FPGA图像处理(直方图均衡化)
图像处理领域中利用图像直方图对对比度进行调整的方法。 对比度是画面黑与白的比值,也就是从黑到白的渐变层次。比值越大,从黑到白的渐变层次就越多,从而色彩表现越丰富。对比度对视觉效果的影响非常关键,一般来说对比度越大,图像越清晰醒目,色彩也越鲜明艳丽;而对比度小,则会让整个画面都灰的不清楚。
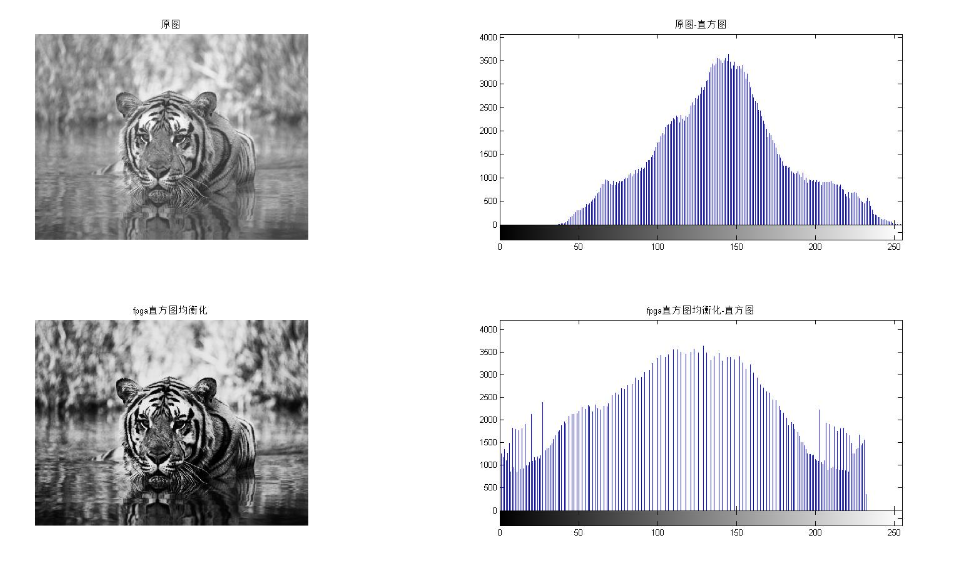
直方图均衡化分为真均衡化和伪均衡化,由于FPGA不方便实现真均衡化,所以采用伪均衡化,即前一帧的图像进行统计、帧间隙进行累计和与归一化、当前帧做归一化后的映射输出。不过仿真的话,前一帧和当前帧是同一张图片,就是真均衡化。
建立直方图,在FPGA中可以用256个计数器对每个灰度进行计数,不过这样做代码代码量太大,使用的资源也很多,不太现实。
像素是一个个来的,因此任何时钟周期都只有一个计数器在增加,意味着累加器可以在存储器中实现,首先需要读取相关存储单元,然后加一再写回,这需要用到双端口ram,一个读端口一个写端口。不过需要注意,因为读出数据需要一拍,图中灰度I需要打一拍再送入写入端口的地址端。因为ram在读写冲突时读出的是旧数据,所以当连续相同像素到来时,会出现统计丢失,不过对结果影响很小,视觉上难以辨别。
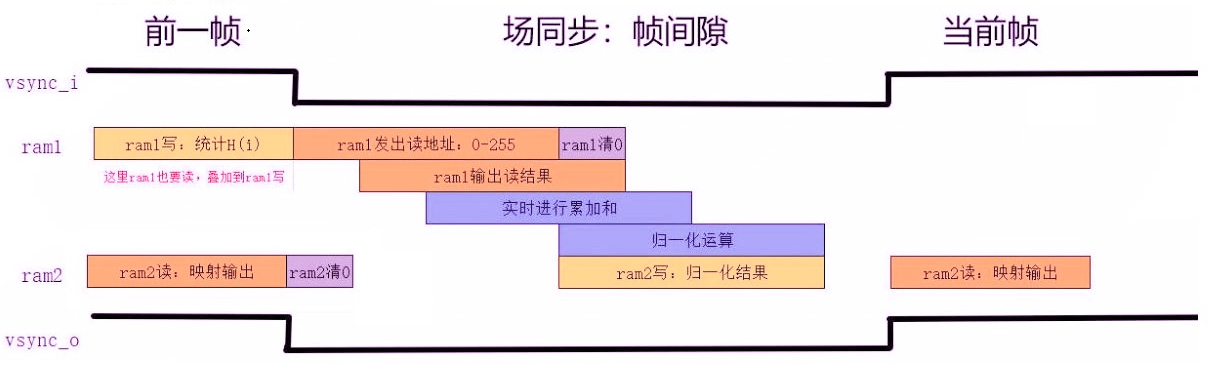
- 第一帧统计直方图存入ram1
- 帧间隙读出ram1中数据进行计算,将计算结果存入ram2,同时对ram1进行清零
- 第二帧根据映射表进行输出
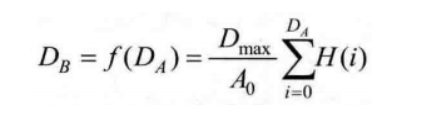
H(i)为第 i 级灰度的像素个数,A0为图像的面积(即分辨率),Dmax为灰度最大值,即255。
帧间隙时,设计一个计数器,从0计数到255,将ram1中的数据读出来,同时对ram1进行清零。读出的数据会通过流水线计算,得出直方图均衡化后的灰度级映射,再写入ram2。第一级进行累加,第二级乘以255,第三级除以分辨率。
第二帧只需读出ram2中的数据进行映射输出即可得到直方图均衡化后的图像。


module histgram_equ( input clk, input rst_n, // input input pre_vsync, input pre_href, input pre_clken, input [7:0] pre_img_Y, // output output reg post_vsync, output reg post_href, output reg post_clken, output [7:0] post_img_Y ); //----------------------信号声明-------------------------- // ram1读地址总线 wire [7:0] rd_addr_bus; // ram1读数据 wire [31:0] rd_data; // ram1写使能总线 wire wren_bus; // ram1写地址总线 wire [7:0] wr_addr_bus; // ram1写数据总线 wire [31:0] wr_data_bus; // 输入灰度打一拍 reg [7:0] pre_img_Y_r; // 数据有效打一拍 reg pre_clken_r; // pre_vsync打一拍检测下降沿 reg pre_vsync_r; // 读出直方图地址计数器 reg [7:0] rd_addr_cnt; // 读出直方图地址计数器使能 reg rd_addr_cnt_en; // 计数器使能打4拍,ram1读出数据需要1时钟周期,第一拍用于累加的使能,累加消耗1时钟周期,乘除消耗2时钟周期 reg [3:0] cnt_en_lag4; // 计数器打4拍作为ram2的写入地址 reg [7:0] rd_addr_cnt_r1; reg [7:0] rd_addr_cnt_r2; reg [7:0] rd_addr_cnt_r3; reg [7:0] rd_addr_cnt_r4; // 直方图累加和 reg [31:0] sum; // 直方图累加和 * 255 reg [31:0] sum_x_255; // 累加 * 255 / 307200,图像分辨率为640*480=307200 reg [7:0] sum_x_255_div_307200; // vsync高电平期间ram1统计直方图,低电平期间读出ram1直方图,并清零 assign rd_addr_bus = pre_vsync ? pre_img_Y : rd_addr_cnt; assign wren_bus = pre_vsync ? pre_clken_r : rd_addr_cnt_en; assign wr_addr_bus = pre_vsync ? pre_img_Y_r : rd_addr_cnt; assign wr_data_bus = pre_vsync ? (rd_data + 1) : 8'd0; //----------------------直方图统计-------------------------- // 输入灰度和数据有效打一拍,与读出数据同步 always @(posedge clk, negedge rst_n) begin if(!rst_n) begin pre_img_Y_r <= 0; pre_clken_r <= 1'b0; end else begin pre_img_Y_r <= pre_img_Y; pre_clken_r <= pre_clken; end end // 统计直方图,读写冲突会导致连续重复像素的统计丢失,但结果和实际直方图均衡近似,只是视觉上稍微暗一点 ram_32x256 inst_ram_32x256( .clock (clk), .data (wr_data_bus), .rdaddress (rd_addr_bus), .wraddress (wr_addr_bus), .wren (wren_bus), .q (rd_data) ); //--------------------------直方图累加---------------------- // pre_vsync打一拍用于检测下降沿 always @(posedge clk, negedge rst_n) begin if(!rst_n) pre_vsync_r <= 0; else pre_vsync_r <= pre_vsync; end // 读地址计数器使能 always @(posedge clk, negedge rst_n) begin if(!rst_n) rd_addr_cnt_en <= 1'b0; else if(~pre_vsync & pre_vsync_r) // 检测pre_vsync的下降沿开始计数 rd_addr_cnt_en <= 1'b1; else if(rd_addr_cnt == 8'd255) // 计数256时钟周期即停止 rd_addr_cnt_en <= 1'b0; end // 读地址计数器 always @(posedge clk, negedge rst_n) begin if(!rst_n) rd_addr_cnt <= 0; else if(rd_addr_cnt_en) rd_addr_cnt <= rd_addr_cnt + 8'd1; end // 直方图累加,消耗一时钟周期 always @(posedge clk, negedge rst_n) begin if(!rst_n) sum <= 0; else if(cnt_en_lag4[0])// 计数器使能打一拍用于累加,因为读出数据延迟一时钟周期 sum <= sum + rd_data; else sum <= 0; end // 累加 * 255,即sum * 256 - sum,消耗一时钟周期 always @(posedge clk, negedge rst_n) begin if(!rst_n) sum_x_255 <= 0; else sum_x_255 <= (sum << 8) - sum; end // 累加 * 255 / 307200,消耗一时钟周期 always @(posedge clk, negedge rst_n) begin if(!rst_n) sum_x_255_div_307200 <= 0; else sum_x_255_div_307200 <= sum_x_255 / 307200; end // 计数器使能打4拍,读出数据消耗一时钟周期,累加、乘、除消耗三时钟周期 always @(posedge clk, negedge rst_n) begin if(!rst_n) cnt_en_lag4 <= 0; else cnt_en_lag4 <= {cnt_en_lag4[2:0], rd_addr_cnt_en}; end // 计数器打4拍作为ram2的写入地址,读出数据消耗一时钟周期,累加、乘、除消耗三时钟周期 always @(posedge clk, negedge rst_n) begin if(!rst_n) begin rd_addr_cnt_r1 <= 0; rd_addr_cnt_r2 <= 0; rd_addr_cnt_r3 <= 0; rd_addr_cnt_r4 <= 0; end else begin rd_addr_cnt_r1 <= rd_addr_cnt; rd_addr_cnt_r2 <= rd_addr_cnt_r1; rd_addr_cnt_r3 <= rd_addr_cnt_r2; rd_addr_cnt_r4 <= rd_addr_cnt_r3; end end // 直方图均衡化映射表 ram_8x256 inst_ram_8x256( .clock (clk), .data (sum_x_255_div_307200), .rdaddress (pre_img_Y), .wraddress (rd_addr_cnt_r4), .wren (cnt_en_lag4[3]), .q (post_img_Y) ); // ram2读出数据消耗1时钟周期,所以其他信号打一拍输出 always @(posedge clk, negedge rst_n) begin if(!rst_n) begin post_vsync <= 1'b0; post_href <= 1'b0; post_clken <= 1'b0; end else begin post_vsync <= pre_vsync; post_href <= pre_href; post_clken <= pre_clken; end end endmodule
,Best Wish 不负年华
