exp/imp、expdp/impdp、SQL*Loader
exp/imp
exp
语法帮助:
[oracle@db1 ~]$ exp help=y
Export: Release 19.0.0.0.0 - Production on 星期五 5月 20 20:33:23 2022
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.
通过输入 EXP 命令和您的用户名/口令, 导出
操作将提示您输入参数:
例如: EXP SCOTT/TIGER
或者, 您也可以通过输入跟有各种参数的 EXP 命令来控制导出
的运行方式。要指定参数, 您可以使用关键字:
格式: EXP KEYWORD=value 或 KEYWORD=(value1,value2,...,valueN)
例如: EXP SCOTT/TIGER GRANTS=Y TABLES=(EMP,DEPT,MGR)
或 TABLES=(T1:P1,T1:P2), 如果 T1 是分区表
USERID 必须是命令行中的第一个参数。
关键字 说明 (默认值) 关键字 说明 (默认值)
--------------------------------------------------------------------------
USERID 用户名/口令 FULL 导出整个文件 (N)
BUFFER 数据缓冲区大小 OWNER 所有者用户名列表
FILE 输出文件 (EXPDAT.DMP) TABLES 表名列表
COMPRESS 导入到一个区 (Y) RECORDLENGTH IO 记录的长度
GRANTS 导出权限 (Y) INCTYPE 增量导出类型
INDEXES 导出索引 (Y) RECORD 跟踪增量导出 (Y)
DIRECT 直接路径 (N) TRIGGERS 导出触发器 (Y)
LOG 屏幕输出的日志文件 STATISTICS 分析对象 (ESTIMATE)
ROWS 导出数据行 (Y) PARFILE 参数文件名
CONSISTENT 交叉表的一致性 (N) CONSTRAINTS 导出的约束条件 (Y)
OBJECT_CONSISTENT 只在对象导出期间设置为只读的事务处理 (N)
FEEDBACK 每 x 行显示进度 (0)
FILESIZE 每个转储文件的最大大小
FLASHBACK_SCN 用于将会话快照设置回以前状态的 SCN
FLASHBACK_TIME 用于获取最接近指定时间的 SCN 的时间
QUERY 用于导出表的子集的 select 子句
RESUMABLE 遇到与空格相关的错误时挂起 (N)
RESUMABLE_NAME 用于标识可恢复语句的文本字符串
RESUMABLE_TIMEOUT RESUMABLE 的等待时间
TTS_FULL_CHECK 对 TTS 执行完整或部分相关性检查
VOLSIZE 写入每个磁带卷的字节数
TABLESPACES 要导出的表空间列表
TRANSPORT_TABLESPACE 导出可传输的表空间元数据 (N)
TEMPLATE 调用 iAS 模式导出的模板名
示例:
1 将数据库TEST完全导出,用户名system 密码manager 导出到D:\daochu.dmp中
exp system/manager@TEST file=d:\daochu.dmp full=y
2 将数据库中system用户与sys用户的表导出
exp system/manager@TEST file=d:\daochu.dmp owner=(system,sys)
3 将数据库中的表table1 、table2导出
exp system/manager@TEST file=d:\daochu.dmp tables=(table1,table2)
4 将数据库中的表table1中的字段filed1以”00″打头的数据导出
exp system/manager@TEST file=d:\daochu.dmp tables=(table1) query=query='WHERE deptno=20';
imp
语法帮助:
[oracle@db1 ~]$ imp help=y
Import: Release 19.0.0.0.0 - Production on 星期五 5月 20 20:44:55 2022
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.
通过输入 IMP 命令和您的用户名/口令, 导入
操作将提示您输入参数:
例如: IMP SCOTT/TIGER
或者, 可以通过输入 IMP 命令和各种参数来控制导入
的运行方式。要指定参数, 您可以使用关键字:
格式: IMP KEYWORD=value 或 KEYWORD=(value1,value2,...,valueN)
例如: IMP SCOTT/TIGER IGNORE=Y TABLES=(EMP,DEPT) FULL=N
或 TABLES=(T1:P1,T1:P2), 如果 T1 是分区表
USERID 必须是命令行中的第一个参数。
关键字 说明 (默认值) 关键字 说明 (默认值)
--------------------------------------------------------------------------
USERID 用户名/口令 FULL 导入整个文件 (N)
BUFFER 数据缓冲区大小 FROMUSER 所有者用户名列表
FILE 输入文件 (EXPDAT.DMP) TOUSER 用户名列表
SHOW 只列出文件内容 (N) TABLES 表名列表
IGNORE 忽略创建错误 (N) RECORDLENGTH IO 记录的长度
GRANTS 导入权限 (Y) INCTYPE 增量导入类型
INDEXES 导入索引 (Y) COMMIT 提交数组插入 (N)
ROWS 导入数据行 (Y) PARFILE 参数文件名
LOG 屏幕输出的日志文件 CONSTRAINTS 导入限制 (Y)
DESTROY 覆盖表空间数据文件 (N)
INDEXFILE 将表/索引信息写入指定的文件
SKIP_UNUSABLE_INDEXES 跳过不可用索引的维护 (N)
FEEDBACK 每 x 行显示进度 (0)
TOID_NOVALIDATE 跳过指定类型 ID 的验证
FILESIZE 每个转储文件的最大大小
STATISTICS 始终导入预计算的统计信息
RESUMABLE 在遇到有关空间的错误时挂起 (N)
RESUMABLE_NAME 用来标识可恢复语句的文本字符串
RESUMABLE_TIMEOUT RESUMABLE 的等待时间
COMPILE 编译过程, 程序包和函数 (Y)
STREAMS_CONFIGURATION 导入流的一般元数据 (Y)
STREAMS_INSTANTIATION 导入流实例化元数据 (N)
DATA_ONLY 仅导入数据 (N)
VOLSIZE 磁带的每个文件卷上的文件的字节数
下列关键字仅用于可传输的表空间
TRANSPORT_TABLESPACE 导入可传输的表空间元数据 (N)
TABLESPACES 将要传输到数据库的表空间
DATAFILES 将要传输到数据库的数据文件
TTS_OWNERS 拥有可传输表空间集中数据的用户
成功终止导入, 没有出现警告。
常用的有:
ignore=y commit=y
示例:
1 将D:\daochu.dmp 中的数据导入 TEST数据库中。
imp system/manager@TEST file=d:\daochu.dmp
ignore=y 忽略错误
2 将d:\daochu.dmp中的表table1 导入
imp system/manager@TEST file=d:\daochu.dmp tables=(table1)
expdp/impdp
expdp
帮助信息:
[oracle@db1 ~]$ expdp help=y
Export: Release 19.0.0.0.0 - Production on 星期五 5月 20 20:49:29 2022
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.
数据泵导出实用程序提供了一种用于在 Oracle 数据库之间传输
数据对象的机制。该实用程序可以使用以下命令进行调用:
示例: expdp scott/tiger DIRECTORY=dmpdir DUMPFILE=scott.dmp
您可以控制导出的运行方式。具体方法是: 在 'expdp' 命令后输入
各种参数。要指定各参数, 请使用关键字:
格式: expdp KEYWORD=value 或 KEYWORD=(value1,value2,...,valueN)
示例: expdp scott/tiger DUMPFILE=scott.dmp DIRECTORY=dmpdir SCHEMAS=scott
或 TABLES=(T1:P1,T1:P2), 如果 T1 是分区表
USERID 必须是命令行中的第一个参数。
------------------------------------------------------------------------------
以下是可用关键字和它们的说明。方括号中列出的是默认值。
ABORT_STEP
在初始化作业后停止作业, 或者在指示的对象中停止作业。
有效值为 -1 或 N, 此处 N 为大于等于零的值。
N 对应于对象在主表中的进程顺序号。
ACCESS_METHOD
指示导出操作使用特定方法来卸载数据。
有效的关键字值为: [AUTOMATIC], DIRECT_PATH 和 EXTERNAL_TABLE。
ATTACH
连接到现有作业。
例如, ATTACH=job_name。
CLUSTER
利用集群资源并将 worker 进程分布在 Oracle RAC 上 [YES]。
COMPRESSION
减少转储文件大小。
有效的关键字值为: ALL, DATA_ONLY, [METADATA_ONLY] 和 NONE。
COMPRESSION_ALGORITHM
指定应使用的压缩算法。
有效的关键字值为: [BASIC], LOW, MEDIUM 和 HIGH。
CONTENT
指定要卸载的数据。
有效的关键字值为: [ALL], DATA_ONLY 和 METADATA_ONLY。
DATA_OPTIONS
数据层选项标记。
有效的关键字值为: GROUP_PARTITION_TABLE_DATA, VERIFY_STREAM_FORMAT 和 XML_CLOBS。
DIRECTORY
用于转储文件和日志文件的目录对象。
DUMPFILE
指定目标转储文件名的列表 [expdat.dmp]。
例如, DUMPFILE=scott1.dmp, scott2.dmp, dmpdir:scott3.dmp。
ENCRYPTION
加密某个转储文件的一部分或全部。
有效的关键字值为: ALL, DATA_ONLY, ENCRYPTED_COLUMNS_ONLY, METADATA_ONLY 和 NONE。
ENCRYPTION_ALGORITHM
指定加密的方式。
有效的关键字值为: [AES128], AES192 和 AES256。
ENCRYPTION_MODE
生成加密密钥的方法。
有效的关键字值为: DUAL, PASSWORD 和 [TRANSPARENT]。
ENCRYPTION_PASSWORD
用于在转储文件中创建加密数据的口令密钥。
ENCRYPTION_PWD_PROMPT
指定是否提示输入加密口令 [NO]。
当标准输入为读取时, 将隐藏终端回送。
ESTIMATE
计算作业估计值。
有效的关键字值为: [BLOCKS] 和 STATISTICS。
ESTIMATE_ONLY
计算作业估计值而不执行导出 [NO]。
EXCLUDE
排除特定对象类型。
例如, EXCLUDE=SCHEMA:"='HR'"。
FILESIZE
以字节为单位指定每个转储文件的大小。
FLASHBACK_SCN
用于重置会话快照的 SCN。
FLASHBACK_TIME
用于查找最接近的相应 SCN 值的时间。
FULL
导出整个数据库 [NO]。
HELP
显示帮助消息 [NO]。
INCLUDE
包括特定对象类型。
例如, INCLUDE=TABLE_DATA。
JOB_NAME
要创建的导出作业的名称。
KEEP_MASTER
在成功完成导出作业后保留主表 [NO]。
LOGFILE
指定日志文件名 [export.log]。
LOGTIME
指定要给在导出操作期间显示的消息加时间戳。
有效的关键字值为: ALL, [NONE], LOGFILE 和 STATUS。
METRICS
将其他作业信息报告到导出日志文件 [NO]。
NETWORK_LINK
源系统的远程数据库链接的名称。
NOLOGFILE
不写入日志文件 [NO]。
PARALLEL
更改当前作业的活动 worker 的数量。
PARFILE
指定参数文件名。
QUERY
用于导出表的子集的谓词子句。
例如, QUERY=employees:"WHERE department_id > 10"。
REMAP_DATA
指定数据转换函数。
例如, REMAP_DATA=EMP.EMPNO:REMAPPKG.EMPNO。
REUSE_DUMPFILES
覆盖目标转储文件 (如果文件存在) [NO]。
SAMPLE
要导出的数据的百分比。
SCHEMAS
要导出的方案的列表 [登录方案]。
SERVICE_NAME
约束 Oracle RAC 资源的活动服务名和关联资源组。
SOURCE_EDITION
用于提取元数据的版本。
STATUS
监视作业状态的频率, 其中
默认值 [0] 表示只要有新状态可用, 就立即显示新状态。
TABLES
标识要导出的表的列表。
例如, TABLES=HR.EMPLOYEES,SH.SALES:SALES_1995。
TABLESPACES
标识要导出的表空间的列表。
TRANSPORTABLE
指定是否可以使用可传输方法。
有效的关键字值为: ALWAYS 和 [NEVER]。
TRANSPORT_FULL_CHECK
验证所有表的存储段 [NO]。
TRANSPORT_TABLESPACES
要从中卸载元数据的表空间的列表。
VERSION
要导出的对象版本。
有效的关键字值为: [COMPATIBLE], LATEST 或任何有效的数据库版本。
VIEWS_AS_TABLES
标识要作为表导出的一个或多个视图。
例如, VIEWS_AS_TABLES=HR.EMP_DETAILS_VIEW。
------------------------------------------------------------------------------
下列命令在交互模式下有效。
注: 允许使用缩写。
ADD_FILE
将转储文件添加到转储文件集。
CONTINUE_CLIENT
返回到事件记录模式。如果处于空闲状态, 将重新启动作业。
EXIT_CLIENT
退出客户机会话并使作业保持运行状态。
FILESIZE
用于后续 ADD_FILE 命令的默认文件大小 (字节)。
HELP
汇总交互命令。
KILL_JOB
分离并删除作业。
PARALLEL
更改当前作业的活动 worker 的数量。
REUSE_DUMPFILES
覆盖目标转储文件 (如果文件存在) [NO]。
START_JOB
启动或恢复当前作业。
有效的关键字值为: SKIP_CURRENT。
STATUS
监视作业状态的频率, 其中
默认值 [0] 表示只要有新状态可用, 就立即显示新状态。
STOP_JOB
按顺序关闭作业执行并退出客户机。
有效的关键字值为: IMMEDIATE。
STOP_WORKER
停止挂起或粘滞的 worker。
TRACE
为当前作业设置跟踪/调试标记。
version参数
导入导出时带上版本号,可以跨版本导入:
version=19.3.0.0.0
使用目录(目录要存在)
CREATE OR REPLACE DIRECTORY DUMPDIR AS '/oracle/impdp';
select * from dba_directories;
GRANT READ,WRITE ON DIRECTORY DUMPDIR TO username;
sys用户:\'sys/oralce as sysdba\'
1)按用户导
expdp scott/tiger@orcl schemas=scott dumpfile=expdp.dmp DIRECTORY=dpdata1;
2)并行进程parallel
expdp scott/tiger@orcl directory=dpdata1 dumpfile=scott3.dmp parallel=40 job_name=scott3
3)按表名导
expdp scott/tiger@orcl TABLES=emp,dept dumpfile=expdp.dmp DIRECTORY=dpdata1;
4)按查询条件导
expdp scott/tiger@orcl directory=dpdata1 dumpfile=expdp.dmp Tables=emp query='WHERE deptno=20';
5)按表空间导
expdp system/manager DIRECTORY=dpdata1 DUMPFILE=tablespace.dmp TABLESPACES=temp,example;
6)导整个数据库
expdp system/manager DIRECTORY=dpdata1 DUMPFILE=full.dmp FULL=y;
impdp
帮助语法:
[oracle@db1 ~]$ impdp help=y
Import: Release 19.0.0.0.0 - Production on 星期五 5月 20 20:55:33 2022
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.
数据泵导入实用程序提供了一种用于在 Oracle 数据库之间传输
数据对象的机制。该实用程序可以使用以下命令进行调用:
示例: impdp scott/tiger DIRECTORY=dmpdir DUMPFILE=scott.dmp
您可以控制导入的运行方式。具体方法是: 在 'impdp' 命令后输入
各种参数。要指定各参数, 请使用关键字:
格式: impdp KEYWORD=value 或 KEYWORD=(value1,value2,...,valueN)
示例: impdp scott/tiger DIRECTORY=dmpdir DUMPFILE=scott.dmp
USERID 必须是命令行中的第一个参数。
------------------------------------------------------------------------------
以下是可用关键字和它们的说明。方括号中列出的是默认值。
ABORT_STEP
在初始化作业后停止作业, 或者在指示的对象中停止作业。
有效值为 -1 或 N, 此处 N 为大于等于零的值。
N 对应于对象在主表中的进程顺序号。
ACCESS_METHOD
指示导入操作使用特定方法来加载数据。
有效的关键字值为: [AUTOMATIC], CONVENTIONAL, DIRECT_PATH,
EXTERNAL_TABLE, 和 INSERT_AS_SELECT。
ATTACH
连接到现有作业。
例如, ATTACH=job_name。
CLUSTER
利用集群资源并将 worker 进程分布在 Oracle RAC 上 [YES]。
CONTENT
指定要加载的数据。
有效的关键字为: [ALL], DATA_ONLY 和 METADATA_ONLY。
DATA_OPTIONS
数据层选项标记。
有效的关键字为: DISABLE_APPEND_HINT, ENABLE_NETWORK_COMPRESSION,
REJECT_ROWS_WITH_REPL_CHAR, SKIP_CONSTRAINT_ERRORS, CONTINUE_LOAD_ON_FORMAT_ERROR,
TRUST_EXISTING_TABLE_PARTITIONS and VALIDATE_TABLE_DATA。
DIRECTORY
用于转储文件, 日志文件和 SQL 文件的目录对象。
DUMPFILE
要从中导入的转储文件的列表 [expdat.dmp]。
例如, DUMPFILE=scott1.dmp, scott2.dmp, dmpdir:scott3.dmp。
ENCRYPTION_PASSWORD
用于访问转储文件中的加密数据的口令密钥。
对于网络导入作业无效。
ENCRYPTION_PWD_PROMPT
指定是否提示输入加密口令 [NO]。
当标准输入为读取时, 将隐藏终端回送。
ESTIMATE
计算网络作业估计值。
有效的关键字为: [BLOCKS] 和 STATISTICS。
EXCLUDE
排除特定对象类型。
例如, EXCLUDE=SCHEMA:"='HR'"。
FLASHBACK_SCN
用于重置会话快照的 SCN。
FLASHBACK_TIME
用于查找最接近的相应 SCN 值的时间。
FULL
导入源中的所有对象 [YES]。
HELP
显示帮助消息 [NO]。
INCLUDE
包括特定对象类型。
例如, INCLUDE=TABLE_DATA。
JOB_NAME
要创建的导入作业的名称。
KEEP_MASTER
在成功完成导入作业后保留主表 [NO]。
LOGFILE
日志文件名 [import.log]。
LOGTIME
指定要给在导入操作期间显示的消息加时间戳。
有效的关键字值为: ALL, [NONE], LOGFILE 和 STATUS。
MASTER_ONLY
只导入主表, 然后停止作业 [NO]。
METRICS
将其他作业信息报告到导入日志文件 [NO]。
NETWORK_LINK
源系统的远程数据库链接的名称。
NOLOGFILE
不写入日志文件 [NO]。
PARALLEL
更改当前作业的活动 worker 的数量。
PARFILE
指定参数文件。
PARTITION_OPTIONS
指定应如何转换分区。
有效的关键字为: DEPARTITION, MERGE 和 [NONE]。
QUERY
用于导入表的子集的谓词子句。
例如, QUERY=employees:"WHERE department_id > 10"。
REMAP_DATA
指定数据转换函数。
例如, REMAP_DATA=EMP.EMPNO:REMAPPKG.EMPNO。
REMAP_DATAFILE
在所有 DDL 语句中重新定义数据文件引用。
REMAP_SCHEMA
将一个方案中的对象加载到另一个方案。
REMAP_TABLE
将表名重新映射到另一个表。
例如, REMAP_TABLE=HR.EMPLOYEES:EMPS。
REMAP_TABLESPACE
将表空间对象重新映射到另一个表空间。
REUSE_DATAFILES
如果表空间已存在, 则将其初始化 [NO]。
SCHEMAS
要导入的方案的列表。
SERVICE_NAME
约束 Oracle RAC 资源的活动服务名和关联资源组。
SKIP_UNUSABLE_INDEXES
跳过设置为“索引不可用”状态的索引。
SOURCE_EDITION
用于提取元数据的版本。
SQLFILE
将所有的 SQL DDL 写入指定的文件。
STATUS
监视作业状态的频率, 其中
默认值 [0] 表示只要有新状态可用, 就立即显示新状态。
STREAMS_CONFIGURATION
启用流元数据的加载 [YES]。
TABLE_EXISTS_ACTION
导入对象已存在时执行的操作。
有效的关键字为: APPEND, REPLACE, [SKIP] 和 TRUNCATE。
TABLES
标识要导入的表的列表。
例如, TABLES=HR.EMPLOYEES,SH.SALES:SALES_1995。
TABLESPACES
标识要导入的表空间的列表。
TARGET_EDITION
用于加载元数据的版本。
TRANSFORM
要应用于适用对象的元数据转换。
有效的关键字为: DISABLE_ARCHIVE_LOGGING, INMEMORY, INMEMORY_CLAUSE,
LOB_STORAGE, OID, PCTSPACE, SEGMENT_ATTRIBUTES, SEGMENT_CREATION,
STORAGE, 和 TABLE_COMPRESSION_CLAUSE。
TRANSPORTABLE
用于选择可传输数据移动的选项。
有效的关键字为: ALWAYS 和 [NEVER]。
仅在 NETWORK_LINK 模式导入操作中有效。
TRANSPORT_DATAFILES
按可传输模式导入的数据文件的列表。
TRANSPORT_FULL_CHECK
验证所有表的存储段 [NO]。
仅在 NETWORK_LINK 模式导入操作中有效。
TRANSPORT_TABLESPACES
要从中加载元数据的表空间的列表。
仅在 NETWORK_LINK 模式导入操作中有效。
VERSION
要导入的对象的版本。
有效的关键字为: [COMPATIBLE], LATEST 或任何有效的数据库版本。
仅对 NETWORK_LINK 和 SQLFILE 有效。
VIEWS_AS_TABLES
标识要作为表导入的一个或多个视图。
例如, VIEWS_AS_TABLES=HR.EMP_DETAILS_VIEW.
请注意, 在网络导入模式下, 表名将附加到
视图名。
------------------------------------------------------------------------------
下列命令在交互模式下有效。
注: 允许使用缩写。
CONTINUE_CLIENT
返回到事件记录模式。如果处于空闲状态, 将重新启动作业。
EXIT_CLIENT
退出客户机会话并使作业保持运行状态。
HELP
汇总交互命令。
KILL_JOB
分离并删除作业。
PARALLEL
更改当前作业的活动 worker 的数量。
START_JOB
启动或恢复当前作业。
有效的关键字为: SKIP_CURRENT。
STATUS
监视作业状态的频率, 其中
默认值 [0] 表示只要有新状态可用, 就立即显示新状态。
STOP_JOB
按顺序关闭作业执行并退出客户机。
有效的关键字为: IMMEDIATE。
STOP_WORKER
停止挂起或粘滞的 worker。
TRACE
为当前作业设置跟踪/调试标记。
常用参数:
JOB_NAME
指定任务名,如果不指定的话,系统会默认自动命名:SYS_EXPORT_mode_nn,因为可以暂定,所以用一张表来存储相关信息,任务完成自动删除
TABLE_EXISTS_ACTION
导入对象已存在时执行的操作。
有效的关键字为: APPEND, REPLACE, [SKIP] 和 TRUNCATE。
SKIP:跳过这张表,继续下一个对象。如果CONTENT设置了DATA_ONLY参数,则不能使用SKIP。
APPEND:导入时对已存在表进行增量导入,追加
TRUNCATE:删除已存在的行,然后加载所有的数据。
REPLACE:drop已存在的表,然后create并加载数据。如果CONTENT设置了DATA_ONLY,则不能使用REPLACE。(生产环境慎用,可能造成丢失数据或者sequence问题)
使用 SKIP、APPEND 或 TRUNCATE 时,不会修改源中现有的表相关对象,例如索引、授权、触发器和约束。
对于 REPLACE,如果依赖对象未被显式或隐式排除(使用 EXCLUDE)并且它们存在于源转储文件或系统中,则会从源中删除并重新创建它们。
REMAP_TABLESPACE
将表空间对象重新映射到另一个表空间。
REMAP_TABLESPACE=source_tabpespace:target_tablespace
还有REMAP_TABLE、REMAP_SCHEMA用法都一样
示例:
1)导到指定用户下
impdp scott/tiger DIRECTORY=dpdata1 DUMPFILE=expdp.dmp SCHEMAS=scott;
2)改变表的owner
impdp system/manager DIRECTORY=dpdata1 DUMPFILE=expdp.dmp TABLES=scott.dept REMAP_SCHEMA=scott:system;
3)导入表空间
impdp system/manager DIRECTORY=dpdata1 DUMPFILE=tablespace.dmp TABLESPACES=example;
4)导入数据库
impdb system/manager DIRECTORY=dump_dir DUMPFILE=full.dmp FULL=y;
5)追加数据
impdp system/manager DIRECTORY=dpdata1 DUMPFILE=expdp.dmp SCHEMAS=system TABLE_EXISTS_ACTION
SQL*Loader
sqlload可以加载任何自由格式的文件,但需要繁琐的调整position控制数据分割,处理文本时并不方便,但是可以配合awk、sed、等文本工具处理后,在被sqlload加载。常用的仍然是使用csv文件。
SQL*Loader加载excel文件
由于excel保存数据的一种格式为“CSV(逗号分隔符)”,该文件类型通过指定的分隔符隔离各列的数据,这就为SQL*Loader加载excel的数据提供了可能。
示例:
有这样一个csv格式文件persons.csv
SQL> create table persons (code number(4),name varchar2(20),sex varchar2(4),age number(4));
编辑控制文件
vim persons.ctl
load data
infile '/home/oracle/persons.csv'
append into table persons
fields terminated by ','
(code,name,sex,age)
调用SQL*Loader加载数据
#使用sys用户注意引号
sqlldr "'sys/ether as sysdba'" control='/home/oracle/persons.ctl'
#一行都没有插入
[oracle@db1 ~]$ sqlldr "'sys/ether as sysdba'" control='/home/oracle/persons.ctl'
所用路径: 常规
达到提交点 - 逻辑记录计数 4
表 PERSONS:
已成功载入 0 行。
查看日志文件:
persons.log
了解有关加载的详细信息。
#查看日志
记录 1: 被拒绝 - 表 PERSONS 的列 AGE 出现错误。
ORA-01722: 无效数字
#原因在于\r\n在win和linux是不同的含义,在win中的回车为\r\n,而Linux中\n,它就表示回车+换行
#所以强行指定。也可以使用dos2unix指定文件,转化为linux的回车符
load data
infile '/home/oracle/persons.csv'
append into table persons
fields terminated by ','
(code,name,sex,age INTEGER EXTERNAL TERMINATED BY whitespace)
#重新执行,成功
[oracle@db1 ~]$ sqlldr "'sys/ether as sysdba'" control='/home/oracle/persons.ctl'
所用路径: 常规
达到提交点 - 逻辑记录计数 4
表 PERSONS:
已成功载入 4 行。
查看日志文件:
persons.log
了解有关加载的详细信息。
#查看数据
SQL> desc persons;
名称 是否为空? 类型
----------------------------------------- -------- ----------------------------
CODE NUMBER(4)
NAME VARCHAR2(20)
SEX VARCHAR2(4)
AGE NUMBER(4)
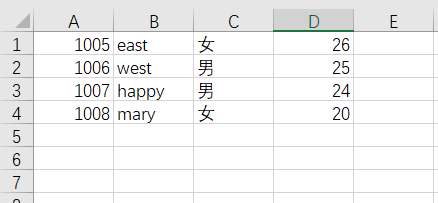
SQL> select * from persons;
CODE NAME SEX AGE
---------- -------------------- ---- ----------
1005 east 女 26
1006 west 男 25
1007 happy 男 24
1008 mary 女 20
帮助信息参考
[oracle@db1 ~]$ sqlldr
SQL*Loader: Release 19.0.0.0.0 - Production on 星期五 5月 20 22:00:06 2022
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.
用法: SQLLDR keyword=value [,keyword=value,...]
有效的关键字:
userid -- ORACLE 用户名/口令
control -- 控制文件名
log -- 日志文件名
bad -- 错误文件名
data -- 数据文件名
discard -- 废弃文件名
discardmax -- 允许废弃的文件的数目 (全部默认)
skip -- 要跳过的逻辑记录的数目 (默认 0)
load -- 要加载的逻辑记录的数目 (全部默认)
errors -- 允许的错误的数目 (默认 50)
rows -- 常规路径绑定数组中或直接路径保存数据间的行数
(默认: 常规路径 250, 所有直接路径)
bindsize -- 常规路径绑定数组的大小 (以字节计) (默认 1048576)
silent -- 运行过程中隐藏消息 (标题,反馈,错误,废弃,分区)
direct -- 使用直接路径 (默认 FALSE)
parfile -- 参数文件: 包含参数说明的文件的名称
parallel -- 执行并行加载 (默认 FALSE)
file -- 要从以下对象中分配区的文件
skip_unusable_indexes -- 不允许/允许使用无用的索引或索引分区 (默认 FALSE)
skip_index_maintenance -- 没有维护索引, 将受到影响的索引标记为无用 (默认 FALSE)
commit_discontinued -- 提交加载中断时已加载的行 (默认 FALSE)
readsize -- 读取缓冲区的大小 (默认 1048576)
external_table -- 使用外部表进行加载; NOT_USED, GENERATE_ONLY, EXECUTE
columnarrayrows -- 直接路径列数组的行数 (默认 5000)
streamsize -- 直接路径流缓冲区的大小 (以字节计) (默认 256000)
multithreading -- 在直接路径中使用多线程
resumable -- 对当前会话启用或禁用可恢复 (默认 FALSE)
resumable_name -- 有助于标识可恢复语句的文本字符串
resumable_timeout -- RESUMABLE 的等待时间 (以秒计) (默认 7200)
date_cache -- 日期转换高速缓存的大小 (以条目计) (默认 1000)
no_index_errors -- 出现任何索引错误时中止加载 (默认 FALSE)
partition_memory -- 开始溢出的直接路径分区内存限制 (kb) (默认 0)
table -- 用于快速模式加载的表
date_format -- 用于快速模式加载的日期格式
timestamp_format -- 用于快速模式加载的时间戳格式
terminated_by -- 由用于快速模式加载的字符终止
enclosed_by -- 由用于快速模式加载的字符封闭
optionally_enclosed_by -- (可选) 由用于快速模式加载的字符封闭
characterset -- 用于快速模式加载的字符集
degree_of_parallelism -- 用于快速模式加载和外部表加载的并行度
trim -- 用于快速模式加载和外部表加载的截取类型
csv -- 用于快速模式加载的 csv 格式数据文件
nullif -- 用于快速模式加载的表级 nullif 子句
field_names -- 用于快速模式加载的数据文件第一条记录字段名设置
dnfs_enable -- 启用或禁用输入数据文件 Direct NFS (dNFS) 的选项 (默认 FALSE)
dnfs_readbuffers -- Direct NFS (dNFS) 读缓冲区数 (默认 4)
sdf_prefix -- 要附加到每个 LOB 文件和辅助数据文件的开头的前缀
help -- 显示帮助消息 (默认 FALSE)
empty_lobs_are_null -- 将空白 LOB 设置为空值 (默认 FALSE)
defaults -- 直接路径默认值加载; EVALUATE_ONCE, EVALUATE_EVERY_ROW, IGNORE, IGNORE_UNSUPPORTED_EVALUATE_ONCE, IGNORE_UNSUPPORTED_EVALUATE_EVERY_ROW
direct_path_lock_wait -- 当前已锁定时, 等待表访问权限 (默认 FALSE)
PLEASE NOTE: 命令行参数可以由位置或关键字指定
。前者的例子是 'sqlldr
scott/tiger foo'; 后一种情况的一个示例是 'sqlldr control=foo
userid=scott/tiger'。位置指定参数的时间必须早于
但不可迟于由关键字指定的参数。例如,
允许 'sqlldr scott/tiger control=foo logfile=log', 但是
不允许 'sqlldr scott/tiger control=foo log', 即使
参数 'log' 的位置正确。
#######################
示例:
load data
infile '要导入的文件路径'
append into table 表名
FIELDS TERMINATED BY whitespace //数据中每行记录用 空格 分隔
trailing nullcols //表的字段没有对应的值时允许为空
(
字段1,
last_login DATE "YYYY-MM-DD HH24:MI:SS" //指定接受日期的格式,相当用 to_date() 函数转换
)
-- 1) insert --为缺省方式,在数据装载开始时要求表为空
-- 2) append --在表中追加新记录
-- 3) replace --删除旧记录(用 delete from table 语句),替换成新装载的记录
-- 4) truncate --删除旧记录(用 truncate table 语句),替换成新装载的记录
fields terminated by X'09'
---fields terminated by固定格式,字段终止于X'09',是一个制表符(TAB),如果是其他分割符如空格填写WHITESPACE,逗号改为‘,’

 浙公网安备 33010602011771号
浙公网安备 33010602011771号