Redis高可用方案
Redis安装及高可用
1.安装及配置
Redis 官网: https://redis.io/
Redis 中文网(更新比较慢): http://www.redis.cn/
1.1 安装
以centos7为例
#下载包
wget https://download.redis.io/releases/redis-6.2.5.tar.gz
#配置gcc,redis6需要gcc9
yum -y install centos-release-scl
yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
#临时将此时的gcc版本改为9
[root@localhost ~]# scl enable devtoolset-9 bash
#或永久改变
echo "source /opt/rh/devtoolset-9/enable" >>/etc/profile
#解压并安装
tar xf redis-6.0.6.tar.gz -C /usr/local/
mv /usr/local/redis-6.0.6/ /usr/local/redis
cd /usr/local/redis/
make
make install
#方便操作
cp src/redis-server src/redis-cli /usr/bin/
1.2 修改配置
需要修改redis.conf,初始化可以修改下面几项,其他根据需求调整
把文件中的daemonize属性改为yes(表明需要在后台运行),需要配置systemd启动时,一定要打开
daemonize yes
把 redis.conf配置文件中的 bind 127.0.0.1 这一行给注释掉,这里的bind指的是只有指定的网段才能远程访问这个redis,注释掉后,就没有这个限制了。(默认是bind 127.0.0.1 -::1,注释掉就行了)
#bind 127.0.0.1
端口号根据需求改
port 6379
把 redis.conf配置文件中的 protected-mode 设置成no(默认是设置成yes的, 防止了远程访问,在redis3.2.3版本后)
protected-mode no
修改Redis默认密码 (默认密码为空),在配置文件中找到这一行 # requirepass foobared,删除前面的注释符号#,并把foobared修改成自己的密码 或者 另起一行 requirepass 自己的密码
requirepass 123456
##protected-mode yes并不是说直接禁止远程访问
而是当下面两种情况同时存在是才会触发Redis的protected-mode
1.没有配置密码
2.没有bind一组地址
#配置文件中的
pidfile /var/run/redis_6379.pid
loglevel notice
logfile "/usr/local/redis/redis.log"
dir /usr/local/redis/
等根据情况选择合适的
内核参数配置
也可以根据日志中的警告来慢慢调整
#最少需要这些参数
vim /etc/sysctl.conf
vm.max_map_count=262144
net.core.somaxconn= 32768
vm.overcommit_memory=1
sysctl -p
1.3 配置开机自启
确保配置文件中:daemonize yes
#新建redis.service服务文件
#可以将配置多个配置文件,启动多个实例,文件名带上端口号来区分
[root@localhost ~]# vim /usr/lib/systemd/system/redis.service
[Unit]
Description=Redis Server Manager
After=syslog.target network.target
[Service]
Type=forking
ExecStart=/usr/local/redis/src/redis-server /usr/local/redis/redis.conf
ExecReload=/bin/kill -USR2 $MAINPID
ExecStop=/bin/kill -SIGINT $MAINPID
[Install]
WantedBy=multi-user.target
#reload systemctl
systemctl daemon-reload
#启动redis
systemctl start redis
systemctl enable redis
2.主从复制
类似于MYSQL的主从同步, 是将一台Redis服务器的数据(主节点)复制到其他的Redis服务器上(从节点),且数据的复制是单向的,只能由主节点到从节点。Redis 主从复制支持 主从同步 和 从从同步 两种,后者是 Redis 后续版本新增的功能,以减轻主节点的同步负担。
https://redis.io/topics/replication
2.1 主从复制原理
1.slave节点初次启动时主动向master发起TCP连接,并发起同步请求(psync命令), master接收连接(可要求授权认证),并将slave的信息保存起来。
2.master节点收到同步请求,执行BGSAVE命令生成rdb文件,文件生成后发送给slave。
3.slave收到后首先清楚自己的旧数据, 然后载入收到的rdb文件, slave更新至master执行bgsave命令前的状态。
4.master将保存rdb文件期间收到的写命令发送给slave, slave更新至主节点的最新状态。
5.此后master每有写命令,就会主动发送给slave节点。
主从节点会分别维护一个复制便宜量(复制的字节数), 当出现网络中断等情况时,重连后会从偏移量处开始进行部分复制,避免了全量复制的重型操作。
2.2 主从复制配置
主从复制master节点不需要做任何配置, 只需要在slave的配置文件中加入: slaveof <masterip> <masterport>
masterauth <master-password>
slaveof no one 将使得这个从属服务器关闭复制功能,并从从属服务器转变回主服务器,原来同步所得的数据集不会被丢弃。
作为从时,从节点是不允许写入的
利用『 SLAVEOF NO ONE 不会丢弃同步所得数据集』这个特性,可以在主服务器失败的时候,将从属服务器用作新的主服务器,从而实现无间断运行。
除了slaveof之外也可以用replicaof <masterip> <masterport>
5.0之后建议使用replicaof
从节点启动时就会自动向主节点发起连接,完成主从同步的一系列过程。
也可以在命令行中配置,但仅本次生效
查看主从信息:
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.250.121,port=6381,state=online,offset=276,lag=1
master_failover_state:no-failover
master_replid:40f533a2d673cf8428ba32a1a02d5b588fef9730
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:276
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:276
2.3 主从优缺点
优点
主从复制提供了基本的数据多节点备份功能, 当主节点发生故障时,可以启用从节点继续提供服务。
缺点
无法实现故障的自动切换, 主节点故障时,需要手动将程序(客户端)的配置从主节点切换为从节点,然后重启客户端程序。
主从复制的机制是其他高可用方式的基础
3.哨兵模式(Redis Sentinel)
哨兵模式官网文档:https://redis.io/topics/sentinel
- 哨兵节点: 哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的 Redis 节点,不存储数据。
- 数据节点: 主节点和从节点都是数据节点。
哨兵方式在主从复制的基础上, 实现了故障自动切换的功能:
- 监控(Monitoring): 哨兵会不断地检查主节点和从节点是否运作正常。
- 自动故障转移(Automatic failover): 当 主节点 不能正常工作时,哨兵会开始 自动故障转移操作,它会将失效主节点的其中一个 从节点升级为新的主节点,并让其他从节点改为复制新的主节点。
- 配置提供者(Configuration provider): 客户端在初始化时,通过连接哨兵来获得当前 Redis 服务的主节点地址。
- 通知(Notification): 哨兵可以将故障转移的结果发送给客户端。
Redis Sentinel 集群是由若干 Sentinel 节点组成的分布式集群,可以实现故障发现、故障自动转移、配置中心和客户端通知。Redis Sentinel 的节点数量要满足 2n+1(n>=1)的奇数个。
3.1 哨兵模式作用
主从同步/复制的模式,当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用,这时候就需要哨兵模式登场了。哨兵模式是从 Redis 的 2.6 版本开始提供的,但是当时这个版本的模式是不稳定的,直到 Redis 的 2.8 版本以后,这个哨兵模式才稳定下来。
哨兵模式核心还是主从复制,只不过在相对于主从模式在主节点宕机导致不可写的情况下,多了一个竞选机制:从所有的从节点竞选出新的主节点。竞选机制的实现,是依赖于在系统中启动一个 sentinel 进程。
哨兵本身也有单点故障的问题,所以在一个一主多从的 Redis 系统中,可以使用多个哨兵进行监控,哨兵不仅会监控主数据库和从数据库,哨兵之间也会相互监控。每一个哨兵都是一个独立的进程,作为进程,它会独立运行。
哨兵模式的作用:
- 监控所有服务器是否正常运行:通过发送命令返回监控服务器的运行状态,处理监控主服务器、从服务器外,哨兵之间也相互监控。
- 故障切换:当哨兵监测到 master 宕机,会自动将 slave 切换成 master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换 master。同时那台有问题的旧主也会变为新主的从,也就是说当旧的主即使恢复时,并不会恢复原来的主身份,而是作为新主的一个从。
3.2 哨兵模式原理
哨兵在启动进程时,会读取配置文件的内容,通过如下的配置找出需要监控的主数据库:
sentinel monitor master-name ip port quorum
# master-name 是主数据库的名字
# ip 和 port 是当前主数据库地址和端口号
# quorum 表示在执行故障切换操作前,需要多少哨兵节点同意。
这里之所以只需要连接主节点,是因为通过主节点的 info 命令,获取从节点信息,从而和从节点也建立连接,同时也能通过主节点的 info 信息知道新增从节点的信息。
一个哨兵节点可以监控多个主节点,但是并不提倡这么做,因为当哨兵节点崩溃时,同时有多个集群切换会发生故障。哨兵启动后,会与主数据库建立两条连接。
- 订阅主数据库
_sentinel_:hello频道以获取同样监控该数据库的哨兵节点信息 - 定期向主数据库发送
info命令,获取主数据库本身的信息。
跟主数据库建立连接后会定时执行以下三个操作:
- 每隔 10s 向 master 和 slave 发送 info 命令。作用是获取当前数据库信息,比如发现新增从节点时,会建立连接,并加入到监控列表中,当主从数据库的角色发生变化进行信息更新。
- 每隔 2s 向主数据里和从数据库的
_sentinel_:hello频道发送自己的信息。作用是将自己的监控数据和哨兵分享。每个哨兵会订阅数据库的_sentinel:hello频道,当其他哨兵收到消息后,会判断该哨兵是不是新的哨兵,如果是则将其加入哨兵列表,并建立连接。 - 每隔 1s 向所有主从节点和所有哨兵节点发送 ping 命令,作用是监控节点是否存活。
3.3 主观下线和客观下线
哨兵节点发送 ping 命令时,当超过一定时间(down-after-millisecond)后,如果节点未回复,则哨兵认为主观下线。主观下线表示当前哨兵认为该节点已经下线,如果该节点为主数据库,哨兵会进一步判断是够需要对其进行故障切换,这时候就要发送命令(SENTINEL is-master-down-by-addr)询问其他哨兵节点是否认为该主节点是主观下线,当达到指定数量(quorum)时,哨兵就会认为是客观下线。
当主节点客观下线时就需要进行主从切换,主从切换的步骤为:
- 选出领头哨兵。
- 领头哨兵所有的 slave 选出优先级最高的从数据库。优先级可以通过 slave-priority 选项设置。
- 如果优先级相同,则从复制的命令偏移量越大(即复制同步数据越多,数据越新),越优先。
- 如果以上条件都一样,则选择 run ID 较小的从数据库。
选出一个从数据库后,哨兵发送 slave no one 命令升级为主数据库,并发送slaveof 命令将其他从节点的主数据库设置为新的主数据库。
3.4 哨兵配置示例
配置哨兵时,最好禁用redis.conf中的requirepass,否则哨兵启动时会认为主机下线
或者需要在哨兵配置文件中增加sentinel auth-pass master-name password
这里的示例没有配置密码
以一主两从为例
首先建好主从
配置如下:
#redis-master.conf master配置
port 6379
daemonize yes
logfile "6379.log"
dbfilename "dump-6379.rdb"
#redis-slave1.conf slave1配置
port 6380
daemonize yes
logfile "6380.log"
dbfilename "dump-6380.rdb"
slaveof 127.0.0.1 6379
#redis-slave2.conf slave2配置
port 6381
daemonize yes
logfile "6381.log"
dbfilename "dump-6381.rdb"
slaveof 127.0.0.1 6379
启动各实例
redis-server redis-master.conf
redis-server redis-slave1.conf
redis-server redis-slave2.conf
配置哨兵节点的配置文件
redis的源码包下面有sentinel.conf文件,它是配置哨兵的示例文件,各种参数也有解释,可以根据它来配置合适的。
#redis-sentinel-6379.conf
port 26379
daemonize yes
logfile "26379.log"
dir /tmp
sentinel monitor mymaster 127.0.0.1 6379 2 #配置监视的Redis 主机,判断一个主机下线需要两个哨兵达成一致
sentinel down-after-milliseconds mymaster 30000 ##Redis主机断线5秒认为其下线
sentinel parallel-syncs mymaster 1 #选项指定了在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步
sentinel failover-timeout mymaster 180000 #故障转移超时时间
#redis-sentinel-6380.conf
port 26380
daemonize yes
logfile "26380.log"
dir /tmp
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
#redis-sentinel-6381.conf
port 26381
daemonize yes
logfile "26381.log"
dir /tmp
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
sentinel monitor mymaster 127.0.0.1 6379 2 配置的含义是:该哨兵节点监控 127.0.0.1:6379 这个主节点,该主节点的名称是 mymaster,最后的 2 的含义与主节点的故障判定有关:至少需要 2 个哨兵节点同意,才能判定主节点故障并进行故障转移。
sentinel monitor mymaster 127.0.0.1 6379 2 一旦配置之后,sentinel会通过检测主节点的状态来得知当前主节点的从节点有哪些
sentinel monitor配置中的建议设置成 Sentinel 节点的一半加 1,当 Sentinel 部署在多个 IDC 的时候,单个 IDC 部署的 Sentinel 数量不建议超过(Sentinel 数量 – quorum)。
一些参数参考:
1)sentinel monitor mymaster 192.168.10.202 6379 2
Sentine监听的maste地址,第一个参数是给master起的名字,第二个参数为master IP,第三个为master端口,第四个为当该master挂了的时候,若想将该master判为失效,
在Sentine集群中必须至少2个Sentine同意才行,只要该数量不达标,则就不会发生故障迁移。
2)sentinel down-after-milliseconds mymaster 30000
表示master被当前sentinel实例认定为失效的间隔时间,在这段时间内一直没有给Sentine返回有效信息,则认定该master主观下线。
只有在足够数量的 Sentinel 都将一个服务器标记为主观下线之后, 服务器才会被标记为客观下线,将服务器标记为客观下线所需的 Sentinel 数量由对主服务器的配置决定。
3)sentinel parallel-syncs mymaster 2
当在执行故障转移时,设置几个slave同时进行切换master,该值越大,则可能就有越多的slave在切换master时不可用,可以将该值设置为1,即一个一个来,这样在某个
slave进行切换master同步数据时,其余的slave还能正常工作,以此保证每次只有一个从服务器处于不能处理命令请求的状态。
4)sentinel can-failover mymaster yes
在sentinel检测到O_DOWN后,是否对这台redis启动failover机制
5)sentinel auth-pass mymaster 20180408
设置sentinel连接的master和slave的密码,这个需要和redis.conf文件中设置的密码一样
6)sentinel failover-timeout mymaster 180000
failover过期时间,当failover开始后,在此时间内仍然没有触发任何failover操作,当前sentinel将会认为此次failoer失败。
执行故障迁移超时时间,即在指定时间内没有大多数的sentinel 反馈master下线,该故障迁移计划则失效
7)sentinel config-epoch mymaster 0
选项指定了在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步。这个数字越小, 完成故障转移所需的时间就越长。
8)sentinel notification-script mymaster /var/redis/notify.sh
当failover时,可以指定一个"通知"脚本用来告知当前集群的情况。
脚本被允许执行的最大时间为60秒,如果超时,脚本将会被终止(KILL)
9)sentinel leader-epoch mymaster 0
同时一时间最多0个slave可同时更新配置,建议数字不要太大,以免影响正常对外提供服务。
启动哨兵
redis-sentinel redis-sentinel-6379.conf
redis-sentinel redis-sentinel-6380.conf
redis-sentinel redis-sentinel-6381.conf
由于sentinel节点也是一个redis实例,因而我们可以通过如下命令使用redis-cli连接sentinel节点:
连上sentinel节点之后我们可以通过如下命令查看sentinel状态:
[root@localhost ~]# redis-cli -p 26379
127.0.0.1:26379> info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=3
可以看到,sentinel检测到主从节点总共有三个,其中一个主节点,两个从节点,并且sentinel节点总共也有三个。启动完成之后,我们可以通过主动下线主节点来模拟sentinel的故障转移过程。
注意点
当完成哨兵配置,整个集群中的实例有变化时,会反应在配置文件上
除了可以redis-cli连上去看状态之外,也可以直接查看配置文件中的改变来查看集群关系状态
在配置完哨兵后,再看看配置文件变化
注意观察myid和sentinel known-sentinel mymaster
如果想了解过程,在log中有详细变化
#查看redis-sentinel-6379.conf
port 26379
daemonize yes
logfile "26379.log"
dir "/tmp"
sentinel monitor mymaster 127.0.0.1 6379 2
# Generated by CONFIG REWRITE
protected-mode no
pidfile "/var/run/redis.pid"
user default on nopass ~* &* +@all
sentinel myid 7e74f5731d16a5f7a4cdf3f21632bcaf420ea4e3
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 0
sentinel current-epoch 0
sentinel known-replica mymaster 127.0.0.1 6381
sentinel known-replica mymaster 127.0.0.1 6380
sentinel known-sentinel mymaster 127.0.0.1 26381 f609ffc98db177946a304048d120547d060b8f7b
sentinel known-sentinel mymaster 127.0.0.1 26380 bbd61766a5653a430201983483803188c5a564d3
#查看redis-sentinel-6380.conf
port 26380
daemonize yes
logfile "26380.log"
dir "/tmp"
sentinel monitor mymaster 127.0.0.1 6379 2
# Generated by CONFIG REWRITE
protected-mode no
pidfile "/var/run/redis.pid"
user default on nopass ~* &* +@all
sentinel myid bbd61766a5653a430201983483803188c5a564d3
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 0
sentinel current-epoch 0
sentinel known-replica mymaster 127.0.0.1 6381
sentinel known-replica mymaster 127.0.0.1 6380
sentinel known-sentinel mymaster 127.0.0.1 26381 f609ffc98db177946a304048d120547d060b8f7b
sentinel known-sentinel mymaster 127.0.0.1 26379 7e74f5731d16a5f7a4cdf3f21632bcaf420ea4e3
#查看redis-sentinel-6381.conf
port 26381
daemonize yes
logfile "26381.log"
dir "/tmp"
sentinel monitor mymaster 127.0.0.1 6379 2
# Generated by CONFIG REWRITE
protected-mode no
pidfile "/var/run/redis.pid"
user default on nopass ~* &* +@all
sentinel myid f609ffc98db177946a304048d120547d060b8f7b
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 0
sentinel current-epoch 0
sentinel known-replica mymaster 127.0.0.1 6380
sentinel known-replica mymaster 127.0.0.1 6381
sentinel known-sentinel mymaster 127.0.0.1 26380 bbd61766a5653a430201983483803188c5a564d3
sentinel known-sentinel mymaster 127.0.0.1 26379 7e74f5731d16a5f7a4cdf3f21632bcaf420ea4e3
3.5 模拟故障转移
一次故障转移操作由以下步骤组成:
- 发现主服务器已经进入客观下线状态。
- 对我们的当前纪元进行自增, 并尝试在这个纪元中当选。
- 如果当选失败, 那么在设定的故障迁移超时时间的两倍之后, 重新尝试当选。如果当选成功, 那么执行以下步骤。
- 选出一个从服务器,并将它升级为主服务器。
- 向被选中的从服务器发送 SLAVEOF NO ONE 命令,让它转变为主服务器。
- 通过发布与订阅功能, 将更新后的配置传播给所有其他 Sentinel , 其他 Sentinel 对它们自己的配置进行更新。
- 向已下线主服务器的从服务器发送 SLAVEOF 命令, 让它们去复制新的主服务器。
- 当所有从服务器都已经开始复制新的主服务器时, 领头 Sentinel 终止这次故障迁移操作。
示例:
当前6379是主,6380和6381两个从
[root@localhost ~]# redis-cli -p 6379
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=114256,lag=0
slave1:ip=127.0.0.1,port=6381,state=online,offset=114256,lag=1
master_failover_state:no-failover
master_replid:1389bb3b39fbf71c6e6542aa1d666e472b11e4d3
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:114389
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:114389
shutdown掉6379,查看转移状态
127.0.0.1:6379> shutdown save
not connected>
#查看6380,成为了主,81称为了从
127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6381,state=online,offset=138121,lag=0
master_failover_state:no-failover
master_replid:be8486d35851985a9af46671eec4dc97355a50b7
master_replid2:1389bb3b39fbf71c6e6542aa1d666e472b11e4d3
master_repl_offset:138121
second_repl_offset:130462
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:138121
恢复6379的redis服务,恢复之后并不会去抢占,而是作为从
[root@localhost ~]# redis-server redis-master.conf
[root@localhost ~]# redis-cli -p 6379
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6380
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:164940
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:be8486d35851985a9af46671eec4dc97355a50b7
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:164940
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:160221
repl_backlog_histlen:4720
#查看6379的配置文件
port 6379
daemonize yes
logfile "6379.log"
dbfilename "dump-6379.rdb"
# Generated by CONFIG REWRITE
pidfile "/var/run/redis.pid"
save 3600 1
save 300 100
save 60 10000
user default on nopass ~* &* +@all
dir "/root"
replicaof 127.0.0.1 6380
#再看看主6080的状态
127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6381,state=online,offset=187837,lag=0
slave1:ip=127.0.0.1,port=6379,state=online,offset=187704,lag=1
master_failover_state:no-failover
master_replid:be8486d35851985a9af46671eec4dc97355a50b7
master_replid2:1389bb3b39fbf71c6e6542aa1d666e472b11e4d3
master_repl_offset:187837
second_repl_offset:130462
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:187837
4.Redis Cluster
https://redis.io/topics/cluster-tutorial
4.1 集群分片和集群通信
4.1.1 hash slot
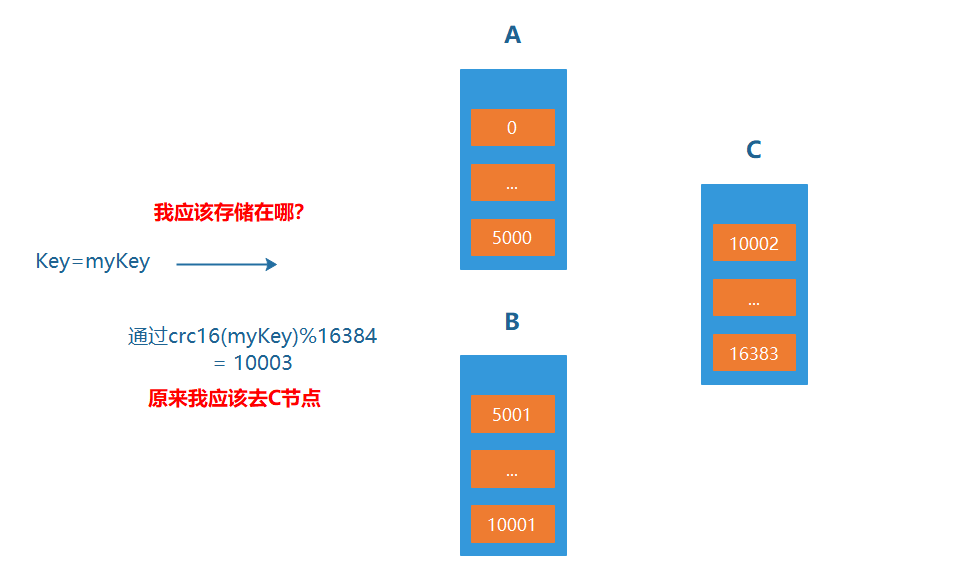
Redis-cluster引入了哈希槽的概念。
也就是对集群分片
Redis-cluster中有16384(即2的14次方)个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽。
Cluster中的每个节点负责一部分hash槽(hash slot)。
比如集群中存在三个节点,则可能存在的一种分配如下:
- 节点A包含0到5500号哈希槽;
- 节点B包含5501到11000号哈希槽;
- 节点C包含11001 到 16383号哈希槽。
4.1.2集群通信
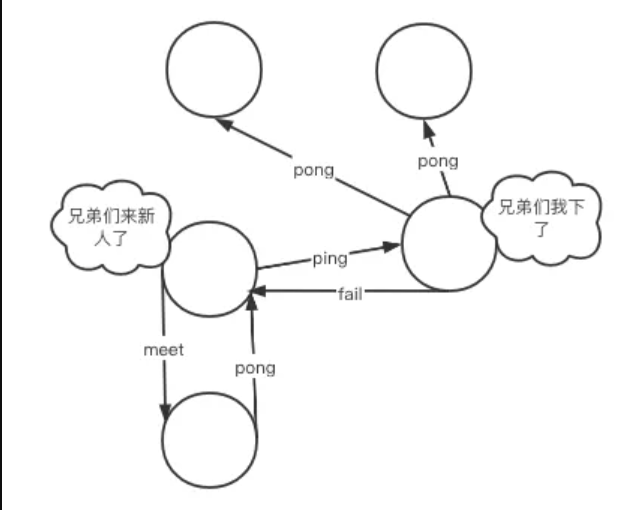
集群中各个节点的信息是互通的,这种现象由Gossip(流言)协议产生。
Gossip协议规定每个集群节点之间互相交换信息,使其能够彼此知道对方的状态。
在通信建立时,集群中的每一个节点都会单独的开辟一个TCP通道,用于与其他节点进行通信,这个通信端口会在基础端口上+10000。
通信建立成功后,每个节点在固定周期内通过特定规则选择节点来发送ping消息(心跳机制)。
当收到ping消息的节点则会使用pong消息作为回应,也就是说,当有一个新节点加入后,一瞬间集群中所有的其他节点也能够获取到该信息。
Gossip协议的主要职责就是进行集群中节点的信息交换,常见的Gossip协议消息有以下几点区分:
- meet:用于通知新节点加入,消息发送者通知接受者加入到当前集群
- ping:集群内每个节点与其他节点进行心跳检测的命令,用于检测其他节点是否在线,除此之外还能交换其他额外信息
- pong:用于回复meet以及ping信息,表示已收到,能够正常通行。此外还能进行群发更新节点状态
- fail:当其他节点收到fail消息后立马把对应节点更新为下线状态,此时集群开始进行故障转移
4.2 请求重定向
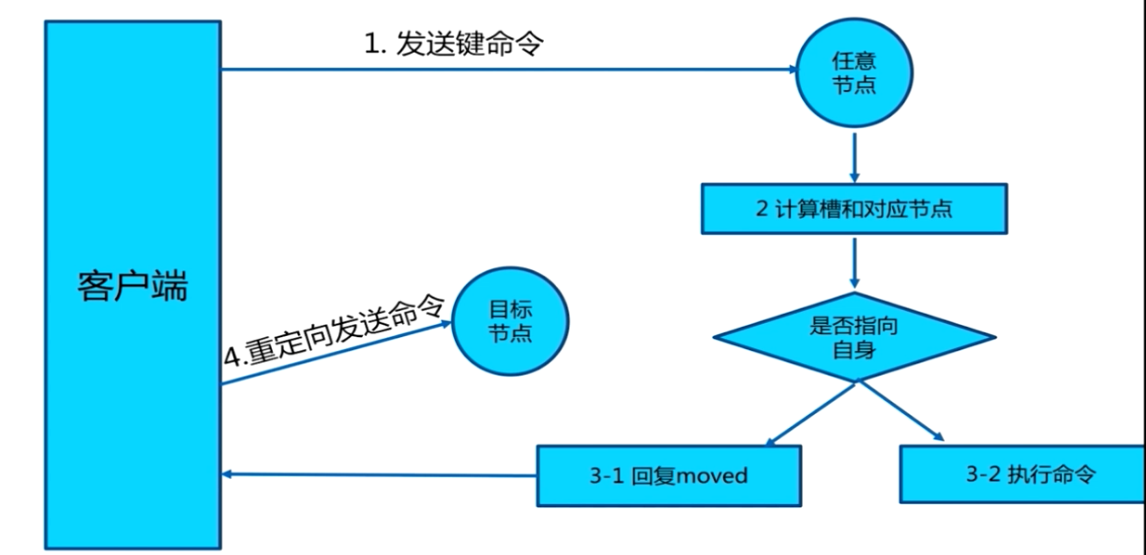
Redis cluster采用去中心化的架构,集群的主节点各自负责一部分槽,客户端如何确定key到底会映射到哪个节点上呢?
在cluster模式下,节点对请求的处理过程如下:
- 检查当前key是否存在当前NODE?
- 通过crc16(key)/16384计算出slot
- 查询负责该slot负责的节点,得到节点指针
- 该指针与自身节点比较
- 若slot不是由自身负责,则返回MOVED重定向
- 若slot由自身负责,且key在slot中,则返回该key对应结果
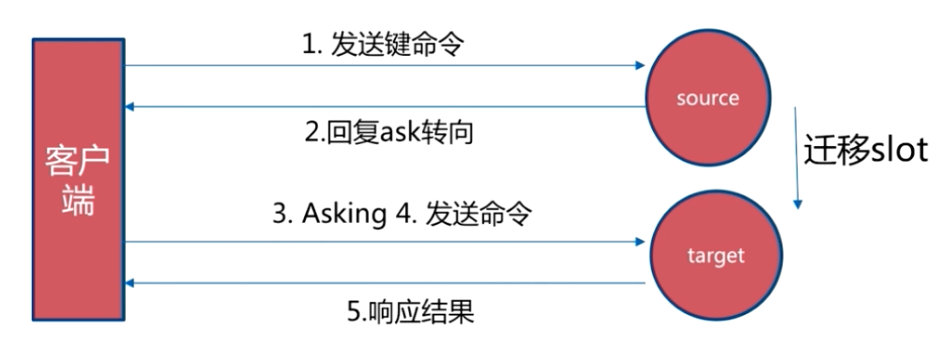
- 若key不存在此slot中,检查该slot是否正在迁出(MIGRATING)?
- 若key正在迁出,返回ASK错误重定向客户端到迁移的目的服务器上
- 若Slot未迁出,检查Slot是否导入中?
- 若Slot导入中且有ASKING标记,则直接操作
- 否则返回MOVED重定向
- 槽命中:直接返回结果
- 槽不命中:即当前键命令所请求的键不在当前请求的节点中,则当前节点会向客户端发送一个Moved 重定向,客户端根据Moved 重定向所包含的内容找到目标节点,再一次发送命令。
ASK 重定向:
Ask重定向发生于集群伸缩时,集群伸缩会导致槽迁移,当我们去源节点访问时,此时数据已经可能已经迁移到了目标节点,使用Ask重定向来解决此种情况
4.3 redis cluster配置参数
官方文档配置作用;https://redis.io/topics/cluster-tutorial
-
cluster-enabled
<yes/no>:启用集群模式 -
cluster-config-file
<filename>:每个集群节点的配置文件注意,尽管这个选项的名称,这不是一个用户可编辑的配置文件,而是一个Redis Cluster节点在每次有变化时自动持久化集群配置(状态,基本上)的文件,以便能够在启动时重新读取它。该文件列出了集群中的其他节点、它们的状态、持久变量等内容。由于某些消息接收,此文件通常会被重写并刷新到磁盘上。
-
cluster-node-timeout
<milliseconds>:Redis 集群节点不可用的最长时间,而不被视为失败。如果主节点在指定的时间内无法访问,它将由其从属节点进行故障转移。该参数控制Redis Cluster中的其他重要事项。值得注意的是,在指定的时间内无法访问大多数主节点的每个节点都将停止接受查询。 -
cluster-slave-validity-factor
<factor>:如果设置为零,则从站将始终认为自己有效,因此将始终尝试对主站进行故障转移,无论主站和从站之间的链接保持断开连接的时间长短。如果值为正,则计算最大断开时间为节点超时值乘以此选项提供的系数,如果节点是从节点,如果主链接断开的时间超过指定的时间,它将不会尝试启动故障转移。例如,如果节点超时设置为 5 秒,并且有效性因子设置为 10,则从站与主站断开连接超过 50 秒的从站将不会尝试对其主站进行故障转移。请注意,如果没有能够对其进行故障转移的从属服务器,则任何非零值都可能导致 Redis 集群在主服务器故障后不可用。在这种情况下,只有当原始主节点重新加入集群时,集群才会恢复可用。 -
cluster-migration-barrier
<count>:一个主站将保持连接的最小从站数量,以便另一个从站迁移到不再被任何从站覆盖的主站。有关更多信息,请参阅本教程中有关副本迁移的相应部分。 -
cluster-require-full-coverage
<yes/no>:如果将其设置为 yes,默认情况下,如果任何节点未覆盖一定百分比的密钥空间,则集群将停止接受写入。如果该选项设置为 no,即使只能处理有关密钥子集的请求,集群仍将提供查询服务。 -
cluster-allow-reads-when-down
<yes/no>:如果设置为 no,默认情况下,当集群被标记为失败时,Redis 集群中的节点将停止服务所有流量,或者当节点无法访问时达到法定人数或未达到完全覆盖时。这可以防止从不知道集群中的变化的节点读取可能不一致的数据。可以将此选项设置为 yes 以允许在故障状态期间从节点读取,这对于希望优先考虑读取可用性但仍希望防止不一致写入的应用程序非常有用。它也可以用于使用只有一个或两个分片的 Redis Cluster 时,因为它允许节点在主节点发生故障但无法自动故障转移时继续提供写入服务。
4.4 配置
要让集群正常工作至少需要3个主节点,在这里我们要创建6个redis节点,其中三个为主节点,三个为从节点。为了方便演示,这6个redis部署在同一台机器, 采用不同的端口号(7000 ~ 7005)。
7000、7002、7004分别为主从,其他三个为从
4.4.1 准备配置文件
创建redis-7000.conf,一直到redis-7005.conf,6 个配置文件
#最小化的示例,其他参数根据官方文档配置文件的参数调整
#直接将redis.conf复制重命名过来,修改下面这些
port 7000
daemonize yes
cluster-enabled yes
cluster-config-file nodes-7000.conf
cluster-node-timeout 5000
pidfile /var/run/redis_7000.pid
logfile "cluster-7000.log"
appendonly yes
#密码可以不配置
requirepass 123456
masterauth 123456
#对于其余的配置文件,只需要将其中对应项的端口号和带有端口号的文件名修改为当前要指定的端口号和端口号的文件名即可。
4.4.2 启动集群
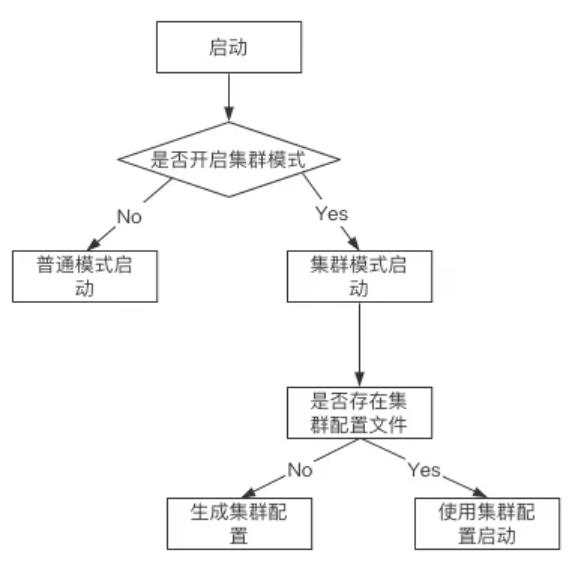
为了规范,放在各自目录中
mkdir /usr/local/redis/cluster-test
cd /usr/local/redis/cluster-test/
mkdir 700{0..5}
#将配置文件放在对应的目录
[root@localhost cluster-test]# tree
.
├── 7000
│ └── cluster-7000.conf
├── 7001
│ └── cluster-7001.conf
├── 7002
│ └── cluster-7002.conf
├── 7003
│ └── cluster-7003.conf
├── 7004
│ └── cluster-7004.conf
└── 7005
└── cluster-7005.conf
6 directories, 6 files
#根据每个配置文件,都启动集群
cd 7000
redis-server cluster-7000.conf
.....
redis-server cluster-7005.conf
#启动时,从每个实例的日志中可以看出,由于没有nodes.conf文件存在,每个节点都会为自己分配一个新的 ID。
267030:M 14 Sep 2021 14:44:54.902 * No cluster configuration found, I'm 7418630a8879f4274bd429820f658f90bc046d95
4.4.3 加入集群
redis4以上,可以使用--cluster,例如
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 \ 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 \ --cluster-replicas 1也可以用官方的工具
连接上后使用cluster meet命令分别连接其余节点:
如果连不上,会handshake - 0 0 0 disconnected,然后剔除
[root@localhost ~]# redis-cli -p 7000 -a 123456
127.0.0.1:7000> cluster meet 127.0.0.1 7001
OK
.....
127.0.0.1:7000> cluster meet 127.0.0.1 7005
OK
#删除节点
cluster forget nodeid
连接好后可以使用cluster nodes命令查看当前集群状态:
127.0.0.1:7000> cluster nodes
d6dc709b3eb04310fab561c1b9a764a0d7e6955d 127.0.0.1:7001@17001 master - 0 1631602857000 5 connected
ce47ccef790cd5a22dc387edc506fe0066de6b25 127.0.0.1:7002@17002 master - 0 1631602857047 2 connected
54fba3d9266a0c58399d365e8e8eefd979bb1339 127.0.0.1:7004@17004 master - 0 1631602858050 4 connected
e831481f400bd0e3a08cbe3b11d5414e117bc2d4 127.0.0.1:7005@17005 master - 0 1631602857000 0 connected
7418630a8879f4274bd429820f658f90bc046d95 127.0.0.1:7000@17000 myself,master - 0 1631602857000 1 connected
b684c9b7aaaf5e3c84c5e02a7e69eff6d6cc3799 127.0.0.1:7003@17003 master - 0 1631602856042 3 connected
可以看到配置的六个节点都已经加入到了集群中,但是其现在还不能使用,因为还没有将16384个槽分配到集群节点中。
4.4.4 分配槽位
我们三主三从,所以只分3个
使用python计算
>>> divmod(16384,3)
(5461, 1)
也就是先分5461,再分5461,最后剩余的分给最后一个
对应的就是:
| 节点 | 槽位 |
|---|---|
| 7000 | 0 - 5461 |
| 7002 | 5461 - 10922 |
| 7004 | 10922 - 16383 |
虚拟槽的分配可以使用redis-cli分别连接到7000,7002和7004端口的节点中,然后分别执行如下命令:
[root@localhost ~]# redis-cli -h 127.0.0.1 -p 7000 -a 123456 cluster addslots {0..5461}
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
OK
[root@localhost ~]# redis-cli -h 127.0.0.1 -p 7002 -a 123456 cluster addslots {5462..10922}
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
OK
[root@localhost ~]# redis-cli -h 127.0.0.1 -p 7004 -a 123456 cluster addslots {10923..16383}
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
OK
使用cluster nodes命令查看当前节点的状态:
d6dc709b3eb04310fab561c1b9a764a0d7e6955d 127.0.0.1:7001@17001 master - 0 1631604722537 5 connected
ce47ccef790cd5a22dc387edc506fe0066de6b25 127.0.0.1:7002@17002 master - 0 1631604722537 2 connected 5462-10922
54fba3d9266a0c58399d365e8e8eefd979bb1339 127.0.0.1:7004@17004 master - 0 1631604722000 4 connected 10923-1638
e831481f400bd0e3a08cbe3b11d5414e117bc2d4 127.0.0.1:7005@17005 master - 0 1631604722000 0 connected
7418630a8879f4274bd429820f658f90bc046d95 127.0.0.1:7000@17000 myself,master - 0 1631604721000 1 connected 0-5
b684c9b7aaaf5e3c84c5e02a7e69eff6d6cc3799 127.0.0.1:7003@17003 master - 0 1631604723000 3 connected
添加完槽位后可使用cluster info命令查看当前集群状态:
127.0.0.1:7000> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:5
cluster_my_epoch:1
cluster_stats_messages_ping_sent:3022
cluster_stats_messages_pong_sent:3238
cluster_stats_messages_meet_sent:7
cluster_stats_messages_sent:6267
cluster_stats_messages_ping_received:3238
cluster_stats_messages_pong_received:3029
cluster_stats_messages_received:6267
4.4.5 配置从节点
这里我们将16384个虚拟槽位分配给了三个节点
而剩余的三个节点我们通过如下命令将其配置为这三个节点的从节点,从而达到高可用的目的:
#根据剩下的三个节点的node_id,将其作为从节点
127.0.0.1:7000> cluster nodes
d6dc709b3eb04310fab561c1b9a764a0d7e6955d 127.0.0.1:7001@17001 master - 0 1631604722537 5 connected
ce47ccef790cd5a22dc387edc506fe0066de6b25 127.0.0.1:7002@17002 master - 0 1631604722537 2 connected 5462-10922
54fba3d9266a0c58399d365e8e8eefd979bb1339 127.0.0.1:7004@17004 master - 0 1631604722000 4 connected 10923-16383
e831481f400bd0e3a08cbe3b11d5414e117bc2d4 127.0.0.1:7005@17005 master - 0 1631604722000 0 connected
7418630a8879f4274bd429820f658f90bc046d95 127.0.0.1:7000@17000 myself,master - 0 1631604721000 1 connected 0-5461
b684c9b7aaaf5e3c84c5e02a7e69eff6d6cc3799 127.0.0.1:7003@17003 master - 0 1631604723000 3 connected
#得到这三个主的id
7000: 7418630a8879f4274bd429820f658f90bc046d95
7002: ce47ccef790cd5a22dc387edc506fe0066de6b25
7004; 54fba3d9266a0c58399d365e8e8eefd979bb1339
#分别登陆三个从,将他们配置为其他三个的副本
127.0.0.1:7001> cluster replicate 7418630a8879f4274bd429820f658f90bc046d95
OK
127.0.0.1:7003> cluster replicate ce47ccef790cd5a22dc387edc506fe0066de6b25
OK
127.0.0.1:7005> cluster replicate 54fba3d9266a0c58399d365e8e8eefd979bb1339
OK
查看状态
127.0.0.1:7000> cluster nodes
d6dc709b3eb04310fab561c1b9a764a0d7e6955d 127.0.0.1:7001@17001 slave 7418630a8879f4274bd429820f658f90bc046d95 0 1631605476000 1 connected
ce47ccef790cd5a22dc387edc506fe0066de6b25 127.0.0.1:7002@17002 master - 0 1631605476000 2 connected 5462-10922
54fba3d9266a0c58399d365e8e8eefd979bb1339 127.0.0.1:7004@17004 master - 0 1631605476543 4 connected 10923-16383
e831481f400bd0e3a08cbe3b11d5414e117bc2d4 127.0.0.1:7005@17005 slave 54fba3d9266a0c58399d365e8e8eefd979bb1339 0 1631605475539 4 connected
7418630a8879f4274bd429820f658f90bc046d95 127.0.0.1:7000@17000 myself,master - 0 1631605476000 1 connected 0-5461
b684c9b7aaaf5e3c84c5e02a7e69eff6d6cc3799 127.0.0.1:7003@17003 slave ce47ccef790cd5a22dc387edc506fe0066de6b25 0 1631605476845 2 connected
4.4.6 测试
127.0.0.1:7000> set hello world
OK
127.0.0.1:7000> get hello
"world"
注意连接集群模式的redis实例时需要加上参数-c,表示连接的是集群模式的实例。连接上后执行get命令:
redis-cli -c -p 7001 -a 123456
127.0.0.1:7001> get hello
-> Redirected to slot [866] located at 127.0.0.1:7000
"world"
redis-cli -c -p 7003 -a 123456
127.0.0.1:7003> keys *
(empty array)
127.0.0.1:7003> get hello
-> Redirected to slot [866] located at 127.0.0.1:7000
"world"
127.0.0.1:7000>
redis-cli -c -p 7004 -a 123456
127.0.0.1:7004> get foor
-> Redirected to slot [3280] located at 127.0.0.1:7000
(nil)
127.0.0.1:7000> get hello
"world"
127.0.0.1:7000>
可以看到,在cluster的实例上执行get命令时,其首先会为当前的键通过一致哈希算法计算其所在的槽位,并且判断该槽位不在当前redis实例中,因而重定向到目标实例上执行该命令,最后发现没有该键对应的值,因而返回了一个(nil)。
4.4.7 常用命令及配置
Cluster配置:
-
是否启用cluster,加入cluster节点
cluster-enabled yes|no -
cluster配置文件名,该文件属于自动生成,仅用于快速查找文件并查询文件内容
cluster-config-file filename -
节点服务响应超时时间,用于判定该节点是否下线或切换为从节点
cluster-node-timeout milliseconds -
master连接的slave最小数量
cluster-migration-barrier min_slave_number
Cluster节点操作命令:
-
查看集群节点信息
cluster nodes -
更改slave指向新的master
cluster replicate master-id -
发现一个新节点,新增master
cluster meet ip:port -
忽略一个没有solt的节点
cluster forget server_id -
手动故障转移
cluster failover
redis-cli命令
-
创建集群
redis-cli –-cluster create masterhost1:masterport1 masterhost2:masterport2masterhost3:masterport3 [masterhostn:masterportn …] slavehost1:slaveport1slavehost2:slaveport2 slavehost3:slaveport3 ––cluster-replicas nmaster与slave的数量要匹配,一个master对应n个slave,由最后的参数n决定
master与slave的匹配顺序为第一个master与前n个slave分为一组,形成主从结构
-
添加master到当前集群中,连接时可以指定任意现有节点地址与端口
redis-cli --cluster add-node new-master-host:new-master-port now-host:now-port -
添加slave
redis-cli --cluster add-node new-slave-host:new-slave-portmaster-host:master-port --cluster-slave --cluster-master-id masterid -
删除节点,如果删除的节点是master,必须保障其中没有槽slot
redis-cli --cluster del-node del-slave-host:del-slave-port del-slave-id -
重新分槽,分槽是从具有槽的master中划分一部分给其他master,过程中不创建新的槽
redis-cli --cluster reshard new-master-host:new-master:port --cluster-from srcmaster-id1, src-master-id2, src-master-idn --cluster-to target-master-id --cluster-slots slots
将需要参与分槽的所有masterid不分先后顺序添加到参数中,使用,分隔
指定目标得到的槽的数量,所有的槽将平均从每个来源的master处获取
-
重新分配槽,从具有槽的master中分配指定数量的槽到另一个master中,常用于清空指定master中的槽
redis-cli --cluster reshard src-master-host:src-master-port --cluster-from srcmaster-id --cluster-to target-master-id --cluster-slots slots --cluster-yes

 浙公网安备 33010602011771号
浙公网安备 33010602011771号