获取执行计划
查看执行计划
recursive calls :递归调用。一般原因:dictionary cache未命中;动态存储扩展;PL/SQL语句
db block gets :bufer中读取的block数量,用于insert,update,delete,selectfor update
consistent gets :这里是一致读次数(一个block可能会被读多次),bufer中读取的用于查询(除掉select forupdate)的block数量。
--db blocksgets+consistent gets= logical read
physical reads :从磁盘上读取的block数量
redo size :bytes,写到redo logs的数据量
bytes sent via SQLNet to client
bytes received via SQLNet from client
SQL*Net roundtrips to/from client
sorts (memory) :内存排序次数
sorts (disk) :磁盘排序次数;与sort_area_size有关
官网对consistent gets 的解释:
consistent gets:Number of times a consistent read wasrequested for a block.
通常我们执行SQL查询时涉及的每一block都是Consistent Read, 只是有些CR(Consistent Read)需要使用undo 来进行构造, 大部分CR(Consistent Read)并不涉及到undo block的读.
还有就是每次读这个block都是一次CR(可能每个block上有多个数据row), 也就是如果某个block被读了10次, 系统会记录10个Consistent Read.
简单的说:
consistentgets : 通过不带for update的select 读的blocks.
dbblock gets : 通过update/delete/selectfor update读的blocks.
db block gets + consistent gets = 整个逻辑读。
查看预估的执行计划--AUTOTRACE
set autot on ----输出所有内容,包括语句本身的查询结果、执行计划,以及性能统计数据
set autot on exp ----输出所有内容,包括语句本身的查询结果和执行计划,不输出性能统计数据
set autot on stat----输出所有内容,包括语句本身的查询结果和性能统计数据,不输出执行计划
set autot trace ----输出执行计划和性能统计数据,不输出语句本身的查询结果
set autot trace exp ----输出执行计划,不输出语句本身的查询结果和性能统计数据
set autot trace stat ----输性能统计数据,不输出语句本身的查询结果和执行计划
开启autotrace我们可以看到目标SQL执行时所耗费的物理读、逻辑读、产生redo的数量及排序的数量等。
查看预估的执行计划--EXPLAIN PLAN FOR
explain plan for select count(*) from t10;
select * from table(dbms_xplan.display);
plan_table(全局临时表,它会存储数据直到会话结束,多个并发用户可以互不影响彼此的工作) 、$ORACLE_HOME/rdbms/admin/utlxplan.sql
查看现在的真实执行计划--SHARE POOL
v$sql_plan
v$sql_plan_statistics
v$sql_workarea
v$sql_plan_statistics_all
select count() from t10;
select sql_id,child_number,sql_text from v$sql where sql_text like '%select count() from t10%' and sql_text not like '%v$sql%';
select * from table(dbms_xplan.display_cursor('fu9fh7nx72xx8',0,'advanced'));
或
#特殊执行计划
ALTER SESSION SET STATISTICS_LEVEL=ALL;
执行待分析的SQL
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));
或
select * from table(dbms_xplan.display_cursor(null,null,'advanced')); --得到的信息更详细
查看过去的真实执行计划--AWR
查询自动工作量资料库(Automatic Workload Repository)或查询Statspack表,它显示存储在资料库中的执行计划
dba_hist_sql_plan
select * from table(dbms_xplan.display_awr('gwq01ynnbm5aj'));
执行计划分析
访问路径方法
表访问操作:
TABLE ACCESS FULL #全表扫描,通过完全扫描的方式访问表
TABLE ACCESS BY INDEX ROWID #通过由索引中获取的ROWID访问表
索引访问操作:
INDEX FULL SCAN # 全索引扫描,即对索引进行完全扫描访问
表连接方式
MERGE JOIN
要进行排序合并,必须有一个前提:两边数据集中数据都已经按照关联字段排序,
否则,优化器会加上一个排序操作(SORT JOIN),使数据集按照关联字段排序。
MERGE JOIN实现过程:从两边数据集的第一条记录开始匹配,如果数值相同,则返回记录;
如果外数据记录中的数值小于内数据记录,则外数据集的游标向下移,读取下一条记录进行匹配;
否则,内数据集的游标向下移,读取下一条记录进行匹配。
*谓词过滤信息
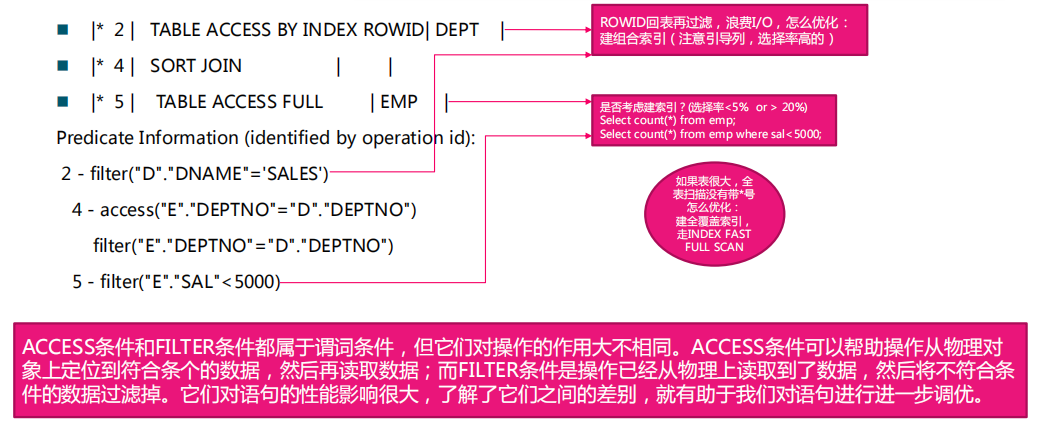
执行计划的访问路径
访问路径的基本类型
指的是ORACLE通过哪种方式去获取数据,比如通过全表扫描,索引扫描,或者通过ROWID获取数据
全表扫描(TABLE ACCESS FULL) 索引扫描
ROWID扫描
全表扫描(TABLE ACCESS FULL)
等待事件:db file scattered read
alter session set statistics_level=all; select count(*) from t1;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
索引扫描
索引唯一扫描(INDEX UNIQUE SCAN)
索引范围扫描(INDEX RANGE SCAN)
索引全扫描(INDEX FULL SCAN)
索引快速全扫描(INDEX FAST FULL SCAN)
索引跳跃式扫描(INDEX SKIP SCAN)
索引降序范围扫描(INDEX RANGE SCAN DESCENDING)
索引唯一扫描(INDEX UNIQUE SCAN)
等待事件:db file squential read
create unique index index_t1 on t1(id);
alter session set statistics_level=all;
select id,name from t1 where id=1; select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
索引范围扫描(INDEX RANGE SCAN)
等待事件:db file squential read
alter session set statistics_level=all;
select id,name from t1 where id>=1 and id<=100; select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
HINT: INDEX(表名/别名 索引名)
索引全扫描(INDEX FULL SCAN)
等待事件:db file squential read
alter session set statistics_level=all;
select/*+ INDEX (t1 index_t1) */ id from t1 where id is not null;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
索引快速全扫描(INDEX FAST FULL SCAN)
等待事件:db file scattered read(多块读)
HINT:INDEX_FFS(表名/别名 索引名)
alter session set statistics_level=all;
select /*+ INDEX_FFS(t1 INDEX_T1) */ id from t1 where id is not null;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
索引跳跃式扫描(INDEX SKIP SCAN)
只可能发生在组合索引上,引导列没有包含在where条件中,并且引导列基数很低
HINT: INDEX_SS(表名/别名 索引名)
create index index_id_name on t1(id,name);
Alter table t1 add (addr varchar2(10));
alter session set statistics_level=all;
select/*+ INDEX_SS(t1 index_id_name) */ * from t1 where NAME='gyj9992';
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
索引降序范围扫描(INDEX RANGE SCAN DESCENDING)
等待事件:db file squential read
HINT:INDEX_DESC(表名/别名 索引名)
alter session set statistics_level=all;
select /*+ index_desc(t1 index_t1) */id,name from t1 where id is not null order by id desc ;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
执行计划的控制
加提示
稳固计划
sql概要(sqlprofile) 改变统计信息
设置优化器模式相关的参数
基线(baseline)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号