式根据此模式进行拆分 import re sections = re.split(r'\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\n', file_content) # print(sections) # 如果txt第一个元素为空值(由于拆分),则将其删除 if not sections[0]: sections.pop(0) # 将每个部分放入列表 list = [] for section in sections[1:]: # 将字符串拆分为几行,然后按空格拆分每行并转换为 DataFrame lines = section.strip().split('\n') # print(lines) matrix = [line.split() for line in lines] df = pd.DataFrame(matrix) # print(matrix) df.columns = df1['直径'] df.index = df1['速度'] # 将df放入list中 list.append(df) # print(list) # 将结果存入excel rdf = pd.concat(list,axis=0) rdf.to_excel('G:/NM004-20230627224400-20230627224859-0.xlsx') # 显示每个dataframe形状以确认 df_shapes = [df.shape for df in list] print(df_shapes)
结果:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程