mysql缓冲池、数据结构和算法
页
mysql中和磁盘交互的最小单位称为页,页是mysql内部定义的一种数据结构,默认为16kb,相当于4个磁盘块,也就是说mysql每次从磁盘中读取一次数据是16KB,要么不读取,要读取就是16KB,此值可以修改的。
InnoDB 存储引擎中默认每个页的大小为16KB,可通过参数 innodb_page_size 将页的大小设置为 4K、8K、16K
在 MySQL 中可通过如下命令查看页的大小:show variables like 'innodb_page_size';
磁盘预读
因为主存和磁盘访问效率的巨大差异,磁盘 I/O 变成了一个很重量级的操作,因此需要尽可能减少磁盘 I/O 的次数,为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是局部性原理,即当计算机访问一个地址的数据的时候,通常与其相邻的数据也会很快被访问到。
预读的长度一般为页(page)的整倍数,页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为 4K),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
这里说的“顺序”,指的是逻辑上的顺序,在物理上并不能保障所有数据都是顺序的,而为了保证顺序,存储引擎一般都根据区(extent)来管理页
例如:在innoDB存储引擎中,一个区是连续的64个页,因此才顺序读取时,以保证这64个页是连续的,但是区与区之间的页,可能是连续的也可能不是连续的。
缓冲池(buffer pool)
缓冲池是基于存储引擎的,每个存储引擎都有自己的缓冲池。
对于MyISAM来说,变量key_buffer_size决定了缓冲池的大小。
对于InnoDB来说,变量innodb_buffer_pool_size决定了缓冲池的大小
先从硬件上来看,内存的速度是远高于硬盘的。
mysql是基于磁盘的数据库,这种数据库都是有缓冲池的。所谓的缓冲池,就是一块内存区域。他的作用就是从磁盘读取指定大小的数据(被称为页或块),放入缓冲池。当再次读取时,数据库首先判断该页是否在缓冲池中,如果在则直接读取,如果不在则读取磁盘上的页。对于写操作来说,数据库将页读入缓冲池,然后在缓冲池中对页进行修改,修改完成后的页异步写入磁盘。对缓冲池的维护一般采用最近最少使用(Least Recently Used,LRU)算法,老版的LRU有一些缺陷,但新版LRU解决了部分缺陷。
所以mysql的缓冲池(buffer pool)的大小决定了数据库的性能,假如数据库能完全放在缓冲池中,则完全可以认为这时的数据库性能是最优的,除了与磁盘进行同步/异步的写操作外,都能在内存中完成
设置缓冲池大小
[server]
innodb_buffer_pool_size = 5242880 #5M,5*1024*1024
innodb_buffer_pool_size = 8G
#不写单位,则单位为字节
#同样set global或是写入配置文件重启
#尽量使用配置文件
#在8.0中除了写入配置文件外,还可以这样
set persist innodb_buffer_pool_size = 8589934592;
执行完该指令后,就会在datadir目录下,生成一个新的文件 mysqld-auto.cnf
这样即便下次MySQL实例重启,这个配置也会持续生效。
但前提是下面这个参数要设置为ON(其默认值也是ON)
persisted_globals_load = ON
数据结构和算法
抛开其他因素,我们全表扫描一个表,从头到尾逐行遍历,直到在无序的行数据中找到符合条件的目标数据。
顺序访问进行全表扫描实现比较简单,但是当表中有大量数据的时候,效率非常低下。例如,在几千万条数据中查找少量的数据时,使用顺序访问方式将会遍历所有的数据,花费大量的时间,显然会影响数据库的处理性能。
正是为了优化查询,减少io,我们才需要这样的数据结构和算法:
- 需要这样的数据结构:从磁盘中检索数据时,能尽可能的减少磁盘的io次数,同时希望将这个次数稳定在一个较小的范围
- 需要这样的算法:从磁盘读取到磁盘块中的数据后,这些块往往可能包含多条记录,这些记录被加载到内存中。我们在内存中想要找出我们想要的目标数据。所以需要一种算法,能快速从内存的记录中检索出目标数据。
当然B+tree作为索引是最常见使用最频繁的的,先看一些与之有关的算法和数据结构更有助于理解后面的B+tree索引的工作流程。
常见的有:
二分查找法
二叉查找树
AVL树(平衡二叉树)
红黑树
展开树
哈希表(分为开放寻址和封闭寻址)
Trie(前缀树)
基数树(也叫压缩前缀树)
三元搜索树
B树和B+树
以简单的二分法和二叉树为例:
二分查找法
二分查找法(Binary Search)也叫折半查找法,用来查找一组有序记录数组中的某一项记录。
基本思想是:现将记录有序排列(递增或递减),查找过程中采用跳跃式的方式查找,即现将有序的数列的中点位置为比较对象,如果要查找的元素值比小于该中点元素,则将待查找的序列缩小为左半部分,否则为右半部分。一次次的一半一半的缩小查找区间,直至找到。
例子:假设要找到48
数据:5, 10, 19, 21, 31, 37, 42, 48, 50, 52
下标:0, 1, 2, 3, 4, 5, 6, 7, 8, 9步骤一:设 low 为下标最小值0,high 为下标最大值9。
步骤二:通过 low 和 high 得到 mid,mid=(low + high) / 2,初始时 mid 为下标4,也可以是5,看具体算法实现。
步骤三:mid = 4对应的数据值是31,31 < 48(我们要找的数字)。
步骤四:通过二分查找的思路,将 low 设置为31对应的下标4,high 保持不变为9,此时 mid 为6。
步骤五:mid = 6对应的数据值是42,42 < 48(我们要找的数字)。
步骤六:通过二分查找的思路,将 low 设置为42对应的下标6,high 保持不变为9,此时 mid 为7。
步骤七:mid = 7对应的数据值是48,48 == 48(我们要找的数字),查找结束。
通过3次二分查找就找到了我们所要的数字,而顺序查找需8次。
换一个更直观的例子:
https://www.cs.usfca.edu/~galles/visualization/Search.html
例:
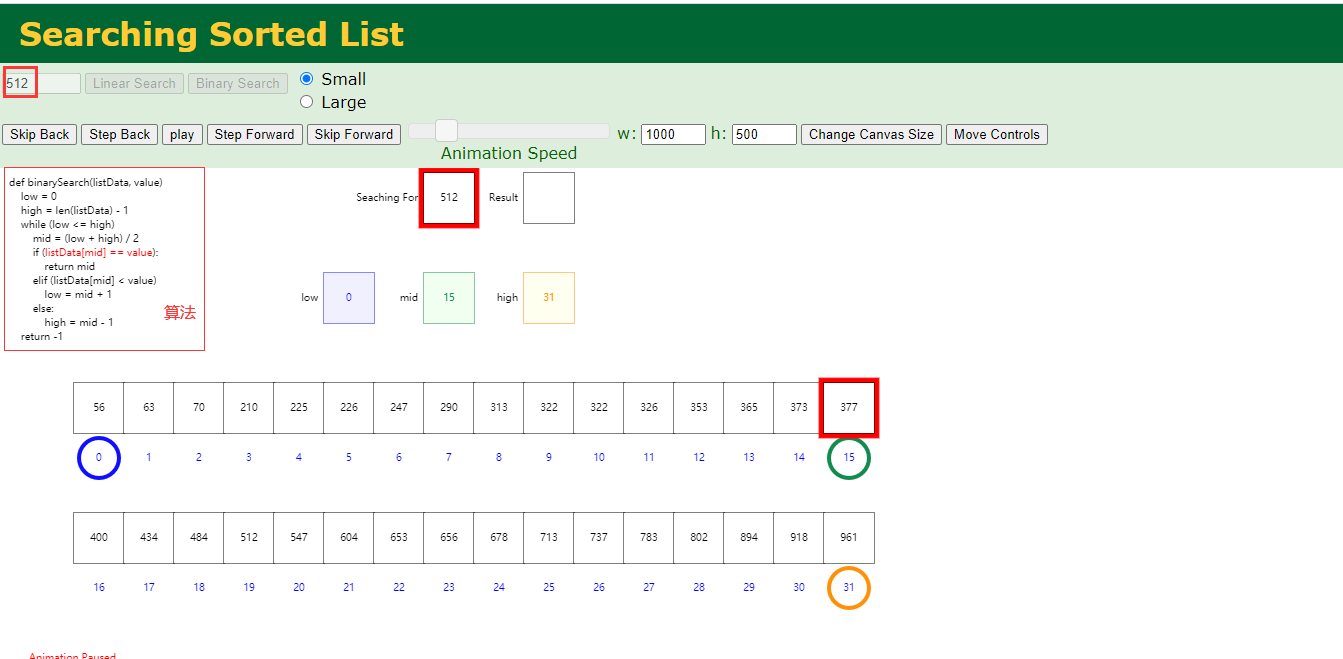
例如查找512,low为0,high为31,根据算法 high-1 后与low相加除以2,得到中间值mid,其值为377
而我们的512大于它,所以继续往右分
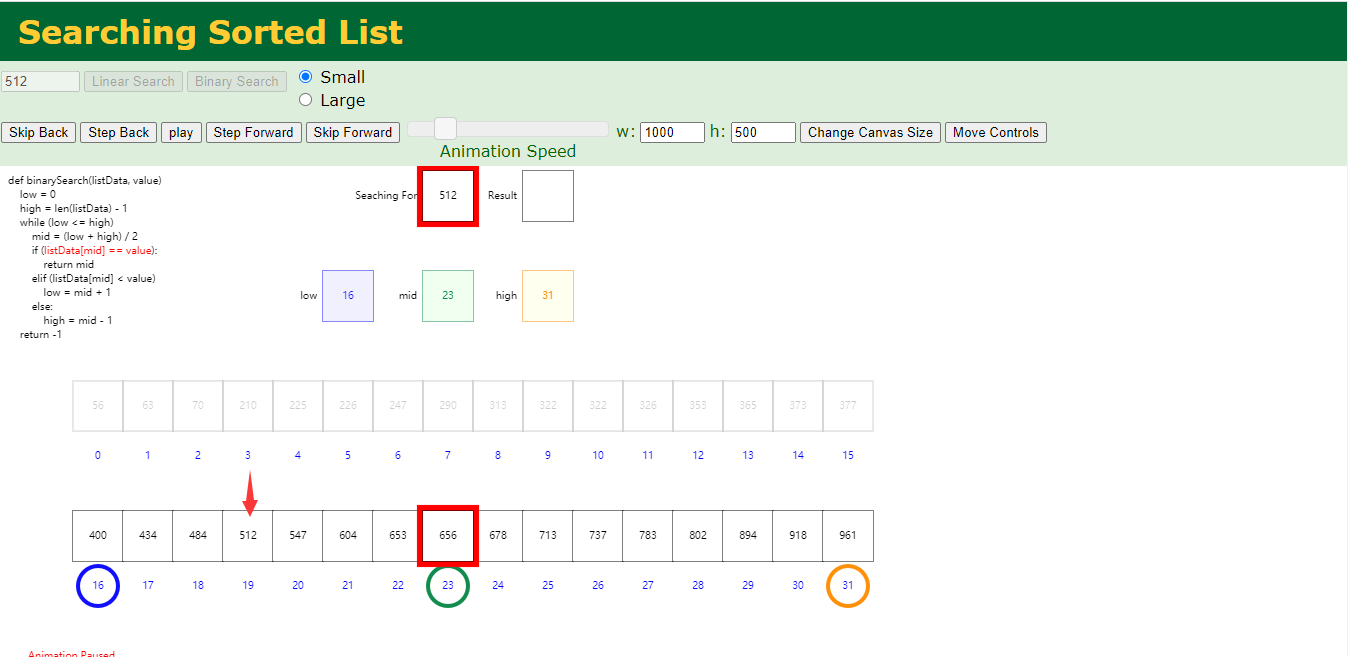
再次二分之后,mid对应的为656,512在左边,继续分
恰好mid对应的为我们需要的值,结束
链表
链表相当于在每个节点上增加一些指针,可以和前面或者后面的节点连接起来,就像一列火车一样,每节车厢相当于一个节点,车厢内部可以存储数据,每个车厢和下一节车厢相连。
链表分为单链表和双向链表
单链表
每个节点中有持有指向下一个节点的指针,只能按照一个方向遍历链表,结构如下:
//单项链表
class Node1{
private Object data;//存储数据
private Node1 nextNode;//指向下一个节点
}
双向链表
每个节点中两个指针,分别指向当前节点的上一个节点和下一个节点,结构如下:
//双向链表
class Node2{
private Object data;//存储数据
private Node1 prevNode;//指向上一个节点
private Node1 nextNode;//指向下一个节点
}
链表的优点:
-
可以快速定位到上一个或者下一个节点
-
可以快速删除数据,只需改变指针的指向即可
链表的缺点:
-
无法向数组那样,通过下标随机访问数据
-
查找数据需从第一个节点开始遍历,不利于数据的查找,查找时间和无需数据类似,需要全遍历,最差时间是O(N)
二叉查找树
二叉查找树(Binary Search Tree,也叫二叉搜索树)是每个结点最多有两个子树的树结构,通常子树被称作“左子树”(left subtree)和“右子树” (right subtree)。二叉树常被用于实现二叉查找树和二叉堆。
没有父节点的节点为根节点,没有子节点的节点称为叶子节点
二叉查找树就是任何节点的左子节点小于当前节点键值,右子节点大于当前节点键值。
二叉树有这样的特性:
1、每个结点都包含一个元素以及n个子树,这里0≤n≤2。
2、左子树和右子树是有顺序的,次序不能任意颠倒,左子树的值要小于父结点,右子树的值要大于父结点。
数组[20,10,5,15,30,25,35]使用二叉查找树存储如下:
https://www.cs.usfca.edu/~galles/visualization/BST.html
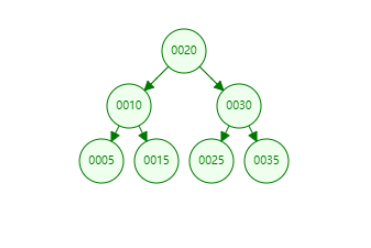
每个节点上面有两个指针(left,rigth),可以通过这2个指针快速访问左右子节点,检索任何一个数据最多只需要访问3个节点,相当于访问了3次数据,时间为O(logN),和二分法查找效率一样。
这里用O(log n)指时间复杂度
但是当我们插入的数据是递增或者递减的时候,它会退化成链表,那它的检索效率和全表扫描一样了,没有任何变化
如[5,10,15,20,30,25,35],那么结构就变成下面这样:
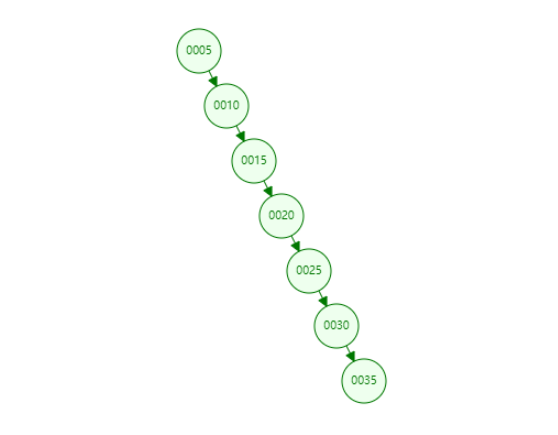
二叉树退化为了一个链表结构,查询数据最差就变为了O(N),完成变成了遍历。
二叉树的优缺点:
-
查询数据的效率不稳定,若树左右比较平衡的时,最差情况为O(logN),如果插入数据是有序的,退化为了链表,查询时间变成了O(N)
-
数据量大的情况下,会导致树的高度变高,如果每个节点对应磁盘的一个块来存储一条数据,需io次数大幅增加,显然用此结构来存储数据是不可取的
平衡二叉树(AVL树)
平衡二叉树定义:首先符合二叉查找树的定义,其次必须满足任何节点的两个子树的高度最大差为1
例如下图,当需要插入一个键值为9的节点时
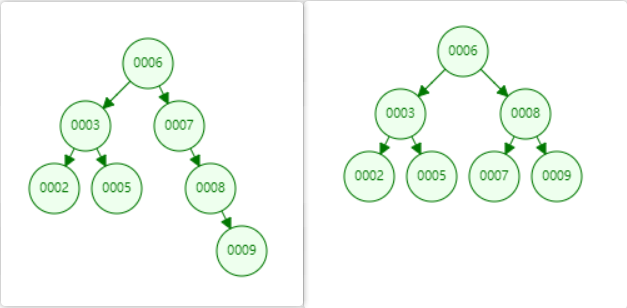
⑦—⑧做了旋转操作
上面演示了向平衡二叉树插入一个节点后,平衡二叉树需要做旋转操作,当然除了插入操作,还有更新和删除操作。相同的是,在进行这些操作后在恢复二叉树的平衡性上没有本质区别,它们都是通过左旋或者右旋来完成的,因此对一颗平衡树的维护是有一定开销的,不过平衡二叉树多用于内存结构对象中,因此维护的开销相对较小。
多次旋转的例子:
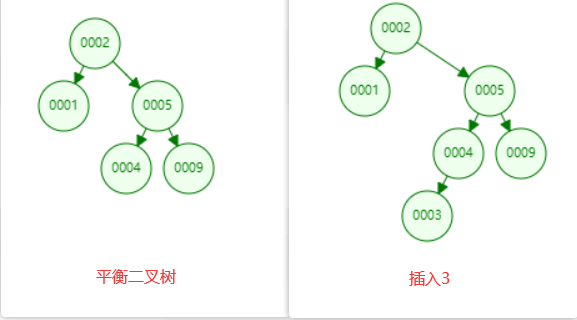
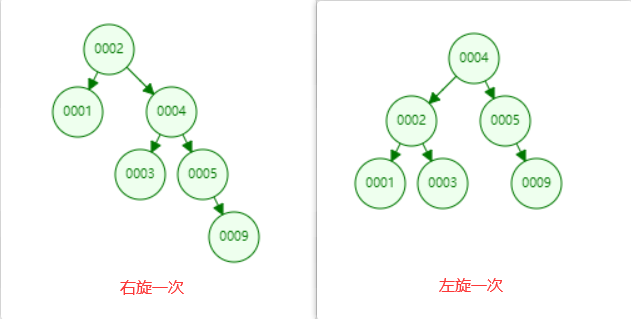
平衡二叉树相对于二叉树来说,树的左右比较平衡,不会出现二叉树那样退化成链表的情况,不管怎么插入数据,最终通过一些调整,都能够保证树左右高度相差不大于1。
这样可以让查询速度比较稳定,查询中遍历节点控制O(logN)范围内
如果数据都存储在内存中,采用AVL树来存储,还是可以的,查询效率非常高。不过我们的数据是存在磁盘中,用过采用这种结构,每个节点对应一个磁盘块,数据量大的时候,也会和二叉树一样,会导致树的高度变高,增加了io次数,显然用这种结构存储数据也是不可取的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号