mysql并行复制
1.为什么需要并行复制
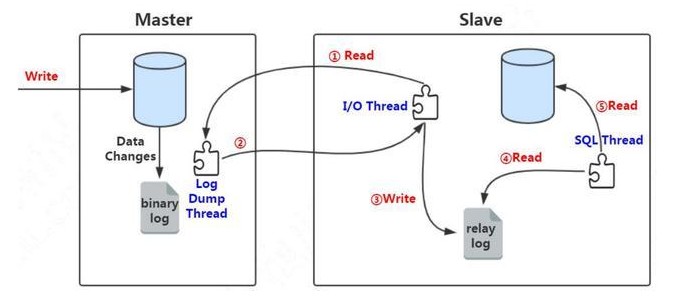
并行复制是为了减少复制延迟时间
并行复制,指的是,
-
在master设置组提交
-
在slave起用多个SQL 进程回放,减小master 与 salve 之间的延迟
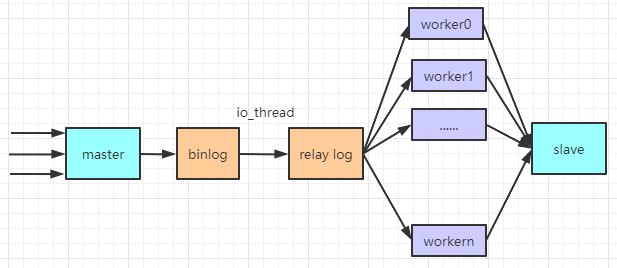
实际上就是io_thread将可以并行的操作交给work线程
从5.5到5.7,并行粒度越来越小,从库到表到行,5.7之后才最终完善
主从复制下延迟的原因:
- 主库写binlog与dump_thread读binlog是串行的操作(5.7+dump_thread读与写binlog是并行的,组提交)
- sql_thread回放线程只有一个;(并行复制解决)
- 主从所在的主机硬件性能有差异;
- 主库有大事务;
2.并行复制配置
2.1配置
主从条件下(gtid):
主库:
binlog_group_commit_sync_delay=100
binlog_group_commit_sync_no_delay_count=10
从库:
#MUlti-thread线程配置
slave_parallel_type=logical_clock
slave_parallel_workers=8
slave_preserve_commit_order=1
master_info_repository=TABLE
relay_log_info_repository=TABLE
relay-log-recovery = ON
log_slave_updates=1
2.2检验并行复制
#首先重启后要确保主从状态,sql和io线程都是yes
#参数配置错误会导致主从起不来,注意start slave查看报错
#查看
select * from performance_schema.replication_applier_status_by_worker\G
*************************** 1. row ***************************
CHANNEL_NAME:
WORKER_ID: 1
THREAD_ID: 27
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION:
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
*************************** 2. row ***************************
CHANNEL_NAME:
WORKER_ID: 2
THREAD_ID: 28
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION:
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
*************************** 3. row ***************************
CHANNEL_NAME:
WORKER_ID: 3
THREAD_ID: 30
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION:
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
*************************** 4. row ***************************
CHANNEL_NAME:
WORKER_ID: 4
THREAD_ID: 32
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION:
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
*************************** 5. row ***************************
CHANNEL_NAME:
WORKER_ID: 5
THREAD_ID: 33
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION:
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
*************************** 6. row ***************************
CHANNEL_NAME:
WORKER_ID: 6
THREAD_ID: 34
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION:
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
*************************** 7. row ***************************
CHANNEL_NAME:
WORKER_ID: 7
THREAD_ID: 35
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION:
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
*************************** 8. row ***************************
CHANNEL_NAME:
WORKER_ID: 8
THREAD_ID: 36
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION:
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
8 rows in set (0.00 sec)
#开了几个work线程,就有几条记录
show processlist;
+----+-------------+-----------+------+---------+------+--------------------------------------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-------------+-----------+------+---------+------+--------------------------------------------------------+------------------+
| 1 | system user | | NULL | Connect | 1181 | Slave has read all relay log; waiting for more updates | NULL |
| 2 | system user | | NULL | Connect | 1181 | Waiting for master to send event | NULL |
| 3 | system user | | NULL | Connect | 1181 | Waiting for an event from Coordinator | NULL |
| 4 | system user | | NULL | Connect | 1181 | Waiting for an event from Coordinator | NULL |
| 6 | system user | | NULL | Connect | 1181 | Waiting for an event from Coordinator | NULL |
| 7 | system user | | NULL | Connect | 1181 | Waiting for an event from Coordinator | NULL |
| 8 | system user | | NULL | Connect | 1181 | Waiting for an event from Coordinator | NULL |
| 9 | system user | | NULL | Connect | 1181 | Waiting for an event from Coordinator | NULL |
| 10 | system user | | NULL | Connect | 1181 | Waiting for an event from Coordinator | NULL |
| 11 | system user | | NULL | Connect | 1181 | Waiting for an event from Coordinator | NULL |
| 13 | root | localhost | NULL | Query | 0 | starting | show processlist |
+----+-------------+-----------+------+---------+------+--------------------------------------------------------+------------------+
11 rows in set (0.00 sec)
2.3监控
并行复制开启后
show slave status\G
Read_Master_Log_Pos和Exec_Master_Log_Pos对比,得出差异
可以利用gtid查看对比
3.参数详解
binlog_group_commit_sync_delay
全局动态变量,单位微妙,默认0,范围:0~1000000(1秒)。
表示
binlog提交后等待延迟多少时间再同步到磁盘,默认0 ,不延迟。当设置为 0 以上的时候,就允许多个事务的日志同时一起提交,也就是我们说的组提交。组提交是并行复制的基础,我们设置这个值的大于 0 就代表打开了组提交的功能。
binlog_group_commit_sync_no_delay_count
全局动态变量,单位个数,默认0,范围:0~1000000。
表示等待延迟提交的最大事务数,如果上面参数的时间没到,但事务数到了,则直接同步到磁盘。若
binlog_group_commit_sync_delay没有开启,则该参数也不会开启。
例如:
binlog_group_commit_sync_delay=100
binlog_group_commit_sync_no_delay_count=10
100微秒合并提交一次,如果不到100微秒到了10个事务也提交一次
这俩个参数是主库并行写binlog,提高主库的并行度,从库的并行复制没关系
注意它们是合起来作为一个组提交的
slave_parallel_type=logical_clock
5.7引入了新的变量slave-parallel-type,其可以配置的值有:
- DATABASE:默认值,基于库的并行复制方式
- LOGICAL_CLOCK:基于组提交的并行复制方式(与主库的组提交对应)
slave_parallel_workers=8
开启多个work线程并行复制
slave_parallel_workers不要设为1,否则要经过一层负载器,更慢,不如关闭
slave_preserve_commit_order
slave_preserve_commit_order 参数在多线程复制环境下,能够保证从库回放relay log事务的顺序与这些事务在relay log中的顺序完全一致,也就是与主库提交的顺序完全一致。
举个例子,开启并行复制后,如果relay log中有3个事务A,B,C,他们在relay log中的顺序是A->B->C,而它们的last_commited相同,也就是说他们可以并行回放,那么在从库上,这3个事务,提交的顺序可能就不再是A->B->C,设置slave_preserve_commit_order=ON,能够保证这3个事务,在从库回放时,仍然按照它们在relay log中的顺序来回放,保证从库回放relay log事务的顺序与主库完全相同。
slave_preserve_commit_order:
- 作用范围:Global
- 动态修改:Yes,修改时需要停止SQL线程
- 默认值:OFF
该参数起作用的前提条件是开启多线程复制:
- slave_parallel_type=LOGICAL_CLOCK
- slave_parallel_workers>0
在 8.0.18 及之前版本,从库只有开启binlog的两个参数(log_bin,log_slave_updates),才能设置slave_preserve_commit_order=ON,而 8.0.19 版本开始,这个前提条件不再需要了。
设置slave_preserve_commit_order=ON,当一个线程等待其他线程的事务提交时,会出现一个状态信息,在一个写入量较大的主从复制集群中,在从库上执行show processlist可以看到这个状态信息,如下:
Waiting for preceding transaction to commit
注意:
ERROR 3031 (HY000): slave_preserve_commit_order is not supported unless both log_bin and log_slave_updates are enabled.
要使用它必须开启binlog和log_slave_updates
log_slave_updates=1
master_info_repository
relay_log_info_repository
master_info_repository决定了slave的master status是存储在master.info还是slave_master_info表。
master_info_repository有两个值,分别是file和table,该参数决定了slave记录master的状态,如果参数是file,就会创建master.info文件,如果参数值是table,就在mysql中创建slave_master_info的表。
开启MTS功能后,务必将参数master_info_repostitory设置为TABLE,这样性能可以有50%~80%的提升。这是因为并行复制开启后对于元master.info这个文件的更新将会大幅提升,资源的竞争也会变大。在之前InnoSQL的版本中,添加了参数来控制刷新master.info这个文件的频率,甚至可以不刷新这个文件。因为刷新这个文件是没有必要的,即根据master-info.log这个文件恢复本身就是不可靠的。在MySQL 5.7中,Inside君推荐将master_info_repository设置为TABLE,来减小这部分的开销。
在 MySQL 5.7 中,推荐将 master-info-repository 和 relay-log-info-repository 设置为TABLE来减少开销
master_info_repository=TABLE
relay_log_info_repository=TABLE
relay-log-recovery = ON
relay_log_recovery
改参数默认是打开的,在数据库启动后立即启动自动relay log恢复,在恢复过程中,创建一个新的relay log文件,将sql线程的位置初始化到新的relay log,并将i/o线程初始化到sql线程位置。
mysql在运行过程中,从库上可能会出现意外宕机的情况,那么在从库启动后,必须能够恢复到停止之前的状态。i/o线程必须恢复到接受事务的位置,sql线程必须恢复到一致执行事务的位置。该信息传统上是存储在文件中,那么有可能存在不一致或者存在的风险,从mysql5.7开始,可以使用表来存储这些信息,并且把这些表设置为innodb引擎,通过使用事务性存储引擎,总能够恢复这个信息。可以配置参数master_info_repository=table和relay_log_info_repository=table使从库信息存储到表中。从库如何从宕机状态恢复到正确状态,取决与从库是单线程还是多线程、relay_log_recover参数的值,以及master_auto_position的使用方式。
1,单线程模式的复制(mysql5.7)
当基于gtid模式复制的时候,并且设置了master_auto_posion参数和relay_log_recover=0,使用该设置,其中relay_log_info_repository和其他变量的设置都不会影响恢复。
当基于传统模式复制的情况下,需要设置relay_log_recovery=1和relay_log_info_repository=table。
2,多线程模式的复制(5.7)
当基于gtid模式复制的时候,并且设置了master_auto_position和relay_log_recover=0,使用该配置,其relay_log_info_repository和其他变量的设置都会影响恢复。
当基于传统模式复制的时候,请设置relay_log_recover=1,sync_relay_log=1和relay_log_info_repository=table。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号